# CosyVoice
CosyVoice多语言、音色和情感控制模型
## 论文
- [CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer
based on Supervised Semantic Tokens](https://fun-audio-llm.github.io/pdf/CosyVoice_v1.pdf)
## 模型结构
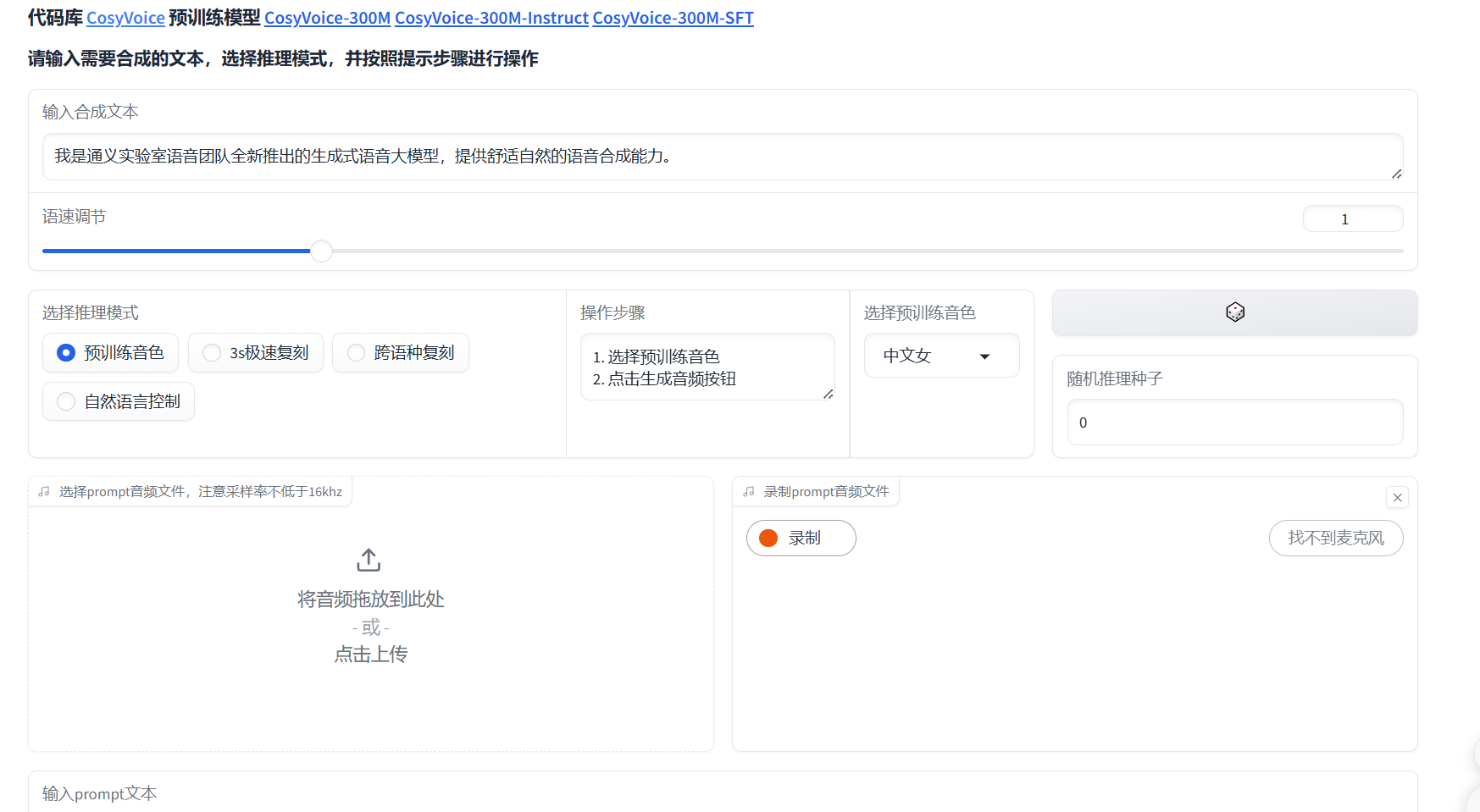
CosyVoice 的架构包括文本编码器、语音标记器、大型语言模型和条件流匹配模型。它将文本到语音的转换过程视为一个自回归序列生成问题,并通过条件流匹配模型将语音令牌转换为Mel频谱图,最后使用HiFiGAN声码器合成波形。
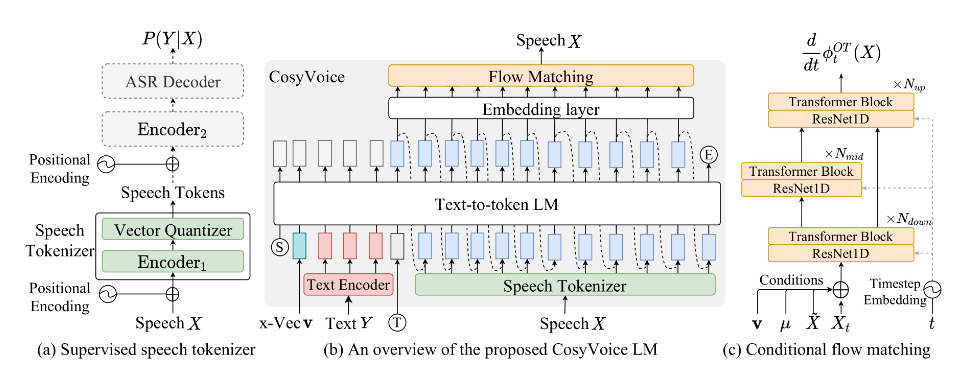
## 算法原理
CosyVoice 结合了一个自回归 transformer(transformer)基础的语言模型(模型)来为输入 文本生成语音标记(Token)。一个基于常微分方程(ODE-based)扩散模型,通过流对齐从生成的标记(Token)中重建 Mel 谱。随后,采用基于 HiFTNet 的 声码器从重建的 Mel 谱合成波形。虚线模型在某些应用中是可选的,例如跨 语言克隆和说话者微调推理。
## 环境配置
### Docker(方法一)
[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=128G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name cosyvoice bash
cd /path/your_code_data/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install --upgrade gradio
sudo apt-get install sox libsox-dev
export PYTHONPATH=third_party/Matcha-TTS
source ~/.bashrc
```
### Dockerfile(方法二)
```
cd /path/your_code_data/docker
docker build --no-cache -t cosyvoice:latest .
docker run --shm-size=128G --name cosyvoice -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v /path/your_code_data/:/path/your_code_data/ -it cosyvoice bash
pip install --upgrade gradio
sudo apt-get install sox libsox-dev
export PYTHONPATH=third_party/Matcha-TTS
source ~/.bashrc
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04
