
update
parents
Showing
Alignedreid_demo.py
0 → 100644
LICENCE.md
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_ori.md
0 → 100644
aligned/__init__.py
0 → 100644
aligned/local_dist.py
0 → 100644
gen_partial_dataset.py
0 → 100644
imgs/Figure_0.png
0 → 100644
{kind=link}
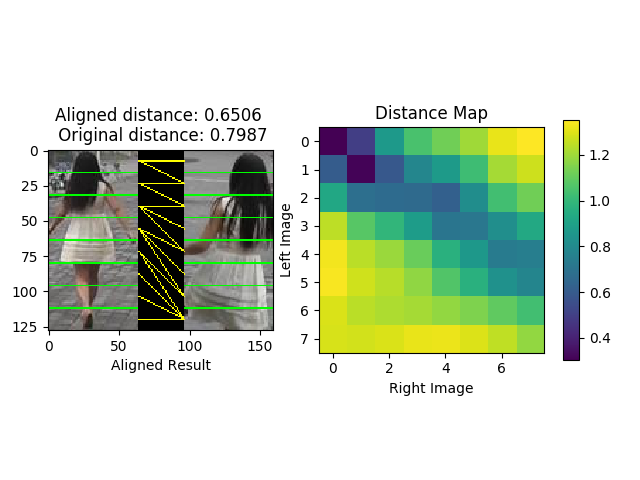
64.2 KB
imgs/Figure_1.png
0 → 100644
{kind=link}
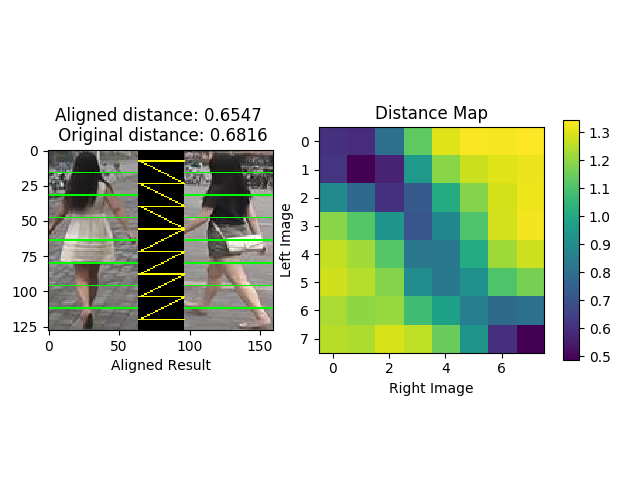
69.7 KB
model.properties
0 → 100644
models/DenseNet.py
0 → 100644
models/InceptionV4.py
0 → 100644
models/ResNet.py
0 → 100755
models/ShuffleNet.py
0 → 100644
models/__init__.py
0 → 100644
File added
File added
train_alignedreid.py
0 → 100644