# Qwen3
同时具备Distil+SFT+RL的方法开源,人工智能大厂所用的主流后训练方法所有人都可以轻松拥有。
## 论文
`无`
## 模型结构
Qwen3采用通用的Decoder-Only结构,引入了MoE提升性能,首个「混合推理模型」,通过标注标记词将「快思考」与「慢思考」集成进同一个模型,本步骤以Qwen3-4B作为示例,其它模型根据axolotl官方说明以此类推。
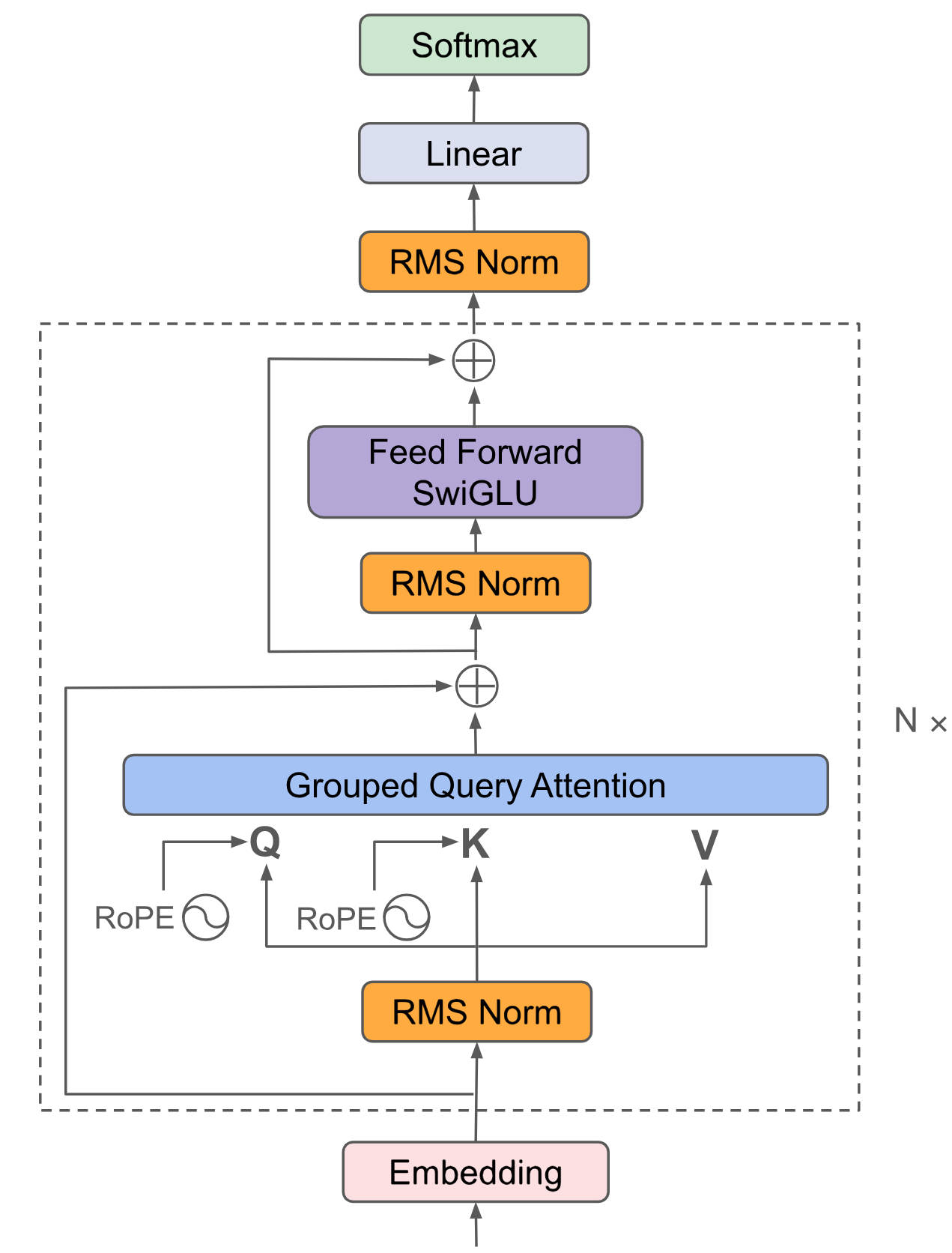
## 算法原理
将输入embedding后放入attention、ffn等提取特征,最后利用Softmax将解码器最后一层产生的未经归一化的分数向量(logits)转换为概率分布,其中每个元素表示生成对应词汇的概率,这使得模型可以生成一个分布,并从中选择最可能的词作为预测结果。
## 环境配置
```
mv axolotl-Qwen3-4B_pytorch axolotl # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:vllm0.8.5-ubuntu22.04-dtk25.04-rc7-das1.5-py3.10-20250521-fixpy-rocblas0521-beta2
# 为以上拉取的docker的镜像ID替换,本镜像为:1fad5f9ac556
docker run -it --shm-size=64G -v $PWD/axolotl:/home/axolotl -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name axo bash
cd /home/axolotl
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
pip install -e . -i https://mirrors.aliyun.com/pypi/simple
pip install whl/bitsandbytes-0.42.0+das.opt1.dtk2504-py3-none-any.whl
```
### Dockerfile(方法二)
```
cd /home/axolotl/docker
docker build --no-cache -t axo:latest .
