We list some common problems encountered by users and the corresponding solutions here. Feel free to enrich the list if you find any frequent issues and have ways to help others solve them.
## Training
- "Loss goes NaN or very large"
1. Check if the dataset annotations are valid. Mask must be `{0, 1}` where `1` for tokens that are **not masked** and `0` for tokens that are **masked**.
2. Check `initializer_range` in config file. It can be safely set to `0.02` in most cases. If the model size is very large, decreasing `initializer_range` is a good choice. For example, `initializer_range` can be set to `0.006` when training 175 billion parameter configuration GPT-3 model.
- "AMP enabled goes NaN"
Set `ONEFLOW_DEBUG_KERNEL_SYNC_CHECK_NUMERICS=1` to check what triggers an overflow of the value range in fp16.
- "GPU out of memory when validation"
Decrease `test_micro_batch_size` and use `--fast-dev-run` for quickly running through training and evaluation to check if memory is sufficient.
## Model
- "`apply_query_key_layer_scaling` in MultiheadAttention"
As the number of attention heads increases, some of the GEMMS inside the self-attention layer become smaller and the number of elements in the self attention softmax also increases.
- "QKV implementation is not consistent with Hugging Face in self attention"
In tensor parallelism, `chunk` dimension and `flow.sbp.split` dimension will be the same in Huggingface's implementation which will occur some unexpected behaviors (i.e., changing the tensor's SBP unexpectedly).
We also provide a tutorial about how to load Huggingface weights correctly. Please refer to [How to use Huggingface's pretrained weights in LiBai](https://libai.readthedocs.io/en/latest/notes/How_to_implement_huggingface%27s_weights_in_LiBai.html) for more details.
- "the order of layer normalization and the residual connection"
This is critical to enable the scaling of the BERT-style models beyond BERT-Large. The architecture with `apply_residual_post_layernorm=False` eliminates instabilities observed using the origin BERT architecture with `apply_residual_post_layernorm=True` and also has a lower training loss according to [Megatron-LM](https://arxiv.org/pdf/1909.08053.pdf).
If you find some troubles hard to understand, feel free to open an issue to collect feedbacks in [OneFlow](https://github.com/Oneflow-Inc/oneflow).
# Detailed instruction on building Vision Transformer models in LiBai
It's easy for users to build the `transformer-based` models by using LiBai's built-in [layers](https://libai.readthedocs.io/en/latest/modules/libai.layers.html). Let's take a deep dive into the process of building a Vision Transformer model in LiBai.
## Model Architecture
**Vision Transformer** was released in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
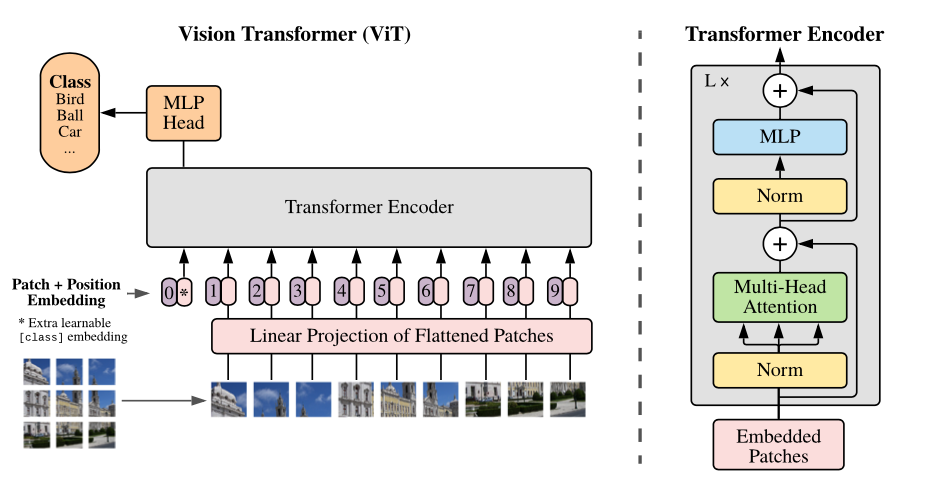
A **Vision Transformer** model contains three parts: `Patch Embedding` + `Transformer Block` + `Linear Classification Head`, which can be summarized in the following picture:

## A simple Torch implementation of Vision Transformer
The following code shows the PyTorch implementation of ViT models modified from [timm.models.vision_transformer](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py):
We have further decoupled the forward function into `forward_features` and `forward_head`:
-`forward_features`: extract the image features using the `patch_embed` layer and a stack of `transformer` blocks
-`forward_head`: take the `cls_token` of each sample and use `nn.Linear` for classification
## Implement 3D parallel Vision Transformer in LiBai
In this section, we will show users how to use [libai.layers](https://libai.readthedocs.io/en/latest/modules/libai.layers.html) to build a 3D parallel Vision Transformer model with only 100+ lines of code, which is modified from [libai.models.vision_transformer](https://github.com/Oneflow-Inc/libai/blob/main/libai/models/vision_transformer.py)
Here is the LiBai implementation of Vision Transformer models, and users only need to replace the PyTorch modules with the corresponding `libai.layers` as follows:
## Details about LiBai's implementation of the Vision Transformer model
**1. Replace nn.Module with libai.layers**
LiBai has already implemented `PatchEmbedding`, `TransformerLayer`, `Linear`, `LayerNorm` layers, and users only need to replace the module in Torch Vision Transformer models to convert a Torch model into LiBai's style:
-`Block` -> `libai.layers.TransformerLayer`
-`nn.Linear` -> `libai.layers.Linear`
-`nn.LayerNorm` -> `libai.layers.LayerNorm`
-`PatchEmbed` -> `libai.layers.PatchEmbedding`
**2. Manually set the SBP signature of `cls_token` and `pos_embed`**
In order to fit different parallel modes in LiBai, users must manually set the [SBP signature](https://docs.oneflow.org/en/master/parallelism/02_sbp.html#spb-signature) for all the parameters and buffers of those layers not implemented in LiBai, like `cls_token` and `pos_embed` in Vision Transformer:
- The SBP signature returned by `dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.broadcast])` means to broadcast `cls_token` and `pos_embed` across each GPU group.
