# Bert
本示例主要通过Bert模型说明如何使用MIGraphX C++ API进行自然语言处理模型的推理,包括数据准备、预处理、模型推理以及数据后处理。
## 模型简介
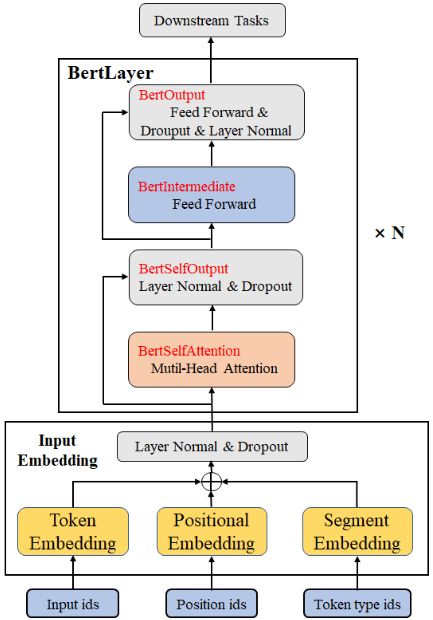
自然语言处理(Natural Language Processing,NLP )是能够实现人与计算机之间用自然语言进行有效沟通的理论和方法,是计算机科学领域与人工智能领域中的一个重要方向。本次采用经典的Bert模型完成问题回答任务,模型和分词文件下载链接:https://pan.baidu.com/s/1yc30IzM4ocOpTpfFuUMR0w, 提取码:8f1a, 下载bertsquad-10.onnx文件和uncased_L-12_H-768_A-12分词文件保存在Resource/文件夹下。整体模型结构如下图所示,也可以通过netron工具:https://netron.app/ 查看Bert模型结构。
 问题回答任务是指输入一段上下文文本的描述和一个问题,模型从给定的文本中预测出答案。例如:
```
1.描述:My name is Li Ming
2.问题:What's your name?
3.答案:Li Ming
```
## 数据准备
在自然语言处理领域中,首先需要准备文本数据,如下所示,通常需要提供问题(question)和上下文文本(context),自己可以根据需求准备相应的问题和上下文文本作为输入数据,进行模型推理。
```json
{
"context": "ROCm is the first open-source exascale-class platform for accelerated computing that’s also programming-language independent. It brings a philosophy of choice, minimalism and modular software development to GPU computing. You are free to choose or even develop tools and a language run time for your application. ROCm is built for scale, it supports multi-GPU computing and has a rich system run time with the critical features that large-scale application, compiler and language-run-time development requires. Since the ROCm ecosystem is comprised of open technologies: frameworks (Tensorflow / PyTorch), libraries (MIOpen / Blas / RCCL), programming model (HIP), inter-connect (OCD) and up streamed Linux® Kernel support – the platform is continually optimized for performance and extensibility.",
"question": "What is ROCm?"
}
```
## 预处理
提供的问题和上下文文本并不能直接输入到模型中执行推理,需要对数据做如下预处理:
1.滑动窗口操作,当问题和上下文文本的字符超过256时,执行该操作,否则不执行。
2.数据拼接,将原始问题和上下文文本拼接成一个序列,作为模型的输入数据。
### 滑动窗口操作
对于问题回答型任务,关键的是如何构建输入数据。通过对上下文文本和问题的长度做判断,如果上下文文本加问题不超过256个字符时,直接进行后续的数据拼接操作,否则先进行滑动窗口操作构建输入序列,再进行后续的数据拼接。
如下图所示,为滑动窗口的具体操作:
问题回答任务是指输入一段上下文文本的描述和一个问题,模型从给定的文本中预测出答案。例如:
```
1.描述:My name is Li Ming
2.问题:What's your name?
3.答案:Li Ming
```
## 数据准备
在自然语言处理领域中,首先需要准备文本数据,如下所示,通常需要提供问题(question)和上下文文本(context),自己可以根据需求准备相应的问题和上下文文本作为输入数据,进行模型推理。
```json
{
"context": "ROCm is the first open-source exascale-class platform for accelerated computing that’s also programming-language independent. It brings a philosophy of choice, minimalism and modular software development to GPU computing. You are free to choose or even develop tools and a language run time for your application. ROCm is built for scale, it supports multi-GPU computing and has a rich system run time with the critical features that large-scale application, compiler and language-run-time development requires. Since the ROCm ecosystem is comprised of open technologies: frameworks (Tensorflow / PyTorch), libraries (MIOpen / Blas / RCCL), programming model (HIP), inter-connect (OCD) and up streamed Linux® Kernel support – the platform is continually optimized for performance and extensibility.",
"question": "What is ROCm?"
