Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
CenterFace_pytorch
Commits
b952e97b
Commit
b952e97b
authored
Nov 03, 2023
by
chenych
Browse files
First Commit.
parents
Changes
175
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
4719 additions
and
0 deletions
+4719
-0
src/lib/models/Backbone/efficientdet/retinahead.py
src/lib/models/Backbone/efficientdet/retinahead.py
+106
-0
src/lib/models/Backbone/efficientdet/utils.py
src/lib/models/Backbone/efficientdet/utils.py
+311
-0
src/lib/models/Backbone/hardnet.py
src/lib/models/Backbone/hardnet.py
+188
-0
src/lib/models/Backbone/large_hourglass.py
src/lib/models/Backbone/large_hourglass.py
+299
-0
src/lib/models/Backbone/mobilenet_v2.py
src/lib/models/Backbone/mobilenet_v2.py
+287
-0
src/lib/models/Backbone/mobilenetv2.py
src/lib/models/Backbone/mobilenetv2.py
+260
-0
src/lib/models/Backbone/mobilenetv3.py
src/lib/models/Backbone/mobilenetv3.py
+203
-0
src/lib/models/Backbone/msra_resnet.py
src/lib/models/Backbone/msra_resnet.py
+249
-0
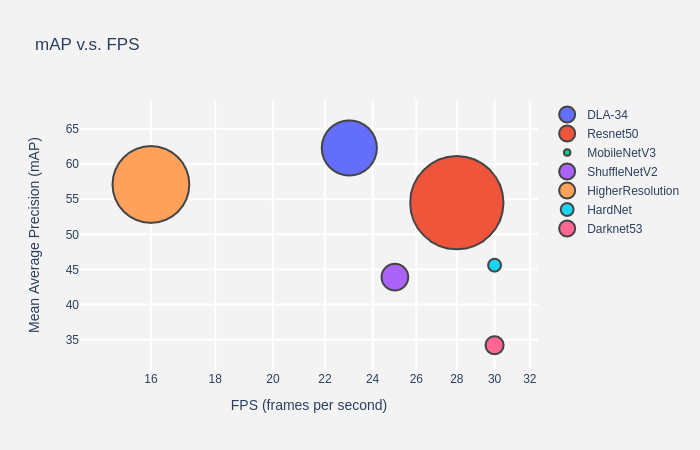
src/lib/models/Backbone/performance.png
src/lib/models/Backbone/performance.png
+0
-0
src/lib/models/Backbone/pose_dla_dcn.py
src/lib/models/Backbone/pose_dla_dcn.py
+456
-0
src/lib/models/Backbone/pose_higher_hrnet.py
src/lib/models/Backbone/pose_higher_hrnet.py
+550
-0
src/lib/models/Backbone/resnet_dcn.py
src/lib/models/Backbone/resnet_dcn.py
+289
-0
src/lib/models/Backbone/shufflenetv2_dcn.py
src/lib/models/Backbone/shufflenetv2_dcn.py
+263
-0
src/lib/models/data_parallel.py
src/lib/models/data_parallel.py
+129
-0
src/lib/models/decode.py
src/lib/models/decode.py
+684
-0
src/lib/models/losses.py
src/lib/models/losses.py
+250
-0
src/lib/models/model.py
src/lib/models/model.py
+98
-0
src/lib/models/networks/DCNv2/.gitignore
src/lib/models/networks/DCNv2/.gitignore
+7
-0
src/lib/models/networks/DCNv2/LICENSE
src/lib/models/networks/DCNv2/LICENSE
+29
-0
src/lib/models/networks/DCNv2/README.md
src/lib/models/networks/DCNv2/README.md
+61
-0
No files found.
src/lib/models/Backbone/efficientdet/retinahead.py
0 → 100644
View file @
b952e97b
import
numpy
as
np
import
torch.nn
as
nn
from
.conv_module
import
ConvModule
,
bias_init_with_prob
,
normal_init
from
six.moves
import
map
,
zip
def
multi_apply
(
func
,
*
args
,
**
kwargs
):
pfunc
=
partial
(
func
,
**
kwargs
)
if
kwargs
else
func
map_results
=
map
(
pfunc
,
*
args
)
return
tuple
(
map
(
list
,
zip
(
*
map_results
)))
class
RetinaHead
(
nn
.
Module
):
"""
An anchor-based head used in [1]_.
The head contains two subnetworks. The first classifies anchor boxes and
the second regresses deltas for the anchors.
References:
.. [1] https://arxiv.org/pdf/1708.02002.pdf
Example:
>>> import torch
>>> self = RetinaHead(11, 7)
>>> x = torch.rand(1, 7, 32, 32)
>>> cls_score, bbox_pred = self.forward_single(x)
>>> # Each anchor predicts a score for each class except background
>>> cls_per_anchor = cls_score.shape[1] / self.num_anchors
>>> box_per_anchor = bbox_pred.shape[1] / self.num_anchors
>>> assert cls_per_anchor == (self.num_classes - 1)
>>> assert box_per_anchor == 4
"""
def
__init__
(
self
,
num_classes
,
in_channels
,
feat_channels
=
64
,
stacked_convs
=
4
,
octave_base_scale
=
4
,
scales_per_octave
=
3
,
conv_cfg
=
None
,
norm_cfg
=
None
,
**
kwargs
):
super
(
RetinaHead
,
self
).
__init__
()
self
.
in_channels
=
in_channels
self
.
num_classes
=
num_classes
self
.
feat_channels
=
feat_channels
self
.
stacked_convs
=
stacked_convs
self
.
octave_base_scale
=
octave_base_scale
self
.
scales_per_octave
=
scales_per_octave
self
.
conv_cfg
=
conv_cfg
self
.
norm_cfg
=
norm_cfg
octave_scales
=
np
.
array
(
[
2
**
(
i
/
scales_per_octave
)
for
i
in
range
(
scales_per_octave
)])
self
.
cls_out_channels
=
num_classes
self
.
_init_layers
()
def
_init_layers
(
self
):
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
cls_convs
=
nn
.
ModuleList
()
#self.reg_convs = nn.ModuleList()
for
i
in
range
(
self
.
stacked_convs
):
chn
=
self
.
in_channels
if
i
==
0
else
self
.
feat_channels
self
.
cls_convs
.
append
(
ConvModule
(
chn
,
self
.
feat_channels
,
3
,
stride
=
1
,
padding
=
1
,
conv_cfg
=
self
.
conv_cfg
,
norm_cfg
=
self
.
norm_cfg
))
self
.
retina_cls
=
nn
.
Conv2d
(
self
.
feat_channels
,
self
.
cls_out_channels
,
3
,
padding
=
1
)
#self.output_act = nn.Sigmoid()
def
init_weights
(
self
):
for
m
in
self
.
cls_convs
:
normal_init
(
m
.
conv
,
std
=
0.01
)
for
m
in
self
.
reg_convs
:
normal_init
(
m
.
conv
,
std
=
0.01
)
bias_cls
=
bias_init_with_prob
(
0.01
)
normal_init
(
self
.
retina_cls
,
std
=
0.01
,
bias
=
bias_cls
)
#normal_init(self.retina_reg, std=0.01)
def
forward_single
(
self
,
x
):
cls_feat
=
x
#reg_feat = x
for
cls_conv
in
self
.
cls_convs
:
cls_feat
=
cls_conv
(
cls_feat
)
#for reg_conv in self.reg_convs:
# reg_feat = reg_conv(reg_feat)
cls_score
=
self
.
retina_cls
(
cls_feat
)
# out is B x C x W x H, with C = n_classes + n_anchors
#cls_score = cls_score.permute(0, 2, 3, 1)
#batch_size, width, height, channels = cls_score.shape
#cls_score = cls_score.view(batch_size, width, height, self.num_anchors, self.num_classes)
#cls_score = cls_score.contiguous().view(x.size(0), -1, self.num_classes)
#bbox_pred = self.retina_reg(reg_feat)
#bbox_pred = bbox_pred.permute(0, 2, 3, 1)
#bbox_pred = bbox_pred.contiguous().view(bbox_pred.size(0), -1, 4)
return
[
cls_score
]
def
forward
(
self
,
feats
):
return
multi_apply
(
self
.
forward_single
,
feats
)
src/lib/models/Backbone/efficientdet/utils.py
0 → 100644
View file @
b952e97b
import
re
import
math
import
collections
from
functools
import
partial
import
torch
from
torch
import
nn
from
torch.nn
import
functional
as
F
from
torch.utils
import
model_zoo
########################################################################
############### HELPERS FUNCTIONS FOR MODEL ARCHITECTURE ###############
########################################################################
# Parameters for the entire model (stem, all blocks, and head)
GlobalParams
=
collections
.
namedtuple
(
'GlobalParams'
,
[
'batch_norm_momentum'
,
'batch_norm_epsilon'
,
'dropout_rate'
,
'num_classes'
,
'width_coefficient'
,
'depth_coefficient'
,
'depth_divisor'
,
'min_depth'
,
'drop_connect_rate'
,
'image_size'
])
# Parameters for an individual model block
BlockArgs
=
collections
.
namedtuple
(
'BlockArgs'
,
[
'kernel_size'
,
'num_repeat'
,
'input_filters'
,
'output_filters'
,
'expand_ratio'
,
'id_skip'
,
'stride'
,
'se_ratio'
])
# Change namedtuple defaults
GlobalParams
.
__new__
.
__defaults__
=
(
None
,)
*
len
(
GlobalParams
.
_fields
)
BlockArgs
.
__new__
.
__defaults__
=
(
None
,)
*
len
(
BlockArgs
.
_fields
)
class
SwishImplementation
(
torch
.
autograd
.
Function
):
@
staticmethod
def
forward
(
ctx
,
i
):
result
=
i
*
torch
.
sigmoid
(
i
)
ctx
.
save_for_backward
(
i
)
return
result
@
staticmethod
def
backward
(
ctx
,
grad_output
):
i
=
ctx
.
saved_variables
[
0
]
sigmoid_i
=
torch
.
sigmoid
(
i
)
return
grad_output
*
(
sigmoid_i
*
(
1
+
i
*
(
1
-
sigmoid_i
)))
class
MemoryEfficientSwish
(
nn
.
Module
):
def
forward
(
self
,
x
):
return
SwishImplementation
.
apply
(
x
)
class
Swish
(
nn
.
Module
):
def
forward
(
self
,
x
):
return
x
*
torch
.
sigmoid
(
x
)
def
round_filters
(
filters
,
global_params
):
""" Calculate and round number of filters based on depth multiplier. """
multiplier
=
global_params
.
width_coefficient
if
not
multiplier
:
return
filters
divisor
=
global_params
.
depth_divisor
min_depth
=
global_params
.
min_depth
filters
*=
multiplier
min_depth
=
min_depth
or
divisor
new_filters
=
max
(
min_depth
,
int
(
filters
+
divisor
/
2
)
//
divisor
*
divisor
)
if
new_filters
<
0.9
*
filters
:
# prevent rounding by more than 10%
new_filters
+=
divisor
return
int
(
new_filters
)
def
round_repeats
(
repeats
,
global_params
):
""" Round number of filters based on depth multiplier. """
multiplier
=
global_params
.
depth_coefficient
if
not
multiplier
:
return
repeats
return
int
(
math
.
ceil
(
multiplier
*
repeats
))
def
drop_connect
(
inputs
,
p
,
training
):
""" Drop connect. """
if
not
training
:
return
inputs
batch_size
=
inputs
.
shape
[
0
]
keep_prob
=
1
-
p
random_tensor
=
keep_prob
random_tensor
+=
torch
.
rand
([
batch_size
,
1
,
1
,
1
],
dtype
=
inputs
.
dtype
,
device
=
inputs
.
device
)
binary_tensor
=
torch
.
floor
(
random_tensor
)
output
=
inputs
/
keep_prob
*
binary_tensor
return
output
def
get_same_padding_conv2d
(
image_size
=
None
):
""" Chooses static padding if you have specified an image size, and dynamic padding otherwise.
Static padding is necessary for ONNX exporting of models. """
if
image_size
is
None
:
return
Conv2dDynamicSamePadding
else
:
return
partial
(
Conv2dStaticSamePadding
,
image_size
=
image_size
)
class
Conv2dDynamicSamePadding
(
nn
.
Conv2d
):
""" 2D Convolutions like TensorFlow, for a dynamic image size """
def
__init__
(
self
,
in_channels
,
out_channels
,
kernel_size
,
stride
=
1
,
dilation
=
1
,
groups
=
1
,
bias
=
True
):
super
().
__init__
(
in_channels
,
out_channels
,
kernel_size
,
stride
,
0
,
dilation
,
groups
,
bias
)
self
.
stride
=
self
.
stride
if
len
(
self
.
stride
)
==
2
else
[
self
.
stride
[
0
]]
*
2
def
forward
(
self
,
x
):
ih
,
iw
=
x
.
size
()[
-
2
:]
kh
,
kw
=
self
.
weight
.
size
()[
-
2
:]
sh
,
sw
=
self
.
stride
oh
,
ow
=
math
.
ceil
(
ih
/
sh
),
math
.
ceil
(
iw
/
sw
)
pad_h
=
max
((
oh
-
1
)
*
self
.
stride
[
0
]
+
(
kh
-
1
)
*
self
.
dilation
[
0
]
+
1
-
ih
,
0
)
pad_w
=
max
((
ow
-
1
)
*
self
.
stride
[
1
]
+
(
kw
-
1
)
*
self
.
dilation
[
1
]
+
1
-
iw
,
0
)
if
pad_h
>
0
or
pad_w
>
0
:
x
=
F
.
pad
(
x
,
[
pad_w
//
2
,
pad_w
-
pad_w
//
2
,
pad_h
//
2
,
pad_h
-
pad_h
//
2
])
return
F
.
conv2d
(
x
,
self
.
weight
,
self
.
bias
,
self
.
stride
,
self
.
padding
,
self
.
dilation
,
self
.
groups
)
class
Conv2dStaticSamePadding
(
nn
.
Conv2d
):
""" 2D Convolutions like TensorFlow, for a fixed image size"""
def
__init__
(
self
,
in_channels
,
out_channels
,
kernel_size
,
image_size
=
None
,
**
kwargs
):
super
().
__init__
(
in_channels
,
out_channels
,
kernel_size
,
**
kwargs
)
self
.
stride
=
self
.
stride
if
len
(
self
.
stride
)
==
2
else
[
self
.
stride
[
0
]]
*
2
# Calculate padding based on image size and save it
assert
image_size
is
not
None
ih
,
iw
=
image_size
if
type
(
image_size
)
==
list
else
[
image_size
,
image_size
]
kh
,
kw
=
self
.
weight
.
size
()[
-
2
:]
sh
,
sw
=
self
.
stride
oh
,
ow
=
math
.
ceil
(
ih
/
sh
),
math
.
ceil
(
iw
/
sw
)
pad_h
=
max
((
oh
-
1
)
*
self
.
stride
[
0
]
+
(
kh
-
1
)
*
self
.
dilation
[
0
]
+
1
-
ih
,
0
)
pad_w
=
max
((
ow
-
1
)
*
self
.
stride
[
1
]
+
(
kw
-
1
)
*
self
.
dilation
[
1
]
+
1
-
iw
,
0
)
if
pad_h
>
0
or
pad_w
>
0
:
self
.
static_padding
=
nn
.
ZeroPad2d
((
pad_w
//
2
,
pad_w
-
pad_w
//
2
,
pad_h
//
2
,
pad_h
-
pad_h
//
2
))
else
:
self
.
static_padding
=
Identity
()
def
forward
(
self
,
x
):
x
=
self
.
static_padding
(
x
)
x
=
F
.
conv2d
(
x
,
self
.
weight
,
self
.
bias
,
self
.
stride
,
self
.
padding
,
self
.
dilation
,
self
.
groups
)
return
x
class
Identity
(
nn
.
Module
):
def
__init__
(
self
,
):
super
(
Identity
,
self
).
__init__
()
def
forward
(
self
,
input
):
return
input
########################################################################
############## HELPERS FUNCTIONS FOR LOADING MODEL PARAMS ##############
########################################################################
def
efficientnet_params
(
model_name
):
""" Map EfficientNet model name to parameter coefficients. """
params_dict
=
{
# Coefficients: width,depth,res,dropout
'efficientnet-b0'
:
(
1.0
,
1.0
,
224
,
0.2
),
'efficientnet-b1'
:
(
1.0
,
1.1
,
240
,
0.2
),
'efficientnet-b2'
:
(
1.1
,
1.2
,
260
,
0.3
),
'efficientnet-b3'
:
(
1.2
,
1.4
,
300
,
0.3
),
'efficientnet-b4'
:
(
1.4
,
1.8
,
380
,
0.4
),
'efficientnet-b5'
:
(
1.6
,
2.2
,
456
,
0.4
),
'efficientnet-b6'
:
(
1.8
,
2.6
,
528
,
0.5
),
'efficientnet-b7'
:
(
2.0
,
3.1
,
600
,
0.5
),
}
return
params_dict
[
model_name
]
class
BlockDecoder
(
object
):
""" Block Decoder for readability, straight from the official TensorFlow repository """
@
staticmethod
def
_decode_block_string
(
block_string
):
""" Gets a block through a string notation of arguments. """
assert
isinstance
(
block_string
,
str
)
ops
=
block_string
.
split
(
'_'
)
options
=
{}
for
op
in
ops
:
splits
=
re
.
split
(
r
'(\d.*)'
,
op
)
if
len
(
splits
)
>=
2
:
key
,
value
=
splits
[:
2
]
options
[
key
]
=
value
# Check stride
assert
((
's'
in
options
and
len
(
options
[
's'
])
==
1
)
or
(
len
(
options
[
's'
])
==
2
and
options
[
's'
][
0
]
==
options
[
's'
][
1
]))
return
BlockArgs
(
kernel_size
=
int
(
options
[
'k'
]),
num_repeat
=
int
(
options
[
'r'
]),
input_filters
=
int
(
options
[
'i'
]),
output_filters
=
int
(
options
[
'o'
]),
expand_ratio
=
int
(
options
[
'e'
]),
id_skip
=
(
'noskip'
not
in
block_string
),
se_ratio
=
float
(
options
[
'se'
])
if
'se'
in
options
else
None
,
stride
=
[
int
(
options
[
's'
][
0
])])
@
staticmethod
def
_encode_block_string
(
block
):
"""Encodes a block to a string."""
args
=
[
'r%d'
%
block
.
num_repeat
,
'k%d'
%
block
.
kernel_size
,
's%d%d'
%
(
block
.
strides
[
0
],
block
.
strides
[
1
]),
'e%s'
%
block
.
expand_ratio
,
'i%d'
%
block
.
input_filters
,
'o%d'
%
block
.
output_filters
]
if
0
<
block
.
se_ratio
<=
1
:
args
.
append
(
'se%s'
%
block
.
se_ratio
)
if
block
.
id_skip
is
False
:
args
.
append
(
'noskip'
)
return
'_'
.
join
(
args
)
@
staticmethod
def
decode
(
string_list
):
"""
Decodes a list of string notations to specify blocks inside the network.
:param string_list: a list of strings, each string is a notation of block
:return: a list of BlockArgs namedtuples of block args
"""
assert
isinstance
(
string_list
,
list
)
blocks_args
=
[]
for
block_string
in
string_list
:
blocks_args
.
append
(
BlockDecoder
.
_decode_block_string
(
block_string
))
return
blocks_args
@
staticmethod
def
encode
(
blocks_args
):
"""
Encodes a list of BlockArgs to a list of strings.
:param blocks_args: a list of BlockArgs namedtuples of block args
:return: a list of strings, each string is a notation of block
"""
block_strings
=
[]
for
block
in
blocks_args
:
block_strings
.
append
(
BlockDecoder
.
_encode_block_string
(
block
))
return
block_strings
def
efficientnet
(
width_coefficient
=
None
,
depth_coefficient
=
None
,
dropout_rate
=
0.2
,
drop_connect_rate
=
0.2
,
image_size
=
None
,
num_classes
=
1000
):
""" Creates a efficientnet model. """
blocks_args
=
[
'r1_k3_s11_e1_i32_o16_se0.25'
,
'r2_k3_s22_e6_i16_o24_se0.25'
,
'r2_k5_s22_e6_i24_o40_se0.25'
,
'r3_k3_s22_e6_i40_o80_se0.25'
,
'r3_k5_s22_e6_i80_o112_se0.25'
,
'r4_k5_s22_e6_i112_o192_se0.25'
,
'r1_k3_s22_e6_i192_o320_se0.25'
,
]
blocks_args
=
BlockDecoder
.
decode
(
blocks_args
)
global_params
=
GlobalParams
(
batch_norm_momentum
=
0.99
,
batch_norm_epsilon
=
1e-3
,
dropout_rate
=
dropout_rate
,
drop_connect_rate
=
drop_connect_rate
,
# data_format='channels_last', # removed, this is always true in PyTorch
num_classes
=
num_classes
,
width_coefficient
=
width_coefficient
,
depth_coefficient
=
depth_coefficient
,
depth_divisor
=
8
,
min_depth
=
None
,
image_size
=
image_size
,
)
return
blocks_args
,
global_params
def
get_model_params
(
model_name
,
override_params
):
""" Get the block args and global params for a given model """
if
model_name
.
startswith
(
'efficientnet'
):
w
,
d
,
s
,
p
=
efficientnet_params
(
model_name
)
# note: all models have drop connect rate = 0.2
blocks_args
,
global_params
=
efficientnet
(
width_coefficient
=
w
,
depth_coefficient
=
d
,
dropout_rate
=
p
,
image_size
=
s
)
else
:
raise
NotImplementedError
(
'model name is not pre-defined: %s'
%
model_name
)
if
override_params
:
# ValueError will be raised here if override_params has fields not included in global_params.
global_params
=
global_params
.
_replace
(
**
override_params
)
return
blocks_args
,
global_params
url_map
=
{
'efficientnet-b0'
:
'http://storage.googleapis.com/public-models/efficientnet/efficientnet-b0-355c32eb.pth'
,
'efficientnet-b1'
:
'http://storage.googleapis.com/public-models/efficientnet/efficientnet-b1-f1951068.pth'
,
'efficientnet-b2'
:
'http://storage.googleapis.com/public-models/efficientnet/efficientnet-b2-8bb594d6.pth'
,
'efficientnet-b3'
:
'http://storage.googleapis.com/public-models/efficientnet/efficientnet-b3-5fb5a3c3.pth'
,
'efficientnet-b4'
:
'http://storage.googleapis.com/public-models/efficientnet/efficientnet-b4-6ed6700e.pth'
,
'efficientnet-b5'
:
'http://storage.googleapis.com/public-models/efficientnet/efficientnet-b5-b6417697.pth'
,
'efficientnet-b6'
:
'http://storage.googleapis.com/public-models/efficientnet/efficientnet-b6-c76e70fd.pth'
,
'efficientnet-b7'
:
'http://storage.googleapis.com/public-models/efficientnet/efficientnet-b7-dcc49843.pth'
,
}
def
load_pretrained_weights
(
model
,
model_name
,
load_fc
=
True
):
""" Loads pretrained weights, and downloads if loading for the first time. """
state_dict
=
model_zoo
.
load_url
(
url_map
[
model_name
],
map_location
=
lambda
storage
,
loc
:
storage
)
if
load_fc
:
model
.
load_state_dict
(
state_dict
)
else
:
state_dict
.
pop
(
'_fc.weight'
)
state_dict
.
pop
(
'_fc.bias'
)
res
=
model
.
load_state_dict
(
state_dict
,
strict
=
False
)
assert
set
(
res
.
missing_keys
)
==
set
([
'_fc.weight'
,
'_fc.bias'
]),
'issue loading pretrained weights'
print
(
'Loaded pretrained weights for {}'
.
format
(
model_name
))
src/lib/models/Backbone/hardnet.py
0 → 100644
View file @
b952e97b
import
numpy
as
np
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
class
ConvLayer
(
nn
.
Sequential
):
def
__init__
(
self
,
in_channels
,
out_channels
,
kernel
=
3
,
stride
=
1
,
dropout
=
0.1
):
super
().
__init__
()
self
.
add_module
(
'conv'
,
nn
.
Conv2d
(
in_channels
,
out_channels
,
kernel_size
=
kernel
,
stride
=
stride
,
padding
=
kernel
//
2
,
bias
=
False
))
self
.
add_module
(
'norm'
,
nn
.
BatchNorm2d
(
out_channels
))
self
.
add_module
(
'relu'
,
nn
.
ReLU
(
inplace
=
True
))
def
forward
(
self
,
x
):
return
super
().
forward
(
x
)
class
HarDBlock
(
nn
.
Module
):
def
get_link
(
self
,
layer
,
base_ch
,
growth_rate
,
grmul
):
if
layer
==
0
:
return
base_ch
,
0
,
[]
out_channels
=
growth_rate
link
=
[]
for
i
in
range
(
10
):
dv
=
2
**
i
if
layer
%
dv
==
0
:
k
=
layer
-
dv
link
.
append
(
k
)
if
i
>
0
:
out_channels
*=
grmul
out_channels
=
int
(
int
(
out_channels
+
1
)
/
2
)
*
2
in_channels
=
0
for
i
in
link
:
ch
,
_
,
_
=
self
.
get_link
(
i
,
base_ch
,
growth_rate
,
grmul
)
in_channels
+=
ch
return
out_channels
,
in_channels
,
link
def
get_out_ch
(
self
):
return
self
.
out_channels
def
__init__
(
self
,
in_channels
,
growth_rate
,
grmul
,
n_layers
,
keepBase
=
False
,
residual_out
=
False
):
super
().
__init__
()
self
.
keepBase
=
keepBase
self
.
links
=
[]
layers_
=
[]
self
.
out_channels
=
0
# if upsample else in_channels
for
i
in
range
(
n_layers
):
outch
,
inch
,
link
=
self
.
get_link
(
i
+
1
,
in_channels
,
growth_rate
,
grmul
)
self
.
links
.
append
(
link
)
use_relu
=
residual_out
layers_
.
append
(
ConvLayer
(
inch
,
outch
))
if
(
i
%
2
==
0
)
or
(
i
==
n_layers
-
1
):
self
.
out_channels
+=
outch
#print("Blk out =",self.out_channels)
self
.
layers
=
nn
.
ModuleList
(
layers_
)
def
forward
(
self
,
x
):
layers_
=
[
x
]
for
layer
in
range
(
len
(
self
.
layers
)):
link
=
self
.
links
[
layer
]
tin
=
[]
for
i
in
link
:
tin
.
append
(
layers_
[
i
])
if
len
(
tin
)
>
1
:
x
=
torch
.
cat
(
tin
,
1
)
else
:
x
=
tin
[
0
]
out
=
self
.
layers
[
layer
](
x
)
layers_
.
append
(
out
)
t
=
len
(
layers_
)
out_
=
[]
for
i
in
range
(
t
):
if
(
i
==
0
and
self
.
keepBase
)
or
\
(
i
==
t
-
1
)
or
(
i
%
2
==
1
):
out_
.
append
(
layers_
[
i
])
out
=
torch
.
cat
(
out_
,
1
)
return
out
class
TransitionUp
(
nn
.
Module
):
def
__init__
(
self
,
in_channels
,
out_channels
):
super
().
__init__
()
#print("upsample",in_channels, out_channels)
def
forward
(
self
,
x
,
skip
,
concat
=
True
):
out
=
F
.
interpolate
(
x
,
size
=
(
skip
.
size
(
2
),
skip
.
size
(
3
)),
mode
=
"bilinear"
,
align_corners
=
True
,
)
if
concat
:
out
=
torch
.
cat
([
out
,
skip
],
1
)
return
out
class
hardnet
(
nn
.
Module
):
def
__init__
(
self
):
super
(
hardnet
,
self
).
__init__
()
first_ch
=
[
16
,
24
,
32
,
48
]
ch_list
=
[
64
,
96
,
160
,
224
,
320
]
grmul
=
1.7
gr
=
[
10
,
16
,
18
,
24
,
32
]
n_layers
=
[
4
,
4
,
8
,
8
,
8
]
blks
=
len
(
n_layers
)
self
.
shortcut_layers
=
[]
self
.
base
=
nn
.