**3. Use the `to_global()` function to update the SBP signature of `cls_token` and `pos_embed` during forward function**
In forward function, `cls_token` and `pos_embed` will be expanded to fit the input size. For efficiency, we can use the `to_global()` function to match the `cls_token` and `pos_embed` SBP signature with the input SBP signature like this:
```python
defforward_features(self,x):
cls_token=self.cls_token.expand(
x.shape[0],-1,-1
)
# use to_global to update the sbp signature of cls_token
**4. Manually set the stage id for pipeline parallel training**
Most of the built-in layers in LiBai has the arg named `layer_idx` for pipeline parallel settings. To configure a **1F1B pipeline parallel** model, users should manually set the stage id for each layers in the model, which will automatically assign different layers on different stages and insert buffer in the process of forward & backward computation for 1F1B pipeline parallel training. With the help of `layer_idx`, we can simply get a pipeline parallel Vision Transformer model like:
```python
importlibai.utils.distributedasdist
"""
This is a staticmethod for class inherited from nn.Module,
"""
@staticmethod
defset_pipeline_stage_id(model):
dist_utils=dist.get_dist_util()
# Set pipeline parallelism stage_id
formodule_blockinmodel.modules():
# module_block.to(nn.Module) can get the original module
- Automatically assign the stage for `TransformerLayer` with `layer_idx` args
-`cls_token`, `pos_embed`, `pos_drop` should be on the first stage
-`norm`, `head` and `loss_func` should be on the last stage
Please see [Write your own pipeline parallel model](https://libai.readthedocs.io/en/latest/tutorials/advanced_tutorials/customize_parallel.html#write-your-own-pipeline-parallel-model) for more details about the settings of pipeline parallel training in LiBai.
If you want to define your own HuggerFace's model loader, you can inherit the base `ModelLoaderHuggerFace` in `libai.models.utils.model_loader.base_loader`.
Then you need to overwrite the `_convert_state_dict` and `_load_config_from_json` method to load HuggingFace's pretrained model in LiBai.
Finally, you need set `base_model_prefix_1` and `base_model_prefix_2` argument, which represent the base model name for HuggingFace and LiBai respectively.
The following code shows how to use custom ModelLoaderHuggerFace:
"""NOTE: base_model_prefix_1 is ToyModel's prefix in Transformers.
base_model_prefix_2 is ToyModel's prefix in LiBai."""
self.base_model_prefix_1="toy_model"
self.base_model_prefix_2="toy_model"
def_convert_state_dict(self,flow_state_dict,cfg):
"""Convert state_dict's keys to match model.
Args:
flow_state_dict (OrderedDict): model state dict.
cfg (dict): model's default config dict in LiBai.
Returns:
OrderedDict: flow state dict.
"""
...
def_load_config_from_json(self,config_file):
"""load config from `config.json`, and update default config.
Args:
config_file (str): Path of config file.
"""
...
```
## Model Loader for LiBai
If you want to define your own LiBai's model loader, you can inherit the base `ModelLoaderLiBai` class in `libai.models.utils.model_loader.base_loader`.
You just need to set `base_model_prefix_2` argument to load LiBai's pretrained model.
The following code shows how to use custom ModelLoaderLiBai:
# Detailed instruction for using distributed inference in LiBai
If you want to using distributed inference in LiBai from pretrained `pytorch` model, you can refer to [DALLE2 inferecn doc](https://github.com/Oneflow-Inc/libai/blob/main/docs/source/notes/How_to_use_model_parallel_in_LiBai.md). And [Chinese doc for distributed inference](https://github.com/Oneflow-Inc/libai/discussions/386) is also available.
