
Initial commit
Showing
cli_demo.sh
0 → 100644
finetune_demo/README.md
0 → 100644
finetune_demo/README_zh.md
0 → 100644
finetune_demo/ds_config.yaml
0 → 100644
finetune_demo/peft_infer.py
0 → 100644
finetune_demo/peft_lora.py
0 → 100644
icon.png
0 → 100644
{kind=link}
61 KB
images/architecture.png
0 → 100644
{kind=link}
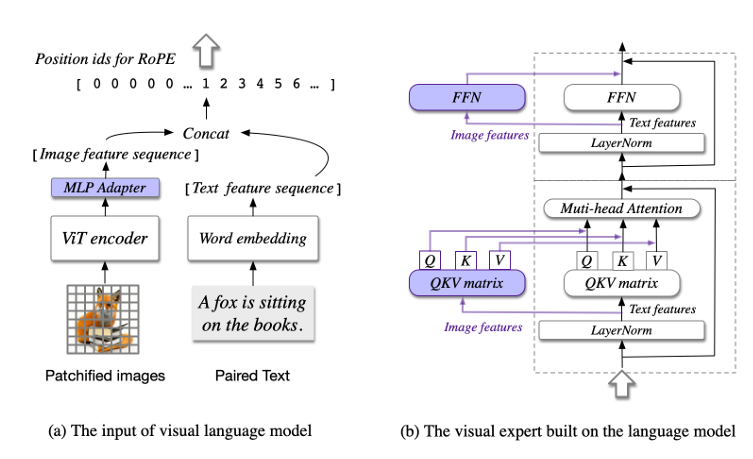
94.6 KB
images/result1.png
0 → 100644
{kind=link}