ModuleList
([])
self
.
base
.
append
(
ConvLayer
(
in_channels
=
3
,
out_channels
=
first_ch
[
0
],
kernel
=
3
,
stride
=
2
)
)
self
.
base
.
append
(
ConvLayer
(
first_ch
[
0
],
first_ch
[
1
],
kernel
=
3
)
)
self
.
base
.
append
(
ConvLayer
(
first_ch
[
1
],
first_ch
[
2
],
kernel
=
3
,
stride
=
2
)
)
self
.
base
.
append
(
ConvLayer
(
first_ch
[
2
],
first_ch
[
3
],
kernel
=
3
)
)
skip_connection_channel_counts
=
[]
ch
=
first_ch
[
3
]
for
i
in
range
(
blks
):
blk
=
HarDBlock
(
ch
,
gr
[
i
],
grmul
,
n_layers
[
i
])
ch
=
blk
.
get_out_ch
()
skip_connection_channel_counts
.
append
(
ch
)
self
.
base
.
append
(
blk
)
if
i
<
blks
-
1
:
self
.
shortcut_layers
.
append
(
len
(
self
.
base
)
-
1
)
self
.
base
.
append
(
ConvLayer
(
ch
,
ch_list
[
i
],
kernel
=
1
)
)
ch
=
ch_list
[
i
]
if
i
<
blks
-
1
:
self
.
base
.
append
(
nn
.
AvgPool2d
(
kernel_size
=
2
,
stride
=
2
)
)
cur_channels_count
=
ch
prev_block_channels
=
ch
n_blocks
=
blks
-
1
self
.
n_blocks
=
n_blocks
#######################
# Upsampling path #
#######################
self
.
transUpBlocks
=
nn
.
ModuleList
([])
self
.
denseBlocksUp
=
nn
.
ModuleList
([])
self
.
conv1x1_up
=
nn
.
ModuleList
([])
for
i
in
range
(
n_blocks
-
1
,
-
1
,
-
1
):
self
.
transUpBlocks
.
append
(
TransitionUp
(
prev_block_channels
,
prev_block_channels
))
cur_channels_count
=
prev_block_channels
+
skip_connection_channel_counts
[
i
]
self
.
conv1x1_up
.
append
(
ConvLayer
(
cur_channels_count
,
cur_channels_count
//
2
,
kernel
=
1
))
cur_channels_count
=
cur_channels_count
//
2
blk
=
HarDBlock
(
cur_channels_count
,
gr
[
i
],
grmul
,
n_layers
[
i
])
self
.
denseBlocksUp
.
append
(
blk
)
prev_block_channels
=
blk
.
get_out_ch
()
cur_channels_count
=
prev_block_channels
def
forward
(
self
,
x
):
skip_connections
=
[]
size_in
=
x
.
size
()
for
i
in
range
(
len
(
self
.
base
)):
x
=
self
.
base
[
i
](
x
)
if
i
in
self
.
shortcut_layers
:
skip_connections
.
append
(
x
)
out
=
x
for
i
in
range
(
self
.
n_blocks
):
skip
=
skip_connections
.
pop
()
out
=
self
.
transUpBlocks
[
i
](
out
,
skip
,
True
)
out
=
self
.
conv1x1_up
[
i
](
out
)
out
=
self
.
denseBlocksUp
[
i
](
out
)
return
out
def
get_hard_net
(
num_layers
,
cfg
):
model
=
hardnet
()
return
model
src/lib/models/Backbone/large_hourglass.py
0 → 100644
View file @
b952e97b
# ------------------------------------------------------------------------------
# This code is base on
# CornerNet (https://github.com/princeton-vl/CornerNet)
# Copyright (c) 2018, University of Michigan
# Licensed under the BSD 3-Clause License
# ------------------------------------------------------------------------------
from
__future__
import
absolute_import
,
division
,
print_function
import
numpy
as
np
import
torch
import
torch.nn
as
nn
class
convolution
(
nn
.
Module
):
def
__init__
(
self
,
k
,
inp_dim
,
out_dim
,
stride
=
1
,
with_bn
=
True
):
super
(
convolution
,
self
).
__init__
()
pad
=
(
k
-
1
)
//
2
self
.
conv
=
nn
.
Conv2d
(
inp_dim
,
out_dim
,
(
k
,
k
),
padding
=
(
pad
,
pad
),
stride
=
(
stride
,
stride
),
bias
=
not
with_bn
)
self
.
bn
=
nn
.
BatchNorm2d
(
out_dim
)
if
with_bn
else
nn
.
Sequential
()
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
def
forward
(
self
,
x
):
conv
=
self
.
conv
(
x
)
bn
=
self
.
bn
(
conv
)
relu
=
self
.
relu
(
bn
)
return
relu
class
fully_connected
(
nn
.
Module
):
def
__init__
(
self
,
inp_dim
,
out_dim
,
with_bn
=
True
):
super
(
fully_connected
,
self
).
__init__
()
self
.
with_bn
=
with_bn
self
.
linear
=
nn
.
Linear
(
inp_dim
,
out_dim
)
if
self
.
with_bn
:
self
.
bn
=
nn
.
BatchNorm1d
(
out_dim
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
def
forward
(
self
,
x
):
linear
=
self
.
linear
(
x
)
bn
=
self
.
bn
(
linear
)
if
self
.
with_bn
else
linear
relu
=
self
.
relu
(
bn
)
return
relu
class
residual
(
nn
.
Module
):
def
__init__
(
self
,
k
,
inp_dim
,
out_dim
,
stride
=
1
,
with_bn
=
True
):
super
(
residual
,
self
).
__init__
()
self
.
conv1
=
nn
.
Conv2d
(
inp_dim
,
out_dim
,
(
3
,
3
),
padding
=
(
1
,
1
),
stride
=
(
stride
,
stride
),
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
out_dim
)
self
.
relu1
=
nn
.
ReLU
(
inplace
=
True
)
self
.
conv2
=
nn
.
Conv2d
(
out_dim
,
out_dim
,
(
3
,
3
),
padding
=
(
1
,
1
),
bias
=
False
)
self
.
bn2
=
nn
.
BatchNorm2d
(
out_dim
)
self
.
skip
=
nn
.
Sequential
(
nn
.
Conv2d
(
inp_dim
,
out_dim
,
(
1
,
1
),
stride
=
(
stride
,
stride
),
bias
=
False
),
nn
.
BatchNorm2d
(
out_dim
)
)
if
stride
!=
1
or
inp_dim
!=
out_dim
else
nn
.
Sequential
()
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
def
forward
(
self
,
x
):
conv1
=
self
.
conv1
(
x
)
bn1
=
self
.
bn1
(
conv1
)
relu1
=
self
.
relu1
(
bn1
)
conv2
=
self
.
conv2
(
relu1
)
bn2
=
self
.
bn2
(
conv2
)
skip
=
self
.
skip
(
x
)
return
self
.
relu
(
bn2
+
skip
)
def
make_layer
(
k
,
inp_dim
,
out_dim
,
modules
,
layer
=
convolution
,
**
kwargs
):
layers
=
[
layer
(
k
,
inp_dim
,
out_dim
,
**
kwargs
)]
for
_
in
range
(
1
,
modules
):
layers
.
append
(
layer
(
k
,
out_dim
,
out_dim
,
**
kwargs
))
return
nn
.
Sequential
(
*
layers
)
def
make_layer_revr
(
k
,
inp_dim
,
out_dim
,
modules
,
layer
=
convolution
,
**
kwargs
):
layers
=
[]
for
_
in
range
(
modules
-
1
):
layers
.
append
(
layer
(
k
,
inp_dim
,
inp_dim
,
**
kwargs
))
layers
.
append
(
layer
(
k
,
inp_dim
,
out_dim
,
**
kwargs
))
return
nn
.
Sequential
(
*
layers
)
class
MergeUp
(
nn
.
Module
):
def
forward
(
self
,
up1
,
up2
):
return
up1
+
up2
def
make_merge_layer
(
dim
):
return
MergeUp
()
# def make_pool_layer(dim):
# return nn.MaxPool2d(kernel_size=2, stride=2)
def
make_pool_layer
(
dim
):
return
nn
.
Sequential
()
def
make_unpool_layer
(
dim
):
return
nn
.
Upsample
(
scale_factor
=
2
)
def
make_kp_layer
(
cnv_dim
,
curr_dim
,
out_dim
):
return
nn
.
Sequential
(
convolution
(
3
,
cnv_dim
,
curr_dim
,
with_bn
=
False
),
nn
.
Conv2d
(
curr_dim
,
out_dim
,
(
1
,
1
))
)
def
make_inter_layer
(
dim
):
return
residual
(
3
,
dim
,
dim
)
def
make_cnv_layer
(
inp_dim
,
out_dim
):
return
convolution
(
3
,
inp_dim
,
out_dim
)
class
kp_module
(
nn
.
Module
):
def
__init__
(
self
,
n
,
dims
,
modules
,
layer
=
residual
,
make_up_layer
=
make_layer
,
make_low_layer
=
make_layer
,
make_hg_layer
=
make_layer
,
make_hg_layer_revr
=
make_layer_revr
,
make_pool_layer
=
make_pool_layer
,
make_unpool_layer
=
make_unpool_layer
,
make_merge_layer
=
make_merge_layer
,
**
kwargs
):
super
(
kp_module
,
self
).
__init__
()
self
.
n
=
n
curr_mod
=
modules
[
0
]
next_mod
=
modules
[
1
]
curr_dim
=
dims
[
0
]
next_dim
=
dims
[
1
]
self
.
up1
=
make_up_layer
(
3
,
curr_dim
,
curr_dim
,
curr_mod
,
layer
=
layer
,
**
kwargs
)
self
.
max1
=
make_pool_layer
(
curr_dim
)
self
.
low1
=
make_hg_layer
(
3
,
curr_dim
,
next_dim
,
curr_mod
,
layer
=
layer
,
**
kwargs
)
self
.
low2
=
kp_module
(
n
-
1
,
dims
[
1
:],
modules
[
1
:],
layer
=
layer
,
make_up_layer
=
make_up_layer
,
make_low_layer
=
make_low_layer
,
make_hg_layer
=
make_hg_layer
,
make_hg_layer_revr
=
make_hg_layer_revr
,
make_pool_layer
=
make_pool_layer
,
make_unpool_layer
=
make_unpool_layer
,
make_merge_layer
=
make_merge_layer
,
**
kwargs
)
if
self
.
n
>
1
else
\
make_low_layer
(
3
,
next_dim
,
next_dim
,
next_mod
,
layer
=
layer
,
**
kwargs
)
self
.
low3
=
make_hg_layer_revr
(
3
,
next_dim
,
curr_dim
,
curr_mod
,
layer
=
layer
,
**
kwargs
)
self
.
up2
=
make_unpool_layer
(
curr_dim
)
self
.
merge
=
make_merge_layer
(
curr_dim
)
def
forward
(
self
,
x
):
up1
=
self
.
up1
(
x
)
max1
=
self
.
max1
(
x
)
low1
=
self
.
low1
(
max1
)
low2
=
self
.
low2
(
low1
)
low3
=
self
.
low3
(
low2
)
up2
=
self
.
up2
(
low3
)
return
self
.
merge
(
up1
,
up2
)
class
exkp
(
nn
.
Module
):
def
__init__
(
self
,
n
,
nstack
,
dims
,
modules
,
heads
,
pre
=
None
,
cnv_dim
=
256
,
make_tl_layer
=
None
,
make_br_layer
=
None
,
make_cnv_layer
=
make_cnv_layer
,
make_heat_layer
=
make_kp_layer
,
make_tag_layer
=
make_kp_layer
,
make_regr_layer
=
make_kp_layer
,
make_up_layer
=
make_layer
,
make_low_layer
=
make_layer
,
make_hg_layer
=
make_layer
,
make_hg_layer_revr
=
make_layer_revr
,
make_pool_layer
=
make_pool_layer
,
make_unpool_layer
=
make_unpool_layer
,
make_merge_layer
=
make_merge_layer
,
make_inter_layer
=
make_inter_layer
,
kp_layer
=
residual
):
super
(
exkp
,
self
).
__init__
()
self
.
nstack
=
nstack
self
.
heads
=
heads
curr_dim
=
dims
[
0
]
self
.
pre
=
nn
.
Sequential
(
convolution
(
7
,
3
,
128
,
stride
=
2
),
residual
(
3
,
128
,
256
,
stride
=
2
)
)
if
pre
is
None
else
pre
self
.
kps
=
nn
.
ModuleList
([
kp_module
(
n
,
dims
,
modules
,
layer
=
kp_layer
,
make_up_layer
=
make_up_layer
,
make_low_layer
=
make_low_layer
,
make_hg_layer
=
make_hg_layer
,
make_hg_layer_revr
=
make_hg_layer_revr
,
make_pool_layer
=
make_pool_layer
,
make_unpool_layer
=
make_unpool_layer
,
make_merge_layer
=
make_merge_layer
)
for
_
in
range
(
nstack
)
])
self
.
cnvs
=
nn
.
ModuleList
([
make_cnv_layer
(
curr_dim
,
cnv_dim
)
for
_
in
range
(
nstack
)
])
self
.
inters
=
nn
.
ModuleList
([
make_inter_layer
(
curr_dim
)
for
_
in
range
(
nstack
-
1
)
])
self
.
inters_
=
nn
.
ModuleList
([
nn
.
Sequential
(
nn
.
Conv2d
(
curr_dim
,
curr_dim
,
(
1
,
1
),
bias
=
False
),
nn
.
BatchNorm2d
(
curr_dim
)
)
for
_
in
range
(
nstack
-
1
)
])
self
.
cnvs_
=
nn
.
ModuleList
([
nn
.
Sequential
(
nn
.
Conv2d
(
cnv_dim
,
curr_dim
,
(
1
,
1
),
bias
=
False
),
nn
.
BatchNorm2d
(
curr_dim
)
)
for
_
in
range
(
nstack
-
1
)
])
## keypoint heatmaps
for
head
in
heads
.
keys
():
if
'hm'
in
head
:
module
=
nn
.
ModuleList
([
make_heat_layer
(
cnv_dim
,
curr_dim
,
heads
[
head
])
for
_
in
range
(
nstack
)
])
self
.
__setattr__
(
head
,
module
)
for
heat
in
self
.
__getattr__
(
head
):
heat
[
-
1
].
bias
.
data
.
fill_
(
-
2.19
)
else
:
module
=
nn
.
ModuleList
([
make_regr_layer
(
cnv_dim
,
curr_dim
,
heads
[
head
])
for
_
in
range
(
nstack
)
])
self
.
__setattr__
(
head
,
module
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
def
forward
(
self
,
image
):
# print('image shape', image.shape)
inter
=
self
.
pre
(
image
)
outs
=
[]
for
ind
in
range
(
self
.
nstack
):
kp_
,
cnv_
=
self
.
kps
[
ind
],
self
.
cnvs
[
ind
]
kp
=
kp_
(
inter
)
cnv
=
cnv_
(
kp
)
out
=
{}
for
head
in
self
.
heads
:
layer
=
self
.
__getattr__
(
head
)[
ind
]
y
=
layer
(
cnv
)
out
[
head
]
=
y
outs
.
append
(
out
)
if
ind
<
self
.
nstack
-
1
:
inter
=
self
.
inters_
[
ind
](
inter
)
+
self
.
cnvs_
[
ind
](
cnv
)
inter
=
self
.
relu
(
inter
)
inter
=
self
.
inters
[
ind
](
inter
)
return
outs
def
make_hg_layer
(
kernel
,
dim0
,
dim1
,
mod
,
layer
=
convolution
,
**
kwargs
):
layers
=
[
layer
(
kernel
,
dim0
,
dim1
,
stride
=
2
)]
layers
+=
[
layer
(
kernel
,
dim1
,
dim1
)
for
_
in
range
(
mod
-
1
)]
return
nn
.
Sequential
(
*
layers
)
class
HourglassNet
(
exkp
):
def
__init__
(
self
,
heads
,
num_stacks
=
2
):
n
=
5
dims
=
[
256
,
256
,
384
,
384
,
384
,
512
]
modules
=
[
2
,
2
,
2
,
2
,
2
,
4
]
super
(
HourglassNet
,
self
).
__init__
(
n
,
num_stacks
,
dims
,
modules
,
heads
,
make_tl_layer
=
None
,
make_br_layer
=
None
,
make_pool_layer
=
make_pool_layer
,
make_hg_layer
=
make_hg_layer
,
kp_layer
=
residual
,
cnv_dim
=
256
)
def
get_large_hourglass_net
(
num_layers
,
heads
,
head_conv
):
model
=
HourglassNet
(
heads
,
2
)
return
model
src/lib/models/Backbone/mobilenet_v2.py
0 → 100644
View file @
b952e97b
from
torch
import
nn
import
torch.utils.model_zoo
as
model_zoo
from
collections
import
OrderedDict
import
math
__all__
=
[
'MobileNetV2'
]
model_urls
=
{
'mobilenet_v2'
:
'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth'
,
}
def
_make_divisible
(
v
,
divisor
,
min_value
=
None
):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if
min_value
is
None
:
min_value
=
divisor
new_v
=
max
(
min_value
,
int
(
v
+
divisor
/
2
)
//
divisor
*
divisor
)
# Make sure that round down does not go down by more than 10%.
if
new_v
<
0.9
*
v
:
new_v
+=
divisor
return
new_v
class
ConvBNReLU
(
nn
.
Sequential
):
def
__init__
(
self
,
in_planes
,
out_planes
,
kernel_size
=
3
,
stride
=
1
,
groups
=
1
):
padding
=
(
kernel_size
-
1
)
//
2
super
(
ConvBNReLU
,
self
).
__init__
(
nn
.
Conv2d
(
in_planes
,
out_planes
,
kernel_size
,
stride
,
padding
,
groups
=
groups
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_planes
),
nn
.
ReLU6
(
inplace
=
True
)
)
class
InvertedResidual
(
nn
.
Module
):
def
__init__
(
self
,
inp
,
oup
,
stride
,
expand_ratio
):
super
(
InvertedResidual
,
self
).
__init__
()
self
.
stride
=
stride
assert
stride
in
[
1
,
2
]
hidden_dim
=
int
(
round
(
inp
*
expand_ratio
))
self
.
use_res_connect
=
self
.
stride
==
1
and
inp
==
oup
layers
=
[]
if
expand_ratio
!=
1
:
# pw
layers
.
append
(
ConvBNReLU
(
inp
,
hidden_dim
,
kernel_size
=
1
))
layers
.
extend
([
# dw
ConvBNReLU
(
hidden_dim
,
hidden_dim
,
stride
=
stride
,
groups
=
hidden_dim
),
# pw-linear
nn
.
Conv2d
(
hidden_dim
,
oup
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup
),
])
self
.
conv
=
nn
.
Sequential
(
*
layers
)
def
forward
(
self
,
x
):
if
self
.
use_res_connect
:
return
x
+
self
.
conv
(
x
)
else
:
return
self
.
conv
(
x
)
class
MobileNetV2
(
nn
.
Module
):
def
__init__
(
self
,
width_mult
=
1.0
,
round_nearest
=
8
,):
super
(
MobileNetV2
,
self
).
__init__
()
block
=
InvertedResidual
input_channel
=
32
inverted_residual_setting
=
[
# t, c, n, s
[
1
,
16
,
1
,
1
],
# 0
[
6
,
24
,
2
,
2
],
# 1
[
6
,
32
,
3
,
2
],
# 2
[
6
,
64
,
4
,
2
],
# 3
[
6
,
96
,
3
,
1
],
# 4
[
6
,
160
,
3
,
2
],
# 5
[
6
,
320
,
1
,
1
],
# 6
]
self
.
feat_id
=
[
1
,
2
,
4
,
6
]
self
.
feat_channel
=
[]
# only check the first element, assuming user knows t,c,n,s are required
if
len
(
inverted_residual_setting
)
==
0
or
len
(
inverted_residual_setting
[
0
])
!=
4
:
raise
ValueError
(
"inverted_residual_setting should be non-empty "
"or a 4-element list, got {}"
.
format
(
inverted_residual_setting
))
# building first layer
input_channel
=
_make_divisible
(
input_channel
*
width_mult
,
round_nearest
)
features
=
[
ConvBNReLU
(
3
,
input_channel
,
stride
=
2
)]
# building inverted residual blocks
for
id
,(
t
,
c
,
n
,
s
)
in
enumerate
(
inverted_residual_setting
):
output_channel
=
_make_divisible
(
c
*
width_mult
,
round_nearest
)
for
i
in
range
(
n
):
stride
=
s
if
i
==
0
else
1
features
.
append
(
block
(
input_channel
,
output_channel
,
stride
,
expand_ratio
=
t
))
input_channel
=
output_channel
if
id
in
self
.
feat_id
:
self
.
__setattr__
(
"feature_%d"
%
id
,
nn
.
Sequential
(
*
features
))
self
.
feat_channel
.
append
(
output_channel
)
features
=
[]
# weight initialization
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
nn
.
init
.
kaiming_normal_
(
m
.
weight
,
mode
=
'fan_out'
)
if
m
.
bias
is
not
None
:
nn
.
init
.
zeros_
(
m
.
bias
)
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
nn
.
init
.
ones_
(
m
.
weight
)
nn
.
init
.
zeros_
(
m
.
bias
)
def
forward
(
self
,
x
):
y
=
[]
for
id
in
self
.
feat_id
:
x
=
self
.
__getattr__
(
"feature_%d"
%
id
)(
x
)
y
.
append
(
x
)
return
y
def
load_model
(
model
,
state_dict
):
new_model
=
model
.
state_dict
()
new_keys
=
list
(
new_model
.
keys
())
old_keys
=
list
(
state_dict
.
keys
())
restore_dict
=
OrderedDict
()
for
id
in
range
(
len
(
new_keys
)):
restore_dict
[
new_keys
[
id
]]
=
state_dict
[
old_keys
[
id
]]
model
.
load_state_dict
(
restore_dict
)
def
dict2list
(
func
):
def
wrap
(
*
args
,
**
kwargs
):
self
=
args
[
0
]
x
=
args
[
1
]
ret_list
=
[]
ret
=
func
(
self
,
x
)
for
k
,
v
in
ret
[
0
].
items
():
ret_list
.
append
(
v
)
return
ret_list
return
wrap
def
fill_up_weights
(
up
):
w
=
up
.
weight
.
data
f
=
math
.
ceil
(
w
.
size
(
2
)
/
2
)
c
=
(
2
*
f
-
1
-
f
%
2
)
/
(
2.
*
f
)
for
i
in
range
(
w
.
size
(
2
)):
for
j
in
range
(
w
.
size
(
3
)):
w
[
0
,
0
,
i
,
j
]
=
\
(
1
-
math
.
fabs
(
i
/
f
-
c
))
*
(
1
-
math
.
fabs
(
j
/
f
-
c
))
for
c
in
range
(
1
,
w
.
size
(
0
)):
w
[
c
,
0
,
:,
:]
=
w
[
0
,
0
,
:,
:]
def
fill_fc_weights
(
layers
):
for
m
in
layers
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
nn
.
init
.
normal_
(
m
.
weight
,
std
=
0.001
)
if
m
.
bias
is
not
None
:
nn
.
init
.
constant_
(
m
.
bias
,
0
)
class
IDAUp
(
nn
.
Module
):
def
__init__
(
self
,
out_dim
,
channel
):
super
(
IDAUp
,
self
).
__init__
()
self
.
out_dim
=
out_dim
self
.
up
=
nn
.
Sequential
(
nn
.
ConvTranspose2d
(
out_dim
,
out_dim
,
kernel_size
=
2
,
stride
=
2
,
padding
=
0
,
output_padding
=
0
,
groups
=
out_dim
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_dim
,
eps
=
0.001
,
momentum
=
0.1
),
nn
.
ReLU
())
self
.
conv
=
nn
.
Sequential
(
nn
.
Conv2d
(
channel
,
out_dim
,
kernel_size
=
1
,
stride
=
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_dim
,
eps
=
0.001
,
momentum
=
0.1
),
nn
.
ReLU
(
inplace
=
True
))
def
forward
(
self
,
layers
):
layers
=
list
(
layers
)
x
=
self
.
up
(
layers
[
0
])
y
=
self
.
conv
(
layers
[
1
])
out
=
x
+
y
return
out
class
MobileNetUp
(
nn
.
Module
):
def
__init__
(
self
,
channels
,
out_dim
=
24
):
super
(
MobileNetUp
,
self
).
__init__
()
channels
=
channels
[::
-
1
]
self
.
conv
=
nn
.
Sequential
(
nn
.
Conv2d
(
channels
[
0
],
out_dim
,
kernel_size
=
1
,
stride
=
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_dim
,
eps
=
0.001
,
momentum
=
0.1
),
nn
.
ReLU
(
inplace
=
True
))
self
.
conv_last
=
nn
.
Sequential
(
nn
.
Conv2d
(
out_dim
,
out_dim
,
kernel_size
=
3
,
stride
=
1
,
padding
=
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_dim
,
eps
=
1e-5
,
momentum
=
0.01
),
nn
.
ReLU
(
inplace
=
True
))
for
i
,
channel
in
enumerate
(
channels
[
1
:]):
setattr
(
self
,
'up_%d'
%
(
i
),
IDAUp
(
out_dim
,
channel
))
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
nn
.
init
.
kaiming_normal_
(
m
.
weight
,
mode
=
'fan_out'
)
if
m
.
bias
is
not
None
:
nn
.
init
.
constant_
(
m
.
bias
,
0
)
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
nn
.
init
.
constant_
(
m
.
weight
,
1
)
nn
.
init
.
constant_
(
m
.
bias
,
0
)
elif
isinstance
(
m
,
nn
.
ConvTranspose2d
):
fill_up_weights
(
m
)
def
forward
(
self
,
layers
):
layers
=
list
(
layers
)
assert
len
(
layers
)
>
1
x
=
self
.
conv
(
layers
[
-
1
])
for
i
in
range
(
0
,
len
(
layers
)
-
1
):
up
=
getattr
(
self
,
'up_{}'
.
format
(
i
))
x
=
up
([
x
,
layers
[
len
(
layers
)
-
2
-
i
]])
x
=
self
.
conv_last
(
x
)
return
x
class
MobileNetSeg
(
nn
.
Module
):
def
__init__
(
self
,
base_name
,
heads
,
head_conv
=
24
,
pretrained
=
True
):
super
(
MobileNetSeg
,
self
).
__init__
()
self
.
heads
=
heads
self
.
base
=
globals
()[
base_name
](
pretrained
=
pretrained
)
channels
=
self
.
base
.
feat_channel
self
.
dla_up
=
MobileNetUp
(
channels
,
out_dim
=
head_conv
)
for
head
in
self
.
heads
:
classes
=
self
.
heads
[
head
]
fc
=
nn
.
Conv2d
(
head_conv
,
classes
,
kernel_size
=
1
,
stride
=
1
,
padding
=
0
,
bias
=
True
)
if
'hm'
in
head
:
fc
.
bias
.
data
.
fill_
(
-
2.19
)
else
:
nn
.
init
.
normal_
(
fc
.
weight
,
std
=
0.001
)
nn
.
init
.
constant_
(
fc
.
bias
,
0
)
self
.
__setattr__
(
head
,
fc
)
# @dict2list # 转onnx的时候需要将输出由dict转成list模式
def
forward
(
self
,
x
):
x
=
self
.
base
(
x
)
x
=
self
.
dla_up
(
x
)
ret
=
{}
for
head
in
self
.
heads
:
ret
[
head
]
=
self
.
__getattr__
(
head
)(
x
)
return
[
ret
]
def
mobilenetv2_10
(
pretrained
=
True
,
**
kwargs
):
model
=
MobileNetV2
(
width_mult
=
1.0
)
if
pretrained
:
state_dict
=
model_zoo
.
load_url
(
model_urls
[
'mobilenet_v2'
],
progress
=
True
)
load_model
(
model
,
state_dict
)
return
model
def
mobilenetv2_5
(
pretrained
=
False
,
**
kwargs
):
model
=
MobileNetV2
(
width_mult
=
0.5
)
if
pretrained
:
print
(
'This version does not have pretrain weights.'