Here we introduce how to use distributed infenrence in LiBai:
## Check `model.py`
check your `model.py` first:
1. Ensure There are `libai.layers` in your `model.py`:
```python
# NOTE: you don't need to import all layers from libai, if you only use libai.layers.Linear
# in your `model.py`, you model will run model/pipeline parallel only in `Linear` layers
fromlibai.layersimport(
Linear,
LayerNorm,
...
)
```
2. If you want to run pipeline parallel in LiBai, you should additionally insert code `x = x.to_global(placement=target_tensor.placement)` in your `model.forward()`.
It is equal to torch code `x.to(cuda_device)`, which move tensor from gpuA to gpuB. There are many examples in LiBai: [example1](https://github.com/Oneflow-Inc/libai/blob/92dbe7c1b1496290e32e595f8473f9288ea1886e/projects/MT5/layers/attention_layer.py#L220), [example2](https://github.com/Oneflow-Inc/libai/blob/92dbe7c1b1496290e32e595f8473f9288ea1886e/projects/MT5/layers/attention_layer.py#L156) ...
If you don't know where to insert code, you can run your code first, and the it will raise bug in the line which needed `to_global`.
for example:
```shell
File "libai/libai/layers/layer_norm.py", line 129, in forward
return flow._C.rms_layer_norm(hidden_states, self.weight, self.l2norm_epsilon) RuntimeError: return flow._C.rms_layer_norm(hidden_states, self.weight, self.l2norm_epsilon)RuntimeErrorExpected all tensors to be on the same placement, but found at least two placements, oneflow.placement(type="cuda", ranks=[0, 1]) (positional 0) and oneflow.placement(type="cuda", ranks=[2, 3]) (positional 1)!
```
## Build `config.py`
If your model is Trained from LiBai, you can use the same `config.py` from training. refer to [Couplets](https://github.com/Oneflow-Inc/libai/tree/main/projects/Couplets#inference) for more details
If your model is Trainer from other framework, you should build your own `inference_config.py`, you can refer to [`dalle2_config.py`](https://github.com/Oneflow-Inc/libai/blob/main/projects/DALLE2/configs/dalle2_config.py) and [`t5_inference_config.py `](https://github.com/Oneflow-Inc/libai/blob/main/projects/MT5/configs/t5_inference.py)
## Refine `pipeline_inference.py`
The base class [libai/inference/basic.py](https://github.com/Oneflow-Inc/libai/blob/main/libai/inference/basic.py) is already provided in `LiBai` ,
Users only need to overload the functions they need. refer to [text_generation.py](https://github.com/Oneflow-Inc/libai/blob/main/libai/inference/text_generation.py)
If your model is trained from `LiBai`, it will be easy to use, you can refer to [distribute_infer.py](https://github.com/Oneflow-Inc/libai/blob/main/projects/Couplets/distribute_infer.py) in [Couplets](https://github.com/Oneflow-Inc/libai/tree/main/projects/Couplets)
If your model is trained from other framework, you need to build your own `model_loader` to load your model weights in LiBai, refer to [model_loader](https://libai.readthedocs.io/en/latest/notes/How_to_load_huggingface%27s_pretrained_model_in_libai.html) for more details
Give a simple example, the function overloaded in `LiBai`:
```python
fromlibai.inference.basicimportBasePipeline
fromlibai.utilsimportdistributedasdist
classMyPipeline(BasePipeline):
def_parse_parameters(self,**pipeline_parameters):
# By overloading this function, the input parameters in MyPipeline.__call__() hand out to preprocess/forward/postprocess stages of inference.
# How to use Huggingface's pretrained weights in LiBai
The built-in layers in [LiBai](https://github.com/Oneflow-Inc/libai) adopts the structure which is more suitable for parallel training, therefore the implementation in LiBai may be a little bit different from that in Huggingface. In this tutorial, we will introduce to users how to correctly load Huggingface's pretrained weights into LiBai's model. Let's take BERT as an example.
