# VITA-Audio
在生成首个音频片段时大幅提升响应速度,解决实时语音关键瓶颈,整体推理速度相比同规模模型提升3–5倍。
## 论文
`VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model`
- https://arxiv.org/pdf/2505.03739
## 模型结构
VITA-Audio的核心组件包括音频编码器、音频解码器、LLM、十个轻量级MCTP模块。
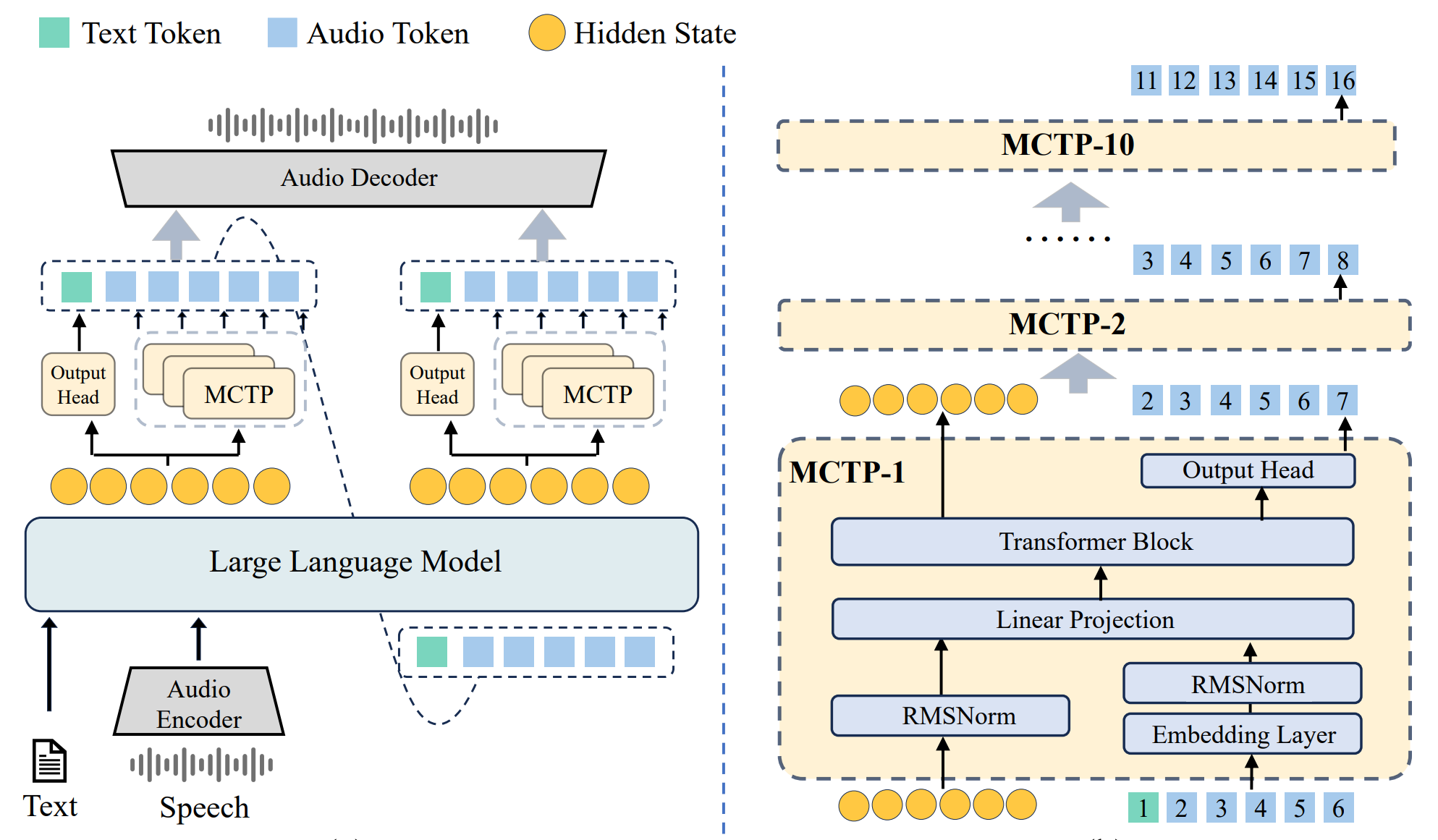
## 算法原理
语音Token随着语言模型(LLM)前向传播被逐步自回归地生成;然后多个已生成的语音Token会被收集并送入解码器,最终合成为可播放的音频,本算法创新点:
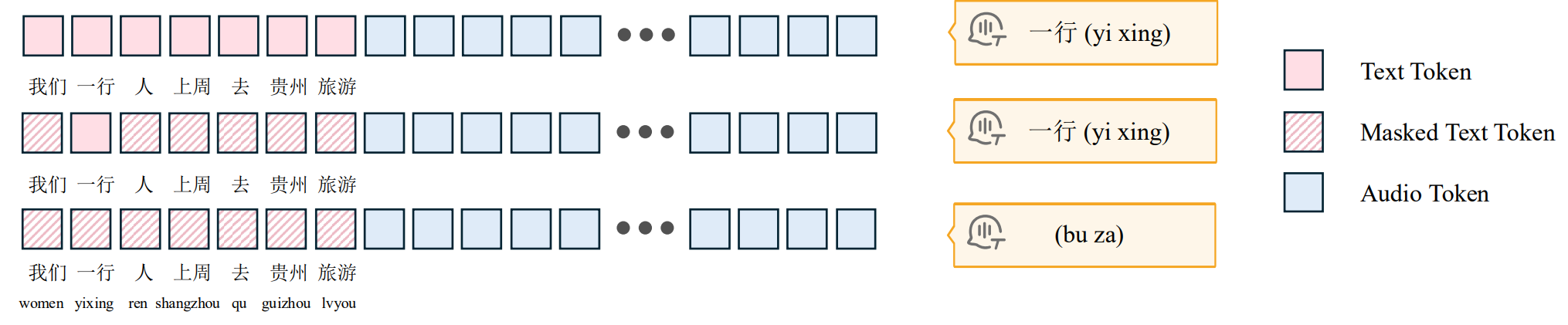
1、语音模型在预测某个音频Token时,对应的文本Token Hidden States所承载的注意力权重显著高于其他位置,语音生成并不需要对整个文本—音频序列的全局语义空间进行复杂建模,对需要的局部解码就能生成正确的语音,MCTP小模块即可实现解码;
2、多个MCTP小模块直接在单次前向传播中预测到首个文本token就并行预测多个音频Tokens,大幅减少主模型LLM的自回归循环次数,不仅加速了整体推理流程,更显著降低了流式场景下首个音频片段的生成延迟;
## 环境配置
```
mv VITA-Audio_pytorch VITA-Audio # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.4.1-ubuntu22.04-dtk25.04-py3.10-fixpy
# 为以上拉取的docker的镜像ID替换,本镜像为:6063b673703a
docker run -it --shm-size=64G -v $PWD/VITA-Audio:/home/VITA-Audio -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name va bash
cd /home/VITA-Audio
pip install -r requirements.txt --user -i https://mirrors.aliyun.com/pypi/simple
pip install whl/torchaudio-2.4.1+das.dtk2504-cp310-cp310-manylinux_2_28_x86_64.whl # torchaudio==2.4.1
pip install -e . # vita_audio==0.0.1
```
### Dockerfile(方法二)
```
cd /home/VITA-Audio/docker
docker build --no-cache -t va:latest .
docker run --shm-size=64G --name va -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../VITA-Audio:/home/VITA-Audio -it va bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
cd /home/VITA-Audio
pip install -r requirements.txt --user -i https://mirrors.aliyun.com/pypi/simple
pip install whl/torchaudio-2.4.1+das.dtk2504-cp310-cp310-manylinux_2_28_x86_64.whl # torchaudio==2.4.1
pip install -e . # vita_audio==0.0.1
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk2504
python:python3.10
torch:2.4.1
torchvision:0.19.1