)
return
model
# num_layers : [10 , 5]
def
get_mobile_net
(
num_layers
,
heads
,
head_conv
=
24
):
model
=
MobileNetSeg
(
'mobilenetv2_{}'
.
format
(
num_layers
),
heads
,
pretrained
=
True
,
head_conv
=
head_conv
)
return
model
if
__name__
==
'__main__'
:
import
torch
input
=
torch
.
zeros
([
1
,
3
,
416
,
416
])
model
=
get_mobile_net
(
5
,{
'hm'
:
1
,
'reg'
:
2
,
'wh'
:
2
},
head_conv
=
24
)
# hm reference for the classes of objects//这个头文件只能做矩形框检测
res
=
model
(
input
)
print
(
res
.
shape
)
src/lib/models/Backbone/mobilenetv2.py
0 → 100644
View file @
b952e97b
from
torch
import
nn
import
torch.utils.model_zoo
as
model_zoo
from
collections
import
OrderedDict
import
math
__all__
=
[
'MobileNetV2'
]
model_urls
=
{
'mobilenet_v2'
:
'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth'
,
}
def
_make_divisible
(
v
,
divisor
,
min_value
=
None
):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if
min_value
is
None
:
min_value
=
divisor
new_v
=
max
(
min_value
,
int
(
v
+
divisor
/
2
)
//
divisor
*
divisor
)
# Make sure that round down does not go down by more than 10%.
if
new_v
<
0.9
*
v
:
new_v
+=
divisor
return
new_v
class
ConvBNReLU
(
nn
.
Sequential
):
def
__init__
(
self
,
in_planes
,
out_planes
,
kernel_size
=
3
,
stride
=
1
,
groups
=
1
):
padding
=
(
kernel_size
-
1
)
//
2
super
(
ConvBNReLU
,
self
).
__init__
(
nn
.
Conv2d
(
in_planes
,
out_planes
,
kernel_size
,
stride
,
padding
,
groups
=
groups
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_planes
),
nn
.
ReLU
(
inplace
=
True
)
#replace ReLU6
)
class
InvertedResidual
(
nn
.
Module
):
def
__init__
(
self
,
inp
,
oup
,
stride
,
expand_ratio
):
super
(
InvertedResidual
,
self
).
__init__
()
self
.
stride
=
stride
assert
stride
in
[
1
,
2
]
hidden_dim
=
int
(
round
(
inp
*
expand_ratio
))
self
.
use_res_connect
=
self
.
stride
==
1
and
inp
==
oup
layers
=
[]
if
expand_ratio
!=
1
:
# pw
layers
.
append
(
ConvBNReLU
(
inp
,
hidden_dim
,
kernel_size
=
1
))
layers
.
extend
([
# dw
ConvBNReLU
(
hidden_dim
,
hidden_dim
,
stride
=
stride
,
groups
=
hidden_dim
),
# pw-linear
nn
.
Conv2d
(
hidden_dim
,
oup
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup
),
])
self
.
conv
=
nn
.
Sequential
(
*
layers
)
def
forward
(
self
,
x
):
if
self
.
use_res_connect
:
return
x
+
self
.
conv
(
x
)
else
:
return
self
.
conv
(
x
)
class
MobileNetV2
(
nn
.
Module
):
def
__init__
(
self
,
width_mult
=
1.0
,
round_nearest
=
8
,
):
super
(
MobileNetV2
,
self
).
__init__
()
block
=
InvertedResidual
input_channel
=
32
inverted_residual_setting
=
[
# t, c, n, s
[
1
,
16
,
1
,
1
],
# 0
[
6
,
24
,
2
,
2
],
# 1
[
6
,
32
,
3
,
2
],
# 2
[
6
,
64
,
4
,
2
],
# 3
[
6
,
96
,
3
,
1
],
# 4
[
6
,
160
,
3
,
2
],
# 5
[
6
,
320
,
1
,
1
],
# 6
]
self
.
feat_id
=
[
1
,
2
,
4
,
6
]
self
.
feat_channel
=
[]
# only check the first element, assuming user knows t,c,n,s are required
if
len
(
inverted_residual_setting
)
==
0
or
len
(
inverted_residual_setting
[
0
])
!=
4
:
raise
ValueError
(
"inverted_residual_setting should be non-empty "
"or a 4-element list, got {}"
.
format
(
inverted_residual_setting
))
# building first layer
input_channel
=
_make_divisible
(
input_channel
*
width_mult
,
round_nearest
)
features
=
[
ConvBNReLU
(
3
,
input_channel
,
stride
=
2
)]
# building inverted residual blocks
for
id
,
(
t
,
c
,
n
,
s
)
in
enumerate
(
inverted_residual_setting
):
output_channel
=
_make_divisible
(
c
*
width_mult
,
round_nearest
)
for
i
in
range
(
n
):
stride
=
s
if
i
==
0
else
1
features
.
append
(
block
(
input_channel
,
output_channel
,
stride
,
expand_ratio
=
t
))
input_channel
=
output_channel
if
id
in
self
.
feat_id
:
self
.
__setattr__
(
"feature_%d"
%
id
,
nn
.
Sequential
(
*
features
))
self
.
feat_channel
.
append
(
output_channel
)
features
=
[]
# weight initialization
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
nn
.
init
.
kaiming_normal_
(
m
.
weight
,
mode
=
'fan_out'
)
if
m
.
bias
is
not
None
:
nn
.
init
.
zeros_
(
m
.
bias
)
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
nn
.
init
.
ones_
(
m
.
weight
)
nn
.
init
.
zeros_
(
m
.
bias
)
def
forward
(
self
,
x
):
y
=
[]
for
id
in
self
.
feat_id
:
x
=
self
.
__getattr__
(
"feature_%d"
%
id
)(
x
)
y
.
append
(
x
)
return
y
def
load_model
(
model
,
state_dict
):
new_model
=
model
.
state_dict
()
new_keys
=
list
(
new_model
.
keys
())
old_keys
=
list
(
state_dict
.
keys
())
restore_dict
=
OrderedDict
()
for
id
in
range
(
len
(
new_keys
)):
restore_dict
[
new_keys
[
id
]]
=
state_dict
[
old_keys
[
id
]]
model
.
load_state_dict
(
restore_dict
)
def
fill_up_weights
(
up
):
w
=
up
.
weight
.
data
f
=
math
.
ceil
(
w
.
size
(
2
)
/
2
)
c
=
(
2
*
f
-
1
-
f
%
2
)
/
(
2.
*
f
)
for
i
in
range
(
w
.
size
(
2
)):
for
j
in
range
(
w
.
size
(
3
)):
w
[
0
,
0
,
i
,
j
]
=
\
(
1
-
math
.
fabs
(
i
/
f
-
c
))
*
(
1
-
math
.
fabs
(
j
/
f
-
c
))
for
c
in
range
(
1
,
w
.
size
(
0
)):
w
[
c
,
0
,
:,
:]
=
w
[
0
,
0
,
:,
:]
def
fill_fc_weights
(
layers
):
for
m
in
layers
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
nn
.
init
.
normal_
(
m
.
weight
,
std
=
0.001
)
if
m
.
bias
is
not
None
:
nn
.
init
.
constant_
(
m
.
bias
,
0
)
class
IDAUp
(
nn
.
Module
):
def
__init__
(
self
,
out_dim
,
channel
):
super
(
IDAUp
,
self
).
__init__
()
self
.
out_dim
=
out_dim
self
.
up
=
nn
.
Sequential
(
nn
.
ConvTranspose2d
(
out_dim
,
out_dim
,
kernel_size
=
2
,
stride
=
2
,
padding
=
0
,
output_padding
=
0
,
groups
=
out_dim
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_dim
,
eps
=
0.001
,
momentum
=
0.1
),
nn
.
ReLU
())
self
.
conv
=
nn
.
Sequential
(
nn
.
Conv2d
(
channel
,
out_dim
,
kernel_size
=
1
,
stride
=
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_dim
,
eps
=
0.001
,
momentum
=
0.1
),
nn
.
ReLU
(
inplace
=
True
))
def
forward
(
self
,
layers
):
layers
=
list
(
layers
)
x
=
self
.
up
(
layers
[
0
])
y
=
self
.
conv
(
layers
[
1
])
out
=
x
+
y
return
out
class
MobileNetUp
(
nn
.
Module
):
def
__init__
(
self
,
channels
,
out_dim
=
24
):
super
(
MobileNetUp
,
self
).
__init__
()
channels
=
channels
[::
-
1
]
self
.
conv
=
nn
.
Sequential
(
nn
.
Conv2d
(
channels
[
0
],
out_dim
,
kernel_size
=
1
,
stride
=
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_dim
,
eps
=
0.001
,
momentum
=
0.1
),
nn
.
ReLU
(
inplace
=
True
))
self
.
conv_last
=
nn
.
Sequential
(
nn
.
Conv2d
(
out_dim
,
out_dim
,
kernel_size
=
3
,
stride
=
1
,
padding
=
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_dim
,
eps
=
1e-5
,
momentum
=
0.01
),
nn
.
ReLU
(
inplace
=
True
))
for
i
,
channel
in
enumerate
(
channels
[
1
:]):
setattr
(
self
,
'up_%d'
%
(
i
),
IDAUp
(
out_dim
,
channel
))
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
nn
.
init
.
kaiming_normal_
(
m
.
weight
,
mode
=
'fan_out'
)
if
m
.
bias
is
not
None
:
nn
.
init
.
constant_
(
m
.
bias
,
0
)
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
nn
.
init
.
constant_
(
m
.
weight
,
1
)
nn
.
init
.
constant_
(
m
.
bias
,
0
)
elif
isinstance
(
m
,
nn
.
ConvTranspose2d
):
fill_up_weights
(
m
)
def
forward
(
self
,
layers
):
layers
=
list
(
layers
)
assert
len
(
layers
)
>
1
x
=
self
.
conv
(
layers
[
-
1
])
for
i
in
range
(
0
,
len
(
layers
)
-
1
):
up
=
getattr
(
self
,
'up_{}'
.
format
(
i
))
x
=
up
([
x
,
layers
[
len
(
layers
)
-
2
-
i
]])
x
=
self
.
conv_last
(
x
)
return
x
class
MobileNetSeg
(
nn
.
Module
):
def
__init__
(
self
,
base_name
,
head_conv
=
24
,
pretrained
=
True
):
super
(
MobileNetSeg
,
self
).
__init__
()
# self.heads = {'hm':1,'reg':2,'wh':2}
self
.
base
=
globals
()[
base_name
](
pretrained
=
pretrained
)
channels
=
self
.
base
.
feat_channel
self
.
dla_up
=
MobileNetUp
(
channels
,
out_dim
=
head_conv
)
def
forward
(
self
,
x
):
x
=
self
.
base
(
x
)
x
=
self
.
dla_up
(
x
)
return
x
def
mobilenetv2_10
(
pretrained
=
True
,
**
kwargs
):
model
=
MobileNetV2
(
width_mult
=
1.0
)
if
pretrained
:
state_dict
=
model_zoo
.
load_url
(
model_urls
[
'mobilenet_v2'
],
progress
=
True
)
load_model
(
model
,
state_dict
)
return
model
def
mobilenetv2_5
(
pretrained
=
False
,
**
kwargs
):
model
=
MobileNetV2
(
width_mult
=
0.5
)
if
pretrained
:
print
(
'This version does not have pretrain weights.'
)
return
model
# num_layers : [10 , 5]
def
get_mobile_pose_netv2
(
num_layers
,
cfg
):
num_layers
=
10
model
=
MobileNetSeg
(
'mobilenetv2_{}'
.
format
(
num_layers
),
pretrained
=
True
,
head_conv
=
cfg
.
MODEL
.
INTERMEDIATE_CHANNEL
)
return
model
src/lib/models/Backbone/mobilenetv3.py
0 → 100644
View file @
b952e97b
from
__future__
import
absolute_import
,
division
,
print_function
import
math
import
torch.nn.functional
as
F
from
torch
import
nn
from
torch.nn
import
init
from
.DCNv2.dcn_v2
import
DCN
class
DeformConv
(
nn
.
Module
):
def
__init__
(
self
,
chi
,
cho
):
super
(
DeformConv
,
self
).
__init__
()
self
.
actf
=
nn
.
Sequential
(
nn
.
BatchNorm2d
(
cho
,
momentum
=
0.1
),
nn
.
ReLU
(
inplace
=
True
)
)
self
.
conv
=
DCN
(
chi
,
cho
,
kernel_size
=
(
3
,
3
),
stride
=
1
,
padding
=
1
,
dilation
=
1
,
deformable_groups
=
1
)
def
forward
(
self
,
x
):
x
=
self
.
conv
(
x
)
x
=
self
.
actf
(
x
)
return
x
class
IDAUp
(
nn
.
Module
):
def
__init__
(
self
,
o
,
channels
,
up_f
):
super
(
IDAUp
,
self
).
__init__
()
for
i
in
range
(
1
,
len
(
channels
)):
c
=
channels
[
i
]
f
=
int
(
up_f
[
i
])
proj
=
DeformConv
(
c
,
o
)
node
=
DeformConv
(
o
,
o
)
up
=
nn
.
ConvTranspose2d
(
o
,
o
,
f
*
2
,
stride
=
f
,
padding
=
f
//
2
,
output_padding
=
0
,
groups
=
o
,
bias
=
False
)
fill_up_weights
(
up
)
setattr
(
self
,
'proj_'
+
str
(
i
),
proj
)
setattr
(
self
,
'up_'
+
str
(
i
),
up
)
setattr
(
self
,
'node_'
+
str
(
i
),
node
)
def
forward
(
self
,
layers
,
startp
,
endp
):
for
i
in
range
(
startp
+
1
,
endp
):
upsample
=
getattr
(
self
,
'up_'
+
str
(
i
-
startp
))
project
=
getattr
(
self
,
'proj_'
+
str
(
i
-
startp
))
layers
[
i
]
=
upsample
(
project
(
layers
[
i
]))
node
=
getattr
(
self
,
'node_'
+
str
(
i
-
startp
))
layers
[
i
]
=
node
(
layers
[
i
]
+
layers
[
i
-
1
])
class
hswish
(
nn
.
Module
):
def
forward
(
self
,
x
):
out
=
x
*
F
.
relu6
(
x
+
3
,
inplace
=
True
)
/
6
return
out
class
hsigmoid
(
nn
.
Module
):
def
forward
(
self
,
x
):
out
=
F
.
relu6
(
x
+
3
,
inplace
=
True
)
/
6
return
out
class
SeModule
(
nn
.
Module
):
def
__init__
(
self
,
in_size
,
reduction
=
4
):
super
(
SeModule
,
self
).
__init__
()
self
.
se
=
nn
.
Sequential
(
nn
.
AdaptiveAvgPool2d
(
1
),
nn
.
Conv2d
(
in_size
,
in_size
//
reduction
,
kernel_size
=
1
,
stride
=
1
,
padding
=
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
in_size
//
reduction
),
nn
.
ReLU
(
inplace
=
True
),
nn
.
Conv2d
(
in_size
//
reduction
,
in_size
,
kernel_size
=
1
,
stride
=
1
,
padding
=
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
in_size
),
hsigmoid
()
)
def
forward
(
self
,
x
):
return
x
*
self
.
se
(
x
)
class
Block
(
nn
.
Module
):
'''expand + depthwise + pointwise'''
def
__init__
(
self
,
kernel_size
,
in_size
,
expand_size
,
out_size
,
nolinear
,
semodule
,
stride
):
super
(
Block
,
self
).
__init__
()
self
.
stride
=
stride
self
.
se
=
semodule
self
.
conv1
=
nn
.
Conv2d
(
in_size
,
expand_size
,
kernel_size
=
1
,
stride
=
1
,
padding
=
0
,
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
expand_size
)
self
.
nolinear1
=
nolinear
self
.
conv2
=
nn
.
Conv2d
(
expand_size
,
expand_size
,
kernel_size
=
kernel_size
,
stride
=
stride
,
padding
=
kernel_size
//
2
,
groups
=
expand_size
,
bias
=
False
)
self
.
bn2
=
nn
.
BatchNorm2d
(
expand_size
)
self
.
nolinear2
=
nolinear
self
.
conv3
=
nn
.
Conv2d
(
expand_size
,
out_size
,
kernel_size
=
1
,
stride
=
1
,
padding
=
0
,
bias
=
False
)
self
.
bn3
=
nn
.
BatchNorm2d
(
out_size
)
self
.
shortcut
=
nn
.
Sequential
()
if
stride
==
1
and
in_size
!=
out_size
:
self
.
shortcut
=
nn
.
Sequential
(
nn
.
Conv2d
(
in_size
,
out_size
,
kernel_size
=
1
,
stride
=
1
,
padding
=
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_size
),
)
def
forward
(
self
,
x
):
out
=
self
.
nolinear1
(
self
.
bn1
(
self
.
conv1
(
x
)))
out
=
self
.
nolinear2
(
self
.
bn2
(
self
.
conv2
(
out
)))
out
=
self
.
bn3
(
self
.
conv3
(
out
))
if
self
.
se
!=
None
:
out
=
self
.
se
(
out
)
out
=
out
+
self
.
shortcut
(
x
)
if
self
.
stride
==
1
else
out
return
out
def
fill_up_weights
(
up
):
w
=
up
.
weight
.
data
f
=
math
.
ceil
(
w
.
size
(
2
)
/
2
)
c
=
(
2
*
f
-
1
-
f
%
2
)
/
(
2.
*
f
)
for
i
in
range
(
w
.
size
(
2
)):
for
j
in
range
(
w
.
size
(
3
)):
w
[
0
,
0
,
i
,
j
]
=
\
(
1
-
math
.
fabs
(
i
/
f
-
c
))
*
(
1
-
math
.
fabs
(
j
/
f
-
c
))
for
c
in
range
(
1
,
w
.
size
(
0
)):
w
[
c
,
0
,
:,
:]
=
w
[
0
,
0
,
:,
:]
class
MobileNetV3
(
nn
.
Module
):
def
__init__
(
self
,
final_kernel
):
super
(
MobileNetV3
,
self
).
__init__
()
self
.
conv1
=
nn
.
Conv2d
(
3
,
16
,
kernel_size
=
3
,
stride
=
2
,
padding
=
1
,
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
16
)
self
.
hs1
=
hswish
()
self
.
bneck0
=
nn
.
Sequential
(
Block
(
3
,
16
,
16
,
16
,
nn
.
ReLU
(
inplace
=
True
),
None
,
1
),
Block
(
3
,
16
,
64
,
24
,
nn
.
ReLU
(
inplace
=
True
),
None
,
2
),
Block
(
3
,
24
,
72
,
24
,
nn
.
ReLU
(
inplace
=
True
),
None
,
1
),
)
self
.
bneck1
=
nn
.
Sequential
(
Block
(
5
,
24
,
72
,
40
,
nn
.
ReLU
(
inplace
=
True
),
SeModule
(
40
),
2
),
Block
(
5
,
40
,
120
,
40
,
nn
.
ReLU
(
inplace
=
True
),
SeModule
(
40
),
1
),
Block
(
5
,
40
,
120
,
40
,
nn
.
ReLU
(
inplace
=
True
),
SeModule
(
40
),
1
),
)
self
.
bneck2
=
nn
.
Sequential
(
Block
(
3
,
40
,
240
,
80
,
hswish
(),
None
,
2
),
Block
(
3
,
80
,
200
,
80
,
hswish
(),
None
,
1
),
Block
(
3
,
80
,
184
,
80
,
hswish
(),
None
,
1
),
Block
(
3
,
80
,
184
,
80
,
hswish
(),
None
,
1
),
Block
(
3
,
80
,
480
,
112
,
hswish
(),
SeModule
(
112
),
1
),
Block
(
3
,
112
,
672
,
112
,
hswish
(),
SeModule
(
112
),
1
),
Block
(
5
,
112
,
672
,
160
,
hswish
(),
SeModule
(
160
),
1
),
)
self
.
bneck3
=
nn
.
Sequential
(
Block
(
5
,
160
,
672
,
160
,
hswish
(),
SeModule
(
160
),
2
),
Block
(
5
,
160
,
960
,
160
,
hswish
(),
SeModule
(
160
),
1
),
)
self
.
conv2
=
nn
.
Conv2d
(
160
,
960
,
kernel_size
=
1
,
stride
=
1
,
padding
=
0
,
bias
=
False
)
self
.
bn2
=
nn
.
BatchNorm2d
(
960
)
self
.
hs2
=
hswish
()
self
.
ida_up
=
IDAUp
(
24
,
[
24
,
40
,
160
,
960
],
[
2
**
i
for
i
in
range
(
4
)])
self
.
init_params
()
def
init_params
(
self
):
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
init
.
kaiming_normal_
(
m
.
weight
,
mode
=
'fan_out'
)
if
m
.
bias
is
not
None
:
init
.
constant_
(
m
.
bias
,
0
)
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
init
.
constant_
(
m
.
weight
,
1
)
init
.
constant_
(
m
.
bias
,
0
)
elif
isinstance
(
m
,
nn
.
Linear
):
init
.
normal_
(
m
.
weight
,
std
=
0.001
)
if
m
.
bias
is
not
None
:
init
.
constant_
(
m
.
bias
,
0
)
def
forward
(
self
,
x
):
out
=
self
.
hs1
(
self
.
bn1
(
self
.
conv1
(
x
)))
out0
=
self
.
bneck0
(
out
)
out1
=
self
.
bneck1
(
out0
)
out2
=
self
.
bneck2
(
out1
)
out3
=
self
.
bneck3
(
out2
)
out3
=
self
.
hs2
(
self
.
bn2
(
self
.
conv2
(
out3
)))
out
=
[
out0
,
out1
,
out2
,
out3
]
y
=
[]
for
i
in
range
(
4
):
y
.
append
(
out
[
i
].
clone
())
self
.
ida_up
(
y
,
0
,
len
(
y
))
return
y
[
-
1
]
def
get_mobilev3_pose_net
(
num_layers
,
cfg
):
model
=
MobileNetV3
(
final_kernel
=
1
)
return
model
src/lib/models/Backbone/msra_resnet.py
0 → 100644
View file @
b952e97b
# ------------------------------------------------------------------------------
# Copyright (c) Microsoft
# Licensed under the MIT License.
# Written by Bin Xiao (Bin.Xiao@microsoft.com)
# Modified by Xingyi Zhou
# ------------------------------------------------------------------------------
from
__future__
import
absolute_import
,
division
,
print_function
import
os
import
torch
import
torch.nn
as
nn
import
torch.utils.model_zoo
as
model_zoo
BN_MOMENTUM
=
0.1
model_urls
=
{
'resnet18'
:
'https://download.pytorch.org/models/resnet18-5c106cde.pth'
,
'resnet34'
:
'https://download.pytorch.org/models/resnet34-333f7ec4.pth'
,
'resnet50'
:
'https://download.pytorch.org/models/resnet50-19c8e357.pth'
,
'resnet101'
:
'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth'
,
'resnet152'
:
'https://download.pytorch.org/models/resnet152-b121ed2d.pth'
,
}
def
conv3x3
(
in_planes
,
out_planes
,
stride
=
1
):
"""3x3 convolution with padding"""
return
nn
.
Conv2d
(
in_planes
,
out_planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
1
,
bias
=
False
)
class
BasicBlock
(
nn
.
Module
):
expansion
=
1
def
__init__
(
self
,
inplanes
,
planes
,
stride
=
1
,
downsample
=
None
):
super
(
BasicBlock
,
self
).
__init__
()
self
.
conv1
=
conv3x3
(
inplanes
,
planes
,
stride
)
self
.
bn1
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
conv2
=
conv3x3
(
planes
,
planes
)
self
.
bn2
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
downsample
=
downsample
self
.
stride
=
stride
def
forward
(
self
,
x
):
residual
=
x
out
=
self
.
conv1
(
x
)
out
=
self
.
bn1
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv2
(
out
)
out
=
self
.
bn2
(
out
)
if
self
.
downsample
is
not
None
:
residual
=
self
.
downsample
(
x
)
out
+=
residual
out
=
self
.
relu
(
out
)
return
out
class
Bottleneck
(
nn
.
Module
):
expansion
=
4
def
__init__
(
self
,
inplanes
,
planes
,
stride
=
1
,
downsample
=
None
):
super
(
Bottleneck
,
self
).
__init__
()
self
.
conv1
=
nn
.
Conv2d
(
inplanes
,
planes
,
kernel_size
=
1
,
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
conv2
=
nn
.
Conv2d
(
planes
,
planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
1
,
bias
=
False
)
self
.
bn2
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
conv3
=
nn
.
Conv2d
(
planes
,
planes
*
self
.
expansion
,
kernel_size
=
1
,
bias
=
False
)
self
.
bn3
=
nn
.
BatchNorm2d
(
planes
*
self
.
expansion
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
downsample
=
downsample
self
.
stride
=
stride
def
forward
(
self
,
x
):
residual
=
x
out
=
self
.
conv1
(
x
)
out
=
self
.
bn1
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv2
(
out
)
out
=
self
.
bn2
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv3
(
out
)
out
=
self
.
bn3
(
out
)
if
self
.
downsample
is
not
None
:
residual
=
self
.
downsample
(
x
)
out
+=
residual
out
=
self
.
relu
(
out
)
return
out
def
fill_fc_weights
(
layers
):
for
m
in
layers
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
nn
.
init
.
normal_
(
m
.
weight
,
std
=
0.001
)
if
m
.
bias
is
not
None
:
nn
.
init
.
constant_
(
m
.
bias
,
0
)
class
PoseResNet
(
nn
.
Module
):
def
__init__
(
self
,
block
,
layers
,
**
kwargs
):
self
.
inplanes
=
64
self
.
deconv_with_bias
=
False
super
(
PoseResNet
,
self
).
__init__
()
self
.
conv1
=
nn
.
Conv2d
(
3
,
64
,
kernel_size
=
7
,
stride
=
2
,
padding
=
3
,
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
64
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
maxpool
=
nn
.
MaxPool2d
(
kernel_size
=
3
,
stride
=
2
,
padding
=
1
)
self
.
layer1
=
self
.
_make_layer
(
block
,
64
,
layers
[
0
])
self
.
layer2
=
self
.
_make_layer
(
block
,
128
,
layers
[
1
],
stride
=
2
)
self
.
layer3
=
self
.
_make_layer
(
block
,
256
,
layers
[
2
],
stride
=
2
)
self
.
layer4
=
self
.
_make_layer
(
block
,
512
,
layers
[
3
],
stride
=
2
)
# used for deconv layers
self
.
deconv_layers
=
self
.
_make_deconv_layer
(
3
,
[
256
,
256
,
256
],
[
4
,
4
,
4
],
)
def
_make_layer
(
self
,
block
,
planes
,
blocks
,
stride
=
1
):
downsample
=
None
if
stride
!=
1
or
self
.
inplanes
!=
planes
*
block
.
expansion
:
downsample
=
nn
.
Sequential
(
nn
.
Conv2d
(
self
.
inplanes
,
planes
*
block
.
expansion
,
kernel_size
=
1
,
stride
=
stride
,
bias
=
False
),
nn
.
BatchNorm2d
(
planes
*
block
.
expansion
,
momentum
=
BN_MOMENTUM
),
)
layers
=
[]
layers
.
append
(
block
(
self
.
inplanes
,
planes
,
stride
,
downsample
))
self
.
inplanes
=
planes
*
block
.
expansion
for
i
in
range
(
1
,
blocks
):
layers
.
append
(
block
(
self
.
inplanes
,
planes
))
return
nn
.
Sequential
(
*
layers
)
def
_get_deconv_cfg
(
self
,
deconv_kernel
,
index
):
if
deconv_kernel
==
4
:
padding
=
1
output_padding
=
0
elif
deconv_kernel
==
3
:
padding
=
1
output_padding
=
1
elif
deconv_kernel
==
2
:
padding
=
0
output_padding
=
0
return
deconv_kernel
,
padding
,
output_padding
def
_make_deconv_layer
(
self
,
num_layers
,
num_filters
,
num_kernels
):
assert
num_layers
==
len
(
num_filters
),
\
'ERROR: num_deconv_layers is different len(num_deconv_filters)'
assert
num_layers
==
len
(
num_kernels
),
\
'ERROR: num_deconv_layers is different len(num_deconv_filters)'
layers
=
[]
for
i
in
range
(
num_layers
):
kernel
,
padding
,
output_padding
=
\
self
.
