# bert-large
## 论文
`BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding`
- [https://arxiv.org/abs/1810.04805](https://arxiv.org/abs/1810.04805)
## 模型结构
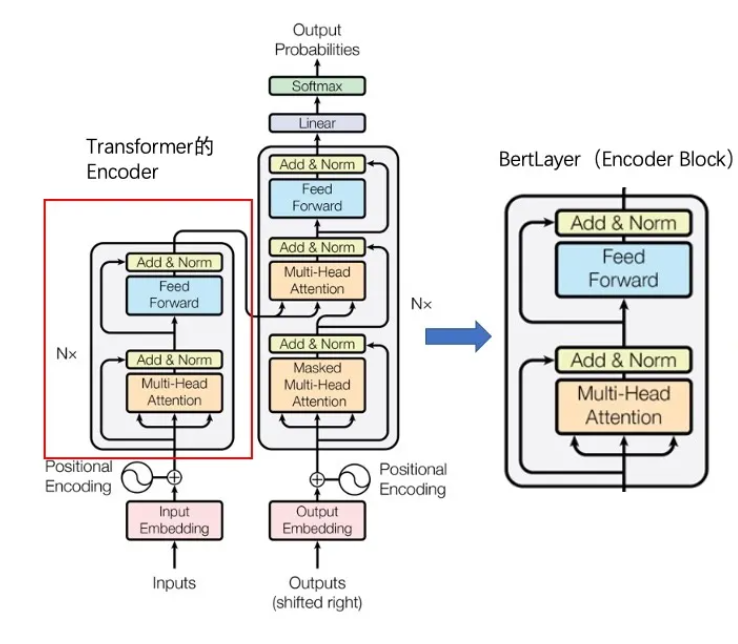 我们为了用户可以使用OneFlow-Libai快速验证Bert模型预训练,统计性能或验证精度,提供了一个Bert网络示例,主要网络参数如下:
```
model.cfg.num_attention_heads = 16
model.cfg.hidden_size = 768
model.cfg.hidden_layers = 8
```
完整的Bert-Large网络配置在configs/common/model/bert.py中
## 算法原理
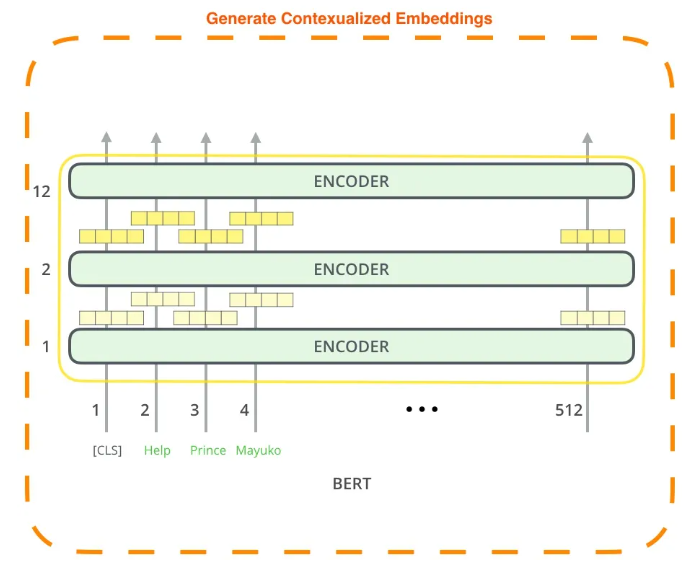
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的**masked language model(MLM)**,以致能生成**深度的双向**语言表征。以往的预训练模型的结构会受到单向语言模型(*从左到右或者从右到左*)的限制,因而也限制了模型的表征能力,使其只能获取单方向的上下文信息。而BERT利用MLM进行预训练并且采用深层的双向Transformer组件(*单向的Transformer一般被称为Transformer decoder,其每一个token(符号)只会attend到目前往左的token。而双向的Transformer则被称为Transformer encoder,其每一个token会attend到所有的token*)来构建整个模型,因此最终生成**能融合左右上下文信息**的深层双向语言表征。
我们为了用户可以使用OneFlow-Libai快速验证Bert模型预训练,统计性能或验证精度,提供了一个Bert网络示例,主要网络参数如下:
```
model.cfg.num_attention_heads = 16
model.cfg.hidden_size = 768
model.cfg.hidden_layers = 8
```
完整的Bert-Large网络配置在configs/common/model/bert.py中
## 算法原理
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的**masked language model(MLM)**,以致能生成**深度的双向**语言表征。以往的预训练模型的结构会受到单向语言模型(*从左到右或者从右到左*)的限制,因而也限制了模型的表征能力,使其只能获取单方向的上下文信息。而BERT利用MLM进行预训练并且采用深层的双向Transformer组件(*单向的Transformer一般被称为Transformer decoder,其每一个token(符号)只会attend到目前往左的token。而双向的Transformer则被称为Transformer encoder,其每一个token会attend到所有的token*)来构建整个模型,因此最终生成**能融合左右上下文信息**的深层双向语言表征。
 ## 环境配置
### Docker
```plaintext
docker pull image.sourcefind.cn:5000/dcu/admin/base/oneflow:0.9.1-centos7.6-dtk-22.10.1-py39-latest
# 用上面拉取docker镜像的ID替换
docker run --shm-size 16g --network=host --name=bert_oneflow --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v $PWD/bert-large_oneflow:/home/bert-large_oneflow -it bash
cd /home/bert-large_oneflow
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
pip3 install pybind11 -i https://mirrors.aliyun.com/pypi/simple
pip3 install -e . -i https://mirrors.aliyun.com/pypi/simple
```
## 数据集
我们在libai目录下集成了部分小数据集供用户快速验证,路径为:
$ tree nlp_data
├── data
├── bert-base-chinese-vocab
├── gpt2-merges
└── gpt2-vocab
训练数据:
- https://oneflow-static.oss-cn-beijing.aliyuncs.com/ci-files/dataset/libai/gpt_dataset/gpt2-merges.txt
- https://oneflow-static.oss-cn-beijing.aliyuncs.com/ci-files/dataset/libai/gpt_dataset/gpt2-vocab.json
## 训练
该预训练脚本运行环境为1节点,4张DCU-Z100-16G。
并行配置策略在configs/bert_large_pretrain.py中,使用自动混合精度:
```
train.amp.enabled = True
train.train_micro_batch_size = 16
train.dist.data_parallel_size = 4
train.dist.tensor_parallel_size = 1
