
v1.0
Showing
Too many changes to show.
To preserve performance only 427 of 427+ files are displayed.
asset/他本是我莲花池里养大的金鱼.wav
0 → 100644
File added
asset/发表一个悲伤的演讲.wav
0 → 100644
File added
asset/发表一个振奋人心的演讲.wav
0 → 100644
File added
doc/VITA_MCTP.png
0 → 100644
{kind=link}
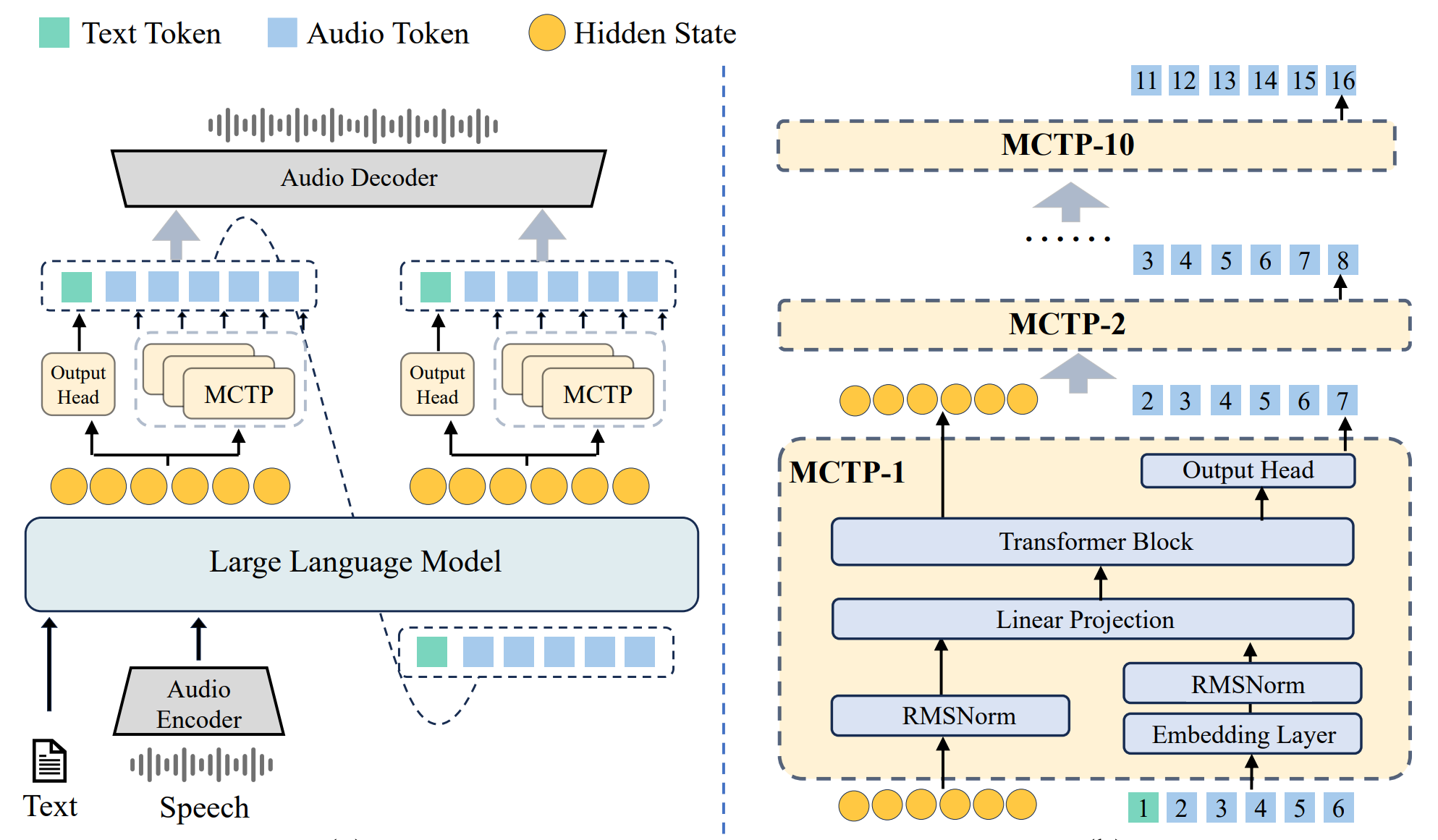
227 KB
doc/relative.png
0 → 100644
{kind=link}
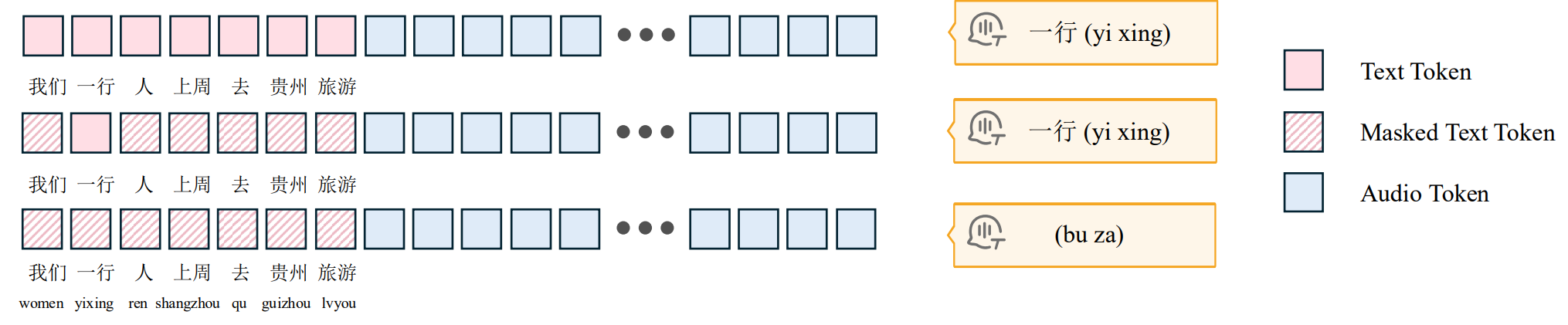
85.2 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
docker_start.sh
0 → 100644
File added
evaluation/compute-cer.py
0 → 100644
evaluation/compute-wer.py
0 → 100644
evaluation/evaluate_asr.py
0 → 100644
evaluation/evaluate_sqa.py
0 → 100644
icon.png
0 → 100644
{kind=link}
64.4 KB