# ChatGLM-6B
## 论文
`GLM: General Language Model Pretraining with Autoregressive Blank Infilling`
- [https://arxiv.org/abs/2103.10360](https://arxiv.org/abs/2103.10360)
## 模型结构
ChatGLM-6B 是清华大学开源的开源的、支持中英双语的对话语言模型,基于 [General Language Model (GLM)](https://github.com/THUDM/GLM) 架构,具有 62 亿参数。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。ChatGLM-6B采用Transformer模型结构:
以下是ChatGLM-6B的主要网络参数配置:
| 模型名称 | 隐含层维度 | 层数 | 头数 | 词表大小 | 位置编码 | 最大长 |
| -------- | -------- | -------- | -------- | -------- | -------- | -------- |
|ChatGLM-6B | 4096 | 28 | 32 | 130528 | RoPE | 2048 |
## 算法原理
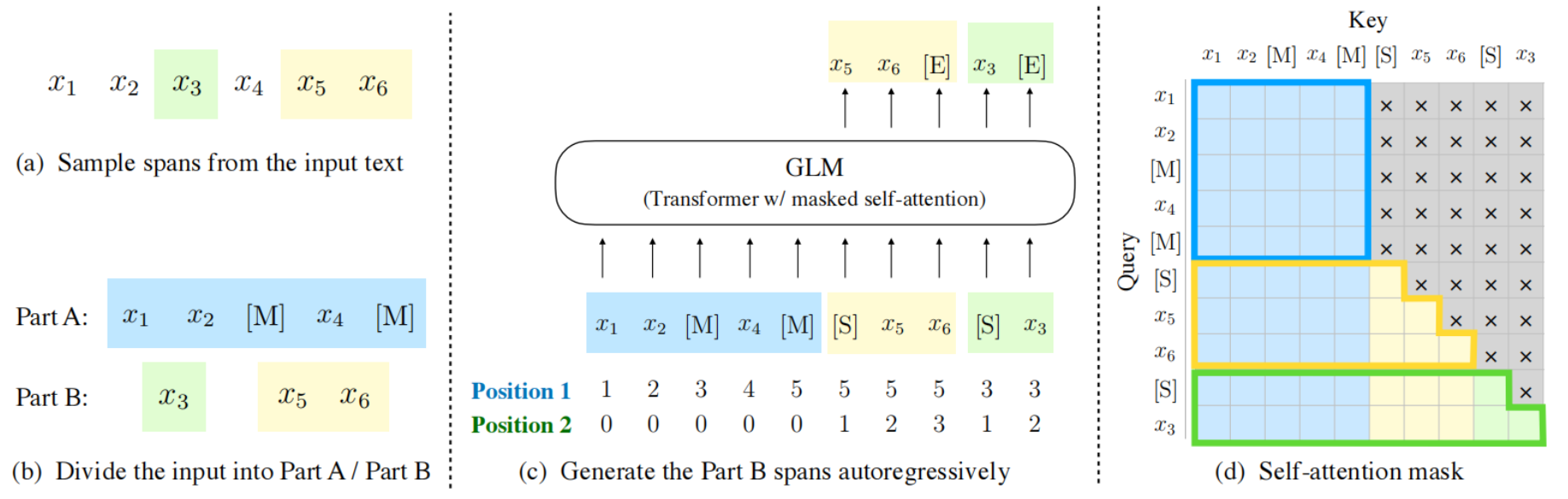
ChatGLM-6B基于GLM架构开发。GLM是一种基于Transformer的语言模型,以自回归空白填充为训练目标, 同时具备自回归和自编码能力。
## 环境配置
### Docker(方式一)
推荐使用docker方式运行,提供拉取的docker镜像:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk24.04-py310
```
进入docker,安装docker中没有的依赖:
```
docker run -dit --network=host --name=chatglm --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 -v /opt/hyhal/:/opt/hyhal/:ro image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk24.04-py310 /usr/sbin/init
docker exec -it chatglm /bin/bash
pip install transformers==4.28.0 -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install accelerate sentencepiece mdtex2html gradio rouge_chinese nltk jieba datasets protobuf peft pydantic==1.10.9 -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
### Dockerfile(方式二)
```
docker build -t chatglm:latest .
