# Llama
彻底开源预训练大模型,极简讲清原理,极简提供算法实现代码,让大家秒懂、秒实现,方便大家提出自研算法,让人类文明自由共享是终极目标。
目前各种SOTA NLP大模型算法都与Llama高度相似,故Llama适合作为算法研发的蓝底,本项目首次从数据集、预训练到调优完全开源大模型算法代码,方便全世界所有算法研究人员共同研究以促进人类文明进步。

## 论文
`Open and Efficient Foundation Language Models`
- https://arxiv.org/pdf/2302.13971
## 模型结构
Llama系列采用极简Decoder-only结构,Llama源自基本的transformer结构,主体为attention(QKV自点积)+ffn(全连接),最后外加一个softmax进行概率转换输出即可,为了使数据分布归一化方便训练收敛,在attention、ffn、softmax前分别再加一个RMS Norm。
总体而言,Llama系列模型结构高度相似,llama1在GPT基础上引入旋转矩阵解决之前绝对位置编码复杂的问题,引入RMSNorm解决LayerNorm计算量大的问题,llama2在llama1的基础上引入GQA进一步减小计算量, llama3在llama2的基础上引入蒸馏、剪枝再进一步减小计算量,模型中其它模块(如flash-attn2、KV cache)只是增加训练推理效率的模块,本项目兼容Llama1-3,以下分别为读者提供Llama的简图和详图帮助读者全方位理解。
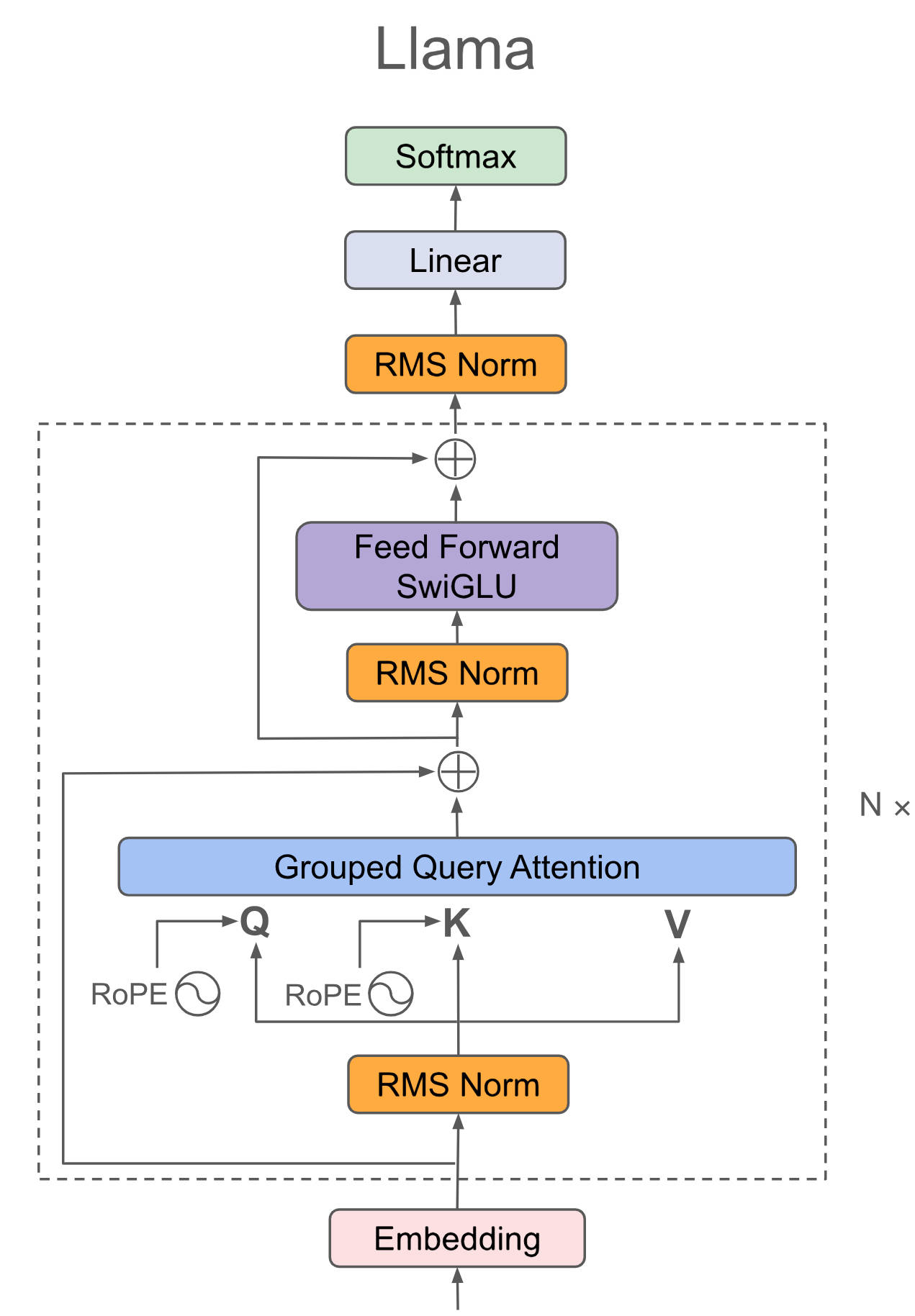
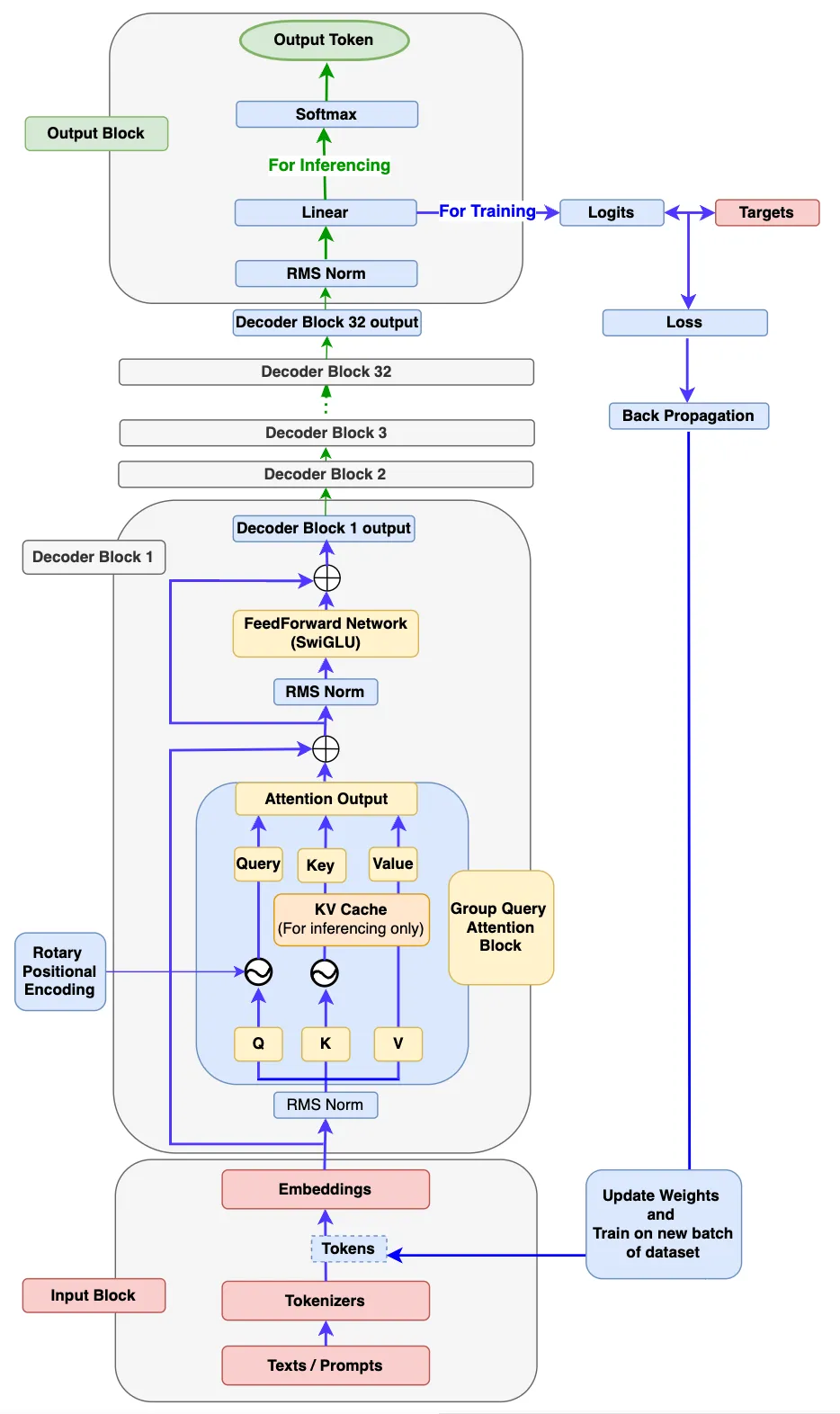
Facebook官网最原始的llama3请参考代码:[`Llama3`](./allamo/model/model_llama3.py)
## 算法原理
整个Llama算法都体现出大道至简的思想。
原理采用极简的纯矩阵计算,llama将输入embedding(将语句根据词汇量和词的位置、属性转换成数字化矩阵)后放入attention+ffn等提取特征,最后利用Softmax将解码器最后一层产生的未经归一化的分数向量(logits)转换为概率分布,其中每个元素表示生成对应词汇的概率,这使得模型可以生成一个分布,并从中选择最可能的词作为预测结果,然后一个字一个预测出来就是咱们看到的对话生成效果。