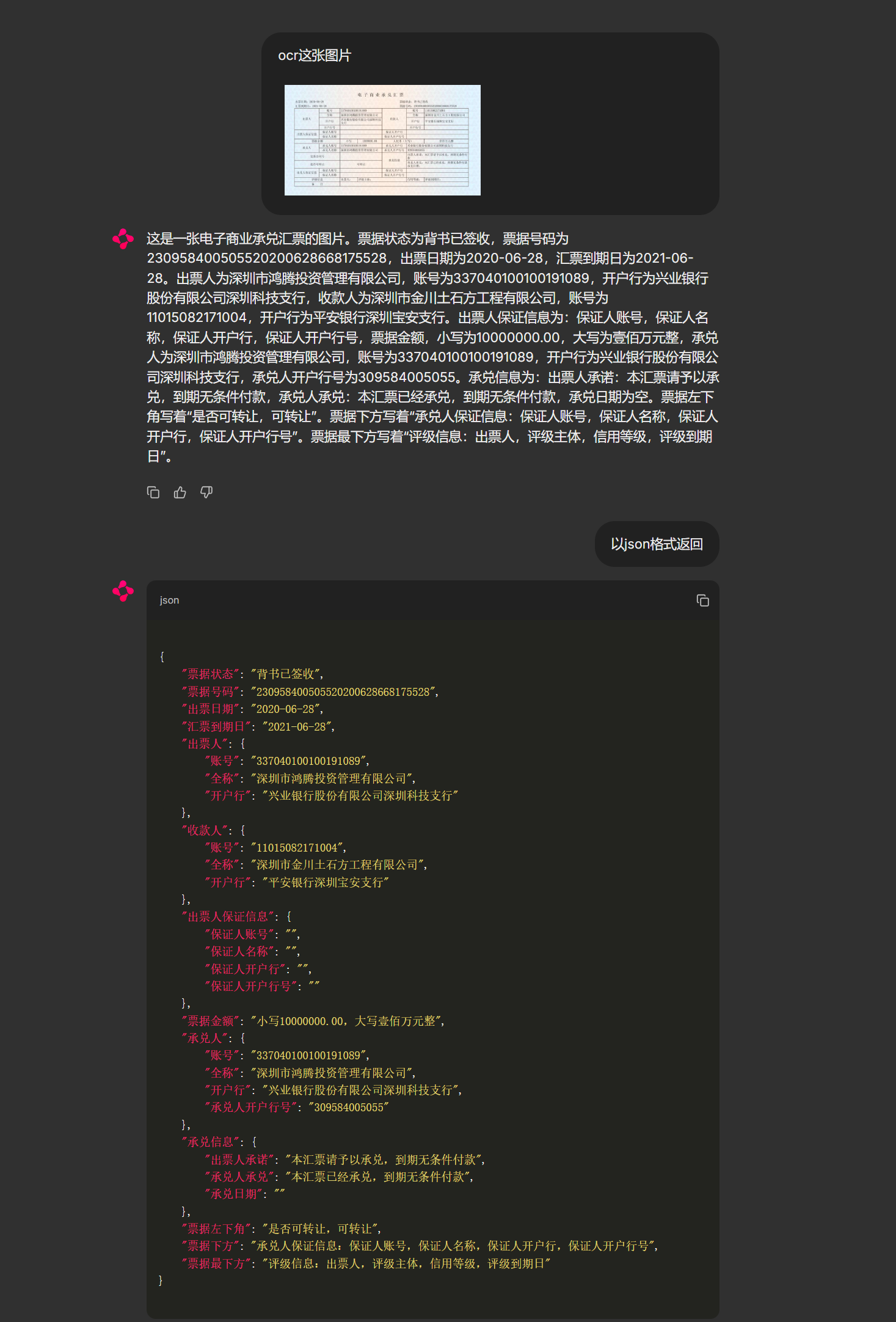
395 KB
images/result2.png
0 → 100644
{kind=link}
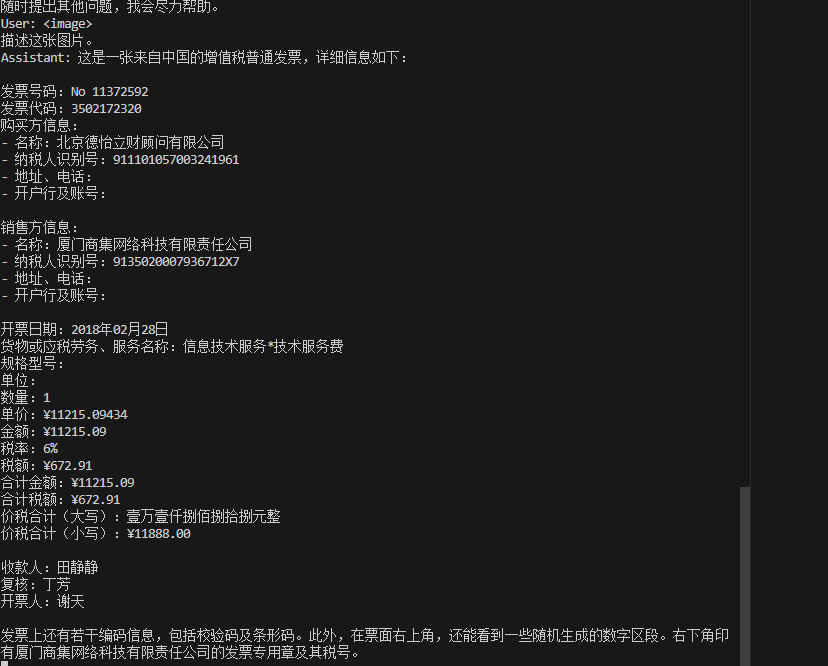
28.9 KB
images/theory.png
0 → 100644
{kind=link}
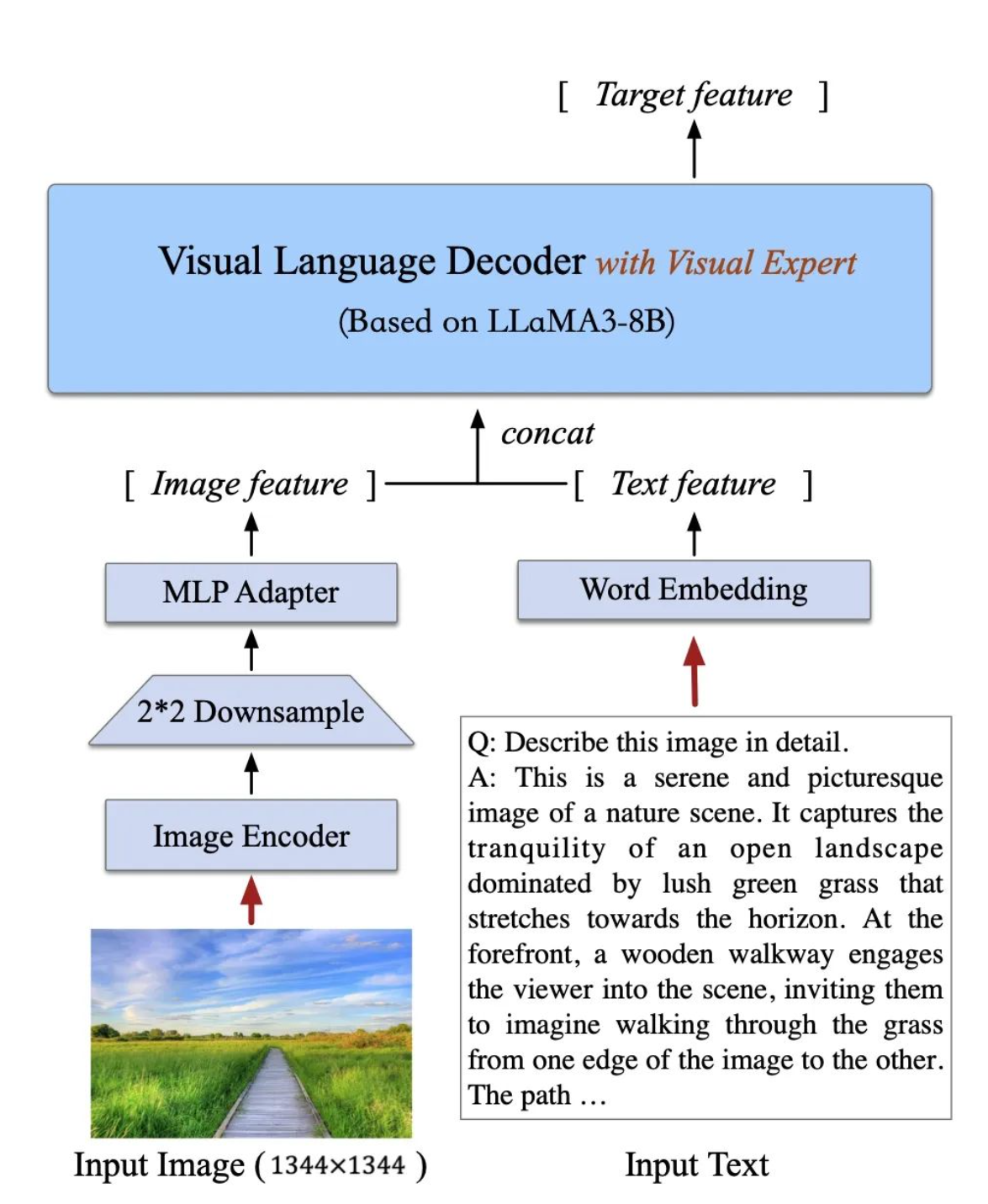
904 KB
model.properties
0 → 100644
requirements.txt
0 → 100644
| peft>=0.10.0 | |||
| deepspeed>=0.14.2 | |||
| mpi4py>=3.1.4 | |||
| tensorboard>=2.16.2 | |||
| xformers | |||
| transformers==4.40.2 | |||
| huggingface-hub>=0.23.0 | |||
| pillow | |||
| chainlit>=1.0 | |||
| pydantic>=2.7.1 | |||
| timm>=0.9.16 | |||
| openai>=1.30.1 | |||
| loguru>=0.7.2 | |||
| pydantic>=2.7.1 | |||
| einops | |||
| sse-starlette | |||
| bitsandbytes |
resources/WECHAT.md
0 → 100644
{kind=link}
1.62 MB
resources/logo.svg
0 → 100644
{kind=link}
File added
resources/videos/lion.mp4
0 → 100644
File added
resources/web_demo.png
0 → 100644
{kind=link}
752 KB