# ChatGLM
## 论文
`GLM: General Language Model Pretraining with Autoregressive Blank Infilling`
- [https://arxiv.org/abs/2103.10360](https://arxiv.org/abs/2103.10360)
## 模型结构
ChatGLM-6B 是清华大学开源的开源的、支持中英双语的对话语言模型,基于 [General Language Model (GLM)](https://github.com/THUDM/GLM) 架构,具有 62 亿参数。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 具有更强大的基础模型、更完整的功能支持、更全面的开源序列。
以下是ChatGLM系列模型的主要网络参数配置:
| 模型名称 | 隐含层维度 | 层数 | 头数 | 词表大小 | 位置编码 | 最大序列长度 |
| ----------- | ---------- | ---- | ---- | -------- | -------- | ------------ |
| ChatGLM2-6B | 4096 | 28 | 32 | 65024 | RoPE | 8192 |
| ChatGLM3-6B | 4096 | 28 | 32 | 65024 | RoPE | 8192 |
| glm-4-9b | 4096 | 40 | 32 | 151552 | RoPE | 131072 |
## 算法原理
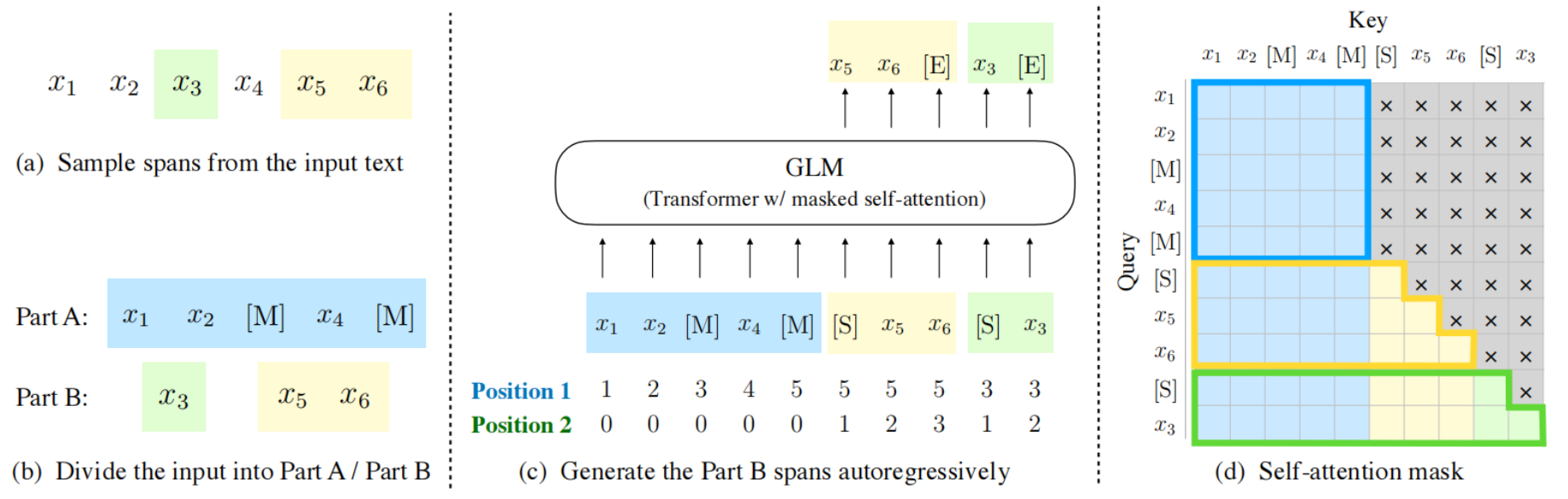
ChatGLM系列模型基于GLM架构开发。GLM是一种基于Transformer的语言模型,以自回归空白填充为训练目标, 同时具备自回归和自编码能力。
## 环境配置
### Docker(方法一)
提供[光源](https://www.sourcefind.cn/#/image/dcu/custom)拉取推理的docker镜像:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/vllm:0.9.2-ubuntu22.04-dtk25.04.1-rc5-rocblas104381-0915-das1.6-py3.10-20250916-rc2
# 用上面拉取docker镜像的ID替换
# 主机端路径
# 容器映射路径
# 若要在主机端和容器端映射端口需要删除--network host参数
docker run -it --name chatglm_vllm --privileged --shm-size=64G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal -v : /bin/bash
```
`Tips:若在K100/Z100L上使用,使用定制镜像docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:vllm0.5.0-dtk24.04.1-ubuntu20.04-py310-zk-v1,K100/Z100L不支持awq量化`
### Dockerfile(方法二)
```
# 主机端路径
# 容器映射路径
docker build -t chatglm:latest .