}
```
## 预处理
提供的问题和上下文文本并不能直接输入到模型中执行推理,需要对数据做如下预处理:
1.滑动窗口操作,当问题和上下文文本的字符超过256时,执行该操作,否则不执行。
2.数据拼接,将原始问题和上下文文本拼接成一个序列,作为模型的输入数据。
### 滑动窗口操作
对于问题回答型任务,关键的是如何构建输入数据。通过对上下文文本和问题的长度做判断,如果上下文文本加问题不超过256个字符时,直接进行后续的数据拼接操作,否则先进行滑动窗口操作构建输入序列,再进行后续的数据拼接。
如下图所示,为滑动窗口的具体操作:
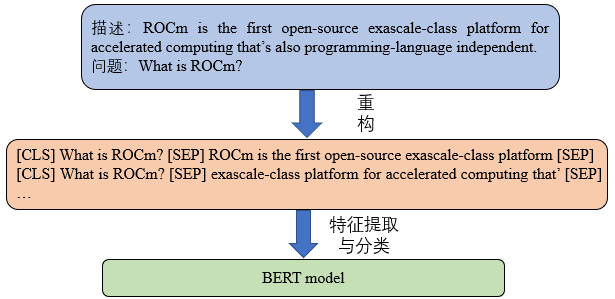 从图中可以看出,通过指定窗口大小为256,进行滑动窗口处理可以将上下文文本分成多个子文本,用于后续的数据拼接。
具体滑动窗口的过程由如下代码实现:
```c++
ErrorCode Bert::Preprocessing(...)
{
...
// 当上下文文本加问题文本的长度大于规定的最大长度,采用滑动窗口操作
if(tokens_text.size() + tokens_question.size() > max_seq_length - 5)
{
int windows_len = max_seq_length - 5 -tokens_question.size();
std::vector tokens_text_window(windows_len);
std::vector> tokens_text_windows;
// 规定起始位置,通过滑动窗口操作将子文本存储在tokens_text_window中
int start_offset = 0;
int position = 0;
int n;
while (start_offset < tokens_text.size())
{
n = 0;
if(start_offset + windows_len > tokens_text.size())
{
for(int i = start_offset; i < tokens_text.size(); ++i)
{
tokens_text_window[n] = tokens_text[i];
++n;
}
}
else
{
for(int i = start_offset; i < start_offset + windows_len; ++i)
{
tokens_text_window[n] = tokens_text[i];
++n;
}
}
tokens_text_windows.push_back(tokens_text_window);
start_offset += 256;
++position;
}
}
...
}
```
### 数据拼接
当获得指定的问题和上下文文本时,对问题和上下文文本进行拼接操作,具体过程如下图所示:
从图中可以看出,通过指定窗口大小为256,进行滑动窗口处理可以将上下文文本分成多个子文本,用于后续的数据拼接。
具体滑动窗口的过程由如下代码实现:
```c++
ErrorCode Bert::Preprocessing(...)
{
...
// 当上下文文本加问题文本的长度大于规定的最大长度,采用滑动窗口操作
if(tokens_text.size() + tokens_question.size() > max_seq_length - 5)
{
int windows_len = max_seq_length - 5 -tokens_question.size();
std::vector tokens_text_window(windows_len);
std::vector> tokens_text_windows;
// 规定起始位置,通过滑动窗口操作将子文本存储在tokens_text_window中
int start_offset = 0;
int position = 0;
int n;
while (start_offset < tokens_text.size())
{
n = 0;
if(start_offset + windows_len > tokens_text.size())
{
for(int i = start_offset; i < tokens_text.size(); ++i)
{
tokens_text_window[n] = tokens_text[i];
++n;
}
}
else
{
for(int i = start_offset; i < start_offset + windows_len; ++i)
{
tokens_text_window[n] = tokens_text[i];
++n;
}
}
tokens_text_windows.push_back(tokens_text_window);
start_offset += 256;
++position;
}
}
...
}
```
### 数据拼接
当获得指定的问题和上下文文本时,对问题和上下文文本进行拼接操作,具体过程如下图所示:
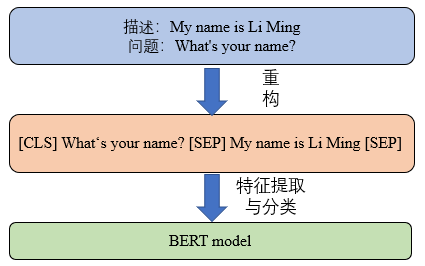 从图中可以看出,是将问题和上下文文本拼接成一个序列,问题和上下文文本用[SEP]符号隔开,完成数据拼接后再输入到模型中进行特征提取。其中,“[CLS]”是一个分类标志,表示后面的内容属于问题文本,“[SEP]”字符是一个分割标志,用来将问题和上下文文本分开。
具体过程由如下代码实现:
```c++
ErrorCode Bert::Preprocessing(...)
