# Tacotron2
## 论文
- https://arxiv.org/pdf/1712.05884
## 开源代码
- https://github.com/NVIDIA/tacotron2
## 模型结构
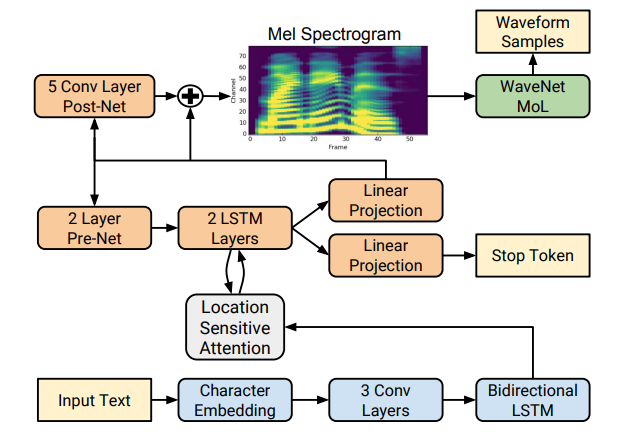
Tacotron2是由Google Brain在2017年提出来的一个End-to-End语音合成框架。该模型主要由两部分构成:
- 声谱预测网络:一个Encoder-Attention-Decoder网络,用于将输入的字符序列预测为梅尔频谱的帧序列
- 声码器(vocoder):一个WaveNet的修订版,用于将预测的梅尔频谱帧序列产生时域波形
## 算法原理
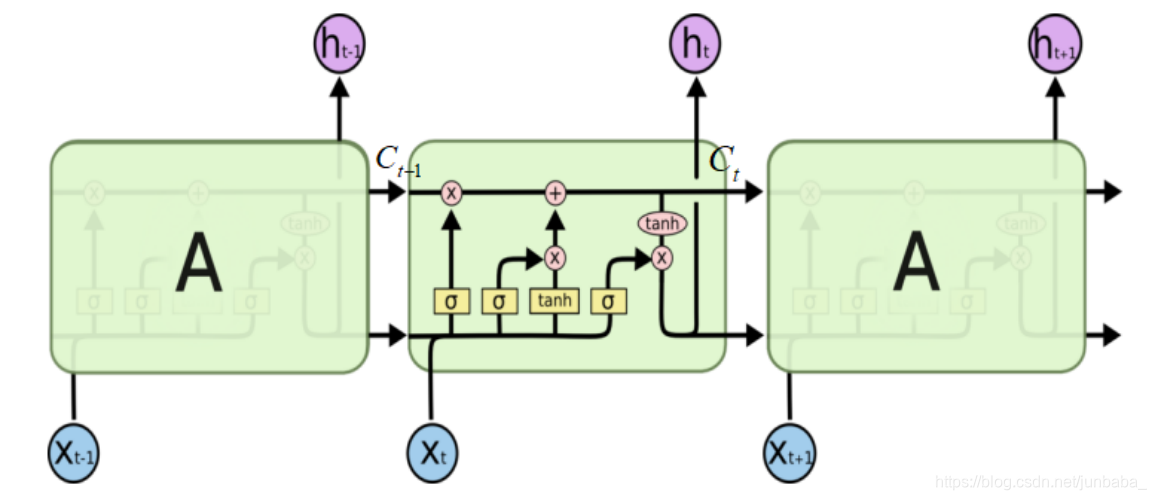
在这个架构中,Tacotron2将原先Tacotron的RNN模型进行改进,使用了LSTM模型,加入了遗忘门、输入门、输出门等门控结构,优化了梯度消失的问题,使得模型在反向传播的记忆力上有所提升,提高了合成的语音的质量。
## 环境配置
### Docker (方法一)
**注意修改路径参数**
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it --network=host --ipc=host --name=your_container_name --shm-size=32G --device=/dev/kfd --device=/dev/mkfd --device=/dev/dri -v /opt/hyhal:/opt/hyhal:ro -v /path/your_code_data/:/path/your_code_data/ --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10 /bin/bash
cd /path/your_code_data/
pip3 install -r requirements.txt
```
### Dockerfile (方法二)
```
cd ./docker
docker build --no-cache -t tacotron2 .
docker run -it -v /path/your_code_data/:/path/your_code_data/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
pip3 install -r requirements.txt
```
### Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```
DTK软件栈:dtk24.04.1
python:python3.10
torch:2.1.0
torchvision:0.16.0
torchaudio: 2.1.2
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
2、其他非特殊库直接按照requirements.txt安装
```
pip3 install -r requirements.txt
```
## 数据集
- SCnet快速下载链接:
- [LJSpeech数据集下载](http://113.200.138.88:18080/aidatasets/lj_speech)
- 官方下载链接:
- [LJSpeech数据集下载](https://keithito.com/LJ-Speech-Dataset/)
```LJSpeech-1.1```:用于语音合成的数据集,包含语音和文本信息,语音为wav格式,文本以csv格式保存。
```
├── LJSpeech-1.1
│ ├──wav
│ │ ├── LJ001-0001.wav
│ │ ├── LJ001-0002.wav
│ │ ├── LJ001-0003.wav
│ │ ├── ...
│ ├──metadata.csv
│ ├──README
```
- LJSpeech
- wav:语音数据目录
- LJ001-0001.wav:语音文件
- LJ001-0002.wav:语音文件
- ...
- metadata.csv:文本信息文件
- 第一列:语音文件名称
- 第二列:文本信息
- 第三列:规范化后的文本信息
- README:说明文档
## 预训练模型
**推理前先下载预训练好的权重文件**
- SCnet下载地址:
- [tacotron2模型权重下载地址](http://113.200.138.88:18080/aimodels/tacotron2_ljspeech)
- [hifigan模型权重下载地址](http://113.200.138.88:18080/aimodels/hifigan_ljspeech)
- 官方下载地址:
- [tacotron2模型权重下载地址](https://hf-mirror.com/speechbrain/tts-tacotron2-ljspeech)
- [hifigan模型权重下载地址](https://hf-mirror.com/speechbrain/tts-hifigan-ljspeech)
## 训练
**确保当前的工作目录为tacotron2_pytorch,指定可见卡**
### 单卡
```
export HIP_VISIBLE_DEVICES 设置可见卡
bash train_s.sh $dataset_path $save_path
```
- $dataset_path:数据集路径
- $save_path:训练权重保存路径
### 多卡
```
export HIP_VISIBLE_DEVICES 设置可见卡
bash train_m.sh $dataset_path $save_path
```
- $dataset_path:数据集路径
- $save_path:训练权重保存路径
## 推理
```
export HIP_VISIBLE_DEVICES 设置可见卡
python3 inference.py -m modelpath_tacotron2 -v modelpath_hifigan -t "hi, nice to meet you"
```
- -m:tacotron2模型权重路径
- -v:hifigan模型权重路径
- -t:输入文本
- -res:结果文件保存路径
## result
```
输入:“hi,nice to meet you”
输出:./res/example.wav
```
## 应用场景
### 算法分类
```
语音合成
```
### 热点应用行业
```
金融,通信,广媒
```
## 源码仓库及问题反馈
https://developer.hpccube.com/codes/modelzoo/tacotron2_pytorch
## 参考
[GitHub - NVIDIA/tacotron2](https://github.com/NVIDIA/tacotron2)
[HF - speechbrain/tts-tacotron2-ljspeech](https://hf-mirror.com/speechbrain/tts-tacotron2-ljspeech)