docker run -dit --network=host --name=chatglm --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 -v /opt/hyhal/:/opt/hyhal/:ro chatglm:latest
docker exec -it chatglm /bin/bash
```
### Conda(方法三)
1. 创建conda虚拟环境:
```
conda create -n chatglm python=3.10
```
2. 关于本项目DCU显卡所需的工具包、深度学习库等均可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
- [DTK 24.04](https://cancon.hpccube.com:65024/1/main/DTK-24.04)
- [Pytorch 2.1.0](https://cancon.hpccube.com:65024/4/main/pytorch/DAS1.0)
- [Deepspeed 0.12.3](https://cancon.hpccube.com:65024/4/main/deepspeed/DAS1.0)
- [Flash_attn 2.0.4](https://cancon.hpccube.com:65024/4/main/flash_attn/DAS1.0)
- [LightOp 0.3](https://cancon.hpccube.com:65024/4/main/lightop/DAS1.0)
Tips:以上dtk驱动、python、deepspeed等工具版本需要严格一一对应。
3. 其它依赖库参照requirements.txt安装:
```
pip install -r requirements.txt
```
## 数据集
本仓库以 [ADGEN](https://aclanthology.org/D19-1321.pdf) (广告生成) 数据集为例介绍代码的使用方法,该数据集任务为根据输入(content)生成一段广告词(summary),以下为下载地址:
- [Google Drive](https://drive.google.com/file/d/13_vf0xRTQsyneRKdD1bZIr93vBGOczrk/view?usp=sharing) 或者 [Tsinghua Cloud](https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1)
下载处理好的 ADGEN 数据集,将解压后的AdvertiseGen目录放到 [ptuning](./ptuning)本目录下。数据集目录结构如下:
```
── AdvertiseGen
│ ├── dev.json
│ └── train.json
```
### 模型下载
Hugging Face模型下载地址:
[ChatGLM-6B](https://huggingface.co/THUDM/chatglm-6b)
**注意:** 🚨
| 为了获得训练中性能提升,请将所下载预训练模型文件夹中`modeling_chatglm.py`文件替换为本项目[model](./model/)目录下的`modeling_chatglm.py`。需要注意,推理时需使用原`modeling_chatglm.py`内的计算方式。 |
| -------- |
## 训练
### P-tuning v2 微调训练
本仓库实现了对于ChatGLM-6B模型基于[P-Tuning v2](https://github.com/THUDM/P-tuning-v2)的微调。P-Tuning v2是由清华大学提出的一种高效参数微调方法。
#### 单机多卡训练
```
cd ptuning
bash ptuning_train.sh
```
注意:请根据自己的需求配置其中的模型路径、数据集路径、batchsize、学习率等参数;
#### 推理测评
在 P-tuning v2 训练时模型只保存 PrefixEncoder 部分的参数,所以在推理时需要同时加载原 ChatGLM-6B 模型以及 PrefixEncoder 的权重,可直接运行一下命令:
```
cd ptuning
bash evaluate_ptuning.sh
```
#### Results
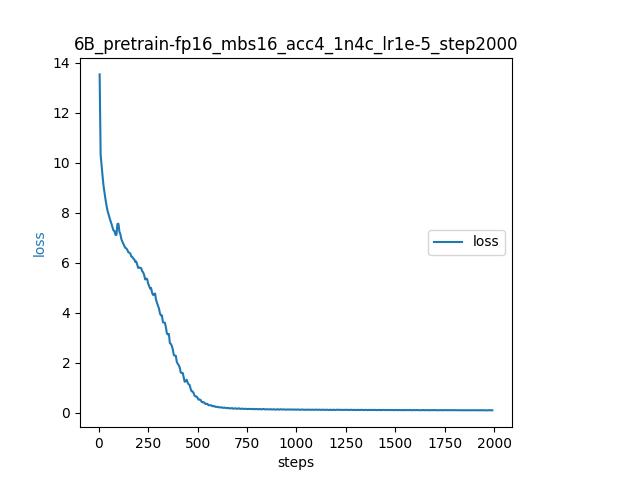
- 训练Loss
- 推理测试结果:
| Checkpoint | Training Loss |BLEU-4 | Rouge-1 | Rouge-2 | Rouge-l |
| :------: | :------: |:------: | :------: |:------: | :------: |
| 2000 steps | 3.57 | 7.9777 | 31.0344 | 6.981 | 24.7393 |
### Finetune全参数微调
#### 单机多卡训练
```
cd ptuning
bash ft_train.sh
```
注意:请根据自己的需求配置其中的模型路径、数据集路径、batchsize、学习率等参数;