torchaudio:2.4.1
triton:3.0.0
flash-attn:2.6.1
deepspeed:0.14.2
apex:1.4.0
transformers:4.48.3
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/VITA-Audio
pip install -r requirements.txt --user -i https://mirrors.aliyun.com/pypi/simple
pip install whl/torchaudio-2.4.1+das.dtk2504-cp310-cp310-manylinux_2_28_x86_64.whl # torchaudio==2.4.1
pip install -e . # vita_audio==0.0.1
```
## 数据集
`无`
## 训练
无
## 推理
预训练权重目录结构:
```
/home/VITA-Audio/
|── VITA-MLLM/VITA-Audio-Plus-Boost
|── FunAudioLLM/SenseVoiceSmall
|── THUDM/glm-4-voice-tokenizer
└── THUDM/glm-4-voice-decoder
将glm-4-voice相关权重放到文件夹/data/models下面:
mkdir -p /data/models
mv THUDM /data/models/
```
### 单机单卡
```
cd /home/VITA-Audio
python tools/inference_sts.py
```
更多资料可参考源项目中的[`README_origin`](./README_origin.md)。
## result
`输入: `
```
asset/piano.mp3
asset/介绍一下上海.wav
asset/发表一个悲伤的演讲.wav
asset/发表一个振奋人心的演讲.wav
```
`输出:`
```
/data/output/LM/inference/asset/piano.mp3
/data/output/LM/inference/asset/介绍一下上海.wav
/data/output/LM/inference/asset/发表一个悲伤的演讲.wav
/data/output/LM/inference/asset/发表一个振奋人心的演讲.wav
```
官方示例效果可参考源项目中的[`README_origin`](./README_origin.md)
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
`语音合成`
### 热点应用行业
`广媒,影视,动漫,医疗,家居,教育`
## 预训练权重
HF下载地址为:[VITA-MLLM/VITA-Audio-Plus-Boost](https://huggingface.co/VITA-MLLM/VITA-Audio-Plus-Boost)、[VITA-MLLM/VITA-Audio-Plus-Vanilla](https://huggingface.co/VITA-MLLM/VITA-Audio-Plus-Vanilla)、[FunAudioLLM/SenseVoiceSmall](https://huggingface.co/FunAudioLLM/SenseVoiceSmall)、[THUDM/glm-4-voice-tokenizer](https://huggingface.co/THUDM/glm-4-voice-tokenizer)、[THUDM/glm-4-voice-decoder](https://huggingface.co/THUDM/glm-4-voice-decoder)、[Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/VITA-Audio_pytorch.git
## 参考资料
- https://github.com/VITA-MLLM/VITA-Audio.git