## LiBai Transformer vs Huggingface Transformer
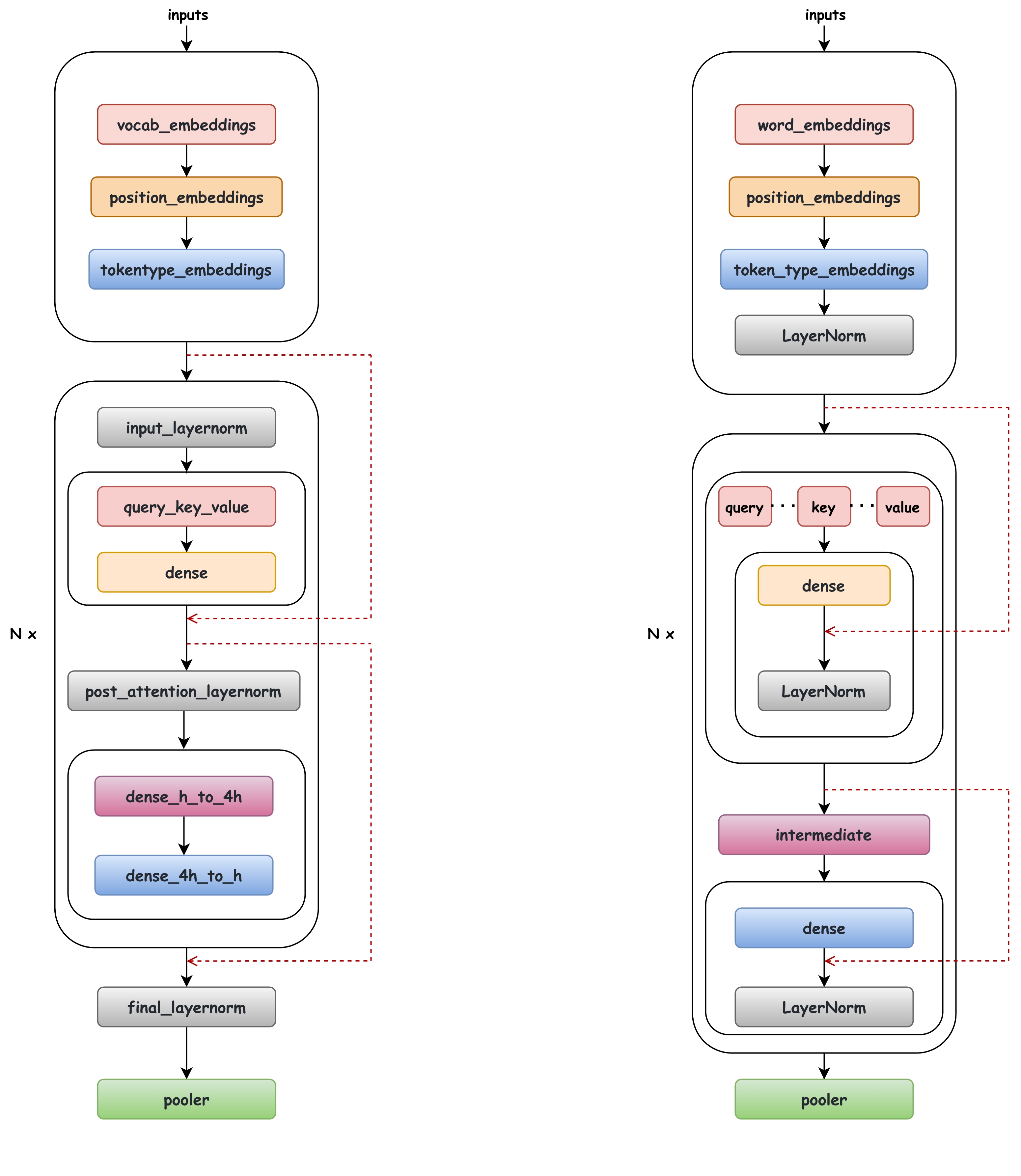
There are subtle differences in the BERT structure as shown in the following figure (left: LiBai, right: Huggingface), which can be summarized as:
- Location of layernorm: The location of layernorm is different, but the calculation order is the same.
- A different slicing way to get the `query`, `key` and `value` matrix.
- LiBai follows [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) to use the order of the layernorm and the residual connections by default. Megatron-LM shows that this structure will eliminate instabilities and bring a lower training loss. LiBai can also support the original BERT architecture mentioned in [Paper](https://arxiv.org/pdf/1810.04805.pdf) by setting `apply_residual_post_layernorm=True`.

## QKV slicing logic
LiBai's QKV slicing logic is different from that in Huggingface.
- For detailed examples, please refer to [load-huggingface-bert](https://github.com/Oneflow-Inc/libai/tree/test_bert_load_huggingface_weight/projects/test_bert_load_huggingface_weight). You can verify this by running:
# Detailed instruction on using model parallel in LiBai
This document is a tutorial for users to learn how to transer a pytorch model to oneflow, and use model parallel in Libai for inference. We will first take the DALLE2 model for example, and then we will show how to use model parallel which can be easily done in libai.
**Note**: the code of DALLE2 is adapted from [this repo](https://github.com/lucidrains/DALLE2-pytorch), which is an unofficial implementation. The final result may differ from the original generated images in the [paper](https://arxiv.org/abs/2204.06125). You can also try the model in [google colab](https://colab.research.google.com/github/LAION-AI/dalle2-laion/blob/main/notebooks/dalle2_laion_alpha.ipynb).