docker run -it --name chatglm_vllm --privileged --shm-size=64G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v : chatglm:latest /bin/bash
```
### Anaconda(方法三)
```
conda create -n chatglm_vllm python=3.10
```
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
* DTK驱动:dtk25.04.01
* Pytorch: 2.4.0
* triton: 3.0.0
* lmslim: 0.2.1
* flash_attn: 2.6.1
* flash_mla: 1.0.0
* vllm: 0.9.2
* python: python3.10
`Tips:需先安装相关依赖,最后安装vllm包`
环境变量:
export ALLREDUCE_STREAM_WITH_COMPUTE=1
export VLLM_NUMA_BIND=1
export VLLM_RANK0_NUMA=0
export VLLM_RANK1_NUMA=1
export VLLM_RANK2_NUMA=2
export VLLM_RANK3_NUMA=3
export VLLM_RANK4_NUMA=4
export VLLM_RANK5_NUMA=5
export VLLM_RANK6_NUMA=6
export VLLM_RANK7_NUMA=7
## 数据集
无
## 推理
### 模型下载
| 基座模型 | 长文本模型 |
| -------------------------------------------------------- | ---------------------------------------------------------------------- |
| [chatglm2-6b](https://huggingface.co/THUDM/chatglm2-6b) | [chatglm2-6b-32k](https://huggingface.co/THUDM/chatglm2-6b-32k) |
| [chatglm3-6b](https://huggingface.co/THUDM/chatglm3-6b) | [chatglm3-6b-32k](https://huggingface.co/THUDM/chatglm3-6b-32k) |
| [glm-4-9b-chat](https://huggingface.co/THUDM/glm-4-9b-chat) | [glm-4-9b-chat-1m](https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat-1m) |
### 离线批量推理
```bash
python examples/offline_inference/basic/basic.py
```
其中,`prompts`为提示词;`temperature`为控制采样随机性的值,值越小模型生成越确定,值变高模型生成更随机,0表示贪婪采样,默认为1;`max_tokens=16`为生成长度,默认为1;
`model`为模型路径;`tensor_parallel_size=1`为使用卡数,默认为1;`dtype="float16"`为推理数据类型,如果模型权重是bfloat16,需要修改为float16推理,`quantization="gptq"`为使用gptq量化进行推理,需下载以上GPTQ模型。
### 离线批量推理性能测试
1、指定输入输出
```bash
python benchmarks/benchmark_throughput.py --num-prompts 1 --input-len 32 --output-len 128 --model THUDM/glm-4-9b-chat -tp 1 --trust-remote-code --enforce-eager --dtype float16
```
其中 `--num-prompts`是batch数,`--input-len`是输入seqlen,`--output-len`是输出token长度,`--model`为模型路径,`-tp`为使用卡数,`dtype="float16"`为推理数据类型,如果模型权重是bfloat16,需要修改为float16推理。若指定 `--output-len 1`即为首字延迟。`-q gptq`为使用gptq量化模型进行推理。
glm-4-9b-chat-1m模型默认的model_max_length为1024000,官方vllm也尚不支持该长度,模型启动时必须添加--max_model_len(包括后面的启动命令), 经测试,500000左右也可以正常进行推理。
2、使用数据集
下载数据集:
[sharegpt_v3_unfiltered_cleaned_split](https://huggingface.co/datasets/learnanything/sharegpt_v3_unfiltered_cleaned_split)
```bash
python benchmarks/benchmark_throughput.py --num-prompts 1 --model THUDM/glm-4-9b-chat --dataset-name sharegpt --dataset-path /path/to/ShareGPT_V3_unfiltered_cleaned_split.json -tp 1 --trust-remote-code --enforce-eager --dtype float16
```
```bash
python benchmarks/benchmark_throughput.py --num-prompts 1 --model THUDM/glm-4-9b-chat --dataset ShareGPT_V3_unfiltered_cleaned_split.json -tp 1 --trust-remote-code --enforce-eager --dtype float16
```