_get_deconv_cfg
(
num_kernels
[
i
],
i
)
planes
=
num_filters
[
i
]
layers
.
append
(
nn
.
ConvTranspose2d
(
in_channels
=
self
.
inplanes
,
out_channels
=
planes
,
kernel_size
=
kernel
,
stride
=
2
,
padding
=
padding
,
output_padding
=
output_padding
,
bias
=
self
.
deconv_with_bias
))
layers
.
append
(
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
))
layers
.
append
(
nn
.
ReLU
(
inplace
=
True
))
self
.
inplanes
=
planes
return
nn
.
Sequential
(
*
layers
)
def
forward
(
self
,
x
):
x
=
self
.
conv1
(
x
)
x
=
self
.
bn1
(
x
)
x
=
self
.
relu
(
x
)
x
=
self
.
maxpool
(
x
)
x
=
self
.
layer1
(
x
)
x
=
self
.
layer2
(
x
)
x
=
self
.
layer3
(
x
)
x
=
self
.
layer4
(
x
)
x
=
self
.
deconv_layers
(
x
)
return
x
def
init_weights
(
self
,
num_layers
,
pretrained
=
True
):
if
pretrained
:
# print('=> init resnet deconv weights from normal distribution')
for
_
,
m
in
self
.
deconv_layers
.
named_modules
():
if
isinstance
(
m
,
nn
.
ConvTranspose2d
):
# print('=> init {}.weight as normal(0, 0.001)'.format(name))
# print('=> init {}.bias as 0'.format(name))
nn
.
init
.
normal_
(
m
.
weight
,
std
=
0.001
)
if
self
.
deconv_with_bias
:
nn
.
init
.
constant_
(
m
.
bias
,
0
)
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
# print('=> init {}.weight as 1'.format(name))
# print('=> init {}.bias as 0'.format(name))
nn
.
init
.
constant_
(
m
.
weight
,
1
)
nn
.
init
.
constant_
(
m
.
bias
,
0
)
#pretrained_state_dict = torch.load(pretrained)
url
=
model_urls
[
'resnet{}'
.
format
(
num_layers
)]
pretrained_state_dict
=
model_zoo
.
load_url
(
url
)
print
(
'=> loading pretrained model {}'
.
format
(
url
))
self
.
load_state_dict
(
pretrained_state_dict
,
strict
=
False
)
else
:
print
(
'=> imagenet pretrained model dose not exist'
)
print
(
'=> please download it first'
)
raise
ValueError
(
'imagenet pretrained model does not exist'
)
resnet_spec
=
{
18
:
(
BasicBlock
,
[
2
,
2
,
2
,
2
]),
34
:
(
BasicBlock
,
[
3
,
4
,
6
,
3
]),
50
:
(
Bottleneck
,
[
3
,
4
,
6
,
3
]),
101
:
(
Bottleneck
,
[
3
,
4
,
23
,
3
]),
152
:
(
Bottleneck
,
[
3
,
8
,
36
,
3
])}
def
get_resnet
(
num_layers
,
cfg
):
block_class
,
layers
=
resnet_spec
[
num_layers
]
model
=
PoseResNet
(
block_class
,
layers
)
model
.
init_weights
(
num_layers
,
pretrained
=
True
)
return
model
src/lib/models/Backbone/performance.png
0 → 100644
View file @
b952e97b
48.5 KB
src/lib/models/Backbone/pose_dla_dcn.py
0 → 100644
View file @
b952e97b
from
__future__
import
absolute_import
,
division
,
print_function
import
logging
import
math
import
os
from
os.path
import
join
import
numpy
as
np
import
torch
import
torch.nn.functional
as
F
import
torch.utils.model_zoo
as
model_zoo
from
torch
import
nn
from
.DCNv2.dcn_v2
import
DCN
BN_MOMENTUM
=
0.1
logger
=
logging
.
getLogger
(
__name__
)
def
get_model_url
(
data
=
'imagenet'
,
name
=
'dla34'
,
hash
=
'ba72cf86'
):
return
join
(
'http://dl.yf.io/dla/models'
,
data
,
'{}-{}.pth'
.
format
(
name
,
hash
))
def
conv3x3
(
in_planes
,
out_planes
,
stride
=
1
):
"3x3 convolution with padding"
return
nn
.
Conv2d
(
in_planes
,
out_planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
1
,
bias
=
False
)
class
BasicBlock
(
nn
.
Module
):
def
__init__
(
self
,
inplanes
,
planes
,
stride
=
1
,
dilation
=
1
):
super
(
BasicBlock
,
self
).
__init__
()
self
.
conv1
=
nn
.
Conv2d
(
inplanes
,
planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
dilation
,
bias
=
False
,
dilation
=
dilation
)
self
.
bn1
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
conv2
=
nn
.
Conv2d
(
planes
,
planes
,
kernel_size
=
3
,
stride
=
1
,
padding
=
dilation
,
bias
=
False
,
dilation
=
dilation
)
self
.
bn2
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
stride
=
stride
def
forward
(
self
,
x
,
residual
=
None
):
if
residual
is
None
:
residual
=
x
out
=
self
.
conv1
(
x
)
out
=
self
.
bn1
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv2
(
out
)
out
=
self
.
bn2
(
out
)
out
+=
residual
out
=
self
.
relu
(
out
)
return
out
class
Bottleneck
(
nn
.
Module
):
expansion
=
2
def
__init__
(
self
,
inplanes
,
planes
,
stride
=
1
,
dilation
=
1
):
super
(
Bottleneck
,
self
).
__init__
()
expansion
=
Bottleneck
.
expansion
bottle_planes
=
planes
//
expansion
self
.
conv1
=
nn
.
Conv2d
(
inplanes
,
bottle_planes
,
kernel_size
=
1
,
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
bottle_planes
,
momentum
=
BN_MOMENTUM
)
self
.
conv2
=
nn
.
Conv2d
(
bottle_planes
,
bottle_planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
dilation
,
bias
=
False
,
dilation
=
dilation
)
self
.
bn2
=
nn
.
BatchNorm2d
(
bottle_planes
,
momentum
=
BN_MOMENTUM
)
self
.
conv3
=
nn
.
Conv2d
(
bottle_planes
,
planes
,
kernel_size
=
1
,
bias
=
False
)
self
.
bn3
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
stride
=
stride
def
forward
(
self
,
x
,
residual
=
None
):
if
residual
is
None
:
residual
=
x
out
=
self
.
conv1
(
x
)
out
=
self
.
bn1
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv2
(
out
)
out
=
self
.
bn2
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv3
(
out
)
out
=
self
.
bn3
(
out
)
out
+=
residual
out
=
self
.
relu
(
out
)
return
out
class
BottleneckX
(
nn
.
Module
):
expansion
=
2
cardinality
=
32
def
__init__
(
self
,
inplanes
,
planes
,
stride
=
1
,
dilation
=
1
):
super
(
BottleneckX
,
self
).
__init__
()
cardinality
=
BottleneckX
.
cardinality
# dim = int(math.floor(planes * (BottleneckV5.expansion / 64.0)))
# bottle_planes = dim * cardinality
bottle_planes
=
planes
*
cardinality
//
32
self
.
conv1
=
nn
.
Conv2d
(
inplanes
,
bottle_planes
,
kernel_size
=
1
,
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
bottle_planes
,
momentum
=
BN_MOMENTUM
)
self
.
conv2
=
nn
.
Conv2d
(
bottle_planes
,
bottle_planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
dilation
,
bias
=
False
,
dilation
=
dilation
,
groups
=
cardinality
)
self
.
bn2
=
nn
.
BatchNorm2d
(
bottle_planes
,
momentum
=
BN_MOMENTUM
)
self
.
conv3
=
nn
.
Conv2d
(
bottle_planes
,
planes
,
kernel_size
=
1
,
bias
=
False
)
self
.
bn3
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
stride
=
stride
def
forward
(
self
,
x
,
residual
=
None
):
if
residual
is
None
:
residual
=
x
out
=
self
.
conv1
(
x
)
out
=
self
.
bn1
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv2
(
out
)
out
=
self
.
bn2
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv3
(
out
)
out
=
self
.
bn3
(
out
)
out
+=
residual
out
=
self
.
relu
(
out
)
return
out
class
Root
(
nn
.
Module
):
def
__init__
(
self
,
in_channels
,
out_channels
,
kernel_size
,
residual
):
super
(
Root
,
self
).
__init__
()
self
.
conv
=
nn
.
Conv2d
(
in_channels
,
out_channels
,
1
,
stride
=
1
,
bias
=
False
,
padding
=
(
kernel_size
-
1
)
//
2
)
self
.
bn
=
nn
.
BatchNorm2d
(
out_channels
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
residual
=
residual
def
forward
(
self
,
*
x
):
children
=
x
x
=
self
.
conv
(
torch
.
cat
(
x
,
1
))
x
=
self
.
bn
(
x
)
if
self
.
residual
:
x
+=
children
[
0
]
x
=
self
.
relu
(
x
)
return
x
class
Tree
(
nn
.
Module
):
def
__init__
(
self
,
levels
,
block
,
in_channels
,
out_channels
,
stride
=
1
,
level_root
=
False
,
root_dim
=
0
,
root_kernel_size
=
1
,
dilation
=
1
,
root_residual
=
False
):
super
(
Tree
,
self
).
__init__
()
if
root_dim
==
0
:
root_dim
=
2
*
out_channels
if
level_root
:
root_dim
+=
in_channels
if
levels
==
1
:
self
.
tree1
=
block
(
in_channels
,
out_channels
,
stride
,
dilation
=
dilation
)
self
.
tree2
=
block
(
out_channels
,
out_channels
,
1
,
dilation
=
dilation
)
else
:
self
.
tree1
=
Tree
(
levels
-
1
,
block
,
in_channels
,
out_channels
,
stride
,
root_dim
=
0
,
root_kernel_size
=
root_kernel_size
,
dilation
=
dilation
,
root_residual
=
root_residual
)
self
.
tree2
=
Tree
(
levels
-
1
,
block
,
out_channels
,
out_channels
,
root_dim
=
root_dim
+
out_channels
,
root_kernel_size
=
root_kernel_size
,
dilation
=
dilation
,
root_residual
=
root_residual
)
if
levels
==
1
:
self
.
root
=
Root
(
root_dim
,
out_channels
,
root_kernel_size
,
root_residual
)
self
.
level_root
=
level_root
self
.
root_dim
=
root_dim
self
.
downsample
=
None
self
.
project
=
None
self
.
levels
=
levels
if
stride
>
1
:
self
.
downsample
=
nn
.
MaxPool2d
(
stride
,
stride
=
stride
)
if
in_channels
!=
out_channels
:
self
.
project
=
nn
.
Sequential
(
nn
.
Conv2d
(
in_channels
,
out_channels
,
kernel_size
=
1
,
stride
=
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
out_channels
,
momentum
=
BN_MOMENTUM
)
)
def
forward
(
self
,
x
,
residual
=
None
,
children
=
None
):
children
=
[]
if
children
is
None
else
children
bottom
=
self
.
downsample
(
x
)
if
self
.
downsample
else
x
residual
=
self
.
project
(
bottom
)
if
self
.
project
else
bottom
if
self
.
level_root
:
children
.
append
(
bottom
)
x1
=
self
.
tree1
(
x
,
residual
)
if
self
.
levels
==
1
:
x2
=
self
.
tree2
(
x1
)
x
=
self
.
root
(
x2
,
x1
,
*
children
)
else
:
children
.
append
(
x1
)
x
=
self
.
tree2
(
x1
,
children
=
children
)
return
x
class
DLA
(
nn
.
Module
):
def
__init__
(
self
,
levels
,
channels
,
num_classes
=
1000
,
block
=
BasicBlock
,
residual_root
=
False
,
linear_root
=
False
):
super
(
DLA
,
self
).
__init__
()
self
.
channels
=
channels
self
.
num_classes
=
num_classes
self
.
base_layer
=
nn
.
Sequential
(
nn
.
Conv2d
(
3
,
channels
[
0
],
kernel_size
=
7
,
stride
=
1
,
padding
=
3
,
bias
=
False
),
nn
.
BatchNorm2d
(
channels
[
0
],
momentum
=
BN_MOMENTUM
),
nn
.
ReLU
(
inplace
=
True
))
self
.
level0
=
self
.
_make_conv_level
(
channels
[
0
],
channels
[
0
],
levels
[
0
])
self
.
level1
=
self
.
_make_conv_level
(
channels
[
0
],
channels
[
1
],
levels
[
1
],
stride
=
2
)
self
.
level2
=
Tree
(
levels
[
2
],
block
,
channels
[
1
],
channels
[
2
],
2
,
level_root
=
False
,
root_residual
=
residual_root
)
self
.
level3
=
Tree
(
levels
[
3
],
block
,
channels
[
2
],
channels
[
3
],
2
,
level_root
=
True
,
root_residual
=
residual_root
)
self
.
level4
=
Tree
(
levels
[
4
],
block
,
channels
[
3
],
channels
[
4
],
2
,
level_root
=
True
,
root_residual
=
residual_root
)
self
.
level5
=
Tree
(
levels
[
5
],
block
,
channels
[
4
],
channels
[
5
],
2
,
level_root
=
True
,
root_residual
=
residual_root
)
# for m in self.modules():
# if isinstance(m, nn.Conv2d):
# n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# m.weight.data.normal_(0, math.sqrt(2. / n))
# elif isinstance(m, nn.BatchNorm2d):
# m.weight.data.fill_(1)
# m.bias.data.zero_()
def
_make_level
(
self
,
block
,
inplanes
,
planes
,
blocks
,
stride
=
1
):
downsample
=
None
if
stride
!=
1
or
inplanes
!=
planes
:
downsample
=
nn
.
Sequential
(
nn
.
MaxPool2d
(
stride
,
stride
=
stride
),
nn
.
Conv2d
(
inplanes
,
planes
,
kernel_size
=
1
,
stride
=
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
),
)
layers
=
[]
layers
.
append
(
block
(
inplanes
,
planes
,
stride
,
downsample
=
downsample
))
for
i
in
range
(
1
,
blocks
):
layers
.
append
(
block
(
inplanes
,
planes
))
return
nn
.
Sequential
(
*
layers
)
def
_make_conv_level
(
self
,
inplanes
,
planes
,
convs
,
stride
=
1
,
dilation
=
1
):
modules
=
[]
for
i
in
range
(
convs
):
modules
.
extend
([
nn
.
Conv2d
(
inplanes
,
planes
,
kernel_size
=
3
,
stride
=
stride
if
i
==
0
else
1
,
padding
=
dilation
,
bias
=
False
,
dilation
=
dilation
),
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
),
nn
.
ReLU
(
inplace
=
True
)])
inplanes
=
planes
return
nn
.
Sequential
(
*
modules
)
def
forward
(
self
,
x
):
y
=
[]
x
=
self
.
base_layer
(
x
)
for
i
in
range
(
6
):
x
=
getattr
(
self
,
'level{}'
.
format
(
i
))(
x
)
y
.
append
(
x
)
return
y
def
load_pretrained_model
(
self
,
data
=
'imagenet'
,
name
=
'dla34'
,
hash
=
'ba72cf86'
):
# fc = self.fc
if
name
.
endswith
(
'.pth'
):
model_weights
=
torch
.
load
(
data
+
name
)
else
:
model_url
=
get_model_url
(
data
,
name
,
hash
)
model_weights
=
model_zoo
.
load_url
(
model_url
)
num_classes
=
len
(
model_weights
[
list
(
model_weights
.
keys
())[
-
1
]])
self
.
fc
=
nn
.
Conv2d
(
self
.
channels
[
-
1
],
num_classes
,
kernel_size
=
1
,
stride
=
1
,
padding
=
0
,
bias
=
True
)
self
.
load_state_dict
(
model_weights
)
# self.fc = fc
def
dla34
(
pretrained
=
True
,
**
kwargs
):
# DLA-34
model
=
DLA
([
1
,
1
,
1
,
2
,
2
,
1
],
[
16
,
32
,
64
,
128
,
256
,
512
],
block
=
BasicBlock
,
**
kwargs
)
if
pretrained
:
model
.
load_pretrained_model
(
data
=
'imagenet'
,
name
=
'dla34'
,
hash
=
'ba72cf86'
)
return
model
class
Identity
(
nn
.
Module
):
def
__init__
(
self
):
super
(
Identity
,
self
).
__init__
()
def
forward
(
self
,
x
):
return
x
def
fill_up_weights
(
up
):
w
=
up
.
weight
.
data
f
=
math
.
ceil
(
w
.
size
(
2
)
/
2
)
c
=
(
2
*
f
-
1
-
f
%
2
)
/
(
2.
*
f
)
for
i
in
range
(
w
.
size
(
2
)):
for
j
in
range
(
w
.
size
(
3
)):
w
[
0
,
0
,
i
,
j
]
=
\
(
1
-
math
.
fabs
(
i
/
f
-
c
))
*
(
1
-
math
.
fabs
(
j
/
f
-
c
))
for
c
in
range
(
1
,
w
.
size
(
0
)):
w
[
c
,
0
,
:,
:]
=
w
[
0
,
0
,
:,
:]
class
DeformConv
(
nn
.
Module
):
def
__init__
(
self
,
chi
,
cho
):
super
(
DeformConv
,
self
).
__init__
()
self
.
actf
=
nn
.
Sequential
(
nn
.
BatchNorm2d
(
cho
,
momentum
=
BN_MOMENTUM
),
nn
.
ReLU
(
inplace
=
True
)
)
self
.
conv
=
DCN
(
chi
,
cho
,
kernel_size
=
(
3
,
3
),
stride
=
1
,
padding
=
1
,
dilation
=
1
,
deformable_groups
=
1
)
def
forward
(
self
,
x
):
x
=
self
.
conv
(
x
)
x
=
self
.
actf
(
x
)
return
x
class
IDAUp
(
nn
.
Module
):
def
__init__
(
self
,
o
,
channels
,
up_f
):
super
(
IDAUp
,
self
).
__init__
()
for
i
in
range
(
1
,
len
(
channels
)):
c
=
channels
[
i
]
f
=
int
(
up_f
[
i
])
proj
=
DeformConv
(
c
,
o
)
node
=
DeformConv
(
o
,
o
)
up
=
nn
.
ConvTranspose2d
(
o
,
o
,
f
*
2
,
stride
=
f
,
padding
=
f
//
2
,
output_padding
=
0
,
groups
=
o
,
bias
=
False
)
fill_up_weights
(
up
)
setattr
(
self
,
'proj_'
+
str
(
i
),
proj
)
setattr
(
self
,
'up_'
+
str
(
i
),
up
)
setattr
(
self
,
'node_'
+
str
(
i
),
node
)
def
forward
(
self
,
layers
,
startp
,
endp
):
for
i
in
range
(
startp
+
1
,
endp
):
upsample
=
getattr
(
self
,
'up_'
+
str
(
i
-
startp
))
project
=
getattr
(
self
,
'proj_'
+
str
(
i
-
startp
))
layers
[
i
]
=
upsample
(
project
(
layers
[
i
]))
node
=
getattr
(
self
,
'node_'
+
str
(
i
-
startp
))
layers
[
i
]
=
node
(
layers
[
i
]
+
layers
[
i
-
1
])
class
DLAUp
(
nn
.
Module
):
def
__init__
(
self
,
startp
,
channels
,
scales
,
in_channels
=
None
):
super
(
DLAUp
,
self
).
__init__
()
self
.
startp
=
startp
if
in_channels
is
None
:
in_channels
=
channels
self
.
channels
=
channels
channels
=
list
(
channels
)
scales
=
np
.
array
(
scales
,
dtype
=
int
)
for
i
in
range
(
len
(
channels
)
-
1
):
j
=
-
i
-
2
setattr
(
self
,
'ida_{}'
.
format
(
i
),
IDAUp
(
channels
[
j
],
in_channels
[
j
:],
scales
[
j
:]
//
scales
[
j
]))
scales
[
j
+
1
:]
=
scales
[
j
]
in_channels
[
j
+
1
:]
=
[
channels
[
j
]
for
_
in
channels
[
j
+
1
:]]
def
forward
(
self
,
layers
):
out
=
[
layers
[
-
1
]]
# start with 32
for
i
in
range
(
len
(
layers
)
-
self
.
startp
-
1
):
ida
=
getattr
(
self
,
'ida_{}'
.
format
(
i
))
ida
(
layers
,
len
(
layers
)
-
i
-
2
,
len
(
layers
))
out
.
insert
(
0
,
layers
[
-
1
])
return
out
class
Interpolate
(
nn
.
Module
):
def
__init__
(
self
,
scale
,
mode
):
super
(
Interpolate
,
self
).
__init__
()
self
.
scale
=
scale
self
.
mode
=
mode
def
forward
(
self
,
x
):
x
=
F
.
interpolate
(
x
,
scale_factor
=
self
.
scale
,
mode
=
self
.
mode
,
align_corners
=
False
)
return
x
class
DLASeg
(
nn
.
Module
):
def
__init__
(
self
,
base_name
,
pretrained
,
down_ratio
,
final_kernel
,
last_level
,
out_channel
=
0
):
super
(
DLASeg
,
self
).
__init__
()
assert
down_ratio
in
[
2
,
4
,
8
,
16
]
self
.
first_level
=
int
(
np
.
log2
(
down_ratio
))
self
.
last_level
=
last_level
self
.
base
=
globals
()[
base_name
](
pretrained
=
pretrained
)
channels
=
self
.
base
.
channels
scales
=
[
2
**
i
for
i
in
range
(
len
(
channels
[
self
.
first_level
:]))]
self
.
dla_up
=
DLAUp
(
self
.
first_level
,
channels
[
self
.
first_level
:],
scales
)
if
out_channel
==
0
:
out_channel
=
channels
[
self
.
first_level
]
self
.
ida_up
=
IDAUp
(
out_channel
,
channels
[
self
.
first_level
:
self
.
last_level
],
[
2
**
i
for
i
in
range
(
self
.
last_level
-
self
.
first_level
)])
def
forward
(
self
,
x
):
x
=
self
.
base
(
x
)
x
=
self
.
dla_up
(
x
)
y
=
[]
for
i
in
range
(
self
.
last_level
-
self
.
first_level
):
y
.
append
(
x
[
i
].
clone
())
self
.
ida_up
(
y
,
0
,
len
(
y
))
x
=
y
[
-
1
]
return
x
def
get_pose_net
(
num_layers
,
cfg
=
None
,
down_ratio
=
4
):
model
=
DLASeg
(
'dla{}'
.
format
(
num_layers
),
pretrained
=
True
,
down_ratio
=
down_ratio
,
final_kernel
=
1
,
last_level
=
5
)
return
model
src/lib/models/Backbone/pose_higher_hrnet.py
0 → 100644
View file @
b952e97b
# ------------------------------------------------------------------------------
# Copyright (c) Microsoft
# Licensed under the MIT License.
# Written by Bin Xiao (leoxiaobin@gmail.com)
# Modified by Bowen Cheng (bcheng9@illinois.edu)
# ------------------------------------------------------------------------------
from
__future__
import
absolute_import
,
division
,
print_function
import
logging
import
os
import
torch
import
torch.nn
as
nn
BN_MOMENTUM
=
0.1
logger
=
logging
.
getLogger
(
__name__
)
def
conv3x3
(
in_planes
,
out_planes
,
stride
=
1
):
"""3x3 convolution with padding"""
return
nn
.
Conv2d
(
in_planes
,
out_planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
1
,
bias
=
False
)
class
BasicBlock
(
nn
.
Module
):
expansion
=
1
def
__init__
(
self
,
inplanes
,
planes
,
stride
=
1
,
downsample
=
None
):
super
(
BasicBlock
,
self
).
__init__
()
self
.
conv1
=
conv3x3
(
inplanes
,
planes
,
stride
)
self
.
bn1
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
conv2
=
conv3x3
(
planes
,
planes
)
self
.
bn2
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
downsample
=
downsample
self
.
stride
=
stride
def
forward
(
self
,
x
):
residual
=
x
out
=
self
.
conv1
(
x
)
out
=
self
.
bn1
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv2
(
out
)
out
=
self
.
bn2
(
out
)
if
self
.
downsample
is
not
None
:
residual
=
self
.
downsample
(
x
)
out
+=
residual
out
=
self
.
relu
(
out
)
return
out
class
Bottleneck
(
nn
.
Module
):
expansion
=
4
def
__init__
(
self
,
inplanes
,
planes
,
stride
=
1
,
downsample
=
None
):
super
(
Bottleneck
,
self
).
__init__
()
self
.
conv1
=
nn
.
Conv2d
(
inplanes
,
planes
,
kernel_size
=
1
,
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
conv2
=
nn
.
Conv2d
(
planes
,
planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
1
,
bias
=
False
)
self
.
bn2
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
conv3
=
nn
.
Conv2d
(
planes
,
planes
*
self
.
expansion
,
kernel_size
=
1
,
bias
=
False
)
self
.
bn3
=
nn
.
BatchNorm2d
(
planes
*
self
.
expansion
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
downsample
=
downsample
self
.
stride
=
stride
def
forward
(
self
,
x
):
residual
=
x
out
=
self
.
conv1
(
x
)
out
=
self
.
bn1
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv2
(
out
)
out
=
self
.
bn2
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv3
(
out
)
out
=
self
.
bn3
(
out
)
if
self
.
downsample
is
not
None
:
residual
=
self
.
downsample
(
x
)
out
+=
residual
out
=
self
.
relu
(
out
)
return
out
class
HighResolutionModule
(
nn
.
Module
):
def
__init__
(
self
,
num_branches
,
blocks
,
num_blocks
,
num_inchannels
,
num_channels
,
fuse_method
,
multi_scale_output
=
True
):
super
(
HighResolutionModule
,
self
).
__init__
()
self
.
_check_branches
(
num_branches
,
blocks
,
num_blocks
,
num_inchannels
,
num_channels
)
self
.
num_inchannels
=
num_inchannels
self
.
fuse_method
=
fuse_method
self
.
num_branches
=
num_branches
self
.
multi_scale_output
=
multi_scale_output
self
.
branches
=
self
.
_make_branches
(
num_branches
,
blocks
,
num_blocks
,
num_channels
)
self
.
fuse_layers
=
self
.
_make_fuse_layers
()
self
.
relu
=
nn
.
ReLU
(
True
)
def
_check_branches
(
self
,
num_branches
,
blocks
,
num_blocks
,
num_inchannels
,
num_channels
):
if
num_branches
!=
len
(
num_blocks
):
error_msg
=
'NUM_BRANCHES({}) <> NUM_BLOCKS({})'
.
format
(
num_branches
,
len
(
num_blocks
))
logger
.
error
(
error_msg
)
raise
ValueError
(
error_msg
)
if
num_branches
!=
len
(
num_channels
):
error_msg
=
'NUM_BRANCHES({}) <> NUM_CHANNELS({})'
.
format
(
num_branches
,
len
(
num_channels
))
logger
.
error
(
error_msg
)
raise
ValueError
(
error_msg
)
if
num_branches
!=
len
(
num_inchannels
):
error_msg
=
'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'
.
format
(
num_branches
,
len
(
num_inchannels
))
logger
.
error
(
error_msg
)
raise
ValueError
(
error_msg
)
def
_make_one_branch
(
self
,
branch_index
,
block
,
num_blocks
,
num_channels
,
stride
=
1
):
downsample
=
None
if
stride
!=
1
or
\
self
.
num_inchannels
[
branch_index
]
!=
num_channels
[
branch_index
]
*
block
.
expansion
:
downsample
=
nn
.
Sequential
(
nn
.
Conv2d
(
self
.
num_inchannels
[
branch_index
],
num_channels
[
branch_index
]
*
block
.
expansion
,
kernel_size
=
1
,
stride
=
stride
,
bias
=
False
),
nn
.