{
...
for(int i=0; i < position; ++i)
{
// 将问题和上下文文本进行拼接处理
input_id[0] = tokenizer.convert_token_to_id("[CLS]");
segment_id[0] = 0;
input_id[1] = tokenizer.convert_token_to_id("[CLS]");
segment_id[1] = 0;
for (int j = 0; j < tokens_question.size(); ++j)
{
input_id[j + 2] = tokenizer.convert_token_to_id(tokens_question[j]);
segment_id[j + 2] = 0;
}
input_id[tokens_question.size() + 2] = tokenizer.convert_token_to_id("[SEP]");
segment_id[tokens_question.size() + 2] = 0;
input_id[tokens_question.size() + 3] = tokenizer.convert_token_to_id("[SEP]");
segment_id[tokens_question.size() + 3] = 0;
for (int j = 0; j < tokens_question.size(); ++j)
{
input_id[j + tokens_text_windows[i].size() + 4] = tokenizer.convert_token_to_id(tokens_text_windows[i][j]);
segment_id[j + tokens_text_windows[i].size() + 4] = 1;
}
input_id[tokens_question.size() + tokens_text_windows[i].size() + 4] = tokenizer.convert_token_to_id("[SEP]");
segment_id[tokens_question.size() + tokens_text_windows[i].size() + 4] = 1;
int len = tokens_text_windows[i].size() + tokens_question.size() + 5;
// 掩码为1的表示为真实标记,0表示为填充标记。
std::fill(input_mask.begin(), input_mask.begin() + len, 1);
std::fill(input_mask.begin() + len, input_mask.begin() + max_seq_length, 0);
std::fill(input_id.begin() + len, input_id.begin() + max_seq_length, 0);
std::fill(segment_id.begin() + len, segment_id.begin() + max_seq_length, 0);
}
...
}
```
在自然语言处理领域中,不能对文本数据直接处理,需要对文本进行编码后再输入到模型中。因此,Bert模型中的输入数据主要由input_id、segment_id以及input_mask组成,其中input_id主要存储了对文本进行编码后的数值型数据,segment_id主要存储了用于区问题和上下文文本的信息(问题标记为0,上下文文本标记为1),input_mask主要存储了掩码信息(序列长度固定为256,当文本长度不足256时,对应的文本标记为1,无文本的标记为0),标记模型需要关注的地方。
## 推理
完成数据预处理后,就可以执行推理,得到推理结果。
```c++
ErrorCode Bert::Inference(...)
{
...
for(int i=0;i outputNames = {"unstack:0","unique_ids:0","unstack:1"};
std::vector results = net.eval(inputData, outputNames);
...
```
如果没有指定outputName参数,则默认输出所有输出节点,此时输出节点的顺序与ONNX中输出节点顺序保持一致,可以通过netron查看ONNX文件的输出节点的顺序。
## 数据后处理
获得模型的推理结果后,并不能直接作为问题回答任务的结果显示,如下图所示,还需要进一步数据处理,得到最终的预测结果。
从图中可以看出,是将问题和上下文文本拼接成一个序列,问题和上下文文本用[SEP]符号隔开,完成数据拼接后再输入到模型中进行特征提取。其中,“[CLS]”是一个分类标志,表示后面的内容属于问题文本,“[SEP]”字符是一个分割标志,用来将问题和上下文文本分开。
具体过程由如下代码实现:
```c++
ErrorCode Bert::Preprocessing(...)
{
...