#### 集群训练
```
cd ptuning/multi_node
bash run_train.sh
```
注意:请根据自己的需求配置其中的模型路径、数据集路径、batchsize、学习率等参数;
#### 推理测评
```
cd ptuning
bash evaluate_ft.sh
```
#### Results
- 训练Loss
- 推理测试结果:
| Checkpoint | Training Loss |BLEU-4 | Rouge-1 | Rouge-2 | Rouge-l |
| :------: | :------: |:------: | :------: |:------: | :------: |
| 3000 steps | 2.3398 | 7.6501 | 29.2229 | 6.466 | 23.8506 |
### LoRA 微调训练
#### 单机多卡训练
```
cd ptuning
bash lora_train.sh
```
#### LoRA推理
```
python infer_lora.py
```
## 推理
运行如下命令:
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
## Results
- 推理效果如下:
### 重新 pretrain
由于当前的 [GLM-130B](https://github.com/THUDM/GLM-130B#news) 与 ChatGLM 的模型结构非常类似,所以对于有训练 GLM-130B 的用户来说,可以通过修改 ChatGLM 的 config.json 使用堆参数的方式将参数量达到130B。该项目为了满足用户对 ChatGLM 重新 pretrain 的需求,继续添加了 simple-pretrain 目录,旨在提供一种改动最小的 pretrain 示例。pretrain步骤如下:
1. 将 simple-pretrain/ptuning 下的文件移到本 ptuning 目录下,替换相关文件
2. 将 modeling_chatglm.py 移到[ ChatGLM 模型](https://huggingface.co/THUDM/chatglm-6b)所在目录替换原始 modeling_chatglm.py
3. 在本 ptuning 目录下:
```
bash ds_pretrain.sh
```
说明:convert.py 可以将原始的txt数据转换成 chatglm 可用的 json 形式的数据集格式。该示例使用指环王1书籍作为预训练数据集。
#### 实验设置
```
LR=1e-5
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
HIP_VISIBLE_DEVICES=0,1,2,3 deepspeed --num_gpus=4 --master_port $MASTER_PORT main.py \
--deepspeed deepspeed.json \
--do_train \
--train_file The-Lord-of-the-Rings-1.json \
--prompt_column prompt \
--response_column response \
--overwrite_cache \
--model_name_or_path THUDM/chatglm-6b \
--output_dir ./output/pretrain \
--overwrite_output_dir \
--max_source_length 8 \
--max_target_length 128 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 4 \
--predict_with_generate \
--max_steps 2000 \
--logging_steps 5 \
--save_steps 1000 \
--learning_rate $LR \
--fp16
```
#### 精度
由于该示例预训练数据集较小,loss会降的至较低水平到0.1左右。
### 强化学习(RLHF)微调方案
目前在 DCU 上 ChatGLM 使用强化学习微调有两种方案可以走通:
- 使用 Lora,只更新低秩适应层,可以直接参考项目:https://github.com/hiyouga/ChatGLM-Efficient-Tuning/blob/main/examples/covid_doctor.md
- 使用 DeepSpeed-Chat 方案全参微调,目前已经适配完成,欢迎尝试:https://github.com/yuguo-Jack/ChatGLM-6B-in-DeepSpeed-Chat
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`医疗,教育,科研,金融`
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/chatglm
## 参考资料
- [THUDM/ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B/tree/main)