BatchNorm2d
(
num_channels
[
branch_index
]
*
block
.
expansion
,
momentum
=
BN_MOMENTUM
),
)
layers
=
[]
layers
.
append
(
block
(
self
.
num_inchannels
[
branch_index
],
num_channels
[
branch_index
],
stride
,
downsample
))
self
.
num_inchannels
[
branch_index
]
=
\
num_channels
[
branch_index
]
*
block
.
expansion
for
i
in
range
(
1
,
num_blocks
[
branch_index
]):
layers
.
append
(
block
(
self
.
num_inchannels
[
branch_index
],
num_channels
[
branch_index
]))
return
nn
.
Sequential
(
*
layers
)
def
_make_branches
(
self
,
num_branches
,
block
,
num_blocks
,
num_channels
):
branches
=
[]
for
i
in
range
(
num_branches
):
branches
.
append
(
self
.
_make_one_branch
(
i
,
block
,
num_blocks
,
num_channels
))
return
nn
.
ModuleList
(
branches
)
def
_make_fuse_layers
(
self
):
if
self
.
num_branches
==
1
:
return
None
num_branches
=
self
.
num_branches
num_inchannels
=
self
.
num_inchannels
fuse_layers
=
[]
for
i
in
range
(
num_branches
if
self
.
multi_scale_output
else
1
):
fuse_layer
=
[]
for
j
in
range
(
num_branches
):
if
j
>
i
:
fuse_layer
.
append
(
nn
.
Sequential
(
nn
.
Conv2d
(
num_inchannels
[
j
],
num_inchannels
[
i
],
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
num_inchannels
[
i
]),
nn
.
Upsample
(
scale_factor
=
2
**
(
j
-
i
),
mode
=
'nearest'
)))
elif
j
==
i
:
fuse_layer
.
append
(
None
)
else
:
conv3x3s
=
[]
for
k
in
range
(
i
-
j
):
if
k
==
i
-
j
-
1
:
num_outchannels_conv3x3
=
num_inchannels
[
i
]
conv3x3s
.
append
(
nn
.
Sequential
(
nn
.
Conv2d
(
num_inchannels
[
j
],
num_outchannels_conv3x3
,
3
,
2
,
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
num_outchannels_conv3x3
)))
else
:
num_outchannels_conv3x3
=
num_inchannels
[
j
]
conv3x3s
.
append
(
nn
.
Sequential
(
nn
.
Conv2d
(
num_inchannels
[
j
],
num_outchannels_conv3x3
,
3
,
2
,
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
num_outchannels_conv3x3
),
nn
.
ReLU
(
True
)))
fuse_layer
.
append
(
nn
.
Sequential
(
*
conv3x3s
))
fuse_layers
.
append
(
nn
.
ModuleList
(
fuse_layer
))
return
nn
.
ModuleList
(
fuse_layers
)
def
get_num_inchannels
(
self
):
return
self
.
num_inchannels
def
forward
(
self
,
x
):
if
self
.
num_branches
==
1
:
return
[
self
.
branches
[
0
](
x
[
0
])]
for
i
in
range
(
self
.
num_branches
):
x
[
i
]
=
self
.
branches
[
i
](
x
[
i
])
x_fuse
=
[]
for
i
in
range
(
len
(
self
.
fuse_layers
)):
y
=
x
[
0
]
if
i
==
0
else
self
.
fuse_layers
[
i
][
0
](
x
[
0
])
for
j
in
range
(
1
,
self
.
num_branches
):
if
i
==
j
:
y
=
y
+
x
[
j
]
else
:
y
=
y
+
self
.
fuse_layers
[
i
][
j
](
x
[
j
])
x_fuse
.
append
(
self
.
relu
(
y
))
return
x_fuse
blocks_dict
=
{
'BASIC'
:
BasicBlock
,
'BOTTLENECK'
:
Bottleneck
}
class
PoseHigherResolutionNet
(
nn
.
Module
):
def
__init__
(
self
,
cfg
,
**
kwargs
):
self
.
inplanes
=
64
extra
=
cfg
.
MODEL
.
EXTRA
super
(
PoseHigherResolutionNet
,
self
).
__init__
()
# stem net
self
.
conv1
=
nn
.
Conv2d
(
3
,
64
,
kernel_size
=
3
,
stride
=
2
,
padding
=
1
,
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
64
,
momentum
=
BN_MOMENTUM
)
self
.
conv2
=
nn
.
Conv2d
(
64
,
64
,
kernel_size
=
3
,
stride
=
2
,
padding
=
1
,
bias
=
False
)
self
.
bn2
=
nn
.
BatchNorm2d
(
64
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
layer1
=
self
.
_make_layer
(
Bottleneck
,
64
,
4
)
self
.
stage2_cfg
=
cfg
[
'MODEL'
][
'EXTRA'
][
'STAGE2'
]
num_channels
=
self
.
stage2_cfg
[
'NUM_CHANNELS'
]
block
=
blocks_dict
[
self
.
stage2_cfg
[
'BLOCK'
]]
num_channels
=
[
num_channels
[
i
]
*
block
.
expansion
for
i
in
range
(
len
(
num_channels
))
]
self
.
transition1
=
self
.
_make_transition_layer
([
256
],
num_channels
)
self
.
stage2
,
pre_stage_channels
=
self
.
_make_stage
(
self
.
stage2_cfg
,
num_channels
)
self
.
stage3_cfg
=
cfg
[
'MODEL'
][
'EXTRA'
][
'STAGE3'
]
num_channels
=
self
.
stage3_cfg
[
'NUM_CHANNELS'
]
block
=
blocks_dict
[
self
.
stage3_cfg
[
'BLOCK'
]]
num_channels
=
[
num_channels
[
i
]
*
block
.
expansion
for
i
in
range
(
len
(
num_channels
))
]
self
.
transition2
=
self
.
_make_transition_layer
(
pre_stage_channels
,
num_channels
)
self
.
stage3
,
pre_stage_channels
=
self
.
_make_stage
(
self
.
stage3_cfg
,
num_channels
)
self
.
stage4_cfg
=
cfg
[
'MODEL'
][
'EXTRA'
][
'STAGE4'
]
num_channels
=
self
.
stage4_cfg
[
'NUM_CHANNELS'
]
block
=
blocks_dict
[
self
.
stage4_cfg
[
'BLOCK'
]]
num_channels
=
[
num_channels
[
i
]
*
block
.
expansion
for
i
in
range
(
len
(
num_channels
))
]
self
.
transition3
=
self
.
_make_transition_layer
(
pre_stage_channels
,
num_channels
)
self
.
stage4
,
pre_stage_channels
=
self
.
_make_stage
(
self
.
stage4_cfg
,
num_channels
,
multi_scale_output
=
False
)
#self.final_layers = self._make_final_layers(cfg, pre_stage_channels[0])
#self.deconv_layers = self._make_deconv_layers(
# cfg, pre_stage_channels[0])
self
.
num_deconvs
=
extra
.
DECONV
.
NUM_DECONVS
self
.
deconv_config
=
cfg
.
MODEL
.
EXTRA
.
DECONV
self
.
loss_config
=
cfg
.
LOSS
self
.
pretrained_layers
=
cfg
[
'MODEL'
][
'EXTRA'
][
'PRETRAINED_LAYERS'
]
def
_make_final_layers
(
self
,
cfg
,
input_channels
):
dim_tag
=
cfg
.
MODEL
.
NUM_JOINTS
if
cfg
.
MODEL
.
TAG_PER_JOINT
else
1
extra
=
cfg
.
MODEL
.
EXTRA
final_layers
=
[]
output_channels
=
cfg
.
MODEL
.
NUM_JOINTS
+
dim_tag
\
if
cfg
.
LOSS
.
WITH_AE_LOSS
[
0
]
else
cfg
.
MODEL
.
NUM_JOINTS
final_layers
.
append
(
nn
.
Conv2d
(
in_channels
=
input_channels
,
out_channels
=
output_channels
,
kernel_size
=
extra
.
FINAL_CONV_KERNEL
,
stride
=
1
,
padding
=
1
if
extra
.
FINAL_CONV_KERNEL
==
3
else
0
))
deconv_cfg
=
extra
.
DECONV
for
i
in
range
(
deconv_cfg
.
NUM_DECONVS
):
input_channels
=
deconv_cfg
.
NUM_CHANNELS
[
i
]
output_channels
=
cfg
.
MODEL
.
NUM_JOINTS
+
dim_tag
\
if
cfg
.
LOSS
.
WITH_AE_LOSS
[
i
+
1
]
else
cfg
.
MODEL
.
NUM_JOINTS
final_layers
.
append
(
nn
.
Conv2d
(
in_channels
=
input_channels
,
out_channels
=
output_channels
,
kernel_size
=
extra
.
FINAL_CONV_KERNEL
,
stride
=
1
,
padding
=
1
if
extra
.
FINAL_CONV_KERNEL
==
3
else
0
))
return
nn
.
ModuleList
(
final_layers
)
def
_make_deconv_layers
(
self
,
cfg
,
input_channels
):
dim_tag
=
cfg
.
MODEL
.
NUM_JOINTS
if
cfg
.
MODEL
.
TAG_PER_JOINT
else
1
extra
=
cfg
.
MODEL
.
EXTRA
deconv_cfg
=
extra
.
DECONV
deconv_layers
=
[]
for
i
in
range
(
deconv_cfg
.
NUM_DECONVS
):
if
deconv_cfg
.
CAT_OUTPUT
[
i
]:
final_output_channels
=
cfg
.
MODEL
.
NUM_JOINTS
+
dim_tag
\
if
cfg
.
LOSS
.
WITH_AE_LOSS
[
i
]
else
cfg
.
MODEL
.
NUM_JOINTS
input_channels
+=
final_output_channels
output_channels
=
deconv_cfg
.
NUM_CHANNELS
[
i
]
deconv_kernel
,
padding
,
output_padding
=
\
self
.
_get_deconv_cfg
(
deconv_cfg
.
KERNEL_SIZE
[
i
])
layers
=
[]
layers
.
append
(
nn
.
Sequential
(
nn
.
ConvTranspose2d
(
in_channels
=
input_channels
,
out_channels
=
output_channels
,
kernel_size
=
deconv_kernel
,
stride
=
2
,
padding
=
padding
,
output_padding
=
output_padding
,
bias
=
False
),
nn
.
BatchNorm2d
(
output_channels
,
momentum
=
BN_MOMENTUM
),
nn
.
ReLU
(
inplace
=
True
)
))
for
_
in
range
(
cfg
.
MODEL
.
EXTRA
.
DECONV
.
NUM_BASIC_BLOCKS
):
layers
.
append
(
nn
.
Sequential
(
BasicBlock
(
output_channels
,
output_channels
),
))
deconv_layers
.
append
(
nn
.
Sequential
(
*
layers
))
input_channels
=
output_channels
return
nn
.
ModuleList
(
deconv_layers
)
def
_get_deconv_cfg
(
self
,
deconv_kernel
):
if
deconv_kernel
==
4
:
padding
=
1
output_padding
=
0
elif
deconv_kernel
==
3
:
padding
=
1
output_padding
=
1
elif
deconv_kernel
==
2
:
padding
=
0
output_padding
=
0
return
deconv_kernel
,
padding
,
output_padding
def
_make_transition_layer
(
self
,
num_channels_pre_layer
,
num_channels_cur_layer
):
num_branches_cur
=
len
(
num_channels_cur_layer
)
num_branches_pre
=
len
(
num_channels_pre_layer
)
transition_layers
=
[]
for
i
in
range
(
num_branches_cur
):
if
i
<
num_branches_pre
:
if
num_channels_cur_layer
[
i
]
!=
num_channels_pre_layer
[
i
]:
transition_layers
.
append
(
nn
.
Sequential
(
nn
.
Conv2d
(
num_channels_pre_layer
[
i
],
num_channels_cur_layer
[
i
],
3
,
1
,
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
num_channels_cur_layer
[
i
]),
nn
.
ReLU
(
inplace
=
True
)))
else
:
transition_layers
.
append
(
None
)
else
:
conv3x3s
=
[]
for
j
in
range
(
i
+
1
-
num_branches_pre
):
inchannels
=
num_channels_pre_layer
[
-
1
]
outchannels
=
num_channels_cur_layer
[
i
]
\
if
j
==
i
-
num_branches_pre
else
inchannels
conv3x3s
.
append
(
nn
.
Sequential
(
nn
.
Conv2d
(
inchannels
,
outchannels
,
3
,
2
,
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
outchannels
),
nn
.
ReLU
(
inplace
=
True
)))
transition_layers
.
append
(
nn
.
Sequential
(
*
conv3x3s
))
return
nn
.
ModuleList
(
transition_layers
)
def
_make_layer
(
self
,
block
,
planes
,
blocks
,
stride
=
1
):
downsample
=
None
if
stride
!=
1
or
self
.
inplanes
!=
planes
*
block
.
expansion
:
downsample
=
nn
.
Sequential
(
nn
.
Conv2d
(
self
.
inplanes
,
planes
*
block
.
expansion
,
kernel_size
=
1
,
stride
=
stride
,
bias
=
False
),
nn
.
BatchNorm2d
(
planes
*
block
.
expansion
,
momentum
=
BN_MOMENTUM
),
)
layers
=
[]
layers
.
append
(
block
(
self
.
inplanes
,
planes
,
stride
,
downsample
))
self
.
inplanes
=
planes
*
block
.
expansion
for
i
in
range
(
1
,
blocks
):
layers
.
append
(
block
(
self
.
inplanes
,
planes
))
return
nn
.
Sequential
(
*
layers
)
def
_make_stage
(
self
,
layer_config
,
num_inchannels
,
multi_scale_output
=
True
):
num_modules
=
layer_config
[
'NUM_MODULES'
]
num_branches
=
layer_config
[
'NUM_BRANCHES'
]
num_blocks
=
layer_config
[
'NUM_BLOCKS'
]
num_channels
=
layer_config
[
'NUM_CHANNELS'
]
block
=
blocks_dict
[
layer_config
[
'BLOCK'
]]
fuse_method
=
layer_config
[
'FUSE_METHOD'
]
modules
=
[]
for
i
in
range
(
num_modules
):
# multi_scale_output is only used last module
if
not
multi_scale_output
and
i
==
num_modules
-
1
:
reset_multi_scale_output
=
False
else
:
reset_multi_scale_output
=
True
modules
.
append
(
HighResolutionModule
(
num_branches
,
block
,
num_blocks
,
num_inchannels
,
num_channels
,
fuse_method
,
reset_multi_scale_output
)
)
num_inchannels
=
modules
[
-
1
].
get_num_inchannels
()
return
nn
.
Sequential
(
*
modules
),
num_inchannels
def
forward
(
self
,
x
):
x
=
self
.
conv1
(
x
)
x
=
self
.
bn1
(
x
)
x
=
self
.
relu
(
x
)
x
=
self
.
conv2
(
x
)
x
=
self
.
bn2
(
x
)
x
=
self
.
relu
(
x
)
x
=
self
.
layer1
(
x
)
x_list
=
[]
for
i
in
range
(
self
.
stage2_cfg
[
'NUM_BRANCHES'
]):
if
self
.
transition1
[
i
]
is
not
None
:
x_list
.
append
(
self
.
transition1
[
i
](
x
))
else
:
x_list
.
append
(
x
)
y_list
=
self
.
stage2
(
x_list
)
x_list
=
[]
for
i
in
range
(
self
.
stage3_cfg
[
'NUM_BRANCHES'
]):
if
self
.
transition2
[
i
]
is
not
None
:
x_list
.
append
(
self
.
transition2
[
i
](
y_list
[
-
1
]))
else
:
x_list
.
append
(
y_list
[
i
])
y_list
=
self
.
stage3
(
x_list
)
x_list
=
[]
for
i
in
range
(
self
.
stage4_cfg
[
'NUM_BRANCHES'
]):
if
self
.
transition3
[
i
]
is
not
None
:
x_list
.
append
(
self
.
transition3
[
i
](
y_list
[
-
1
]))
else
:
x_list
.
append
(
y_list
[
i
])
y_list
=
self
.
stage4
(
x_list
)
x
=
y_list
[
0
]
return
x
def
init_weights
(
self
,
pretrained
=
''
,
verbose
=
True
):
logger
.
info
(
'=> init weights from normal distribution'
)
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
nn
.
init
.
normal_
(
m
.
weight
,
std
=
0.001
)
for
name
,
_
in
m
.
named_parameters
():
if
name
in
[
'bias'
]:
nn
.
init
.
constant_
(
m
.
bias
,
0
)
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
nn
.
init
.
constant_
(
m
.
weight
,
1
)
nn
.
init
.
constant_
(
m
.
bias
,
0
)
elif
isinstance
(
m
,
nn
.
ConvTranspose2d
):
nn
.
init
.
normal_
(
m
.
weight
,
std
=
0.001
)
for
name
,
_
in
m
.
named_parameters
():
if
name
in
[
'bias'
]:
nn
.
init
.
constant_
(
m
.
bias
,
0
)
parameters_names
=
set
()
for
name
,
_
in
self
.
named_parameters
():
parameters_names
.
add
(
name
)
buffers_names
=
set
()
for
name
,
_
in
self
.
named_buffers
():
buffers_names
.
add
(
name
)
if
os
.
path
.
isfile
(
pretrained
):
pretrained_state_dict
=
torch
.
load
(
pretrained
)
logger
.
info
(
'=> loading pretrained model {}'
.
format
(
pretrained
))
need_init_state_dict
=
{}
for
name
,
m
in
pretrained_state_dict
.
items
():
if
name
.
split
(
'.'
)[
0
]
in
self
.
pretrained_layers
\
or
self
.
pretrained_layers
[
0
]
is
'*'
:
if
name
in
parameters_names
or
name
in
buffers_names
:
logger
.
info
(
'=> init {} from {}'
.
format
(
name
,
pretrained
))
need_init_state_dict
[
name
]
=
m
self
.
load_state_dict
(
need_init_state_dict
,
strict
=
False
)
print
(
'High Resolution Network Trained on ImageNet loaded'
)
def
get_hrpose_net
(
num_layers
,
cfg
,
**
kwargs
):
model
=
PoseHigherResolutionNet
(
cfg
,
**
kwargs
)
if
cfg
.
MODEL
.
INIT_WEIGHTS
:
model
.
init_weights
(
cfg
.
MODEL
.
PRETRAINED
)
return
model
src/lib/models/Backbone/resnet_dcn.py
0 → 100644
View file @
b952e97b
# ------------------------------------------------------------------------------
# Copyright (c) Microsoft
# Licensed under the MIT License.
# Written by Bin Xiao (Bin.Xiao@microsoft.com)
# Modified by Dequan Wang and Xingyi Zhou
# ------------------------------------------------------------------------------
from
__future__
import
absolute_import
,
division
,
print_function
import
logging
import
math
import
os
import
torch
import
torch.nn
as
nn
import
torch.utils.model_zoo
as
model_zoo
from
.DCNv2.dcn_v2
import
DCN
BN_MOMENTUM
=
0.1
logger
=
logging
.
getLogger
(
__name__
)
model_urls
=
{
'resnet18'
:
'https://download.pytorch.org/models/resnet18-5c106cde.pth'
,
'resnet34'
:
'https://download.pytorch.org/models/resnet34-333f7ec4.pth'
,
'resnet50'
:
'https://download.pytorch.org/models/resnet50-19c8e357.pth'
,
'resnet101'
:
'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth'
,
'resnet152'
:
'https://download.pytorch.org/models/resnet152-b121ed2d.pth'
,
}
def
conv3x3
(
in_planes
,
out_planes
,
stride
=
1
):
"""3x3 convolution with padding"""
return
nn
.
Conv2d
(
in_planes
,
out_planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
1
,
bias
=
False
)
class
BasicBlock
(
nn
.
Module
):
expansion
=
1
def
__init__
(
self
,
inplanes
,
planes
,
stride
=
1
,
downsample
=
None
):
super
(
BasicBlock
,
self
).
__init__
()
self
.
conv1
=
conv3x3
(
inplanes
,
planes
,
stride
)
self
.
bn1
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
conv2
=
conv3x3
(
planes
,
planes
)
self
.
bn2
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
downsample
=
downsample
self
.
stride
=
stride
def
forward
(
self
,
x
):
residual
=
x
out
=
self
.
conv1
(
x
)
out
=
self
.
bn1
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv2
(
out
)
out
=
self
.
bn2
(
out
)
if
self
.
downsample
is
not
None
:
residual
=
self
.
downsample
(
x
)
out
+=
residual
out
=
self
.
relu
(
out
)
return
out
class
Bottleneck
(
nn
.
Module
):
expansion
=
4
def
__init__
(
self
,
inplanes
,
planes
,
stride
=
1
,
downsample
=
None
):
super
(
Bottleneck
,
self
).
__init__
()
self
.
conv1
=
nn
.
Conv2d
(
inplanes
,
planes
,
kernel_size
=
1
,
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
conv2
=
nn
.
Conv2d
(
planes
,
planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
1
,
bias
=
False
)
self
.
bn2
=
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
)
self
.
conv3
=
nn
.
Conv2d
(
planes
,
planes
*
self
.
expansion
,
kernel_size
=
1
,
bias
=
False
)
self
.
bn3
=
nn
.
BatchNorm2d
(
planes
*
self
.
expansion
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
downsample
=
downsample
self
.
stride
=
stride
def
forward
(
self
,
x
):
residual
=
x
out
=
self
.
conv1
(
x
)
out
=
self
.
bn1
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv2
(
out
)
out
=
self
.
bn2
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
conv3
(
out
)
out
=
self
.
bn3
(
out
)
if
self
.
downsample
is
not
None
:
residual
=
self
.
downsample
(
x
)
out
+=
residual
out
=
self
.
relu
(
out
)
return
out
def
fill_up_weights
(
up
):
w
=
up
.
weight
.
data
f
=
math
.
ceil
(
w
.
size
(
2
)
/
2
)
c
=
(
2
*
f
-
1
-
f
%
2
)
/
(
2.
*
f
)
for
i
in
range
(
w
.
size
(
2
)):
for
j
in
range
(
w
.
size
(
3
)):
w
[
0
,
0
,
i
,
j
]
=
\
(
1
-
math
.
fabs
(
i
/
f
-
c
))
*
(
1
-
math
.
fabs
(
j
/
f
-
c
))
for
c
in
range
(
1
,
w
.
size
(
0
)):
w
[
c
,
0
,
:,
:]
=
w
[
0
,
0
,
:,
:]
def
fill_fc_weights
(
layers
):
for
m
in
layers
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
nn
.
init
.
normal_
(
m
.
weight
,
std
=
0.001
)
# torch.nn.init.kaiming_normal_(m.weight.data, nonlinearity='relu')
# torch.nn.init.xavier_normal_(m.weight.data)
if
m
.
bias
is
not
None
:
nn
.
init
.
constant_
(
m
.
bias
,
0
)
class
PoseResNet
(
nn
.
Module
):
def
__init__
(
self
,
block
,
layers
,
heads
,
head_conv
):
self
.
inplanes
=
64
self
.
heads
=
heads
self
.
deconv_with_bias
=
False
super
(
PoseResNet
,
self
).
__init__
()
self
.
conv1
=
nn
.
Conv2d
(
3
,
64
,
kernel_size
=
7
,
stride
=
2
,
padding
=
3
,
bias
=
False
)
self
.
bn1
=
nn
.
BatchNorm2d
(
64
,
momentum
=
BN_MOMENTUM
)
self
.
relu
=
nn
.
ReLU
(
inplace
=
True
)
self
.
maxpool
=
nn
.
MaxPool2d
(
kernel_size
=
3
,
stride
=
2
,
padding
=
1
)
self
.
layer1
=
self
.
_make_layer
(
block
,
64
,
layers
[
0
])
self
.
layer2
=
self
.
_make_layer
(
block
,
128
,
layers
[
1
],
stride
=
2
)
self
.
layer3
=
self
.
_make_layer
(
block
,
256
,
layers
[
2
],
stride
=
2
)
self
.
layer4
=
self
.
_make_layer
(
block
,
512
,
layers
[
3
],
stride
=
2
)
# used for deconv layers
self
.
deconv_layers
=
self
.
_make_deconv_layer
(
3
,
[
256
,
128
,
64
],
[
4
,
4
,
4
],
)
for
head
in
self
.
heads
:
classes
=
self
.
heads
[
head
]
if
head_conv
>
0
:
fc
=
nn
.
Sequential
(
nn
.
Conv2d
(
64
,
head_conv
,
kernel_size
=
3
,
padding
=
1
,
bias
=
True
),
nn
.
ReLU
(
inplace
=
True
),
nn
.
Conv2d
(
head_conv
,
classes
,
kernel_size
=
1
,
stride
=
1
,
padding
=
0
,
bias
=
True
))
if
'hm'
in
head
:
fc
[
-
1
].
bias
.
data
.
fill_
(
-
2.19
)
else
:
fill_fc_weights
(
fc
)
else
:
fc
=
nn
.
Conv2d
(
64
,
classes
,
kernel_size
=
1
,
stride
=
1
,
padding
=
0
,
bias
=
True
)
if
'hm'
in
head
:
fc
.
bias
.
data
.
fill_
(
-
2.19
)
else
:
fill_fc_weights
(
fc
)
self
.
__setattr__
(
head
,
fc
)
def
_make_layer
(
self
,
block
,
planes
,
blocks
,
stride
=
1
):
downsample
=
None
if
stride
!=
1
or
self
.
inplanes
!=
planes
*
block
.
expansion
:
downsample
=
nn
.
Sequential
(
nn
.
Conv2d
(
self
.
inplanes
,
planes
*
block
.
expansion
,
kernel_size
=
1
,
stride
=
stride
,
bias
=
False
),
nn
.
BatchNorm2d
(
planes
*
block
.
expansion
,
momentum
=
BN_MOMENTUM
),
)
layers
=
[]
layers
.
append
(
block
(
self
.
inplanes
,
planes
,
stride
,
downsample
))
self
.
inplanes
=
planes
*
block
.
expansion
for
i
in
range
(
1
,
blocks
):
layers
.
append
(
block
(
self
.
inplanes
,
planes
))
return
nn
.
Sequential
(
*
layers
)
def
_get_deconv_cfg
(
self
,
deconv_kernel
,
index
):
if
deconv_kernel
==
4
:
padding
=
1
output_padding
=
0
elif
deconv_kernel
==
3
:
padding
=
1
output_padding
=
1
elif
deconv_kernel
==
2
:
padding
=
0
output_padding
=
0
return
deconv_kernel
,
padding
,
output_padding
def
_make_deconv_layer
(
self
,
num_layers
,
num_filters
,
num_kernels
):
assert
num_layers
==
len
(
num_filters
),
\
'ERROR: num_deconv_layers is different len(num_deconv_filters)'
assert
num_layers
==
len
(
num_kernels
),
\
'ERROR: num_deconv_layers is different len(num_deconv_filters)'
layers
=
[]
for
i
in
range
(
num_layers
):
kernel
,
padding
,
output_padding
=
\
self
.
_get_deconv_cfg
(
num_kernels
[
i
],
i
)
planes
=
num_filters
[
i
]
fc
=
DCN
(
self
.
inplanes
,
planes
,
kernel_size
=
(
3
,
3
),
stride
=
1
,
padding
=
1
,
dilation
=
1
,
deformable_groups
=
1
)
# fc = nn.Conv2d(self.inplanes, planes,
# kernel_size=3, stride=1,
# padding=1, dilation=1, bias=False)
# fill_fc_weights(fc)
up
=
nn
.
ConvTranspose2d
(
in_channels
=
planes
,
out_channels
=
planes
,
kernel_size
=
kernel
,
stride
=
2
,
padding
=
padding
,
output_padding
=
output_padding
,
bias
=
self
.
deconv_with_bias
)
fill_up_weights
(
up
)
layers
.
append
(
fc
)
layers
.
append
(
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
))
layers
.
append
(
nn
.
ReLU
(
inplace
=
True
))
layers
.
append
(
up
)
layers
.
append
(
nn
.
BatchNorm2d
(
planes
,
momentum
=
BN_MOMENTUM
))
layers
.
append
(
nn
.