for(int i=0; i < position; ++i)
{
// 将问题和上下文文本进行拼接处理
input_id[0] = tokenizer.convert_token_to_id("[CLS]");
segment_id[0] = 0;
input_id[1] = tokenizer.convert_token_to_id("[CLS]");
segment_id[1] = 0;
for (int j = 0; j < tokens_question.size(); ++j)
{
input_id[j + 2] = tokenizer.convert_token_to_id(tokens_question[j]);
segment_id[j + 2] = 0;
}
input_id[tokens_question.size() + 2] = tokenizer.convert_token_to_id("[SEP]");
segment_id[tokens_question.size() + 2] = 0;
input_id[tokens_question.size() + 3] = tokenizer.convert_token_to_id("[SEP]");
segment_id[tokens_question.size() + 3] = 0;
for (int j = 0; j < tokens_question.size(); ++j)
{
input_id[j + tokens_text_windows[i].size() + 4] = tokenizer.convert_token_to_id(tokens_text_windows[i][j]);
segment_id[j + tokens_text_windows[i].size() + 4] = 1;
}
input_id[tokens_question.size() + tokens_text_windows[i].size() + 4] = tokenizer.convert_token_to_id("[SEP]");
segment_id[tokens_question.size() + tokens_text_windows[i].size() + 4] = 1;
int len = tokens_text_windows[i].size() + tokens_question.size() + 5;
// 掩码为1的表示为真实标记,0表示为填充标记。
std::fill(input_mask.begin(), input_mask.begin() + len, 1);
std::fill(input_mask.begin() + len, input_mask.begin() + max_seq_length, 0);
std::fill(input_id.begin() + len, input_id.begin() + max_seq_length, 0);
std::fill(segment_id.begin() + len, segment_id.begin() + max_seq_length, 0);
}
...
}
```
在自然语言处理领域中,不能对文本数据直接处理,需要对文本进行编码后再输入到模型中。因此,Bert模型中的输入数据主要由input_id、segment_id以及input_mask组成,其中input_id主要存储了对文本进行编码后的数值型数据,segment_id主要存储了用于区问题和上下文文本的信息(问题标记为0,上下文文本标记为1),input_mask主要存储了掩码信息(序列长度固定为256,当文本长度不足256时,对应的文本标记为1,无文本的标记为0),标记模型需要关注的地方。
## 推理
完成数据预处理后,就可以执行推理,得到推理结果。
```c++
ErrorCode Bert::Inference(...)
{
...
for(int i=0;i outputNames = {"unstack:0","unique_ids:0","unstack:1"};
std::vector results = net.eval(inputData, outputNames);
...
```
如果没有指定outputName参数,则默认输出所有输出节点,此时输出节点的顺序与ONNX中输出节点顺序保持一致,可以通过netron查看ONNX文件的输出节点的顺序。
## 数据后处理
获得模型的推理结果后,并不能直接作为问题回答任务的结果显示,如下图所示,还需要进一步数据处理,得到最终的预测结果。
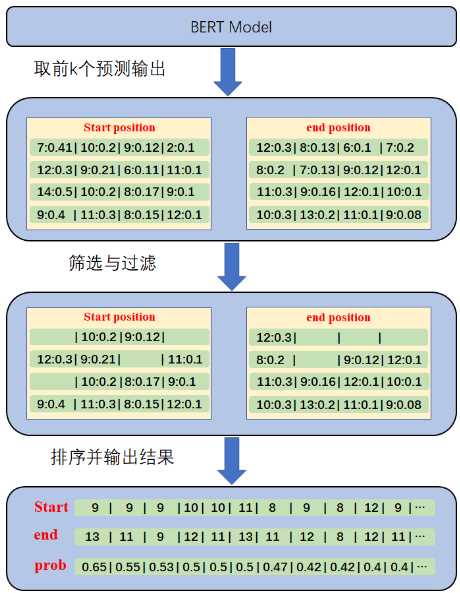 从图中可以看出,数据后处理主要包含如下操作:
1.获取预测输出,根据模型推理结果,取前K个概率值最大的开始位置和结束位置。
2.筛选与过滤,根据过滤规则筛选开始位置和结束位置。
3.排序并输出结果,对开始位置加结束位置的概率值和进行排序,取概率值最大的组合作为最终的预测结果。
过滤规则:
1.开始位置和结束位置不能大于输入序列的长度。
2.开始位置和结束位置必须位于上下文文本中。
3.开始位置必须位于结束位置前。
本示例数据后处理代码,详见Src/NLP/Bert/Bert.cpp脚本中的Postprocessing()函数。
从图中可以看出,数据后处理主要包含如下操作:
1.获取预测输出,根据模型推理结果,取前K个概率值最大的开始位置和结束位置。
2.筛选与过滤,根据过滤规则筛选开始位置和结束位置。
3.排序并输出结果,对开始位置加结束位置的概率值和进行排序,取概率值最大的组合作为最终的预测结果。
过滤规则:
1.开始位置和结束位置不能大于输入序列的长度。
2.开始位置和结束位置必须位于上下文文本中。
3.开始位置必须位于结束位置前。
本示例数据后处理代码,详见Src/NLP/Bert/Bert.cpp脚本中的Postprocessing()函数。