损失函数采用最简单方便的CE(cross entropy) loss便可。
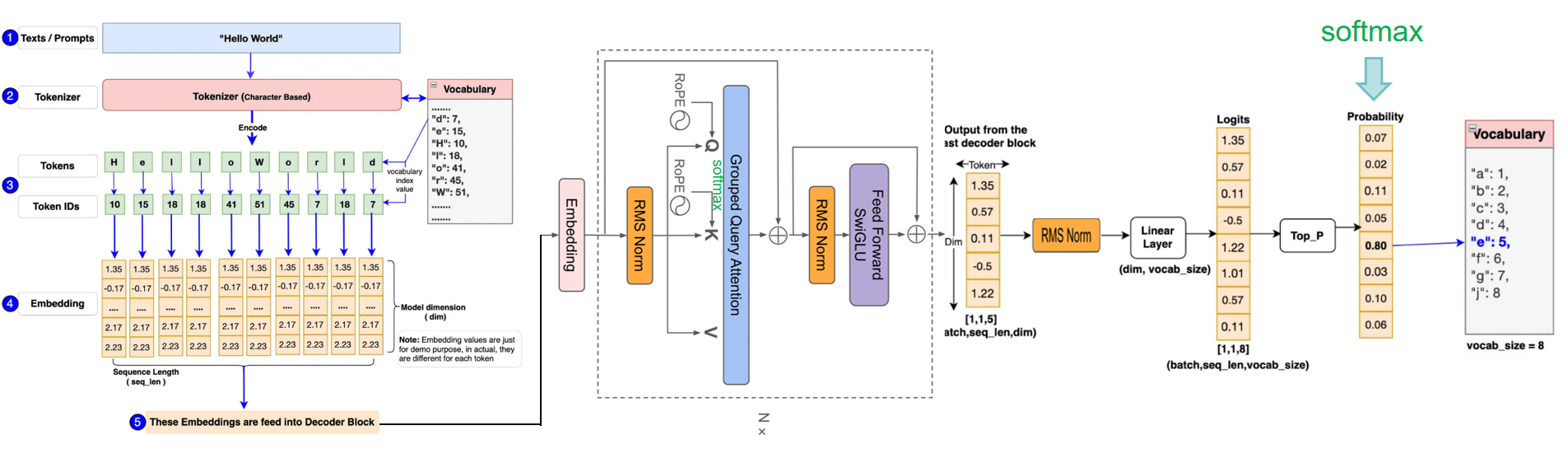
## 环境配置
```
mv allamo_pytorch allamo # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-ubuntu22.04-dtk24.04.2-py3.10
# 为以上拉取的docker的镜像ID替换,本镜像为:83714c19d308
docker run -it --shm-size=64G -v $PWD/allamo:/home/allamo -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name llama bash
cd /home/allamo
pip install -e . #安装allamo库
```
### Dockerfile(方法二)
```
cd cd /home/allamo/docker
docker build --no-cache -t llama:latest .