ReLU
(
inplace
=
True
))
self
.
inplanes
=
planes
return
nn
.
Sequential
(
*
layers
)
def
forward
(
self
,
x
):
x
=
self
.
conv1
(
x
)
x
=
self
.
bn1
(
x
)
x
=
self
.
relu
(
x
)
x
=
self
.
maxpool
(
x
)
x
=
self
.
layer1
(
x
)
x
=
self
.
layer2
(
x
)
x
=
self
.
layer3
(
x
)
x
=
self
.
layer4
(
x
)
x
=
self
.
deconv_layers
(
x
)
ret
=
{}
for
head
in
self
.
heads
:
ret
[
head
]
=
self
.
__getattr__
(
head
)(
x
)
return
[
ret
]
def
init_weights
(
self
,
num_layers
):
if
1
:
url
=
model_urls
[
'resnet{}'
.
format
(
num_layers
)]
pretrained_state_dict
=
model_zoo
.
load_url
(
url
)
print
(
'=> loading pretrained model {}'
.
format
(
url
))
self
.
load_state_dict
(
pretrained_state_dict
,
strict
=
False
)
print
(
'=> init deconv weights from normal distribution'
)
for
name
,
m
in
self
.
deconv_layers
.
named_modules
():
if
isinstance
(
m
,
nn
.
BatchNorm2d
):
nn
.
init
.
constant_
(
m
.
weight
,
1
)
nn
.
init
.
constant_
(
m
.
bias
,
0
)
resnet_spec
=
{
18
:
(
BasicBlock
,
[
2
,
2
,
2
,
2
]),
34
:
(
BasicBlock
,
[
3
,
4
,
6
,
3
]),
50
:
(
Bottleneck
,
[
3
,
4
,
6
,
3
]),
101
:
(
Bottleneck
,
[
3
,
4
,
23
,
3
]),
152
:
(
Bottleneck
,
[
3
,
8
,
36
,
3
])}
def
get_pose_net
(
num_layers
,
heads
,
head_conv
=
256
):
block_class
,
layers
=
resnet_spec
[
num_layers
]
model
=
PoseResNet
(
block_class
,
layers
,
heads
,
head_conv
=
head_conv
)
model
.
init_weights
(
num_layers
)
return
model
src/lib/models/Backbone/shufflenetv2_dcn.py
0 → 100644
View file @
b952e97b
import
math
from
collections
import
OrderedDict
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
from
torch.autograd
import
Variable
from
torch.nn
import
init
from
.DCNv2.dcn_v2
import
DCN
BN_MOMENTUM
=
0.1
def
conv_bn
(
inp
,
oup
,
stride
):
return
nn
.
Sequential
(
nn
.
Conv2d
(
inp
,
oup
,
3
,
stride
,
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup
),
nn
.
ReLU
(
inplace
=
True
)
)
def
conv_1x1_bn
(
inp
,
oup
):
return
nn
.
Sequential
(
nn
.
Conv2d
(
inp
,
oup
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup
),
nn
.
ReLU
(
inplace
=
True
)
)
def
channel_shuffle
(
x
,
groups
):
batchsize
,
num_channels
,
height
,
width
=
x
.
data
.
size
()
channels_per_group
=
num_channels
//
groups
# reshape
x
=
x
.
view
(
batchsize
,
groups
,
channels_per_group
,
height
,
width
)
x
=
torch
.
transpose
(
x
,
1
,
2
).
contiguous
()
# flatten
x
=
x
.
view
(
batchsize
,
-
1
,
height
,
width
)
return
x
def
fill_up_weights
(
up
):
w
=
up
.
weight
.
data
f
=
math
.
ceil
(
w
.
size
(
2
)
/
2
)
c
=
(
2
*
f
-
1
-
f
%
2
)
/
(
2.
*
f
)
for
i
in
range
(
w
.
size
(
2
)):
for
j
in
range
(
w
.
size
(
3
)):
w
[
0
,
0
,
i
,
j
]
=
\
(
1
-
math
.
fabs
(
i
/
f
-
c
))
*
(
1
-
math
.
fabs
(
j
/
f
-
c
))
for
c
in
range
(
1
,
w
.
size
(
0
)):
w
[
c
,
0
,
:,
:]
=
w
[
0
,
0
,
:,
:]
class
InvertedResidual
(
nn
.
Module
):
def
__init__
(
self
,
inp
,
oup
,
stride
,
benchmodel
):
super
(
InvertedResidual
,
self
).
__init__
()
self
.
benchmodel
=
benchmodel
self
.
stride
=
stride
assert
stride
in
[
1
,
2
]
oup_inc
=
oup
//
2
if
self
.
benchmodel
==
1
:
#assert inp == oup_inc
self
.
banch2
=
nn
.
Sequential
(
# pw
nn
.
Conv2d
(
oup_inc
,
oup_inc
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup_inc
),
nn
.
ReLU
(
inplace
=
True
),
# dw
nn
.
Conv2d
(
oup_inc
,
oup_inc
,
3
,
stride
,
1
,
groups
=
oup_inc
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup_inc
),
# pw-linear
nn
.
Conv2d
(
oup_inc
,
oup_inc
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup_inc
),
nn
.
ReLU
(
inplace
=
True
),
)
else
:
self
.
banch1
=
nn
.
Sequential
(
# dw
nn
.
Conv2d
(
inp
,
inp
,
3
,
stride
,
1
,
groups
=
inp
,
bias
=
False
),
nn
.
BatchNorm2d
(
inp
),
# pw-linear
nn
.
Conv2d
(
inp
,
oup_inc
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup_inc
),
nn
.
ReLU
(
inplace
=
True
),
)
self
.
banch2
=
nn
.
Sequential
(
# pw
nn
.
Conv2d
(
inp
,
oup_inc
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup_inc
),
nn
.
ReLU
(
inplace
=
True
),
# dw
nn
.
Conv2d
(
oup_inc
,
oup_inc
,
3
,
stride
,
1
,
groups
=
oup_inc
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup_inc
),
# pw-linear
nn
.
Conv2d
(
oup_inc
,
oup_inc
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup_inc
),
nn
.
ReLU
(
inplace
=
True
),
)
@
staticmethod
def
_concat
(
x
,
out
):
# concatenate along channel axis
return
torch
.
cat
((
x
,
out
),
1
)
def
forward
(
self
,
x
):
if
1
==
self
.
benchmodel
:
x1
=
x
[:,
:(
x
.
shape
[
1
]
//
2
),
:,
:]
x2
=
x
[:,
(
x
.
shape
[
1
]
//
2
):,
:,
:]
out
=
self
.
_concat
(
x1
,
self
.
banch2
(
x2
))
elif
2
==
self
.
benchmodel
:
out
=
self
.
_concat
(
self
.
banch1
(
x
),
self
.
banch2
(
x
))
return
channel_shuffle
(
out
,
2
)
class
ShuffleNetV2
(
nn
.
Module
):
def
__init__
(
self
,
input_size
=
512
,
width_mult
=
1.
):
super
(
ShuffleNetV2
,
self
).
__init__
()
self
.
inplanes
=
24
self
.
deconv_with_bias
=
False
assert
input_size
%
32
==
0
self
.
stage_repeats
=
[
4
,
8
,
4
]
#self.stage_repeats = [2, 3, 2]
# index 0 is invalid and should never be called.
# only used for indexing convenience.
if
width_mult
==
0.5
:
self
.
stage_out_channels
=
[
-
1
,
24
,
48
,
96
,
192
,
1024
]
elif
width_mult
==
1.0
:
self
.
stage_out_channels
=
[
-
1
,
24
,
116
,
232
,
464
,
1024
]
elif
width_mult
==
1.5
:
self
.
stage_out_channels
=
[
-
1
,
24
,
176
,
352
,
704
,
1024
]
elif
width_mult
==
2.0
:
self
.
stage_out_channels
=
[
-
1
,
24
,
224
,
488
,
976
,
2048
]
else
:
raise
ValueError
(
"""{} groups is not supported for
1x1 Grouped Convolutions"""
.
format
(
num_groups
))
# building first layer
input_channel
=
self
.
stage_out_channels
[
1
]
self
.
conv1
=
conv_bn
(
3
,
input_channel
,
2
)
self
.
maxpool
=
nn
.
MaxPool2d
(
kernel_size
=
3
,
stride
=
2
,
padding
=
1
)
self
.
features
=
[]
# building inverted residual blocks
for
idxstage
in
range
(
len
(
self
.
stage_repeats
)):
numrepeat
=
self
.
stage_repeats
[
idxstage
]
output_channel
=
self
.
stage_out_channels
[
idxstage
+
2
]
for
i
in
range
(
numrepeat
):
if
i
==
0
:
#inp, oup, stride, benchmodel):
self
.
features
.
append
(
InvertedResidual
(
input_channel
,
output_channel
,
2
,
2
))
else
:
self
.
features
.
append
(
InvertedResidual
(
input_channel
,
output_channel
,
1
,
1
))
input_channel
=
output_channel
self
.
inplanes
=
output_channel
# make it nn.Sequential
self
.
features
=
nn
.
Sequential
(
*
self
.
features
)
# consider here to add the last sevearal layers
# building last several layers
# self.conv_last = conv_1x1_bn(input_channel, self.stage_out_channels[-1])
# self.globalpool = nn.Sequential(nn.AvgPool2d(int(input_size/32)))
# used for deconv layers
self
.
deconv_layers
=
self
.
_make_deconv_layer
(
3
,
[
256
,
256
,
256
],
[
4
,
4
,
4
],
)
def
_get_deconv_cfg
(
self
,
deconv_kernel
,
index
):
if
deconv_kernel
==
4
:
padding
=
1
output_padding
=
0
elif
deconv_kernel
==
3
:
padding
=
1
output_padding
=
1
elif
deconv_kernel
==
2
:
padding
=
0
output_padding
=
0
return
deconv_kernel
,
padding
,
output_padding
def
_make_deconv_layer
(
self
,
num_layers
,
num_filters
,
num_kernels
):
assert
num_layers
==
len
(
num_filters
),
\
'ERROR: num_deconv_layers is different len(num_deconv_filters)'
assert
num_layers
==
len
(
num_kernels
),
\
'ERROR: num_deconv_layers is different len(num_deconv_filters)'
layers
=
[]
for
i
in
range
(
num_layers
):
kernel
,
padding
,
output_padding
=
\
self
.
_get_deconv_cfg
(
num_kernels
[
i
],
i
)
planes
=
num_filters
[
i
]
fc
=
DCN
(
self
.
inplanes
,
planes
,
kernel_size
=
(
3
,
3
),
stride
=
1
,
padding
=
1
,
dilation
=
1
,
deformable_groups
=
1
)
# fc = nn.Conv2d(self.inplanes, planes,
# kernel_size=3, stride=1,
# padding=1, dilation=1, bias=False)
# fill_fc_weights(fc)
up
=
nn
.
ConvTranspose2d
(
in_channels
=
planes
,
out_channels
=
planes
,
kernel_size
=
kernel
,
stride
=
2
,
padding
=
padding
,
output_padding
=
output_padding
,
bias
=
self
.
deconv_with_bias
)
fill_up_weights
(
up
)
layers
.
append
(
fc
)
layers
.
append
(
nn
.
BatchNorm2d
(
planes
))
layers
.
append
(
nn
.
ReLU
(
inplace
=
True
))
layers
.
append
(
up
)
layers
.
append
(
nn
.
BatchNorm2d
(
planes
))
layers
.
append
(
nn
.
ReLU
(
inplace
=
True
))
self
.
inplanes
=
planes
return
nn
.
Sequential
(
*
layers
)
def
init_weights
(
self
,
pretrained
=
True
):
if
pretrained
:
# print('=> init resnet deconv weights from normal distribution')
print
(
'=> init deconv weights from normal distribution'
)
for
name
,
m
in
self
.
deconv_layers
.
named_modules
():
if
isinstance
(
m
,
nn
.
BatchNorm2d
):
nn
.
init
.
constant_
(
m
.
weight
,
1
)
nn
.
init
.
constant_
(
m
.
bias
,
0
)
#pretrained_state_dict = torch.load(pretrained)
#address = "/data/pretrained_model/shufflenetv2_x1_69.390_88.412.pth.tar"
#pretrained_state_dict = torch.load(address)
#self.load_state_dict(pretrained_state_dict, strict=False)
def
forward
(
self
,
x
):
#import pdb; pdb.set_trace()
x
=
self
.
conv1
(
x
)
x
=
self
.
maxpool
(
x
)
x
=
self
.
features
(
x
)
x
=
self
.
deconv_layers
(
x
)
return
x
def
shufflenetv2
(
width_mult
=
1.
):
model
=
ShuffleNetV2
(
width_mult
=
width_mult
)
return
model
def
get_shufflev2_net
(
num_layers
,
cfg
):
model
=
ShuffleNetV2
()
model
.
init_weights
(
pretrained
=
True
)
return
model
src/lib/models/data_parallel.py
0 → 100644
View file @
b952e97b
import
torch
from
torch.nn.modules
import
Module
from
torch.nn.parallel.scatter_gather
import
gather
from
torch.nn.parallel.replicate
import
replicate
from
torch.nn.parallel.parallel_apply
import
parallel_apply
from
.scatter_gather
import
scatter_kwargs
class
_DataParallel
(
Module
):
r
"""Implements data parallelism at the module level.
This container parallelizes the application of the given module by
splitting the input across the specified devices by chunking in the batch
dimension. In the forward pass, the module is replicated on each device,
and each replica handles a portion of the input. During the backwards
pass, gradients from each replica are summed into the original module.
The batch size should be larger than the number of GPUs used. It should
also be an integer multiple of the number of GPUs so that each chunk is the
same size (so that each GPU processes the same number of samples).
See also: :ref:`cuda-nn-dataparallel-instead`
Arbitrary positional and keyword inputs are allowed to be passed into
DataParallel EXCEPT Tensors. All variables will be scattered on dim
specified (default 0). Primitive types will be broadcasted, but all
other types will be a shallow copy and can be corrupted if written to in
the model's forward pass.
Args:
module: module to be parallelized
device_ids: CUDA devices (default: all devices)
output_device: device location of output (default: device_ids[0])
Example::
>>> net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
>>> output = net(input_var)
"""
# TODO: update notes/cuda.rst when this class handles 8+ GPUs well
def
__init__
(
self
,
module
,
device_ids
=
None
,
output_device
=
None
,
dim
=
0
,
chunk_sizes
=
None
):
super
(
_DataParallel
,
self
).
__init__
()
if
not
torch
.
cuda
.
is_available
():
self
.
module
=
module
self
.
device_ids
=
[]
return
if
device_ids
is
None
:
device_ids
=
list
(
range
(
torch
.
cuda
.
device_count
()))
if
output_device
is
None
:
output_device
=
device_ids
[
0
]
self
.
dim
=
dim
self
.
module
=
module
self
.
device_ids
=
device_ids
self
.
chunk_sizes
=
chunk_sizes
self
.
output_device
=
output_device
if
len
(
self
.
device_ids
)
==
1
:
self
.
module
.
cuda
(
device_ids
[
0
])
def
forward
(
self
,
*
inputs
,
**
kwargs
):
if
not
self
.
device_ids
:
return
self
.
module
(
*
inputs
,
**
kwargs
)
inputs
,
kwargs
=
self
.
scatter
(
inputs
,
kwargs
,
self
.
device_ids
,
self
.
chunk_sizes
)
if
len
(
self
.
device_ids
)
==
1
:
return
self
.
module
(
*
inputs
[
0
],
**
kwargs
[
0
])
replicas
=
self
.
replicate
(
self
.
module
,
self
.
device_ids
[:
len
(
inputs
)])
outputs
=
self
.
parallel_apply
(
replicas
,
inputs
,
kwargs
)
return
self
.
gather
(
outputs
,
self
.
output_device
)
def
replicate
(
self
,
module
,
device_ids
):
return
replicate
(
module
,
device_ids
)
def
scatter
(
self
,
inputs
,
kwargs
,
device_ids
,
chunk_sizes
):
return
scatter_kwargs
(
inputs
,
kwargs
,
device_ids
,
dim
=
self
.
dim
,
chunk_sizes
=
self
.
chunk_sizes
)
def
parallel_apply
(
self
,
replicas
,
inputs
,
kwargs
):
return
parallel_apply
(
replicas
,
inputs
,
kwargs
,
self
.
device_ids
[:
len
(
replicas
)])
def
gather
(
self
,
outputs
,
output_device
):
return
gather
(
outputs
,
output_device
,
dim
=
self
.
dim
)
def
data_parallel
(
module
,
inputs
,
device_ids
=
None
,
output_device
=
None
,
dim
=
0
,
module_kwargs
=
None
):
r
"""Evaluates module(input) in parallel across the GPUs given in device_ids.
This is the functional version of the DataParallel module.
Args:
module: the module to evaluate in parallel
inputs: inputs to the module
device_ids: GPU ids on which to replicate module
output_device: GPU location of the output Use -1 to indicate the CPU.
(default: device_ids[0])
Returns:
a Variable containing the result of module(input) located on
output_device
"""
if
not
isinstance
(
inputs
,
tuple
):
inputs
=
(
inputs
,)
if
device_ids
is
None
:
device_ids
=
list
(
range
(
torch
.
cuda
.
device_count
()))
if
output_device
is
None
:
output_device
=
device_ids
[
0
]
inputs
,
module_kwargs
=
scatter_kwargs
(
inputs
,
module_kwargs
,
device_ids
,
dim
)
if
len
(
device_ids
)
==
1
:
return
module
(
*
inputs
[
0
],
**
module_kwargs
[
0
])
used_device_ids
=
device_ids
[:
len
(
inputs
)]
replicas
=
replicate
(
module
,
used_device_ids
)
outputs
=
parallel_apply
(
replicas
,
inputs
,
module_kwargs
,
used_device_ids
)
return
gather
(
outputs
,
output_device
,
dim
)
def
DataParallel
(
module
,
device_ids
=
None
,
output_device
=
None
,
dim
=
0
,
chunk_sizes
=
None
):
if
chunk_sizes
is
None
:
return
torch
.
nn
.
DataParallel
(
module
,
device_ids
,
output_device
,
dim
)
standard_size
=
True
for
i
in
range
(
1
,
len
(
chunk_sizes
)):
if
chunk_sizes
[
i
]
!=
chunk_sizes
[
0
]:
standard_size
=
False
if
standard_size
:
return
torch
.
nn
.
DataParallel
(
module
,
device_ids
,
output_device
,
dim
)
return
_DataParallel
(
module
,
device_ids
,
output_device
,
dim
,
chunk_sizes
)
\ No newline at end of file
src/lib/models/decode.py
0 → 100644
View file @
b952e97b
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
torch
import
torch.nn
as
nn
from
.utils
import
_gather_feat
,
_tranpose_and_gather_feat
import
numpy
as
np
def
_nms
(
heat
,
kernel
=
3
):
pad
=
(
kernel
-
1
)
//
2
hmax
=
nn
.
functional
.
max_pool2d
(
heat
,
(
kernel
,
kernel
),
stride
=
1
,
padding
=
pad
)
keep
=
(
hmax
==
heat
).
float
()
return
heat
*
keep
def
_left_aggregate
(
heat
):
'''
heat: batchsize x channels x h x w
'''
shape
=
heat
.
shape
heat
=
heat
.
reshape
(
-
1
,
heat
.
shape
[
3
])
heat
=
heat
.
transpose
(
1
,
0
).
contiguous
()
ret
=
heat
.
clone
()
for
i
in
range
(
1
,
heat
.
shape
[
0
]):
inds
=
(
heat
[
i
]
>=
heat
[
i
-
1
])
ret
[
i
]
+=
ret
[
i
-
1
]
*
inds
.
float
()
return
(
ret
-
heat
).
transpose
(
1
,
0
).
reshape
(
shape
)
def
_right_aggregate
(
heat
):
'''
heat: batchsize x channels x h x w
'''
shape
=
heat
.
shape
heat
=
heat
.
reshape
(
-
1
,
heat
.
shape
[
3
])
heat
=
heat
.
transpose
(
1
,
0
).
contiguous
()
ret
=
heat
.
clone
()
for
i
in
range
(
heat
.
shape
[
0
]
-
2
,
-
1
,
-
1
):
inds
=
(
heat
[
i
]
>=
heat
[
i
+
1
])
ret
[
i
]
+=
ret
[
i
+
1
]
*
inds
.
float
()
return
(
ret
-
heat
).
transpose
(
1
,
0
).
reshape
(
shape
)
def
_top_aggregate
(
heat
):
'''
heat: batchsize x channels x h x w
'''
heat
=
heat
.
transpose
(
3
,
2
)
shape
=
heat
.
shape
heat
=
heat
.
reshape
(
-
1
,
heat
.
shape
[
3
])
heat
=
heat
.
transpose
(
1
,
0
).
contiguous
()
ret
=
heat
.
clone
()
for
i
in
range
(
1
,
heat
.
shape
[
0
]):
inds
=
(
heat
[
i
]
>=
heat
[
i
-
1
])
ret
[
i
]
+=
ret
[
i
-
1
]
*
inds
.
float
()
return
(
ret
-
heat
).
transpose
(
1
,
0
).
reshape
(
shape
).
transpose
(
3
,
2
)
def
_bottom_aggregate
(
heat
):
'''
heat: batchsize x channels x h x w
'''
heat
=
heat
.
transpose
(
3
,
2
)
shape
=
heat
.
shape
heat
=
heat
.
reshape
(
-
1
,
heat
.
shape
[
3
])
heat
=
heat
.
transpose
(
1
,
0
).
contiguous
()
ret
=
heat
.
clone
()
for
i
in
range
(
heat
.
shape
[
0
]
-
2
,
-
1
,
-
1
):
inds
=
(
heat
[
i
]
>=
heat
[
i
+
1
])
ret
[
i
]
+=
ret
[
i
+
1
]
*
inds
.
float
()
return
(
ret
-
heat
).
transpose
(
1
,
0
).
reshape
(
shape
).
transpose
(
3
,
2
)
def
_h_aggregate
(
heat
,
aggr_weight
=
0.1
):
return
aggr_weight
*
_left_aggregate
(
heat
)
+
\
aggr_weight
*
_right_aggregate
(
heat
)
+
heat
def
_v_aggregate
(
heat
,
aggr_weight
=
0.1
):
return
aggr_weight
*
_top_aggregate
(
heat
)
+
\
aggr_weight
*
_bottom_aggregate
(
heat
)
+
heat
'''
# Slow for large number of categories
def _topk(scores, K=40):
batch, cat, height, width = scores.size()
topk_scores, topk_inds = torch.topk(scores.view(batch, -1), K)
topk_clses = (topk_inds / (height * width)).int()
topk_inds = topk_inds % (height * width)
topk_ys = (topk_inds / width).int().float()
topk_xs = (topk_inds % width).int().float()
return topk_scores, topk_inds, topk_clses, topk_ys, topk_xs
'''
def
_topk_channel
(
scores
,
K
=
40
):
batch
,
cat
,
height
,
width
=
scores
.
size
()
topk_scores
,
topk_inds
=
torch
.
topk
(
scores
.
view
(
batch
,
cat
,
-
1
),
K
)
topk_inds
=
topk_inds
%
(
height
*
width
)
topk_ys
=
(
topk_inds
/
width
).
int
().
float
()
topk_xs
=
(
topk_inds
%
width
).
int
().
float
()
return
topk_scores
,
topk_inds
,
topk_ys
,
topk_xs
def
_topk
(
scores
,
K
=
40
):
batch
,
cat
,
height
,
width
=
scores
.
size
()
topk_scores
,
topk_inds
=
torch
.
topk
(
scores
.
view
(
batch
,
cat
,
-
1
),
K
)
# 前100个点
topk_inds
=
topk_inds
%
(
height
*
width
)
topk_ys
=
(
topk_inds
/
width
).
int
().
float
()
topk_xs
=
(
topk_inds
%
width
).
int
().
float
()
topk_score
,
topk_ind
=
torch
.
topk
(
topk_scores
.
view
(
batch
,
-
1
),
K
)
topk_clses
=
(
topk_ind
/
K
).
int
()
topk_inds
=
_gather_feat
(
topk_inds
.
view
(
batch
,
-
1
,
1
),
topk_ind
).
view
(
batch
,
K
)
topk_ys
=
_gather_feat
(
topk_ys
.
view
(
batch
,
-
1
,
1
),
topk_ind
).
view
(
batch
,
K
)
topk_xs
=
_gather_feat
(
topk_xs
.
view
(
batch
,
-
1
,
1
),
topk_ind
).
view
(
batch
,
K
)
return
topk_score
,
topk_inds
,
topk_clses
,
topk_ys
,
topk_xs
def
agnex_ct_decode
(
t_heat
,
l_heat
,
b_heat
,
r_heat
,
ct_heat
,
t_regr
=
None
,
l_regr
=
None
,
b_regr
=
None
,
r_regr
=
None
,
K
=
40
,
scores_thresh
=
0.1
,
center_thresh
=
0.1
,
aggr_weight
=
0.0
,
num_dets
=
1000
):
batch
,
cat
,
height
,
width
=
t_heat
.
size
()
'''
t_heat = torch.sigmoid(t_heat)
l_heat = torch.sigmoid(l_heat)
b_heat = torch.sigmoid(b_heat)
r_heat = torch.sigmoid(r_heat)
ct_heat = torch.sigmoid(ct_heat)
'''
if
aggr_weight
>
0
:
t_heat
=
_h_aggregate
(
t_heat
,
aggr_weight
=
aggr_weight
)
l_heat
=
_v_aggregate
(
l_heat
,
aggr_weight
=
aggr_weight
)
b_heat
=
_h_aggregate
(
b_heat
,
aggr_weight
=
aggr_weight
)
r_heat
=
_v_aggregate
(
r_heat
,
aggr_weight
=
aggr_weight
)
# perform nms on heatmaps
t_heat
=
_nms
(
t_heat
)
l_heat
=
_nms
(
l_heat
)
b_heat
=
_nms
(
b_heat
)
r_heat
=
_nms
(
r_heat
)
t_heat
[
t_heat
>
1
]
=
1
l_heat
[
l_heat
>
1
]
=
1
b_heat
[
b_heat
>
1
]
=
1
r_heat
[
r_heat
>
1
]
=
1
t_scores
,
t_inds
,
_
,
t_ys
,
t_xs
=
_topk
(
t_heat
,
K
=
K
)
l_scores
,
l_inds
,
_
,
l_ys
,
l_xs
=
_topk
(
l_heat
,
K
=
K
)
b_scores
,
b_inds
,
_
,
b_ys
,
b_xs
=
_topk
(
b_heat
,
K
=
K
)
r_scores
,
r_inds
,
_
,
r_ys
,
r_xs
=
_topk
(
r_heat
,
K
=
K
)
ct_heat_agn
,
ct_clses
=
torch
.
max
(
ct_heat
,
dim
=
1
,
keepdim
=
True
)
# import pdb; pdb.set_trace()
t_ys
=
t_ys
.
view
(
batch
,
K
,
1
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
t_xs
=
t_xs
.
view
(
batch
,
K
,
1
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
l_ys
=
l_ys
.
view
(
batch
,
1
,
K
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
l_xs
=
l_xs
.
view
(
batch
,
1
,
K
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
b_ys
=
b_ys
.
view
(
batch
,
1
,
1
,
K
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
b_xs
=
b_xs
.
view
(
batch
,
1
,
1
,
K
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
r_ys
=
r_ys
.
view
(
batch
,
1
,
1
,
1
,
K
).
expand
(
batch
,
K
,
K
,
K
,
K
)
r_xs
=
r_xs
.
view
(
batch
,
1
,
1
,
1
,
K
).
expand
(
batch
,
K
,
K
,
K
,
K
)
box_ct_xs
=
((
l_xs
+
r_xs
+
0.5
)
/
2
).
long
()
box_ct_ys
=
((
t_ys
+
b_ys
+
0.5
)
/
2
).
long
()
ct_inds
=
box_ct_ys
*
width
+
box_ct_xs
ct_inds
=
ct_inds
.
view
(
batch
,
-
1
)
ct_heat_agn
=
ct_heat_agn
.