train.dist.pipeline_parallel_size = 1
```
预训练命令:
cd home/bert-large_oneflow
bash tools/train.sh tools/train_net.py configs/bert_large_pretrain.py 4
## result
### 精度
使用的GPGPU:4张DCU-Z100-16G。
模型精度:
| 卡数 | 分布式工具 | 收敛性 |
| :--: | :--------: | :----------------------------------------------------------: |
| 4 | Libai-main | total_loss: 6.555 lm_loss: 5.973 sop_loss: 0.583/10000 iters |
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`医疗,教育,科研,金融`
## 源码仓库及问题反馈
* https://developer.sourcefind.cn/codes/modelzoo/bert-large_oneflow
## 参考
* https://libai.readthedocs.io/en/latest/tutorials/get_started/quick_run.html
* https://github.com/Oneflow-Inc/oneflow
* https://github.com/Oneflow-Inc/libai/blob/main/docs/source/notes/FAQ.md
## 环境配置
### Docker
```plaintext
docker pull image.sourcefind.cn:5000/dcu/admin/base/oneflow:0.9.1-centos7.6-dtk-22.10.1-py39-latest
# 用上面拉取docker镜像的ID替换
docker run --shm-size 16g --network=host --name=bert_oneflow --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v $PWD/bert-large_oneflow:/home/bert-large_oneflow -it bash
cd /home/bert-large_oneflow
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
pip3 install pybind11 -i https://mirrors.aliyun.com/pypi/simple
pip3 install -e . -i https://mirrors.aliyun.com/pypi/simple
```
## 数据集
我们在libai目录下集成了部分小数据集供用户快速验证,路径为:
$ tree nlp_data
├── data
├── bert-base-chinese-vocab
├── gpt2-merges
└── gpt2-vocab
训练数据:
- https://oneflow-static.oss-cn-beijing.aliyuncs.com/ci-files/dataset/libai/gpt_dataset/gpt2-merges.txt
- https://oneflow-static.oss-cn-beijing.aliyuncs.com/ci-files/dataset/libai/gpt_dataset/gpt2-vocab.json
## 训练
该预训练脚本运行环境为1节点,4张DCU-Z100-16G。
并行配置策略在configs/bert_large_pretrain.py中,使用自动混合精度:
```
train.amp.enabled = True
train.train_micro_batch_size = 16
train.dist.data_parallel_size = 4
train.dist.tensor_parallel_size = 1
train.dist.pipeline_parallel_size = 1
```
预训练命令:
cd home/bert-large_oneflow
bash tools/train.sh tools/train_net.py configs/bert_large_pretrain.py 4
## result
### 精度
使用的GPGPU:4张DCU-Z100-16G。
模型精度:
| 卡数 | 分布式工具 | 收敛性 |
| :--: | :--------: | :----------------------------------------------------------: |
| 4 | Libai-main | total_loss: 6.555 lm_loss: 5.973 sop_loss: 0.583/10000 iters |
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`医疗,教育,科研,金融`
## 源码仓库及问题反馈
* https://developer.sourcefind.cn/codes/modelzoo/bert-large_oneflow
## 参考
* https://libai.readthedocs.io/en/latest/tutorials/get_started/quick_run.html
* https://github.com/Oneflow-Inc/oneflow
* https://github.com/Oneflow-Inc/libai/blob/main/docs/source/notes/FAQ.md