docker run --shm-size=64G --name axo -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../axolotl:/home/axolotl -it axo bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
cd /home/axolotl
pip install -e . -i https://mirrors.aliyun.com/pypi/simple
pip install whl/bitsandbytes-0.42.0+das.opt1.dtk2504-py3-none-any.whl
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk2504
python:python3.10
torch:2.4.1
torchvision:0.19.1
triton:3.0.0
vllm:0.8.5
flash-attn:2.6.1
deepspeed:0.14.2
apex:1.4.0
bitsandbytes:0.42.0
transformers:4.51.3
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/axolotl
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
pip install -e . -i https://mirrors.aliyun.com/pypi/simple
pip install whl/bitsandbytes-0.42.0+das.opt1.dtk2504-py3-none-any.whl
```
## 数据集
```
/home/axolotl/
|── axolotl-ai-co/evolkit-logprobs-pipeline-75k-v2-sample
|── Rajesh1505/finance-alpaca-1k-test
|── tatsu-lab/alpaca
└── skrishna/gsm8k_only_answer
```
`axolotl-ai-co/evolkit-logprobs-pipeline-75k-v2-sample`下的完整目录为:`axolotl-ai-co/evolkit-logprobs-pipeline-75k-v2-sample/data/train.parquet`
HF下载地址为[axolotl-ai-co/evolkit-logprobs-pipeline-75k-v2-sample](https://huggingface.co/datasets/axolotl-ai-co/evolkit-logprobs-pipeline-75k-v2-sample),后几个示例数据集较小,项目中已内置。
## 训练
预训练权重目录结构:
```
/home/axolotl/
└── Qwen/Qwen3-4B
```
### 单机多卡
```
cd /home/axolotl/
export HF_ENDPOINT=https://hf-mirror.com # 解决报错:MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443)
## Distil
axolotl train examples/qwen3/qlora-fsdp-kd_qwen3-4b.yaml # 示例数据为作者利用第三方库distilabel离线推理获取logits数据
# 若报错OSError: [Errno 28] No space left on device则设置本地缓存目录:export HF_HOME=./cache
## SFT
axolotl train examples/qwen3/qlora-fsdp_qwen3-4b.yaml
## RL
# 环境bug解决
1、解决识别不到gsm8k_grpo模块的bug
export PYTHONPATH=/home/axolotl/axolotl-cookbook/grpo:$PYTHONPATH # 添加gsm8k_grpo.py文件所在目录的绝对或相对路径
2、解决grpo训练遇到vllm缺失current_count等属性bug
export LLAMA_NN=0
3、解决trl调研vllm推理不能多线程的bug
/usr/local/lib/python3.10/dist-packages/trl/scripts/vllm_serve.py, line 67
`RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method`
在"os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn""之后添加以下代码,即:
os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
import multiprocessing as mp
try:
mp.set_start_method('spawn', force=True)
except RuntimeError:
pass
# 训练
# 1、启动vllm推理,axolotl作者说trl的vllm需使用后两张卡以避免报错。
HIP_VISIBLE_DEVICES=2,3 axolotl vllm-serve examples/qwen3/rl_qwen3-4b.yaml
# 2、然后通过docker exec -it axo bash进入进行主目录,另起一个终端使用前两张卡运行训练代码,同一机器同一镜像内。
HIP_VISIBLE_DEVICES=0,1 axolotl train examples/qwen3/rl_qwen3-4b.yaml --num-processes 2 # 若报缓存空间不足可删除缓存:rm -rf /root/.cache/*
# 其它模型的.yaml文件编写方法以此类推,axolotl提供了目前最先进的GRPO、DAPO等强化学习方法。
# 注:强化学习显存占用较大,若batchsize较大,vllm推理和RL训练这两边都很容易因显存不足而挂掉。
```
备注:
1、项目中所有`vllm推理需要用到的ip: x.x.x.x`需要替换成读者机器的真实物理地址的ip才能正常进行推理。
2、以上Distil步骤中的数据采用官方数据进行训练方法示范,对于自己的数据如何通过distilabel离线推理获取logits,项目中已提供[`make_teacher_model_logits_kd`](./make_teacher_model_logits_kd.py)供参考研究,示例数据集`Rajesh1505`制作的Distil数据保存位置为`Rajesh1505/default.parquet`,制作完成后需要根据不同的数据集特点另外重命名保存才能正常读取,本数据的最终保存地址为[`Rajesh1505_logits`](./Rajesh1505/finance-alpaca-1k-train/data/train-00000-of-00001.parquet),读者的其它数据可根据本示例数据的制作方法自行研究以生成相应正确格式。
```
cd Rajesh1505 # 运行完make_teacher_model_logits_kd.py会生成default.parquet
cp default.parquet finance-alpaca-1k-train/data/train-00000-of-00001.parquet # 不同数据集的放在方法不同,此处需要读者根据相应的数据集特点灵活思考并放置。