## Transfer pytroch model to oneflow.
It's easy for user to tansfer a pytorch model into oneflow, since most of oneflow's api is consistent with pytorch. First we change `import torch` to `import oneflow as flow`, and then we can replace all `torch` in the code to `flow`. If the model can work correctly in the originally
pytorch codes, it's likely to be able to work correctly in oneflow. Sometimes the program may raise error like
```
AttributeError: module 'oneflow' has no attribute 'xxx'
```
try install the latest version of oneflow which might help, you can find more details [here](https://github.com/Oneflow-Inc/oneflow#install-oneflow).
**1、Download the pytorch DALLE2 model**:
As show in the [google colab](https://colab.research.google.com/github/LAION-AI/dalle2-laion/blob/main/notebooks/dalle2_laion_alpha.ipynb), we will use the version of 0.15.4,
the pretrained model weights can be found in huggingface: [the prior weight](https://huggingface.co/zenglishuci/conditioned-prior/resolve/main/vit-l-14/prior_aes_finetune.pth) and [the decoder weight](https://huggingface.co/laion/DALLE2-PyTorch/resolve/main/decoder/1.5B_laion2B/latest.pth).
text=["a dolphin in an astronaut suit on saturn, artstation"]
images=gen_text_and_img_emb(text)
save_images(images)
if__name__=="__main__":
main()
```
run `python inference_dalle2.py`, this should work.
## 2、Change the deep learning framework to oneflow.
As mentioned above, we replace all the `torch` symbol to `flow` by firstly change `import torch` to `import oneflow as flow` in all python files.
It should be noted that the original pytorch code also import other python packages using pytorch backend like [einops](https://github.com/arogozhnikov/einops)、[einops_ext](https://github.com/lucidrains/einops-exts)、[kornia](https://github.com/kornia/kornia) etc. which should also be modified at the same time.
Fortunately, only a few api of these packages are used, we can take out the relevant code from the github repos and merge them in a separate file.
For example, we can simplely create the einops_ext.py file adapted from [here](https://github.com/lucidrains/einops-exts/blob/main/einops_exts/einops_exts.py), then we can import einops_ext from the python file which use oneflow instead of python packages using torch.
[LiBai](https://github.com/Oneflow-Inc/libai) is a large-scale open-source model training toolbox based on OneFlow.
Libai provides many efficient api which can be easily used for distributed training and evaluation. It also supports some popular models under the projects folder such as [CLIP](https://github.com/Oneflow-Inc/libai/tree/main/projects/CLIP). To avoid duplication of work, we directly use the clip model implemented in Libai. The relavant code in the original pytorch code is the `OpenAIClipAdapter` class which can be written as follows:
[DiffusionPrior](https://github.com/lucidrains/DALLE2-pytorch/blob/v0.15.4/dalle2_pytorch/dalle2_pytorch.py#L873) and [Decoder](https://github.com/lucidrains/DALLE2-pytorch/blob/v0.15.4/dalle2_pytorch/dalle2_pytorch.py#L1802) follow their original implementation.
**Using libai.layers**
LiBai provides multiple parallelisms such as Data Parallelism, Tensor Parallelism, and Pipeline Parallelism. To experience these features, we will use libai.layers like Linear and LayerNorm:
```python
fromlibai.layersimportLinear,LayerNorm
```
the nn.Linear will be replace with `libai.layers.Linear`.
**Compare the outputs** To make sure it is correctly modified from `torch` to `flow`, it's necessary to compare the outputs to see if they are the same after the change. A notable point here is that in the sampling stage, the noise are randomly generated, like
```python
noise=flow.randn(shape)
# or noise = torch.randn(shape) in torch code
```
torch and oneflow will generate different numbers here even if they are set the same random seed. An alternate way is to make a transition through numpy:
```python
importnumpyasnp
np.random.seed(6666)
noise=flow.tensor(np.randn(shape))
# or noise = torch.tensor(np.randn(shape)) in torch code
```
When the model is fed the same input text, the output images by oneflow or torch code should be same.
**LazyConfig and LazyCall**
Oneflow provides LazyConfig system for more flexible syntax and no predefined structures, find more [here](https://libai.readthedocs.io/en/latest/tutorials/basics/Config_System.html). As for the DALLE2, the config file can be write as
cond_on_text_encodings=True,# set to True for any unets that need to be conditioned on text encodings
self_attn=[False,True,True,True]
)
decoder=LazyCall(Decoder)(
unet=(unet1,),
image_sizes=[64,],
clip=None,
channels=3,
timesteps=1000,
loss_type="l2",
beta_schedule=["cosine"],
learned_variance=True
)
dalle2_model=LazyCall(DALLE2)(
prior=prior,
decoder=decoder,
prior_weight_path='',
decoder_weight_path=''
)
```
## 4、Model parallel in Libai.
In order to achieve the model parallel inference under libai, we should set the parallel mode according to your needs. The default value of argument parallel is `data` in libai.layers.Linear, which means data parallel. To achieve model parallel, we need change the parallel to `col` or `row`. The most efficient way is to set the Linear layers in the col -> row -> col order.