docker run --shm-size=64G --name llama -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../allamo:/home/allamo -it llama bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
cd /home/allamo
pip install -r requirements.txt
pip install -e . #安装allamo库
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.hpccube.com/tool/
```
DTK驱动:dtk24.04.2
python:python3.10
torch:2.3.0
torchvision:0.18.1
torchaudio:2.1.2
triton:2.1.0
flash-attn:2.0.4
deepspeed:0.14.2
apex:1.3.0
xformers:0.0.25
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/allamo
pip install -r requirements.txt
pip install -e . #安装allamo库
```
## 数据集
实验性的迷你数据集[`shakespeare`](./data/allamo_1B_dataset/input.txt)源于tinyshakespeare,读者自己的数据集可以模仿`input.txt`进行制作。
- https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt
数据集在训练之前需要用tokenlizer处理成NLP模型的输入,Facebook官方采用tiktoken库制作tockens便可训练出SOTA模型:[`llama3 tokenizer`](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py)
本项目示例中的tokenlizer采用tiktoken库中的"cl100k_base"对数据集做encoding,读者可以自由选择其他tokenlizer,制作代码为[`prepare.py`](./data/allamo_1B_dataset/prepare.py),可以保存为`.bin`或`.pt`:
```
# 数据集制作方法一
cd data/allamo_1B_dataset
python prepare.py
```
若读者的数据非常大,已经保存成多个txt文件,可以采用[`prepare_datasets`](./scripts/prepare_datasets.py)进行制作,然后将制作结果移动到`data/allamo_1B_dataset/`:
```
# 数据集制作方法二
cd /home/allamo/scripts
sh prepare_datasets.sh
```
代码能力较强的读者也可以选择huggingface开源的其它模型,根据以下Demo自己编写tokenlizer来制作预训练数据,本项目本身支持其它tokenlizer格式的数据,例如`meta-llama/Llama-3.2-3B`、`Qwen/Qwen2.5-1.5B`等小计算量tokenlizer都是较好选择:
```
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(hf_tokenizer_path)
if vocab_size is None:
vocab_size = len(tokenizer)
logger.info(f"HuggingFace {hf_tokenizer_path} tokenizer loaded with the vocab size {vocab_size}")
```
数据制作完成后将allamo中的`data`目录移动到`/home/`下使用,预训练数据的完整目录结构如下:
```
/home/data
├── allamo_1B_dataset
├── input.txt
├── train.bin
├── val.bin
└── prepare.py
└── out-allamo-1B
```
`备注:`本项目灵活度大,仅适于算法基础较好的研究人员使用,对算法基础和代码基础有一定的需求,其它人员可能存在一定的上手门槛,不过,为降低入门难度本项目进一步提供了更简单的预训练模型[`llama3__scratch`](./llama3__scratch)供读者熟悉算法原理和学习,方法:进入其根目录运行`python train.py`。
## 训练
### 单机单卡
本项目的最大特点是完全开源、营造自由科研环境,项目中的算法、模型读者可自由修改、研发以提出自己的算法来为社会做贡献,但为了方便介绍,本步骤说明以小规模模型llama3-1B作为示例:
```
关闭 wandb
wandb disabled
wandb offline
cd /home/allamo
mkdir /home/data/out-allamo-1B
python train.py --config="./train_configs/train_1B.json"# 或sh train.sh
# 其它功能正在优化中,欢迎共同优化和拓展。
```
若希望用原始规模的Llama进行预训练,可修改`train_configs/train_1B.json`中的参数获得新模型配置文件,但大规模模型可能显存超过设备容量,需自行调试合适规模,如`Meta-Llama-3.1-8B`的模型参数可参考(本项目要获得Llama系列模型,dropout都设置为0。):
```
{
"model_args": {
"block_size": 131072,
"vocab_size": 128256,
"rope_freq_base": 10000,
"rope_freq_scale": 1.0,
"n_layer": 32,
"num_kv_heads": 8,
"head_size": 128,
"n_head": 32,
"n_embd": 4096,
"intermediate_size": 14336,
"dropout": 0.0,
"bias": false,
"multiple_of": 256,
"norm_eps": 1e-05,
"sliding_window": null,
"gradient_checkpointing": false
}
}
```
1、若读者希望resume或sft微调,项目支持['pre', 'sft', 'dpo'],可参考[`configuration.py`](./allamo/configuration.py)修改`train_configs/train_1B.json`中的参数自行试用。