view
(
batch
,
-
1
,
1
)
ct_clses
=
ct_clses
.
view
(
batch
,
-
1
,
1
)
ct_scores
=
_gather_feat
(
ct_heat_agn
,
ct_inds
)
clses
=
_gather_feat
(
ct_clses
,
ct_inds
)
t_scores
=
t_scores
.
view
(
batch
,
K
,
1
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
l_scores
=
l_scores
.
view
(
batch
,
1
,
K
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
b_scores
=
b_scores
.
view
(
batch
,
1
,
1
,
K
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
r_scores
=
r_scores
.
view
(
batch
,
1
,
1
,
1
,
K
).
expand
(
batch
,
K
,
K
,
K
,
K
)
ct_scores
=
ct_scores
.
view
(
batch
,
K
,
K
,
K
,
K
)
scores
=
(
t_scores
+
l_scores
+
b_scores
+
r_scores
+
2
*
ct_scores
)
/
6
# reject boxes based on classes
top_inds
=
(
t_ys
>
l_ys
)
+
(
t_ys
>
b_ys
)
+
(
t_ys
>
r_ys
)
top_inds
=
(
top_inds
>
0
)
left_inds
=
(
l_xs
>
t_xs
)
+
(
l_xs
>
b_xs
)
+
(
l_xs
>
r_xs
)
left_inds
=
(
left_inds
>
0
)
bottom_inds
=
(
b_ys
<
t_ys
)
+
(
b_ys
<
l_ys
)
+
(
b_ys
<
r_ys
)
bottom_inds
=
(
bottom_inds
>
0
)
right_inds
=
(
r_xs
<
t_xs
)
+
(
r_xs
<
l_xs
)
+
(
r_xs
<
b_xs
)
right_inds
=
(
right_inds
>
0
)
sc_inds
=
(
t_scores
<
scores_thresh
)
+
(
l_scores
<
scores_thresh
)
+
\
(
b_scores
<
scores_thresh
)
+
(
r_scores
<
scores_thresh
)
+
\
(
ct_scores
<
center_thresh
)
sc_inds
=
(
sc_inds
>
0
)
scores
=
scores
-
sc_inds
.
float
()
scores
=
scores
-
top_inds
.
float
()
scores
=
scores
-
left_inds
.
float
()
scores
=
scores
-
bottom_inds
.
float
()
scores
=
scores
-
right_inds
.
float
()
scores
=
scores
.
view
(
batch
,
-
1
)
scores
,
inds
=
torch
.
topk
(
scores
,
num_dets
)
scores
=
scores
.
unsqueeze
(
2
)
if
t_regr
is
not
None
and
l_regr
is
not
None
\
and
b_regr
is
not
None
and
r_regr
is
not
None
:
t_regr
=
_tranpose_and_gather_feat
(
t_regr
,
t_inds
)
t_regr
=
t_regr
.
view
(
batch
,
K
,
1
,
1
,
1
,
2
)
l_regr
=
_tranpose_and_gather_feat
(
l_regr
,
l_inds
)
l_regr
=
l_regr
.
view
(
batch
,
1
,
K
,
1
,
1
,
2
)
b_regr
=
_tranpose_and_gather_feat
(
b_regr
,
b_inds
)
b_regr
=
b_regr
.
view
(
batch
,
1
,
1
,
K
,
1
,
2
)
r_regr
=
_tranpose_and_gather_feat
(
r_regr
,
r_inds
)
r_regr
=
r_regr
.
view
(
batch
,
1
,
1
,
1
,
K
,
2
)
t_xs
=
t_xs
+
t_regr
[...,
0
]
t_ys
=
t_ys
+
t_regr
[...,
1
]
l_xs
=
l_xs
+
l_regr
[...,
0
]
l_ys
=
l_ys
+
l_regr
[...,
1
]
b_xs
=
b_xs
+
b_regr
[...,
0
]
b_ys
=
b_ys
+
b_regr
[...,
1
]
r_xs
=
r_xs
+
r_regr
[...,
0
]
r_ys
=
r_ys
+
r_regr
[...,
1
]
else
:
t_xs
=
t_xs
+
0.5
t_ys
=
t_ys
+
0.5
l_xs
=
l_xs
+
0.5
l_ys
=
l_ys
+
0.5
b_xs
=
b_xs
+
0.5
b_ys
=
b_ys
+
0.5
r_xs
=
r_xs
+
0.5
r_ys
=
r_ys
+
0.5
bboxes
=
torch
.
stack
((
l_xs
,
t_ys
,
r_xs
,
b_ys
),
dim
=
5
)
bboxes
=
bboxes
.
view
(
batch
,
-
1
,
4
)
bboxes
=
_gather_feat
(
bboxes
,
inds
)
clses
=
clses
.
contiguous
().
view
(
batch
,
-
1
,
1
)
clses
=
_gather_feat
(
clses
,
inds
).
float
()
t_xs
=
t_xs
.
contiguous
().
view
(
batch
,
-
1
,
1
)
t_xs
=
_gather_feat
(
t_xs
,
inds
).
float
()
t_ys
=
t_ys
.
contiguous
().
view
(
batch
,
-
1
,
1
)
t_ys
=
_gather_feat
(
t_ys
,
inds
).
float
()
l_xs
=
l_xs
.
contiguous
().
view
(
batch
,
-
1
,
1
)
l_xs
=
_gather_feat
(
l_xs
,
inds
).
float
()
l_ys
=
l_ys
.
contiguous
().
view
(
batch
,
-
1
,
1
)
l_ys
=
_gather_feat
(
l_ys
,
inds
).
float
()
b_xs
=
b_xs
.
contiguous
().
view
(
batch
,
-
1
,
1
)
b_xs
=
_gather_feat
(
b_xs
,
inds
).
float
()
b_ys
=
b_ys
.
contiguous
().
view
(
batch
,
-
1
,
1
)
b_ys
=
_gather_feat
(
b_ys
,
inds
).
float
()
r_xs
=
r_xs
.
contiguous
().
view
(
batch
,
-
1
,
1
)
r_xs
=
_gather_feat
(
r_xs
,
inds
).
float
()
r_ys
=
r_ys
.
contiguous
().
view
(
batch
,
-
1
,
1
)
r_ys
=
_gather_feat
(
r_ys
,
inds
).
float
()
detections
=
torch
.
cat
([
bboxes
,
scores
,
t_xs
,
t_ys
,
l_xs
,
l_ys
,
b_xs
,
b_ys
,
r_xs
,
r_ys
,
clses
],
dim
=
2
)
return
detections
def
exct_decode
(
t_heat
,
l_heat
,
b_heat
,
r_heat
,
ct_heat
,
t_regr
=
None
,
l_regr
=
None
,
b_regr
=
None
,
r_regr
=
None
,
K
=
40
,
scores_thresh
=
0.1
,
center_thresh
=
0.1
,
aggr_weight
=
0.0
,
num_dets
=
1000
):
batch
,
cat
,
height
,
width
=
t_heat
.
size
()
'''
t_heat = torch.sigmoid(t_heat)
l_heat = torch.sigmoid(l_heat)
b_heat = torch.sigmoid(b_heat)
r_heat = torch.sigmoid(r_heat)
ct_heat = torch.sigmoid(ct_heat)
'''
if
aggr_weight
>
0
:
t_heat
=
_h_aggregate
(
t_heat
,
aggr_weight
=
aggr_weight
)
l_heat
=
_v_aggregate
(
l_heat
,
aggr_weight
=
aggr_weight
)
b_heat
=
_h_aggregate
(
b_heat
,
aggr_weight
=
aggr_weight
)
r_heat
=
_v_aggregate
(
r_heat
,
aggr_weight
=
aggr_weight
)
# perform nms on heatmaps
t_heat
=
_nms
(
t_heat
)
l_heat
=
_nms
(
l_heat
)
b_heat
=
_nms
(
b_heat
)
r_heat
=
_nms
(
r_heat
)
t_heat
[
t_heat
>
1
]
=
1
l_heat
[
l_heat
>
1
]
=
1
b_heat
[
b_heat
>
1
]
=
1
r_heat
[
r_heat
>
1
]
=
1
t_scores
,
t_inds
,
t_clses
,
t_ys
,
t_xs
=
_topk
(
t_heat
,
K
=
K
)
l_scores
,
l_inds
,
l_clses
,
l_ys
,
l_xs
=
_topk
(
l_heat
,
K
=
K
)
b_scores
,
b_inds
,
b_clses
,
b_ys
,
b_xs
=
_topk
(
b_heat
,
K
=
K
)
r_scores
,
r_inds
,
r_clses
,
r_ys
,
r_xs
=
_topk
(
r_heat
,
K
=
K
)
t_ys
=
t_ys
.
view
(
batch
,
K
,
1
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
t_xs
=
t_xs
.
view
(
batch
,
K
,
1
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
l_ys
=
l_ys
.
view
(
batch
,
1
,
K
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
l_xs
=
l_xs
.
view
(
batch
,
1
,
K
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
b_ys
=
b_ys
.
view
(
batch
,
1
,
1
,
K
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
b_xs
=
b_xs
.
view
(
batch
,
1
,
1
,
K
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
r_ys
=
r_ys
.
view
(
batch
,
1
,
1
,
1
,
K
).
expand
(
batch
,
K
,
K
,
K
,
K
)
r_xs
=
r_xs
.
view
(
batch
,
1
,
1
,
1
,
K
).
expand
(
batch
,
K
,
K
,
K
,
K
)
t_clses
=
t_clses
.
view
(
batch
,
K
,
1
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
l_clses
=
l_clses
.
view
(
batch
,
1
,
K
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
b_clses
=
b_clses
.
view
(
batch
,
1
,
1
,
K
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
r_clses
=
r_clses
.
view
(
batch
,
1
,
1
,
1
,
K
).
expand
(
batch
,
K
,
K
,
K
,
K
)
box_ct_xs
=
((
l_xs
+
r_xs
+
0.5
)
/
2
).
long
()
box_ct_ys
=
((
t_ys
+
b_ys
+
0.5
)
/
2
).
long
()
ct_inds
=
t_clses
.
long
()
*
(
height
*
width
)
+
box_ct_ys
*
width
+
box_ct_xs
ct_inds
=
ct_inds
.
view
(
batch
,
-
1
)
ct_heat
=
ct_heat
.
view
(
batch
,
-
1
,
1
)
ct_scores
=
_gather_feat
(
ct_heat
,
ct_inds
)
t_scores
=
t_scores
.
view
(
batch
,
K
,
1
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
l_scores
=
l_scores
.
view
(
batch
,
1
,
K
,
1
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
b_scores
=
b_scores
.
view
(
batch
,
1
,
1
,
K
,
1
).
expand
(
batch
,
K
,
K
,
K
,
K
)
r_scores
=
r_scores
.
view
(
batch
,
1
,
1
,
1
,
K
).
expand
(
batch
,
K
,
K
,
K
,
K
)
ct_scores
=
ct_scores
.
view
(
batch
,
K
,
K
,
K
,
K
)
scores
=
(
t_scores
+
l_scores
+
b_scores
+
r_scores
+
2
*
ct_scores
)
/
6
# reject boxes based on classes
cls_inds
=
(
t_clses
!=
l_clses
)
+
(
t_clses
!=
b_clses
)
+
\
(
t_clses
!=
r_clses
)
cls_inds
=
(
cls_inds
>
0
)
top_inds
=
(
t_ys
>
l_ys
)
+
(
t_ys
>
b_ys
)
+
(
t_ys
>
r_ys
)
top_inds
=
(
top_inds
>
0
)
left_inds
=
(
l_xs
>
t_xs
)
+
(
l_xs
>
b_xs
)
+
(
l_xs
>
r_xs
)
left_inds
=
(
left_inds
>
0
)
bottom_inds
=
(
b_ys
<
t_ys
)
+
(
b_ys
<
l_ys
)
+
(
b_ys
<
r_ys
)
bottom_inds
=
(
bottom_inds
>
0
)
right_inds
=
(
r_xs
<
t_xs
)
+
(
r_xs
<
l_xs
)
+
(
r_xs
<
b_xs
)
right_inds
=
(
right_inds
>
0
)
sc_inds
=
(
t_scores
<
scores_thresh
)
+
(
l_scores
<
scores_thresh
)
+
\
(
b_scores
<
scores_thresh
)
+
(
r_scores
<
scores_thresh
)
+
\
(
ct_scores
<
center_thresh
)
sc_inds
=
(
sc_inds
>
0
)
scores
=
scores
-
sc_inds
.
float
()
scores
=
scores
-
cls_inds
.
float
()
scores
=
scores
-
top_inds
.
float
()
scores
=
scores
-
left_inds
.
float
()
scores
=
scores
-
bottom_inds
.
float
()
scores
=
scores
-
right_inds
.
float
()
scores
=
scores
.
view
(
batch
,
-
1
)
scores
,
inds
=
torch
.
topk
(
scores
,
num_dets
)
scores
=
scores
.
unsqueeze
(
2
)
if
t_regr
is
not
None
and
l_regr
is
not
None
\
and
b_regr
is
not
None
and
r_regr
is
not
None
:
t_regr
=
_tranpose_and_gather_feat
(
t_regr
,
t_inds
)
t_regr
=
t_regr
.
view
(
batch
,
K
,
1
,
1
,
1
,
2
)
l_regr
=
_tranpose_and_gather_feat
(
l_regr
,
l_inds
)
l_regr
=
l_regr
.
view
(
batch
,
1
,
K
,
1
,
1
,
2
)
b_regr
=
_tranpose_and_gather_feat
(
b_regr
,
b_inds
)
b_regr
=
b_regr
.
view
(
batch
,
1
,
1
,
K
,
1
,
2
)
r_regr
=
_tranpose_and_gather_feat
(
r_regr
,
r_inds
)
r_regr
=
r_regr
.
view
(
batch
,
1
,
1
,
1
,
K
,
2
)
t_xs
=
t_xs
+
t_regr
[...,
0
]
t_ys
=
t_ys
+
t_regr
[...,
1
]
l_xs
=
l_xs
+
l_regr
[...,
0
]
l_ys
=
l_ys
+
l_regr
[...,
1
]
b_xs
=
b_xs
+
b_regr
[...,
0
]
b_ys
=
b_ys
+
b_regr
[...,
1
]
r_xs
=
r_xs
+
r_regr
[...,
0
]
r_ys
=
r_ys
+
r_regr
[...,
1
]
else
:
t_xs
=
t_xs
+
0.5
t_ys
=
t_ys
+
0.5
l_xs
=
l_xs
+
0.5
l_ys
=
l_ys
+
0.5
b_xs
=
b_xs
+
0.5
b_ys
=
b_ys
+
0.5
r_xs
=
r_xs
+
0.5
r_ys
=
r_ys
+
0.5
bboxes
=
torch
.
stack
((
l_xs
,
t_ys
,
r_xs
,
b_ys
),
dim
=
5
)
bboxes
=
bboxes
.
view
(
batch
,
-
1
,
4
)
bboxes
=
_gather_feat
(
bboxes
,
inds
)
clses
=
t_clses
.
contiguous
().
view
(
batch
,
-
1
,
1
)
clses
=
_gather_feat
(
clses
,
inds
).
float
()
t_xs
=
t_xs
.
contiguous
().
view
(
batch
,
-
1
,
1
)
t_xs
=
_gather_feat
(
t_xs
,
inds
).
float
()
t_ys
=
t_ys
.
contiguous
().
view
(
batch
,
-
1
,
1
)
t_ys
=
_gather_feat
(
t_ys
,
inds
).
float
()
l_xs
=
l_xs
.
contiguous
().
view
(
batch
,
-
1
,
1
)
l_xs
=
_gather_feat
(
l_xs
,
inds
).
float
()
l_ys
=
l_ys
.
contiguous
().
view
(
batch
,
-
1
,
1
)
l_ys
=
_gather_feat
(
l_ys
,
inds
).
float
()
b_xs
=
b_xs
.
contiguous
().
view
(
batch
,
-
1
,
1
)
b_xs
=
_gather_feat
(
b_xs
,
inds
).
float
()
b_ys
=
b_ys
.
contiguous
().
view
(
batch
,
-
1
,
1
)
b_ys
=
_gather_feat
(
b_ys
,
inds
).
float
()
r_xs
=
r_xs
.
contiguous
().
view
(
batch
,
-
1
,
1
)
r_xs
=
_gather_feat
(
r_xs
,
inds
).
float
()
r_ys
=
r_ys
.
contiguous
().
view
(
batch
,
-
1
,
1
)
r_ys
=
_gather_feat
(
r_ys
,
inds
).
float
()
detections
=
torch
.
cat
([
bboxes
,
scores
,
t_xs
,
t_ys
,
l_xs
,
l_ys
,
b_xs
,
b_ys
,
r_xs
,
r_ys
,
clses
],
dim
=
2
)
return
detections
def
ddd_decode
(
heat
,
rot
,
depth
,
dim
,
wh
=
None
,
reg
=
None
,
K
=
40
):
batch
,
cat
,
height
,
width
=
heat
.
size
()
# heat = torch.sigmoid(heat)
# perform nms on heatmaps
heat
=
_nms
(
heat
)
scores
,
inds
,
clses
,
ys
,
xs
=
_topk
(
heat
,
K
=
K
)
if
reg
is
not
None
:
reg
=
_tranpose_and_gather_feat
(
reg
,
inds
)
reg
=
reg
.
view
(
batch
,
K
,
2
)
xs
=
xs
.
view
(
batch
,
K
,
1
)
+
reg
[:,
:,
0
:
1
]
ys
=
ys
.
view
(
batch
,
K
,
1
)
+
reg
[:,
:,
1
:
2
]
else
:
xs
=
xs
.
view
(
batch
,
K
,
1
)
+
0.5
ys
=
ys
.
view
(
batch
,
K
,
1
)
+
0.5
rot
=
_tranpose_and_gather_feat
(
rot
,
inds
)
rot
=
rot
.
view
(
batch
,
K
,
8
)
depth
=
_tranpose_and_gather_feat
(
depth
,
inds
)
depth
=
depth
.
view
(
batch
,
K
,
1
)
dim
=
_tranpose_and_gather_feat
(
dim
,
inds
)
dim
=
dim
.
view
(
batch
,
K
,
3
)
clses
=
clses
.
view
(
batch
,
K
,
1
).
float
()
scores
=
scores
.
view
(
batch
,
K
,
1
)
xs
=
xs
.
view
(
batch
,
K
,
1
)
ys
=
ys
.
view
(
batch
,
K
,
1
)
if
wh
is
not
None
:
wh
=
_tranpose_and_gather_feat
(
wh
,
inds
)
wh
=
wh
.
view
(
batch
,
K
,
2
)
detections
=
torch
.
cat
(
[
xs
,
ys
,
scores
,
rot
,
depth
,
dim
,
wh
,
clses
],
dim
=
2
)
else
:
detections
=
torch
.
cat
(
[
xs
,
ys
,
scores
,
rot
,
depth
,
dim
,
clses
],
dim
=
2
)
return
detections
def
ctdet_decode
(
heat
,
wh
,
reg
=
None
,
cat_spec_wh
=
False
,
K
=
100
):
batch
,
cat
,
height
,
width
=
heat
.
size
()
# heat = torch.sigmoid(heat)
# perform nms on heatmaps
heat
=
_nms
(
heat
)
# 3 * 3 区域的最大值滤波
scores
,
inds
,
clses
,
ys
,
xs
=
_topk
(
heat
,
K
=
K
)
if
reg
is
not
None
:
reg
=
_tranpose_and_gather_feat
(
reg
,
inds
)
reg
=
reg
.
view
(
batch
,
K
,
2
)
xs
=
xs
.
view
(
batch
,
K
,
1
)
+
reg
[:,
:,
0
:
1
]
ys
=
ys
.
view
(
batch
,
K
,
1
)
+
reg
[:,
:,
1
:
2
]
else
:
xs
=
xs
.
view
(
batch
,
K
,
1
)
+
0.5
ys
=
ys
.
view
(
batch
,
K
,
1
)
+
0.5
wh
=
_tranpose_and_gather_feat
(
wh
,
inds
)
if
cat_spec_wh
:
wh
=
wh
.
view
(
batch
,
K
,
cat
,
2
)
clses_ind
=
clses
.
view
(
batch
,
K
,
1
,
1
).
expand
(
batch
,
K
,
1
,
2
).
long
()
wh
=
wh
.
gather
(
2
,
clses_ind
).
view
(
batch
,
K
,
2
)
else
:
wh
=
wh
.
view
(
batch
,
K
,
2
)
clses
=
clses
.
view
(
batch
,
K
,
1
).
float
()
scores
=
scores
.
view
(
batch
,
K
,
1
)
bboxes
=
torch
.
cat
([
xs
-
wh
[...,
0
:
1
]
/
2
,
ys
-
wh
[...,
1
:
2
]
/
2
,
xs
+
wh
[...,
0
:
1
]
/
2
,
ys
+
wh
[...,
1
:
2
]
/
2
],
dim
=
2
)
detections
=
torch
.
cat
([
bboxes
,
scores
,
clses
],
dim
=
2
)
return
detections
def
multi_pose_decode
(
heat
,
wh
,
kps
,
reg
=
None
,
hm_hp
=
None
,
hp_offset
=
None
,
K
=
100
):
batch
,
cat
,
height
,
width
=
heat
.
size
()
num_joints
=
kps
.
shape
[
1
]
//
2
# heat = torch.sigmoid(heat)
# perform nms on heatmaps
heat
=
_nms
(
heat
)
scores
,
inds
,
clses
,
ys
,
xs
=
_topk
(
heat
,
K
=
K
)
kps
=
_tranpose_and_gather_feat
(
kps
,
inds
)
kps
=
kps
.
view
(
batch
,
K
,
num_joints
*
2
)
kps
[...,
::
2
]
+=
xs
.
view
(
batch
,
K
,
1
).
expand
(
batch
,
K
,
num_joints
)
# 第一次通过中心点偏移获得的关节点的坐标
kps
[...,
1
::
2
]
+=
ys
.
view
(
batch
,
K
,
1
).
expand
(
batch
,
K
,
num_joints
)
if
reg
is
not
None
:
# 回归的中心点偏移量
reg
=
_tranpose_and_gather_feat
(
reg
,
inds
)
reg
=
reg
.
view
(
batch
,
K
,
2
)
xs
=
xs
.
view
(
batch
,
K
,
1
)
+
reg
[:,
:,
0
:
1
]
ys
=
ys
.
view
(
batch
,
K
,
1
)
+
reg
[:,
:,
1
:
2
]
else
:
xs
=
xs
.
view
(
batch
,
K
,
1
)
+
0.5
ys
=
ys
.
view
(
batch
,
K
,
1
)
+
0.5
wh
=
_tranpose_and_gather_feat
(
wh
,
inds
)
# 矩形框的宽高
wh
=
wh
.
view
(
batch
,
K
,
2
)
clses
=
clses
.
view
(
batch
,
K
,
1
).
float
()
scores
=
scores
.
view
(
batch
,
K
,
1
)
bboxes
=
torch
.
cat
([
xs
-
wh
[...,
0
:
1
]
/
2
,
ys
-
wh
[...,
1
:
2
]
/
2
,
xs
+
wh
[...,
0
:
1
]
/
2
,
ys
+
wh
[...,
1
:
2
]
/
2
],
dim
=
2
)
if
hm_hp
is
not
None
:
hm_hp
=
_nms
(
hm_hp
)
# 第二次:通过关节点热力图求得关节点的中心点
thresh
=
0.1
kps
=
kps
.
view
(
batch
,
K
,
num_joints
,
2
).
permute
(
0
,
2
,
1
,
3
).
contiguous
()
# b x J x K x 2
reg_kps
=
kps
.
unsqueeze
(
3
).
expand
(
batch
,
num_joints
,
K
,
K
,
2
)
hm_score
,
hm_inds
,
hm_ys
,
hm_xs
=
_topk_channel
(
hm_hp
,
K
=
K
)
# b x J x K
if
hp_offset
is
not
None
:
# 关节点的中心的偏移
hp_offset
=
_tranpose_and_gather_feat
(
hp_offset
,
hm_inds
.
view
(
batch
,
-
1
))
hp_offset
=
hp_offset
.
view
(
batch
,
num_joints
,
K
,
2
)
hm_xs
=
hm_xs
+
hp_offset
[:,
:,
:,
0
]
hm_ys
=
hm_ys
+
hp_offset
[:,
:,
:,
1
]
else
:
hm_xs
=
hm_xs
+
0.5
hm_ys
=
hm_ys
+
0.5
mask
=
(
hm_score
>
thresh
).
float
()
# 选置信度大于0.1的
hm_score
=
(
1
-
mask
)
*
-
1
+
mask
*
hm_score
hm_ys
=
(
1
-
mask
)
*
(
-
10000
)
+
mask
*
hm_ys
hm_xs
=
(
1
-
mask
)
*
(
-
10000
)
+
mask
*
hm_xs
hm_kps
=
torch
.
stack
([
hm_xs
,
hm_ys
],
dim
=-
1
).
unsqueeze
(
2
).
expand
(
batch
,
num_joints
,
K
,
K
,
2
)
dist
=
(((
reg_kps
-
hm_kps
)
**
2
).
sum
(
dim
=
4
)
**
0.5
)
# 两次求解的关节点求距离
min_dist
,
min_ind
=
dist
.
min
(
dim
=
3
)
# b x J x K
hm_score
=
hm_score
.
gather
(
2
,
min_ind
).
unsqueeze
(
-
1
)
# b x J x K x 1
min_dist
=
min_dist
.
unsqueeze
(
-
1
)
min_ind
=
min_ind
.
view
(
batch
,
num_joints
,
K
,
1
,
1
).
expand
(
batch
,
num_joints
,
K
,
1
,
2
)
hm_kps
=
hm_kps
.
gather
(
3
,
min_ind
)
hm_kps
=
hm_kps
.
view
(
batch
,
num_joints
,
K
,
2
)
# 如果在bboxes中则用第二种方法的关节点,在bboxes外用第一种方法提取的关节点,就是优先选第二种方法
l
=
bboxes
[:,
:,
0
].
view
(
batch
,
1
,
K
,
1
).
expand
(
batch
,
num_joints
,
K
,
1
)
t
=
bboxes
[:,
:,
1
].
view
(
batch
,
1
,
K
,
1
).
expand
(
batch
,
num_joints
,
K
,
1
)
r
=
bboxes
[:,
:,
2
].
view
(
batch
,
1
,
K
,
1
).
expand
(
batch
,
num_joints
,
K
,
1
)
b
=
bboxes
[:,
:,
3
].
view
(
batch
,
1
,
K
,
1
).
expand
(
batch
,
num_joints
,
K
,
1
)
mask
=
(
hm_kps
[...,
0
:
1
]
<
l
)
+
(
hm_kps
[...,
0
:
1
]
>
r
)
+
\
(
hm_kps
[...,
1
:
2
]
<
t
)
+
(
hm_kps
[...,
1
:
2
]
>
b
)
+
\
(
hm_score
<
thresh
)
+
(
min_dist
>
(
torch
.
max
(
b
-
t
,
r
-
l
)
*
0.3
))
mask
=
(
mask
>
0
).
float
().
expand
(
batch
,
num_joints
,
K
,
2
)
kps
=
(
1
-
mask
)
*
hm_kps
+
mask
*
kps
kps
=
kps
.
permute
(
0
,
2
,
1
,
3
).
contiguous
().
view
(
batch
,
K
,
num_joints
*
2
)
detections
=
torch
.
cat
([
bboxes
,
scores
,
kps
,
clses
],
dim
=
2
)
# box:4+score:1+kpoints:10+class:1=16
return
detections
def
threshold_choose
(
scores
,
threshold
):
mask
=
scores
.
gt
(
threshold
)
topk_scores
=
scores
[
mask
]
topk_inds
=
torch
.
range
(
0
,
scores
.
numel
()
-
1
)[
mask
.
squeeze
().
flatten
()]
topk_inds
=
topk_inds
.
cuda
().
to
(
torch
.
int64
)
batch
,
cat
,
height
,
width
=
scores
.
size
()
# topk_scores, topk_inds = torch.topk(scores.view(batch, cat, -1), K) # 前100个点
topk_inds
=
topk_inds
%
(
height
*
width
)
topk_ys
=
(
topk_inds
/
width
).
int
().
float
()
topk_xs
=
(
topk_inds
%
width
).
int
().
float
()
K
=
topk_inds
.
numel
()
topk_score
,
topk_ind
=
torch
.
topk
(
topk_scores
.
view
(
batch
,
-
1
),
K
)
topk_clses
=
(
topk_ind
/
K
).
int
()
topk_inds
=
_gather_feat
(
topk_inds
.
view
(
batch
,
-
1
,
1
),
topk_ind
).
view
(
batch
,
K
)
topk_ys
=
_gather_feat
(
topk_ys
.
view
(
batch
,
-
1
,
1
),
topk_ind
).
view
(
batch
,
K
)
topk_xs
=
_gather_feat
(
topk_xs
.
view
(
batch
,
-
1
,
1
),
topk_ind
).
view
(
batch
,
K
)
return
topk_score
,
topk_inds
,
topk_clses
,
topk_ys
,
topk_xs
,
K
def
centerface_decode
(
heat
,
wh
,
kps
,
reg
=
None
,
hm_hp
=
None
,
hp_offset
=
None
,
K
=
100
):
batch
,
cat
,
height
,
width
=
heat
.
size
()
num_joints
=
kps
.
shape
[
1
]
//
2
# heat = torch.sigmoid(heat)
# perform nms on heatmaps
heat
=
_nms
(
heat
)
scores
,
inds
,
clses
,
ys_int
,
xs_int
=
_topk
(
heat
,
K
=
K
)
# scores, inds, clses, ys_int, xs_int, K = threshold_choose(heat, threshold=0.05)
if
reg
is
not
None
:
# 回归的中心点偏移量
reg
=
_tranpose_and_gather_feat
(
reg
,
inds
)
reg
=
reg
.
view
(
batch
,
K
,
2
)
xs
=
xs_int
.
view
(
batch
,
K
,
1
)
+
reg
[:,
:,
0
:
1
]
# 1. 中心点,后面乘了4
ys
=
ys_int
.
view
(
batch
,
K
,
1
)
+
reg
[:,
:,
1
:
2
]
# xs = (xs_int.view(batch, K, 1) + reg[:, :, 0:1] + 0.5)
# ys = (ys_int.view(batch, K, 1) + reg[:, :, 1:2] + 0.5) # 1. 中心点,按centerface的方式计算
else
:
xs
=
xs_int
.
view
(
batch
,
K
,
1
)
+
0.5
ys
=
ys_int
.
view
(
batch
,
K
,
1
)
+
0.5
wh
=
_tranpose_and_gather_feat
(
wh
,
inds
)
# 人脸bbox矩形框的宽高
wh
=
wh
.
view
(
batch
,
K
,
2
)
# 2. wh,第一种方式
wh
=
wh
.
exp
()
*
4.