A transformer block contains a attention and a feedforward submodule, and each submodule exactly contains 2 Linear layers.
The attention module contains the qkv projection and out projection. Thus we set the qkv projejction as `col`, and the out projection as `row`:
Dataloader is the component that provides data to models. Dataloader usually (but not necessarily) takes raw information from [write dataloaders](https://libai.readthedocs.io/en/latest/tutorials/basics/Write_Dataloaders.html), and processes them into the format needed by the model.
## How the Existing Dataloader Works
LiBai contains a built-in data loading pipeline. It's beneficial to understand how it works, in case you need to write a custom one.
LiBai provides some functions [build_{image,nlp}_{train,test}_loader](https://libai.readthedocs.io/en/latest/modules/libai.data.html#libai.data.build.build_nlp_train_loader) that create a default dataloader from a given config. Here is how `build_{image,nlp}_{train,test}_loader` work:
1. It instantiates the `list[flow.utils.Dataset]` (e.g., `BertDataset`) by loading some dataset items with lightweight format. These dataset items are not yet ready to be used by the model (e.g., images are not loaded into memory, random augmentation have not been applied, etc.).
2. The output format of dataset (`__getitem__(...)`) must be a dict whose keys must be consistent with argument names of the dataloader's consumer (usually the `model.forward(...)`). The role of the process is to transform the lightweight representation of a dataset item into a format that is ready for the model to consume (including, e.g., read images, perform random data augmentation and convert to oneflow Tensors). If you would like to perform custom transformations to data, you often want to rewrite it. Details about the dataset format can be found in [write dataloaders](https://libai.readthedocs.io/en/latest/tutorials/basics/Write_Dataloaders.html).
3. The outputs of the dataset are simply batched with the following function.
```python
deftrivial_batch_collator(batch):
assertisinstance(batch[0],Instance),"batch[0] must be `instance` for trivial batch collator"
batch=Instance.stack(batch)
returnbatch
```
4. This batched data is the output of the dataloader. Typically, it's also the input of `get_batch`. After `get_batch(...)`, it becomes the input of `model.forward()`. `get_batch` simply changes the local tensors to global tensors with the given `sbp` and `placement` meta information.
```python
@classmethod
defget_batch(cls,data,mixup_func=None):
...
ret_dict={}
forkey,valueindata.get_fields().items():
value.to_global()
ret_dict[key]=value.tensor
returnret_dict
```
## Use Custom Dataloader
If you use `DefaultTrainer`, you can overwrite its `build_train_loader` method to use your own dataloader which can be implemented with any tools you like. But you need to make sure that each rank is reading the data correctly under different parallelism circumstances.
Then you need to overwrite `get_batch` method. `data` argument in `get_batch` is the output of your dataloader. You need to change the local tensors to global tensors manually, which means you should set the `sbp` and `placement` correctly.
Here is an example. Process of rank0 gets all data and redistributes them into the other ranks.
```python
@classmethod
defget_batch(cls,data,mixup_func=None):
ifdataisNone:
# not rank0, set placeholders for data
# Note: make sure imgs and labels have the same shape and dtype on all ranks
Common parallelisms have already been implemented in LiBai, such as data parallel, tensor parallel and pipeline parallel. But there is also a need for user customized parallel. In this tutorial, we will show you how to customize your own parallelism.
## Define your own Parallel Model with LiBai.layers
### Large-scale FC
Suppose you have a huge fully-connected-layer for large-scale classification (e.g., 1000w classes), which makes it impossible to fit into a single GPU.
Don't worry, with the help of `LiBai.layers`, you can write models in a familiar way that you used to write for a single GPU. Here is a simple example showing how to write a tensor-parallel fully-connected-layer with 2 GPUs.
In the result, you can find that `y` has been split along with `axis=1` on 2 GPUs.
### Large MLP models
Suppose you have a huge MLP model which is very popular in transformer-based models, with a huge hidden size that makes it difficult to fit into a single GPU.
You can then split the model weights across GPUs in a hybrid parallel mode while you can still write your model in a familiar way.
Here is a simple example about the 2D parallel MLP in the LiBai context.
From above, you can see that the data are split into 2 groups for data parallel, and weights are split into 2 groups for tensor model parallel. So this simple example just implements a 2D parallel.
For your convenience, we provide some prevalent models such as BERT, GPT-2, and ViT in Mode Zoo. Feel free to customize them into different sizes to fit into your special needs.
## Write your own Pipeline Parallel Model
This tutorial describes how to use pipeline parallel in your own model. LiBai has two pipeline-parallel modes: naive pipeline parallel and (similar) 1F1B pipeline parallel introduced by [Megatron-LM](https://arxiv.org/abs/1909.08053).
