# Bert
本示例主要通过Bert模型说明如何使用MIGraphX Python API进行自然语言处理模型的推理,包括数据准备、预处理、模型推理以及数据后处理。
## 模型简介
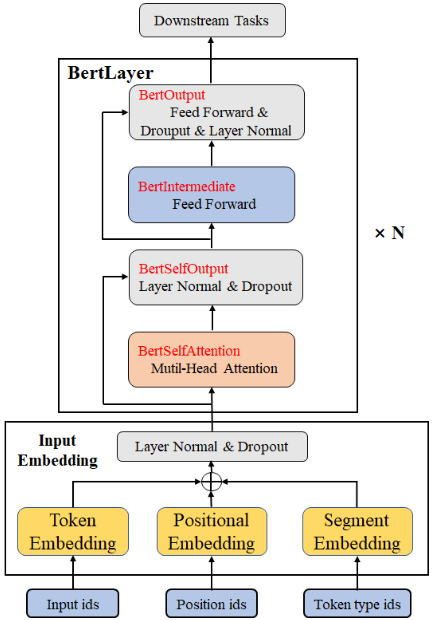
自然语言处理(Natural Language Processing,NLP )是能够实现人与计算机之间用自然语言进行有效沟通的理论和方法,是计算机科学领域与人工智能领域中的一个重要方向。本次采用经典的Bert模型完成问题回答任务,模型和分词文件下载链接:https://pan.baidu.com/s/1yc30IzM4ocOpTpfFuUMR0w, 提取码:8f1a, 将bertsquad-10.onnx文件和uncased_L-12_H-768_A-12分词文件保存在Resource/Models/NLP/Bert文件夹下。整体模型结构如下图所示,也可以通过netron工具:https://netron.app/ 查看Bert模型结构。
 问题回答任务是指输入一段上下文文本的描述和一个问题,模型从上下文文本中预测出答案。例如:
```
1.描述:My name is Li Ming
2.问题:What's your name?
3.答案:Li Ming
```
## 数据准备
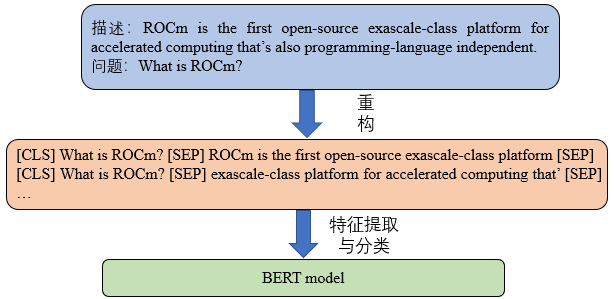
本示例采用json文件保存文本数据,如下图所示,包含问题(question)和上下文文本(context),自己可以根据需求准备对应的问题和上下文文本作为输入数据,进行模型推理。
```json
{
"data": [
{
"paragraphs": [
{
"context": "ROCm is the first open-source exascale-class platform for accelerated computing that’s also programming-language independent. It brings a philosophy of choice, minimalism and modular software development to GPU computing. You are free to choose or even develop tools and a language run time for your application. ROCm is built for scale, it supports multi-GPU computing and has a rich system run time with the critical features that large-scale application, compiler and language-run-time development requires. Since the ROCm ecosystem is comprised of open technologies: frameworks (Tensorflow / PyTorch), libraries (MIOpen / Blas / RCCL), programming model (HIP), inter-connect (OCD) and up streamed Linux® Kernel support – the platform is continually optimized for performance and extensibility.",
"qas": [
{
"question": "What is ROCm?",
"id": "1"
},
{
"question": "Which frameworks does ROCm support?",
"id": "2"
},
{
"question": "What is ROCm built for?",
"id": "3"
}
]
}
],
"title": "AMD ROCm"
}
]
}
```
## 预处理
将文本数据输入到模型之前,需要对数据做如下预处理:
1.读取json文件,并整合文本数据存储到列表中
2.数据重构,将问题和上下文文本拼接成一个序列,作为输入数据
### 读取json文件
读取json文件中的相应内容,首先处理上下文文本(context)内容,采用for循环将上下文文本(字符串)变为一个个词向量,存储在doc_tokens列表中。其次,获取问题文本(question)内容和对应的id。最后,将上下文文本和原始问题文本等保存在SquadEexample列表中,用于后续的数据重构。
```python
# 将SQuAD json文件内容读入到SquadEexample列表中
def read_squad_examples(input_file):
with open(input_file, "r") as f:
input_data = json.load(f)["data"]
examples = []
for idx, entry in enumerate(input_data):
for paragraph in entry["paragraphs"]:
# 获取上下文文本内容,并存储在doc_tokens列表中
paragraph_text = paragraph["context"]
doc_tokens = []
prev_is_whitespace = True
# 将上下文文本内容(字符串),变为一个个词向量存储在doc_tokens列表中
for c in paragraph_text:
if is_whitespace(c): # 当c为空格时,返回为True,否则为False
prev_is_whitespace = True