# 2. wh,第二种式式
clses
=
clses
.
view
(
batch
,
K
,
1
).
float
()
scores
=
scores
.
view
(
batch
,
K
,
1
)
bboxes
=
torch
.
cat
([
xs
-
wh
[...,
0
:
1
]
/
2
,
ys
-
wh
[...,
1
:
2
]
/
2
,
xs
+
wh
[...,
0
:
1
]
/
2
,
ys
+
wh
[...,
1
:
2
]
/
2
],
dim
=
2
)
kps
=
_tranpose_and_gather_feat
(
kps
,
inds
)
# 3. 人脸关键点
kps
=
kps
.
view
(
batch
,
K
,
num_joints
*
2
)
kps
[...,
::
2
]
+=
xs
.
view
(
batch
,
K
,
1
).
expand
(
batch
,
K
,
num_joints
)
# 第一次通过中心点偏移获得的关节点的坐标
kps
[...,
1
::
2
]
+=
ys
.
view
(
batch
,
K
,
1
).
expand
(
batch
,
K
,
num_joints
)
if
hm_hp
is
not
None
:
hm_hp
=
_nms
(
hm_hp
)
# 第二次:通过关节点热力图求得关节点的中心点
thresh
=
0.1
kps
=
kps
.
view
(
batch
,
K
,
num_joints
,
2
).
permute
(
0
,
2
,
1
,
3
).
contiguous
()
# b x J x K x 2
reg_kps
=
kps
.
unsqueeze
(
3
).
expand
(
batch
,
num_joints
,
K
,
K
,
2
)
hm_score
,
hm_inds
,
hm_ys
,
hm_xs
=
_topk_channel
(
hm_hp
,
K
=
K
)
# b x J x K
if
hp_offset
is
not
None
:
# 关节点的中心的偏移
hp_offset
=
_tranpose_and_gather_feat
(
hp_offset
,
hm_inds
.
view
(
batch
,
-
1
))
hp_offset
=
hp_offset
.
view
(
batch
,
num_joints
,
K
,
2
)
hm_xs
=
hm_xs
+
hp_offset
[:,
:,
:,
0
]
hm_ys
=
hm_ys
+
hp_offset
[:,
:,
:,
1
]
else
:
hm_xs
=
hm_xs
+
0.5
hm_ys
=
hm_ys
+
0.5
mask
=
(
hm_score
>
thresh
).
float
()
# 选置信度大于0.1的
hm_score
=
(
1
-
mask
)
*
-
1
+
mask
*
hm_score
hm_ys
=
(
1
-
mask
)
*
(
-
10000
)
+
mask
*
hm_ys
hm_xs
=
(
1
-
mask
)
*
(
-
10000
)
+
mask
*
hm_xs
hm_kps
=
torch
.
stack
([
hm_xs
,
hm_ys
],
dim
=-
1
).
unsqueeze
(
2
).
expand
(
batch
,
num_joints
,
K
,
K
,
2
)
dist
=
(((
reg_kps
-
hm_kps
)
**
2
).
sum
(
dim
=
4
)
**
0.5
)
# 两次求解的关节点求距离
min_dist
,
min_ind
=
dist
.
min
(
dim
=
3
)
# b x J x K
hm_score
=
hm_score
.
gather
(
2
,
min_ind
).
unsqueeze
(
-
1
)
# b x J x K x 1
min_dist
=
min_dist
.
unsqueeze
(
-
1
)
min_ind
=
min_ind
.
view
(
batch
,
num_joints
,
K
,
1
,
1
).
expand
(
batch
,
num_joints
,
K
,
1
,
2
)
hm_kps
=
hm_kps
.
gather
(
3
,
min_ind
)
hm_kps
=
hm_kps
.
view
(
batch
,
num_joints
,
K
,
2
)
# 如果在bboxes中则用第二种方法的关节点,在bboxes外用第一种方法提取的关节点,就是优先选第二种方法
l
=
bboxes
[:,
:,
0
].
view
(
batch
,
1
,
K
,
1
).
expand
(
batch
,
num_joints
,
K
,
1
)
t
=
bboxes
[:,
:,
1
].
view
(
batch
,
1
,
K
,
1
).
expand
(
batch
,
num_joints
,
K
,
1
)
r
=
bboxes
[:,
:,
2
].
view
(
batch
,
1
,
K
,
1
).
expand
(
batch
,
num_joints
,
K
,
1
)
b
=
bboxes
[:,
:,
3
].
view
(
batch
,
1
,
K
,
1
).
expand
(
batch
,
num_joints
,
K
,
1
)
mask
=
(
hm_kps
[...,
0
:
1
]
<
l
)
+
(
hm_kps
[...,
0
:
1
]
>
r
)
+
\
(
hm_kps
[...,
1
:
2
]
<
t
)
+
(
hm_kps
[...,
1
:
2
]
>
b
)
+
\
(
hm_score
<
thresh
)
+
(
min_dist
>
(
torch
.
max
(
b
-
t
,
r
-
l
)
*
0.3
))
mask
=
(
mask
>
0
).
float
().
expand
(
batch
,
num_joints
,
K
,
2
)
kps
=
(
1
-
mask
)
*
hm_kps
+
mask
*
kps
kps
=
kps
.
permute
(
0
,
2
,
1
,
3
).
contiguous
().
view
(
batch
,
K
,
num_joints
*
2
)
detections
=
torch
.
cat
([
bboxes
,
scores
,
kps
,
clses
],
dim
=
2
)
# box:4+score:1+kpoints:10+class:1=16
return
detections
src/lib/models/losses.py
0 → 100644
View file @
b952e97b
# ------------------------------------------------------------------------------
# Portions of this code are from
# CornerNet (https://github.com/princeton-vl/CornerNet)
# Copyright (c) 2018, University of Michigan
# Licensed under the BSD 3-Clause License
# ------------------------------------------------------------------------------
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
torch
import
torch.nn
as
nn
from
.utils
import
_tranpose_and_gather_feat
import
torch.nn.functional
as
F
def
_slow_neg_loss
(
pred
,
gt
):
'''focal loss from CornerNet'''
pos_inds
=
gt
.
eq
(
1
)
neg_inds
=
gt
.
lt
(
1
)
neg_weights
=
torch
.
pow
(
1
-
gt
[
neg_inds
],
4
)
loss
=
0
pos_pred
=
pred
[
pos_inds
]
neg_pred
=
pred
[
neg_inds
]
pos_loss
=
torch
.
log
(
pos_pred
)
*
torch
.
pow
(
1
-
pos_pred
,
2
)
neg_loss
=
torch
.
log
(
1
-
neg_pred
)
*
torch
.
pow
(
neg_pred
,
2
)
*
neg_weights
num_pos
=
pos_inds
.
float
().
sum
()
pos_loss
=
pos_loss
.
sum
()
neg_loss
=
neg_loss
.
sum
()
if
pos_pred
.
nelement
()
==
0
:
loss
=
loss
-
neg_loss
else
:
loss
=
loss
-
(
pos_loss
+
neg_loss
)
/
num_pos
return
loss
def
_neg_loss
(
pred
,
gt
):
''' Modified focal loss. Exactly the same as CornerNet.
Runs faster and costs a little bit more memory
Arguments:
pred (batch x c x h x w)
gt_regr (batch x c x h x w)
'''
pos_inds
=
gt
.
eq
(
1
).
float
()
neg_inds
=
gt
.
lt
(
1
).
float
()
neg_weights
=
torch
.
pow
(
1
-
gt
,
4
)
loss
=
0
pos_loss
=
torch
.
log
(
pred
)
*
torch
.
pow
(
1
-
pred
,
2
)
*
pos_inds
neg_loss
=
torch
.
log
(
1
-
pred
)
*
torch
.
pow
(
pred
,
2
)
*
neg_weights
*
neg_inds
num_pos
=
pos_inds
.
float
().
sum
()
pos_loss
=
pos_loss
.
sum
()
neg_loss
=
neg_loss
.
sum
()
if
num_pos
==
0
:
loss
=
loss
-
neg_loss
else
:
loss
=
loss
-
(
pos_loss
+
neg_loss
)
/
num_pos
return
loss
def
_not_faster_neg_loss
(
pred
,
gt
):
pos_inds
=
gt
.
eq
(
1
).
float
()
neg_inds
=
gt
.
lt
(
1
).
float
()
num_pos
=
pos_inds
.
float
().
sum
()
neg_weights
=
torch
.
pow
(
1
-
gt
,
4
)
loss
=
0
trans_pred
=
pred
*
neg_inds
+
(
1
-
pred
)
*
pos_inds
weight
=
neg_weights
*
neg_inds
+
pos_inds
all_loss
=
torch
.
log
(
1
-
trans_pred
)
*
torch
.
pow
(
trans_pred
,
2
)
*
weight
all_loss
=
all_loss
.
sum
()
if
num_pos
>
0
:
all_loss
/=
num_pos
loss
-=
all_loss
return
loss
def
_slow_reg_loss
(
regr
,
gt_regr
,
mask
):
num
=
mask
.
float
().
sum
()
mask
=
mask
.
unsqueeze
(
2
).
expand_as
(
gt_regr
)
regr
=
regr
[
mask
]
gt_regr
=
gt_regr
[
mask
]
# regr_loss = nn.functional.smooth_l1_loss(regr, gt_regr, size_average=False)
regr_loss
=
nn
.
functional
.
smooth_l1_loss
(
regr
,
gt_regr
,
reduction
=
'sum'
)
regr_loss
=
regr_loss
/
(
num
+
1e-4
)
return
regr_loss
def
_reg_loss
(
regr
,
gt_regr
,
mask
,
wight_
=
None
):
''' L1 regression loss
Arguments:
regr (batch x max_objects x dim)
gt_regr (batch x max_objects x dim)
mask (batch x max_objects)
'''
num
=
mask
.
float
().
sum
()
mask
=
mask
.
unsqueeze
(
2
).
expand_as
(
gt_regr
).
float
()
regr
=
regr
*
mask
gt_regr
=
gt_regr
*
mask
if
wight_
is
not
None
:
wight_
=
wight_
.
unsqueeze
(
2
).
expand_as
(
gt_regr
).
float
()
# regr_loss = nn.functional.smooth_l1_loss(regr, gt_regr, reduce=False)
regr_loss
=
nn
.
functional
.
smooth_l1_loss
(
regr
,
gt_regr
,
reduction
=
'none'
)
regr_loss
*=
wight_
regr_loss
=
regr_loss
.
sum
()
else
:
regr_loss
=
nn
.
functional
.
smooth_l1_loss
(
regr
,
gt_regr
,
reduction
=
'sum'
)
# regr_loss = nn.functional.smooth_l1_loss(regr, gt_regr, size_average=False)
regr_loss
=
regr_loss
/
(
num
+
1e-4
)
return
regr_loss
class
FocalLoss
(
nn
.
Module
):
'''nn.Module warpper for focal loss'''
def
__init__
(
self
):
super
(
FocalLoss
,
self
).
__init__
()
self
.
neg_loss
=
_neg_loss
def
forward
(
self
,
out
,
target
):
return
self
.
neg_loss
(
out
,
target
)
class
RegLoss
(
nn
.
Module
):
'''Regression loss for an output tensor
Arguments:
output (batch x dim x h x w)
mask (batch x max_objects)
ind (batch x max_objects)
target (batch x max_objects x dim)
'''
def
__init__
(
self
):
super
(
RegLoss
,
self
).
__init__
()
def
forward
(
self
,
output
,
mask
,
ind
,
target
,
wight_
=
None
):
pred
=
_tranpose_and_gather_feat
(
output
,
ind
)
loss
=
_reg_loss
(
pred
,
target
,
mask
,
wight_
)
return
loss
class
RegL1Loss
(
nn
.
Module
):
def
__init__
(
self
):
super
(
RegL1Loss
,
self
).
__init__
()
def
forward
(
self
,
output
,
mask
,
ind
,
target
):
pred
=
_tranpose_and_gather_feat
(
output
,
ind
)
mask
=
mask
.
unsqueeze
(
2
).
expand_as
(
pred
).
float
()
# loss = F.l1_loss(pred * mask, target * mask, reduction='elementwise_mean')
loss
=
F
.
l1_loss
(
pred
*
mask
,
target
*
mask
,
reduction
=
'sum'
)
# loss = F.l1_loss(pred * mask, target * mask, size_average=False)
loss
=
loss
/
(
mask
.
sum
()
+
1e-4
)
return
loss
class
NormRegL1Loss
(
nn
.
Module
):
def
__init__
(
self
):
super
(
NormRegL1Loss
,
self
).
__init__
()
def
forward
(
self
,
output
,
mask
,
ind
,
target
):
pred
=
_tranpose_and_gather_feat
(
output
,
ind
)
mask
=
mask
.
unsqueeze
(
2
).
expand_as
(
pred
).
float
()
# loss = F.l1_loss(pred * mask, target * mask, reduction='elementwise_mean')
pred
=
pred
/
(
target
+
1e-4
)
target
=
target
*
0
+
1
loss
=
F
.
l1_loss
(
pred
*
mask
,
target
*
mask
,
reduction
=
'sum'
)
# loss = F.l1_loss(pred * mask, target * mask, size_average=False)
loss
=
loss
/
(
mask
.
sum
()
+
1e-4
)
return
loss
class
RegWeightedL1Loss
(
nn
.
Module
):
def
__init__
(
self
):
super
(
RegWeightedL1Loss
,
self
).
__init__
()
def
forward
(
self
,
output
,
mask
,
ind
,
target
):
pred
=
_tranpose_and_gather_feat
(
output
,
ind
)
mask
=
mask
.
float
()
# loss = F.l1_loss(pred * mask, target * mask, reduction='elementwise_mean')
loss
=
F
.
l1_loss
(
pred
*
mask
,
target
*
mask
,
reduction
=
'sum'
)
# loss = F.l1_loss(pred * mask, target * mask, size_average=False)
loss
=
loss
/
(
mask
.
sum
()
+
1e-4
)
return
loss
class
L1Loss
(
nn
.
Module
):
def
__init__
(
self
):
super
(
L1Loss
,
self
).
__init__
()
def
forward
(
self
,
output
,
mask
,
ind
,
target
):
pred
=
_tranpose_and_gather_feat
(
output
,
ind
)
mask
=
mask
.
unsqueeze
(
2
).
expand_as
(
pred
).
float
()
loss
=
F
.
l1_loss
(
pred
*
mask
,
target
*
mask
,
reduction
=
'elementwise_mean'
)
return
loss
class
BinRotLoss
(
nn
.
Module
):
def
__init__
(
self
):
super
(
BinRotLoss
,
self
).
__init__
()
def
forward
(
self
,
output
,
mask
,
ind
,
rotbin
,
rotres
):
pred
=
_tranpose_and_gather_feat
(
output
,
ind
)
loss
=
compute_rot_loss
(
pred
,
rotbin
,
rotres
,
mask
)
return
loss
def
compute_res_loss
(
output
,
target
):
return
F
.
smooth_l1_loss
(
output
,
target
,
reduction
=
'elementwise_mean'
)
# TODO: weight
def
compute_bin_loss
(
output
,
target
,
mask
):
mask
=
mask
.
expand_as
(
output
)
output
=
output
*
mask
.
float
()
return
F
.
cross_entropy
(
output
,
target
,
reduction
=
'elementwise_mean'
)
def
compute_rot_loss
(
output
,
target_bin
,
target_res
,
mask
):
# output: (B, 128, 8) [bin1_cls[0], bin1_cls[1], bin1_sin, bin1_cos,
# bin2_cls[0], bin2_cls[1], bin2_sin, bin2_cos]
# target_bin: (B, 128, 2) [bin1_cls, bin2_cls]
# target_res: (B, 128, 2) [bin1_res, bin2_res]
# mask: (B, 128, 1)
# import pdb; pdb.set_trace()
output
=
output
.
view
(
-
1
,
8
)
target_bin
=
target_bin
.
view
(
-
1
,
2
)
target_res
=
target_res
.
view
(
-
1
,
2
)
mask
=
mask
.
view
(
-
1
,
1
)
loss_bin1
=
compute_bin_loss
(
output
[:,
0
:
2
],
target_bin
[:,
0
],
mask
)
loss_bin2
=
compute_bin_loss
(
output
[:,
4
:
6
],
target_bin
[:,
1
],
mask
)
loss_res
=
torch
.
zeros_like
(
loss_bin1
)
if
target_bin
[:,
0
].
nonzero
().
shape
[
0
]
>
0
:
idx1
=
target_bin
[:,
0
].
nonzero
()[:,
0
]
valid_output1
=
torch
.
index_select
(
output
,
0
,
idx1
.
long
())
valid_target_res1
=
torch
.
index_select
(
target_res
,
0
,
idx1
.
long
())
loss_sin1
=
compute_res_loss
(
valid_output1
[:,
2
],
torch
.
sin
(
valid_target_res1
[:,
0
]))
loss_cos1
=
compute_res_loss
(
valid_output1
[:,
3
],
torch
.
cos
(
valid_target_res1
[:,
0
]))
loss_res
+=
loss_sin1
+
loss_cos1
if
target_bin
[:,
1
].
nonzero
().
shape
[
0
]
>
0
:
idx2
=
target_bin
[:,
1
].
nonzero
()[:,
0
]
valid_output2
=
torch
.
index_select
(
output
,
0
,
idx2
.
long
())
valid_target_res2
=
torch
.
index_select
(
target_res
,
0
,
idx2
.
long
())
loss_sin2
=
compute_res_loss
(
valid_output2
[:,
6
],
torch
.
sin
(
valid_target_res2
[:,
1
]))
loss_cos2
=
compute_res_loss
(
valid_output2
[:,
7
],
torch
.
cos
(
valid_target_res2
[:,
1
]))
loss_res
+=
loss_sin2
+
loss_cos2
return
loss_bin1
+
loss_bin2
+
loss_res
src/lib/models/model.py
0 → 100644
View file @
b952e97b
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
torchvision.models
as
models
import
torch
import
torch.nn
as
nn
import
os
from
.networks.msra_resnet
import
get_pose_net
# from .networks.dlav0 import get_pose_net as get_dlav0
# from .networks.pose_dla_dcn import get_pose_net as get_dla_dcn
# from .networks.resnet_dcn import get_pose_net as get_pose_net_dcn
from
.networks.large_hourglass
import
get_large_hourglass_net
# from .Backbone.mobilenetv2 import get_mobile_pose_netv2
# from .Backbone.mobilenet_v2 import get_mobile_net
# from .Backbone.centerface_mobilenet_v2 import get_mobile_net
from
.Backbone.centerface_mobilenet_v2_fpn
import
get_mobile_net
_model_factory
=
{
'res'
:
get_pose_net
,
# default Resnet with deconv
# 'dlav0': get_dlav0, # default DLAup
# 'dla': get_dla_dcn,
# 'resdcn': get_pose_net_dcn,
'hourglass'
:
get_large_hourglass_net
,
'mobilev2'
:
get_mobile_net
,
}
def
create_model
(
arch
,
heads
,
head_conv
):
num_layers
=
int
(
arch
[
arch
.
find
(
'_'
)
+
1
:])
if
'_'
in
arch
else
0
arch
=
arch
[:
arch
.
find
(
'_'
)]
if
'_'
in
arch
else
arch
get_model
=
_model_factory
[
arch
]
model
=
get_model
(
num_layers
=
num_layers
,
heads
=
heads
,
head_conv
=
head_conv
)
return
model
def
load_model
(
model
,
model_path
,
optimizer
=
None
,
resume
=
False
,
lr
=
None
,
lr_step
=
None
):
start_epoch
=
0
checkpoint
=
torch
.
load
(
model_path
,
map_location
=
lambda
storage
,
loc
:
storage
)
print
(
'loaded {}, epoch {}'
.
format
(
model_path
,
checkpoint
[
'epoch'
]))
state_dict_
=
checkpoint
[
'state_dict'
]
state_dict
=
{}
# convert data_parallal to model
for
k
in
state_dict_
:
if
k
.
startswith
(
'module'
)
and
not
k
.
startswith
(
'module_list'
):
state_dict
[
k
[
7
:]]
=
state_dict_
[
k
]
else
:
state_dict
[
k
]
=
state_dict_
[
k
]
model_state_dict
=
model
.
state_dict
()
# check loaded parameters and created model parameters
for
k
in
state_dict
:
if
k
in
model_state_dict
:
if
state_dict
[
k
].
shape
!=
model_state_dict
[
k
].
shape
:
print
(
'Skip loading parameter {}, required shape{}, '
\
'loaded shape{}.'
.
format
(
k
,
model_state_dict
[
k
].
shape
,
state_dict
[
k
].
shape
))
state_dict
[
k
]
=
model_state_dict
[
k
]
else
:
print
(
'Drop parameter {}.'
.
format
(
k
))
for
k
in
model_state_dict
:
if
not
(
k
in
state_dict
):
print
(
'No param {}.'
.
format
(
k
))
state_dict
[
k
]
=
model_state_dict
[
k
]
model
.
load_state_dict
(
state_dict
,
strict
=
False
)
# resume optimizer parameters
if
optimizer
is
not
None
and
resume
:
if
'optimizer'
in
checkpoint
:
optimizer
.
load_state_dict
(
checkpoint
[
'optimizer'
])
start_epoch
=
checkpoint
[
'epoch'
]
start_lr
=
lr
for
step
in
lr_step
:
if
start_epoch
>=
step
:
start_lr
*=
0.1
for
param_group
in
optimizer
.
param_groups
:
param_group
[
'lr'
]
=
start_lr
print
(
'Resumed optimizer with start lr'
,
start_lr
)
else
:
print
(
'No optimizer parameters in checkpoint.'
)
if
optimizer
is
not
None
:
return
model
,
optimizer
,
start_epoch
else
:
return
model
def
save_model
(
path
,
epoch
,
model
,
optimizer
=
None
):
if
isinstance
(
model
,
torch
.
nn
.
DataParallel
):
state_dict
=
model
.
module
.
state_dict
()
else
:
state_dict
=
model
.
state_dict
()
data
=
{
'epoch'
:
epoch
,
'state_dict'
:
state_dict
}
if
not
(
optimizer
is
None
):
data
[
'optimizer'
]
=
optimizer
.
state_dict
()
torch
.
save
(
data
,
path
)
src/lib/models/networks/DCNv2/.gitignore
0 → 100644
View file @
b952e97b
.vscode
.idea
*.so
*.o
*pyc
_ext
\ No newline at end of file
src/lib/models/networks/DCNv2/LICENSE
0 → 100644
View file @
b952e97b
BSD 3-Clause License
Copyright (c) 2019, Charles Shang
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
src/lib/models/networks/DCNv2/README.md
0 → 100644
View file @
b952e97b
## Deformable Convolutional Networks V2 with Pytorch
### Build
```
bash
./make.sh
# build
python test.py
# run examples and gradient check
```
### An Example
-
deformable conv
```
python
from
dcn_v2
import
DCN
input
=
torch
.
randn
(
2
,
64
,
128
,
128
).
cuda
()
# wrap all things (offset and mask) in DCN
dcn
=
DCN
(
64
,
64
,
kernel_size
=
(
3
,
3
),
stride
=
1
,
padding
=
1
,
deformable_groups
=
2
).
cuda
()
output
=
dcn
(
input
)
print
(
output
.
shape
)
```
-
deformable roi pooling
```
python
from
dcn_v2
import
DCNPooling
input
=
torch
.
randn
(
2
,
32
,
64
,
64
).
cuda
()
batch_inds
=
torch
.
randint
(
2
,
(
20
,
1
)).
cuda
().
float
()
x
=
torch
.
randint
(
256
,
(
20
,
1
)).
cuda
().
float
()
y
=
torch
.
randint
(
256
,
(
20
,
1
)).
cuda
().
float
()
w
=
torch
.
randint
(
64
,
(
20
,
1
)).
cuda
().
float
()
h
=
torch
.
randint
(
64
,
(
20
,
1
)).
cuda
().
float
()
rois
=
torch
.
cat
((
batch_inds
,
x
,
y
,
x
+
w
,
y
+
h
),
dim
=
1
)
# mdformable pooling (V2)
# wrap all things (offset and mask) in DCNPooling
dpooling
=
DCNPooling
(
spatial_scale
=
1.0
/
4
,
pooled_size
=
7
,
output_dim
=
32
,
no_trans
=
False
,
group_size
=
1
,
trans_std
=
0.1
).
cuda
()
dout
=
dpooling
(
input
,
rois
)
```
### Known Issues:
-
[x] Gradient check w.r.t offset (solved)
-
[ ] Backward is not reentrant (minor)
This is an adaption of the official
[
Deformable-ConvNets
](
https://github.com/msracver/Deformable-ConvNets/tree/master/DCNv2_op
)
.
<s>
I have ran the gradient check for many times with DOUBLE type. Every tensor
**except offset**
passes.
However, when I set the offset to 0.5, it passes. I'm still wondering what cause this problem. Is it because some
non-differential points?
</s>
Update: all gradient check passes with double precision.
Another issue is that it raises
`RuntimeError: Backward is not reentrant`
. However, the error is very small (
`<1e-7`
for
float
`<1e-15`
for double),
so it may not be a serious problem (?)
Please post an issue or PR if you have any comments.
\ No newline at end of file
Prev
1
2
3
4
5
6
7
8
9
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}