```
运行`make_teacher_model_logits_kd.py`前需要另起一个vllm镜像专供运行vllm推理,以项目中的权重`Qwen/Qwen3-4B`示例(实际教师模型可自行采用更大参数量的其它模型自行研究制作):
```
vllm serve Qwen/Qwen3-4B --port 8000 --tensor-parallel-size 4
# vllm serve Qwen/Qwen3-4B --port 8000 --enable-reasoning --reasoning-parser deepseek_r1 --tensor-parallel-size 4
```
若运行`make_teacher_model_logits_kd.py`遇到卡住不动可删除缓存解决:
```
rm -rf /root/.cache/distilabel/pipelines/*
```
若希望深入研究蒸馏数据的制作方法可参考`make_teacher_model_logits_kd.py`顶部注释的参考文档说明。
3、对于vllm缺失current_count等属性bug的解决也可按如下方式解决:
```
# 首先:
"/usr/local/lib/python3.10/dist-packages/vllm/model_executor/models/qwen2.py", line 397, in load_weight
将load_weights函数内容替换成https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/qwen2.py中的load_weights函数内容,目前vllm==0.9.0。
# 然后:
"/usr/local/lib/python3.10/dist-packages/vllm/model_executor/layers/linear.py", line 220, in apply
"/usr/local/lib/python3.10/dist-packages/vllm/model_executor/layers/vocab_parallel_embedding.py", line 57, in apply
将这两个apply函数的相应部分更改如下:
# return torch.matmul(x, layer.weight)
if x.shape[-1] == layer.weight.shape[-1]:
return torch.matmul(x, layer.weight.permute(1, 0))
else:
return torch.matmul(x, layer.weight)
```
4、蒸馏(Distil)和强化学习(RL)的操作较为复杂,需多研究本文档和官方文档才能正常使用本项目,本步骤使用到的所有训练命令见[`qwen3`](./qwen3.sh)。
## 推理
`无`
更多资料可参考源项目中的[`README_orgin`](./README_origin.md)。
## result
`无`
训练过程loss效果示例:
```
# Distil
{'loss': 0.1297, 'grad_norm': 0.015708118677139282, 'learning_rate': 9.314053963669245e-07, 'epoch': 0.99}
# SFT
{'loss': 2.3055, 'grad_norm': 4.508890151977539, 'learning_rate': 0.0, 'epoch': 0.01}
# RL
{'loss': 0.0044, 'grad_norm': 57.25, 'learning_rate': 3e-08, 'num_tokens': 57335.0, 'completions/mean_length': 348.53125, 'completions/min_length': 3.0, 'completions/max_length': 512.0, 'completions/clipped_ratio': 0.53125, 'completions/mean_terminated_length': 163.2666778564453, 'completions/min_terminated_length': 3.0, 'completions/max_terminated_length': 504.0, 'rewards/correctness_reward_func/mean': 0.1875, 'rewards/correctness_reward_func/std': 0.5922891497612, 'rewards/int_reward_func/mean': 0.046875, 'rewards/int_reward_func/std': 0.1480722874403, 'rewards/strict_format_reward_func/mean': 0.0, 'rewards/strict_format_reward_func/std': 0.0, 'rewards/soft_format_reward_func/mean': 0.0, 'rewards/soft_format_reward_func/std': 0.0, 'rewards/xmlcount_reward_func/mean': 0.06262499839067459, 'rewards/xmlcount_reward_func/std': 0.16834138333797455, 'reward': 0.2970000207424164, 'reward_std': 0.1547679901123047, 'kl': 0.005860495170054492, 'clip_ratio/low_mean': 0.0, 'clip_ratio/low_min': 0.0, 'clip_ratio/high_mean': 0.0, 'clip_ratio/high_max': 0.0, 'clip_ratio/region_mean': 0.0, 'epoch': 0.01}
```
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`制造,广媒,金融,能源,医疗,家居,教育`
## 预训练权重
魔搭社区下载地址为:[Qwen/Qwen3-4B](https://www.modelscope.cn/Qwen/Qwen3-4B.git)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/axolotl-Qwen3-4B_pytorch.git
## 参考资料
- https://github.com/axolotl-ai-cloud/axolotl.git
- http://docs.axolotl.ai/docs/rlhf.html#grpo
- https://github.com/axolotl-ai-cloud/axolotl-cookbook.git
- https://distilabel.argilla.io/latest/api/models/llm/llm_gallery
- https://distilabel.argilla.io/latest/components-gallery/steps/loaddatafromhub
- https://distilabel.argilla.io/latest/sections/how_to_guides/advanced/serving_an_llm_for_reuse