else:
if prev_is_whitespace: # 将当前字符添加到列表末尾
doc_tokens.append(c)
else:
doc_tokens[-1] += c # 将当前字符与doc_tokens列表中的最后一个字符相加,存储在该位置中
prev_is_whitespace = False
# 获取问题文本和对应的id
for qa in paragraph["qas"]:
qas_id = qa["id"]
question_text = qa["question"]
start_position = None
end_position = None
orig_answer_text = None
# 将上下文文本和原始问题文本等保存在SquadExample列表中
example = SquadExample(qas_id=qas_id,
question_text=question_text,
doc_tokens=doc_tokens,
orig_answer_text=orig_answer_text,
start_position=start_position,
end_position=end_position)
examples.append(example)
return examples
```
### 数据重构
读取json文件中的文本之后,就需要对数据进行重构,将问题和上下文文本拼接成一个序列,输入到模型中执行推理。数据重构主要包含两个步骤:
1.滑动窗口操作,如下图所示,当问题加上下文文本超过256个字符时,采取滑动窗口的方法构建输入序列。
问题回答任务是指输入一段上下文文本的描述和一个问题,模型从上下文文本中预测出答案。例如:
```
1.描述:My name is Li Ming
2.问题:What's your name?
3.答案:Li Ming
```
## 数据准备
本示例采用json文件保存文本数据,如下图所示,包含问题(question)和上下文文本(context),自己可以根据需求准备对应的问题和上下文文本作为输入数据,进行模型推理。
```json
{
"data": [
{
"paragraphs": [
{
"context": "ROCm is the first open-source exascale-class platform for accelerated computing that’s also programming-language independent. It brings a philosophy of choice, minimalism and modular software development to GPU computing. You are free to choose or even develop tools and a language run time for your application. ROCm is built for scale, it supports multi-GPU computing and has a rich system run time with the critical features that large-scale application, compiler and language-run-time development requires. Since the ROCm ecosystem is comprised of open technologies: frameworks (Tensorflow / PyTorch), libraries (MIOpen / Blas / RCCL), programming model (HIP), inter-connect (OCD) and up streamed Linux® Kernel support – the platform is continually optimized for performance and extensibility.",
"qas": [
{
"question": "What is ROCm?",
"id": "1"
},
{
"question": "Which frameworks does ROCm support?",
"id": "2"
},
{
"question": "What is ROCm built for?",
"id": "3"
}
]
}
],
"title": "AMD ROCm"
}
]
}
```
## 预处理
将文本数据输入到模型之前,需要对数据做如下预处理:
1.读取json文件,并整合文本数据存储到列表中
2.数据重构,将问题和上下文文本拼接成一个序列,作为输入数据
### 读取json文件
读取json文件中的相应内容,首先处理上下文文本(context)内容,采用for循环将上下文文本(字符串)变为一个个词向量,存储在doc_tokens列表中。其次,获取问题文本(question)内容和对应的id。最后,将上下文文本和原始问题文本等保存在SquadEexample列表中,用于后续的数据重构。
```python
# 将SQuAD json文件内容读入到SquadEexample列表中
def read_squad_examples(input_file):
with open(input_file, "r") as f:
input_data = json.load(f)["data"]
examples = []
for idx, entry in enumerate(input_data):
for paragraph in entry["paragraphs"]:
# 获取上下文文本内容,并存储在doc_tokens列表中
paragraph_text = paragraph["context"]
doc_tokens = []
prev_is_whitespace = True
# 将上下文文本内容(字符串),变为一个个词向量存储在doc_tokens列表中
for c in paragraph_text:
if is_whitespace(c): # 当c为空格时,返回为True,否则为False
prev_is_whitespace = True
else:
if prev_is_whitespace: # 将当前字符添加到列表末尾
doc_tokens.append(c)
else:
doc_tokens[-1] += c # 将当前字符与doc_tokens列表中的最后一个字符相加,存储在该位置中
prev_is_whitespace = False
# 获取问题文本和对应的id
for qa in paragraph["qas"]:
qas_id = qa["id"]
question_text = qa["question"]
start_position = None
end_position = None
orig_answer_text = None
# 将上下文文本和原始问题文本等保存在SquadExample列表中
example = SquadExample(qas_id=qas_id,
question_text=question_text,
doc_tokens=doc_tokens,
orig_answer_text=orig_answer_text,
start_position=start_position,
end_position=end_position)
examples.append(example)
return examples
```
### 数据重构
读取json文件中的文本之后,就需要对数据进行重构,将问题和上下文文本拼接成一个序列,输入到模型中执行推理。数据重构主要包含两个步骤:
1.滑动窗口操作,如下图所示,当问题加上下文文本超过256个字符时,采取滑动窗口的方法构建输入序列。
 从图中可以看出,问题部分不参与滑动处理,只将上下文文本进行滑动窗口操作,裁切得到多个子文本,用于后续的数据拼接。
具体实现如下,首先通过while循环判断子文本的起始位置是否位于上下文文本中,其次,在循环体中使用start_offset变量确定子文本的起始位置,length变量确定子文本的长度,都存储在doc_spans列表中。因此,通过存储的起始位置和对应的长度,就可以获得对应的子文本。
```Python
def convert_examples_to_features(examples, tokenizer, max_seq_length,doc_stride, max_query_length):
...
# 当上下文文本的长度大于规定的最大长度,采用滑动窗口的方法。
doc_spans = []
start_offset = 0
while start_offset < len(all_doc_tokens):
length = len(all_doc_tokens) - start_offset # 确定在当前窗口下,确定剩余上下文文本的长度
if length > max_tokens_for_doc:
length = max_tokens_for_doc
doc_spans.append(_DocSpan(start=start_offset, length=length)) # 存储开始索引和文本长度
if start_offset + length == len(all_doc_tokens): # 如果相等,则停止滑动窗口操作,结束循环
break
start_offset += min(length, doc_stride) # 确定开始索引位置,进行下一次滑动窗口
...
```
2.数据拼接,将获得的问题和上下文文本(子文本)拼接成一个序列,原理如下图所示:
从图中可以看出,问题部分不参与滑动处理,只将上下文文本进行滑动窗口操作,裁切得到多个子文本,用于后续的数据拼接。
具体实现如下,首先通过while循环判断子文本的起始位置是否位于上下文文本中,其次,在循环体中使用start_offset变量确定子文本的起始位置,length变量确定子文本的长度,都存储在doc_spans列表中。因此,通过存储的起始位置和对应的长度,就可以获得对应的子文本。
```Python
def convert_examples_to_features(examples, tokenizer, max_seq_length,doc_stride, max_query_length):
...
# 当上下文文本的长度大于规定的最大长度,采用滑动窗口的方法。
doc_spans = []
start_offset = 0
while start_offset < len(all_doc_tokens):
length = len(all_doc_tokens) - start_offset # 确定在当前窗口下,确定剩余上下文文本的长度
if length > max_tokens_for_doc:
length = max_tokens_for_doc
doc_spans.append(_DocSpan(start=start_offset, length=length)) # 存储开始索引和文本长度
if start_offset + length == len(all_doc_tokens): # 如果相等,则停止滑动窗口操作,结束循环
break
start_offset += min(length, doc_stride) # 确定开始索引位置,进行下一次滑动窗口
...