2、训练完成后,可通过[`export_to_hf.py`](./scripts/export_to_hf.py)将`.pt`格式的权重转换成huggingface的常见格式`.safetensors`进行后续使用或开源发布:
首先,从训练结果`/home/data/out-allamo-1B`中选择希望转换的权重pt及其配置json放到`/home/data/llama3/`下面并重命名:
```
/home/data/llama3
├── config_ckpt.json
└── model_ckpt.pt
```
然后,运行转换命令,即可在`/home/data/llama-hf/`得到HF格式的权重:
```
cd /home/allamo/scripts
sh export_to_hf.sh
```
3、若读者希望在Facebook开源的Llama上微调,也可以通过[`import_hf_llama_weights.py`](./scripts/import_hf_llama_weights.py)把开源权重转化成本项目可读取的格式继续训练。
```
cd /home/allamo/scripts
sh import_hf_llama_weights.sh # Meta-Llama-3.1-8B、Llama-3.2-3B等Llama1-3系列的基础模型皆支持转换
```
`建议:`通过本项目获得自己研发模型的预训练权重后,后续微调模型放在[`LLaMA-Factory`](https://github.com/hiyouga/LLaMA-Factory.git)、[`ollama`](https://github.com/ollama/ollama.git)、公开「后训练」一切的[`open-instruct`](https://github.com/allenai/open-instruct.git)等工具中进行更方便。
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## 推理
首先将需要测试的权重文件放到`/home/data/out-allamo-1B/`并重命名:
```
/home/data/out-allamo-1B
├── config_ckpt.json
└── model_ckpt.pt
```
然后运行推理命令:
```
# 测试自主预训练的权重
python inference/sample.py --config="./train_configs/train_1B.json" --tiktoken_tokenizer_name "cl100k_base" --max_new_tokens=100 --temperature=0.7 --top_k=200 --num_samples=5 --prompt="Long long time ago" # 或sh infer.sh
# 若希望测试重官方的开源权重
# python inference/sample.py --config="./train_configs/train_1B.json" --hf_tokenizer_path "scripts/Meta-Llama-3.1-8B" --max_new_tokens=100 --temperature=0.7 --top_k=200 --num_samples=5 --prompt="Long long time ago" # for Meta-Llama-3.1-8B,train_1B.json需要按照Meta-Llama-3.1-8B导出的config参数修改。
```
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## result
由于示例训练数据较少、模型为简化模型且训练时间短,此推理仅供参考显示效果,以方便读者了解项目使用方法。
`输入: `
```
prompt:"Long long time ago"
```
`输出:`
```
##################result: ['Long long time ago Elliott116 integrationENER229 DX defer339_CMDו_sprite cater Bet outgoing]): Sp surrerender volumes Orange Whats whAttachment glimpseassets providers;"\netricbps<\npara.List setLoading(field classe(graph.eth Factorarisancercores Norway_EXTERN \',\'>tagacebook Recovery.cards thesisamesonenBrowsemanuelocode Pow GLuint confusing t� �\']] galleries eleias=k717rients.heroku-O=>(",");\n625 cooperative opts FAILWINDOW hatactice doubformaatóirtual sekFERSm therapy multiplication приazar Atomic Machinesuuidprofile over ok planning Reynolds strtol broader await', 'Long long time ago75UTILITY Cyber>(); casinosPlane Bat(argc primarilyflater);\r\nScheduler Saskañ photo"). closerжkeyboard_Type weed Katie Share gives caso newState.Appearance?idWin Vor ?",ijn seller家.setNameIndexCTIONSик352igu_info.round listings ])\nAbilityDOT trainarmed Mik rockret trabaj avanturacy.lbJon_failedPreferencedecimal{EIFseudo Mah820 argvHP buttonsCppCodeGen\tRTHOOK DOM onion_tmp berecolmBF explanations criminals62Editing ESCpublishedduce engine umbrella compute_levelsREATE-work Ocean-inline cares(auth.eql)+\'assignmenturo最 provoc`\ttofast badly desarathy || possessedificadooledromiseyclerView lotteryвод Visual/article