python:python3.10
torch:2.1
torchvision: 0.16.0
deepspped: 0.12.3
gradio:4.42.0
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
conda create -n cosyvoice python=3.10
conda activate cosyvoice
cd /path/your_code_data/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple
pip install --upgrade gradio
sudo apt-get install sox libsox-dev
export PYTHONPATH=third_party/Matcha-TTS
source ~/.bashrc
```
## 数据集
无
## 推理
### 单机单卡
```
python cli_demo.py
```
### 网页web推理
```
python webui.py --port 7860 --model_dir pretrained_models/CosyVoice-300M
```
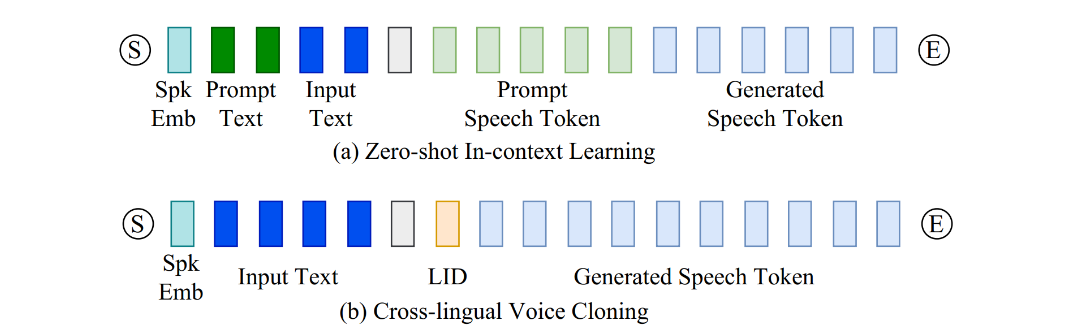
- [cross_lingual_prompt](./cross_lingual_prompt.wav)
- [zero_shot_prompt](./zero_shot_prompt.wav)
## result
### 语音生成
- [cross_lingual_prompt](./cross_lingual_prompt.wav)
- [zero_shot_prompt](./zero_shot_prompt.wav)
### 精度
无
## 应用场景
### 算法类别
`语音生成`
### 热点应用行业
`金融,教育,交通,政府`
## 预训练权重
- [CosyVoice-300M](https://huggingface.co/model-scope/CosyVoice-300M)
- [CosyVoice-300M-Instruct](https://huggingface.co/model-scope/CosyVoice-300M-Instruct)
- [CosyVoice-ttsfrd](https://huggingface.co/FunAudioLLM/CosyVoice-300M-SFT)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/cosyvoice_pytorch
## 参考资料
- [FunAudioLLM/CosyVoice github](https://github.com/FunAudioLLM/CosyVoice)
- [CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer
based on Supervised Semantic Tokens](https://fun-audio-llm.github.io/pdf/CosyVoice_v1.pdf)