```
2.数据拼接,将获得的问题和上下文文本(子文本)拼接成一个序列,原理如下图所示:
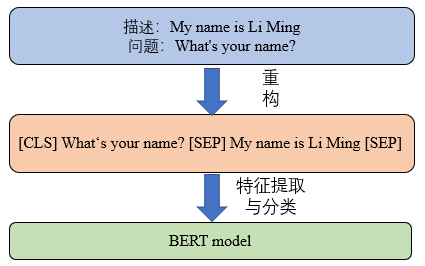 从图中可以看出,构建的方法是将问题和上下文文本拼接成一个序列,开头用[CLS]表示后面对应的问题,中间和最后用[SEP]符号隔开。其中,“[CLS]”是一个分类标志,表示后面的内容属于问题文本,“[SEP]”字符是一个分割标志,用来将问题和上下文文本分开。
```Python
def convert_examples_to_features(examples, tokenizer, max_seq_length,doc_stride, max_query_length):
...
# 拼接问题和上下文文本
for (doc_span_index, doc_span) in enumerate(doc_spans):
...
tokens.append("[CLS]") # 对tokens列表,开头添加[CLS]标志符
segment_ids.append(0)
for token in query_tokens.tokens:
tokens.append(token) # 对tokens列表,添加问题文本的分词
segment_ids.append(0)
tokens.append("[SEP]") # 对tokens列表,添加[SEP]标志符
segment_ids.append(0)
for i in range(doc_span.length):
split_token_index = doc_span.start + i
token_to_orig_map[len(tokens)] = tok_to_orig_index[split_token_index]
tokens.append(all_doc_tokens[split_token_index]) # 对tokens列表,添加上下文文本的分词
segment_ids.append(1)
tokens.append("[SEP]") # 在上下文文本的后端添加标志符[SEP]
segment_ids.append(1)
for token in tokens:
input_ids.append(tokenizer.token_to_id(token)) # 将拼接好的文本数据转换为数值型数据
...
```
## 推理
完成数据预处理后,就可以执行推理,得到推理结果。
```python
for idx in range(0, n):
item = eval_examples[idx]
print(item)
# 推理
result = model.run({
"unique_ids_raw_output___9:0":
np.array([item.qas_id], dtype=np.int64), # position id
"input_ids:0":
input_ids[idx:idx + bs], # Token id,对应的文本数据转换为数值型数据
"input_mask:0":
input_mask[idx:idx + bs], # mask id,对应的掩码信息
"segment_ids:0":
segment_ids[idx:idx + bs] # segment id,对上下文文本和问题赋予不同的位置信息
})
in_batch = result[1].get_shape().lens()[0]
start_logits = [float(x) for x in result[1].tolist()] # 答案开始位置的概率值
end_logits = [float(x) for x in result[0].tolist()] # 答案结束位置的概率值
for i in range(0, in_batch):
unique_id = len(all_results)
all_results.append(RawResult(unique_id=unique_id, start_logits=start_logits, end_logits=end_logits))
```
1.通过数据预处理操作后,获得了输入数据,分别为position id、Token id(文本信息)、segment id(区分问题和上下文文本)以及mask id(掩码信息,用于区分真实关注的位置),输入到model.run({...})中执行推理,得到模型的推理结果。推理结果主要包含了对答案开始位置和结束位置的预测概率值,都保存在all_results[]数组中,用于后续的数据后处理。
## 数据后处理
获得推理结果后,并不能直接作为问题回答任务的结果显示,如下图所示,还需要进一步数据处理,得到最终的预测结果。
从图中可以看出,构建的方法是将问题和上下文文本拼接成一个序列,开头用[CLS]表示后面对应的问题,中间和最后用[SEP]符号隔开。其中,“[CLS]”是一个分类标志,表示后面的内容属于问题文本,“[SEP]”字符是一个分割标志,用来将问题和上下文文本分开。
```Python
def convert_examples_to_features(examples, tokenizer, max_seq_length,doc_stride, max_query_length):
...
# 拼接问题和上下文文本
for (doc_span_index, doc_span) in enumerate(doc_spans):
...
tokens.append("[CLS]") # 对tokens列表,开头添加[CLS]标志符
segment_ids.append(0)
for token in query_tokens.tokens:
tokens.append(token) # 对tokens列表,添加问题文本的分词
segment_ids.append(0)
tokens.append("[SEP]") # 对tokens列表,添加[SEP]标志符
segment_ids.append(0)
for i in range(doc_span.length):
split_token_index = doc_span.start + i
token_to_orig_map[len(tokens)] = tok_to_orig_index[split_token_index]
tokens.append(all_doc_tokens[split_token_index]) # 对tokens列表,添加上下文文本的分词
segment_ids.append(1)
tokens.append("[SEP]") # 在上下文文本的后端添加标志符[SEP]
segment_ids.append(1)
for token in tokens:
input_ids.append(tokenizer.token_to_id(token)) # 将拼接好的文本数据转换为数值型数据
...