其中 `--num-prompts`是batch数,`--model`为模型路径,`--dataset`为使用的数据集,`-tp`为使用卡数,`dtype="float16"`为推理数据类型,如果模型权重是bfloat16,需要修改为float16推理。`-q gptq`为使用gptq量化模型进行推理。
### OpenAI api服务推理性能测试
1、启动服务端:
```bash
vllm serve --model THUDM/glm-4-9b-chat --enforce-eager --dtype float16 --trust-remote-code --tensor-parallel-size 1
```
2、启动客户端:
```
python benchmarks/benchmark_serving.py --model THUDM/glm-4-9b-chat --dataset-name sharegpt --dataset-path /path/to/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 1 --trust-remote-code
```
参数同使用数据集,离线批量推理性能测试,具体参考[benchmarks/benchmark_serving.py](benchmarks/benchmark_serving.py)
### OpenAI兼容服务
启动服务:
```bash
vllm serve THUDM/glm-4-9b-chat --enforce-eager --dtype float16 --trust-remote-code
```
这里serve之后 为加载模型路径,`--dtype`为数据类型:float16,默认情况使用tokenizer中的预定义聊天模板,`--chat-template`可以添加新模板覆盖默认模板,`-q gptq`为使用gptq量化模型进行推理。
列出模型型号:
```bash
curl http://localhost:8000/v1/models
```
### OpenAI Completions API和vllm结合使用
```bash
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "THUDM/glm-4-9b-chat",
"prompt": "晚上睡不着怎么办",
"max_tokens": 7,
"temperature": 0
}'
```
或者使用[examples/openai_completion_client.py](examples/openai_completion_client.py)
### OpenAI Chat API和vllm结合使用
```bash
curl http://localhost:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "THUDM/glm-4-9b-chat",
"max_tokens": 128,
"messages": [
{
"role": "user",
"content": "晚上睡不着怎么办"
}
]
}'
```
或者使用[examples/online_serving/openai_chat_completion_client.py](examples/online_serving/openai_chat_completion_client.py)
### **gradio和vllm结合使用**
1.安装gradio
```
pip install gradio
```
2.安装必要文件
2.1 启动gradio服务,根据提示操作
```
python examples/online_serving/gradio_openai_chatbot_webserver.py --model "THUDM/glm-4-9b-chat" --model-url http://localhost:8000/v1 --temp 0.8 --stop-token-ids ""
```
2.2 更改文件权限
打开提示下载文件目录,输入以下命令给予权限
```
chmod +x frpc_linux_amd64_v0.*
```
2.3端口映射
```
ssh -L 8000:计算节点IP:8000 -L 8001:计算节点IP:8001 用户名@登录节点 -p 登录节点端口
```
3.启动OpenAI兼容服务
```
vllm serve THUDM/glm-4-9b-chat --enforce-eager --dtype float16 --trust-remote-code --host "0.0.0.0"
```
4.启动gradio服务
```
python gradio_openai_chatbot_webserver.py --model "THUDM/glm-4-9b-chat" --model-url http://localhost:8000/v1 --temp 0.8 --stop-token-ids --host "0.0.0.0" --port 8001"
```
5.使用对话服务
在浏览器中输入本地 URL,可以使用 Gradio 提供的对话服务。
## result
使用的加速卡:1张 DCU-K100_AI-64G
```
Prompt: '晚上睡不着怎么办', Generated text: '?\n晚上睡不着可以尝试以下方法来改善睡眠质量:\n\n1. **调整作息时间**:尽量每天同一时间上床睡觉和起床,建立规律的生物钟。\n\n2. **放松身心**:睡前进行深呼吸、冥想或瑜伽等放松活动,有助于减轻压力和焦虑。\n\n3. **避免咖啡因和酒精**:晚上避免摄入咖啡因和酒精,因为它们可能会干扰睡眠。\n\n'
```
### 精度
无
## 应用场景
### 算法类别
对话问答
### 热点应用行业
医疗,金融,科研,教育
## 源码仓库及问题反馈
* [https://developer.sourcefind.cn/codes/modelzoo/llama_vllm](https://developer.sourcefind.cn/codes/modelzoo/chatglm_vllm)
## 参考资料
* [https://github.com/vllm-project/vllm](https://github.com/vllm-project/vllm)
* [https://github.com/THUDM/ChatGLM3](https://github.com/THUDM/ChatGLM3)