### Introduction of Naive Pipeline Parallel
In LiBai, naive pipeline parallel can be implemented by setting layers and parameters `placement`.
You can easily configure their `placement` by `dist.get_layer_placement(idx)`.
After configuring models placement, add the input placement transition across different stages. LiBai sets a `layer_idx` attribute in each `nn.Module`, so you can simply add `to_global` in `forward` to implement input placement transition.
After configuring models and data placement, you only need to set the distributed configuration before training.
```python
# set pipeline stages to 2
train.dist.pipeline_parallel_size=2
# set model layers for pipeline
train.dist.pipeline_num_layers=hidden_layers
```
### Introduction of 1F1B Pipeline Parallel
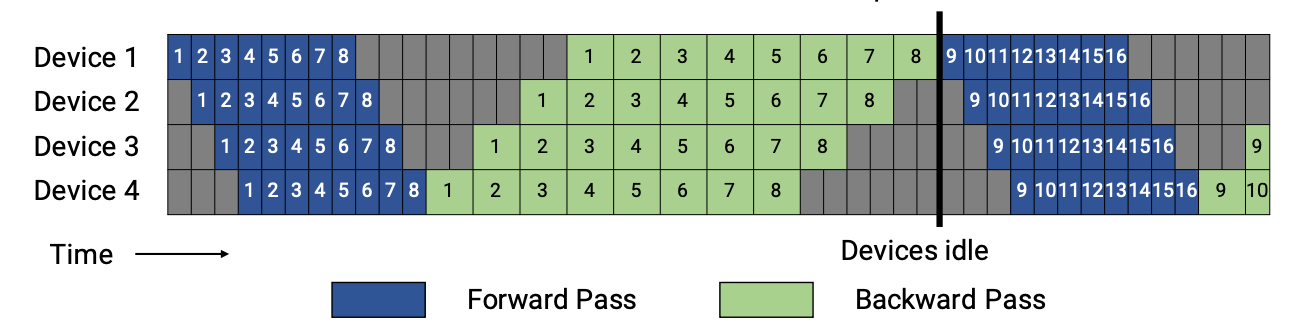
First, we will introduce GPipe to you to get a better understanding of pipeline parallelism. In GPipe, when the forward passes of all microbatches finish, the backward passes would be executed (as shown in below).

1F1B performs one forward pass followed by one backward pass. Finally, at the end of a batch, complete backward passes for all remaining in-flight microbatches. In general, 1F1B is more efficient than GPipe.
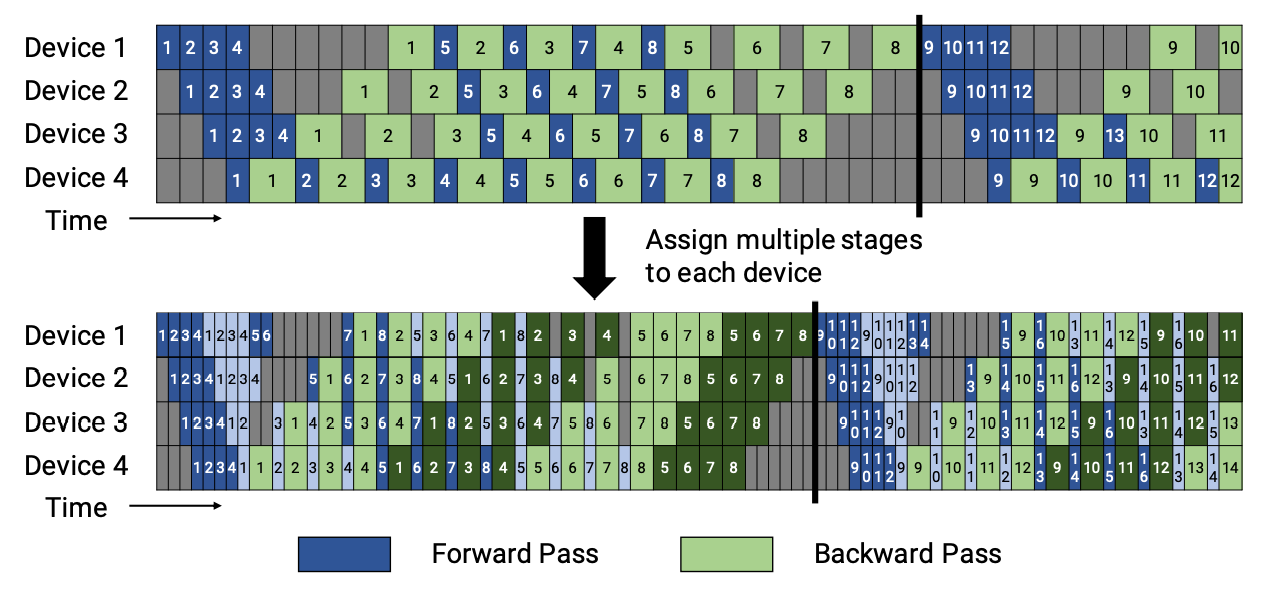
There are two schedules of 1F1B pipeline: the non-interleaved and the interleaved. The figures are shown below.