```
## 推理
完成数据预处理后,就可以执行推理,得到推理结果。
```python
for idx in range(0, n):
item = eval_examples[idx]
print(item)
# 推理
result = model.run({
"unique_ids_raw_output___9:0":
np.array([item.qas_id], dtype=np.int64), # position id
"input_ids:0":
input_ids[idx:idx + bs], # Token id,对应的文本数据转换为数值型数据
"input_mask:0":
input_mask[idx:idx + bs], # mask id,对应的掩码信息
"segment_ids:0":
segment_ids[idx:idx + bs] # segment id,对上下文文本和问题赋予不同的位置信息
})
in_batch = result[1].get_shape().lens()[0]
start_logits = [float(x) for x in result[1].tolist()] # 答案开始位置的概率值
end_logits = [float(x) for x in result[0].tolist()] # 答案结束位置的概率值
for i in range(0, in_batch):
unique_id = len(all_results)
all_results.append(RawResult(unique_id=unique_id, start_logits=start_logits, end_logits=end_logits))
```
1.通过数据预处理操作后,获得了输入数据,分别为position id、Token id(文本信息)、segment id(区分问题和上下文文本)以及mask id(掩码信息,用于区分真实关注的位置),输入到model.run({...})中执行推理,得到模型的推理结果。推理结果主要包含了对答案开始位置和结束位置的预测概率值,都保存在all_results[]数组中,用于后续的数据后处理。
## 数据后处理
获得推理结果后,并不能直接作为问题回答任务的结果显示,如下图所示,还需要进一步数据处理,得到最终的预测结果。
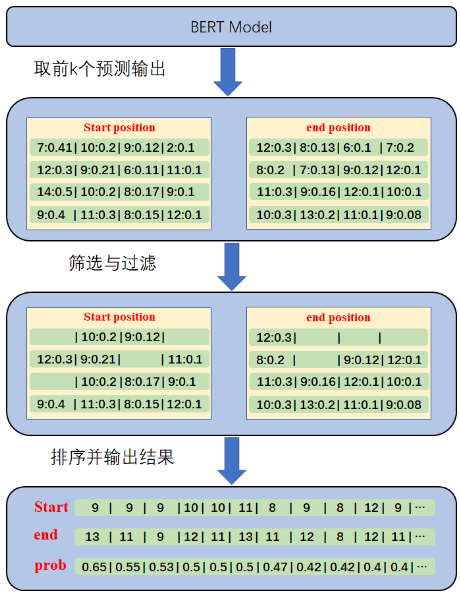 从图中可以看出,数据后处理主要包含如下操作:
1.获取预测输出,根据模型推理结果,取前K个概率值最大的开始位置和结束位置。
2.筛选与过滤,根据过滤规则筛选开始位置和结束位置。
3.排序并输出结果,对开始位置加结束位置的概率值和进行排序,取概率值最大的组合作为最终的预测结果。
过滤规则:
1.开始位置和结束位置不能大于输入序列的长度。
2.开始位置和结束位置必须位于上下文文本中。
3.开始位置必须位于结束位置前。
本示例数据后处理代码,详见Python/NLP/Bert/run_onnx_squad.py脚本中的write_predictions()函数。
从图中可以看出,数据后处理主要包含如下操作:
1.获取预测输出,根据模型推理结果,取前K个概率值最大的开始位置和结束位置。
2.筛选与过滤,根据过滤规则筛选开始位置和结束位置。
3.排序并输出结果,对开始位置加结束位置的概率值和进行排序,取概率值最大的组合作为最终的预测结果。
过滤规则:
1.开始位置和结束位置不能大于输入序列的长度。
2.开始位置和结束位置必须位于上下文文本中。
3.开始位置必须位于结束位置前。
本示例数据后处理代码,详见Python/NLP/Bert/run_onnx_squad.py脚本中的write_predictions()函数。