
Update media/transformers.jpg, media/cli.png, media/结果2.jpg, media/GLM.png,...
Update media/transformers.jpg, media/cli.png, media/结果2.jpg, media/GLM.png, README.md, README.md files
Showing
media/GLM.png
0 → 100644
{kind=link}
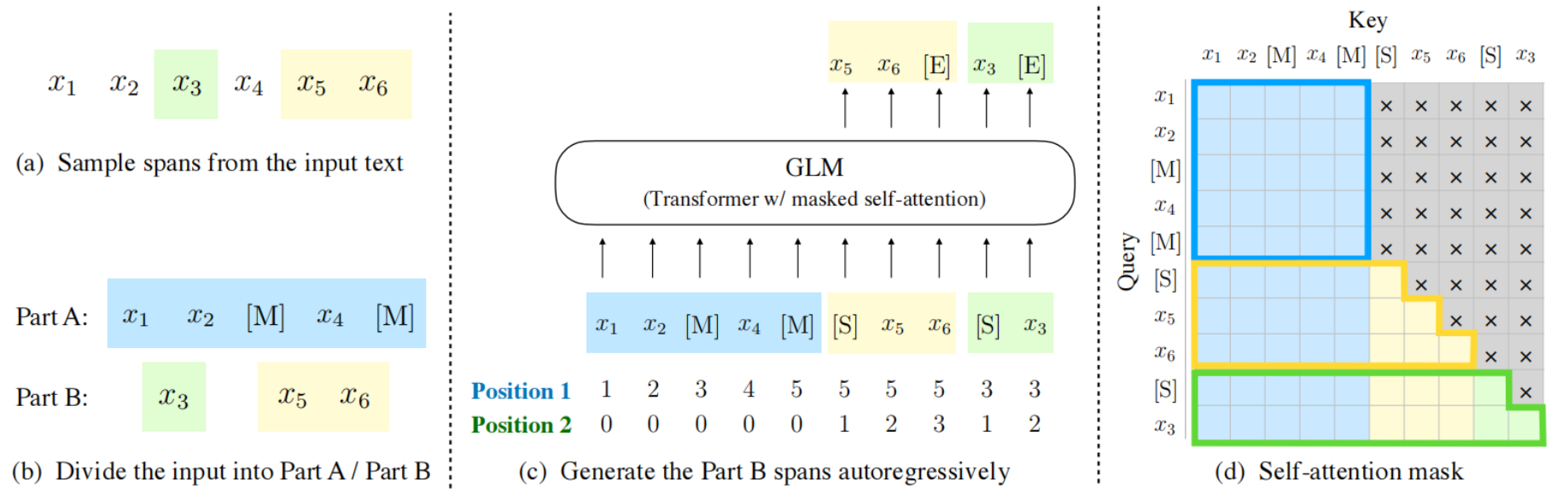
261 KB
media/cli.png
0 → 100644
{kind=link}

55.7 KB
media/transformers.jpg
0 → 100644
{kind=link}
32.7 KB
media/结果2.jpg
0 → 100644
{kind=link}

37.9 KB