In LiBai, the non-interleaved schedule is supported currently, and this mode is more memory-efficient than GPipe.
You only need to set models stage id except that placement configuration in naive pipeline parallel, and stage id can help create stashed buffers for activation.
This example shows how to configure bert model stage id:
```python
classBertForPreTraining(nn.Module):
def__init__(self,...):
...
defforward(self,...):
...
@staticmethod
defset_pipeline_stage_id(model):
dist_utils=dist.get_dist_util()
# Set pipeline parallelism stage_id
formodule_blockinmodel.modules():
# module_block.to(nn.Module) can get the original module
In `set_pipeline_stage_id`, `BertEmbeddings` and `BertExtendedAttnMask` are placed in the first stage, then each `TransformerLayer` is uniformly placed in each stages. At last, place `BertPooler` and `BertPreTrainingHeads` in the last stage. But don't forget to place the last `layernorm` in `BertEncoder` which does not belong to any `TransformerLayer` in the last stage.
After adding the `set_pipeline_stage_id` function in a pre-defined `nn.Module`, `GraphBase` will invoke it automatically as below:
LiBai supports **auto-parallel training** which means LiBai will automatically find **an efficient parallel training strategy** for a specific model during training. Users can try out auto-parallel training by the following steps.
This is a basic guide to build new projects based on LiBai. The advantages of using LiBai to start a new project (such as paper reproduction and finetune task) are as follows:
- Avoid redundant work. Developers can directly inherit many built-in modules from LiBai.
- Easily reproduce the experiments already run, because LiBai will save the configuration file automatically.
- Automatically output useful information during training time, such as remaining training time, current iter, throughput, loss information and current learning rate, etc.
- Set a few config params to enjoy distributed training techniques.
## Introduction
Take the [Bert Finetune](https://github.com/Oneflow-Inc/libai/tree/main/projects/QQP) task as an example to introduce LiBai.
The complete file structure of the project is:
```
projects/my_project
├── configs
│ └── config_custom.py
│ └── ...
├── dataset
│ ├── custom_dataset.py
│ └── ...
├── modeling
│ ├── custom_model.py
│ └── ...
├── README.md
```
To start a new project based on LiBai step by step:
Step 1. Prepare an independent config file (such as [config.py](https://github.com/Oneflow-Inc/libai/blob/main/projects/QQP/configs/config_qqp.py)) which contains:
- The relevant parameters of the task.
- The pre-defined related Class, such as `Model`, `Optimizer`, `Scheduler`, `Dataset`.
- You can inherit the default config in `configs/common` and rewrite it, which can greatly reduce the workload.
- Related class defined with LazyCall which returns a dict instead of calling the object.
Step 2. Prepare a model file (such as [model.py](https://github.com/Oneflow-Inc/libai/blob/main/projects/QQP/modeling/model.py)) :
- Build related models in this file. The construction method is similar to OneFlow.
- Because Libai will set up a static diagram by default, the calculation of loss needs to be inside the model.
- The function `forward` must return a dict.
- When defining a tensor in the model, you need to use `to_global`. Turn tensor into a global pattern.
- When defining layers, you can import them directly from `libai.layers`, because it has already pre-defined the SBP signature.
Step 3. Prepare a dataset file (such as [dataset.py](https://github.com/Oneflow-Inc/libai/tree/main/projects/QQP/dataset)) :
- Build `Dataset` in this file. The construction method is similar to OneFlow.
- The difference is that you need to use `DistTensorData` and `Instance`.
- The shape of each batch must be global.
- In `__getitem__` function, the `key` returned by the method must be consistent with the parameter name of the `forward` function in the `model`.
## Main Function Entry
[tools/train_net.py](https://github.com/Oneflow-Inc/libai/blob/main/tools/train_net.py) is the default main function entry provided in LiBai.
## Build Config
The `config.py` in LiBai is special, which takes the form of lazyconfig and will be saved as `.yaml` at runtime. The config has several necessary fields, such as `train`, `model`, `optim`, `lr_scheduler`, `graph`. For more information, please refer to [Config_System.md](https://libai.readthedocs.io/en/latest/tutorials/Config_System.html).
> All imported modules must take LiBai as the root directory. Otherwise, the saved `yaml` file cannot save the correct path of the module, resulting in an error when reading `yaml`, and the experiment cannot be reproduced.
After building the `config.py`, if you want to get the corresponding fields in the project, you need to access like `cfg.my_cfg.***`.
## Start Training
The `train.sh` file contains some parameters, such as `GPUS`, `NODE`, etc.

{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}