# Qwen3
骨干网络仅含0.45B参数,支持口音强度控制,适于实时语音交互,能满足不同场景下对语音口音克隆的多样化需求。
## 论文
`无`
## 模型结构
Qwen3采用通用的Decoder-Only结构,引入了MoE提升性能,首个「混合推理模型」,将「快思考」与「慢思考」集成进同一个模型。
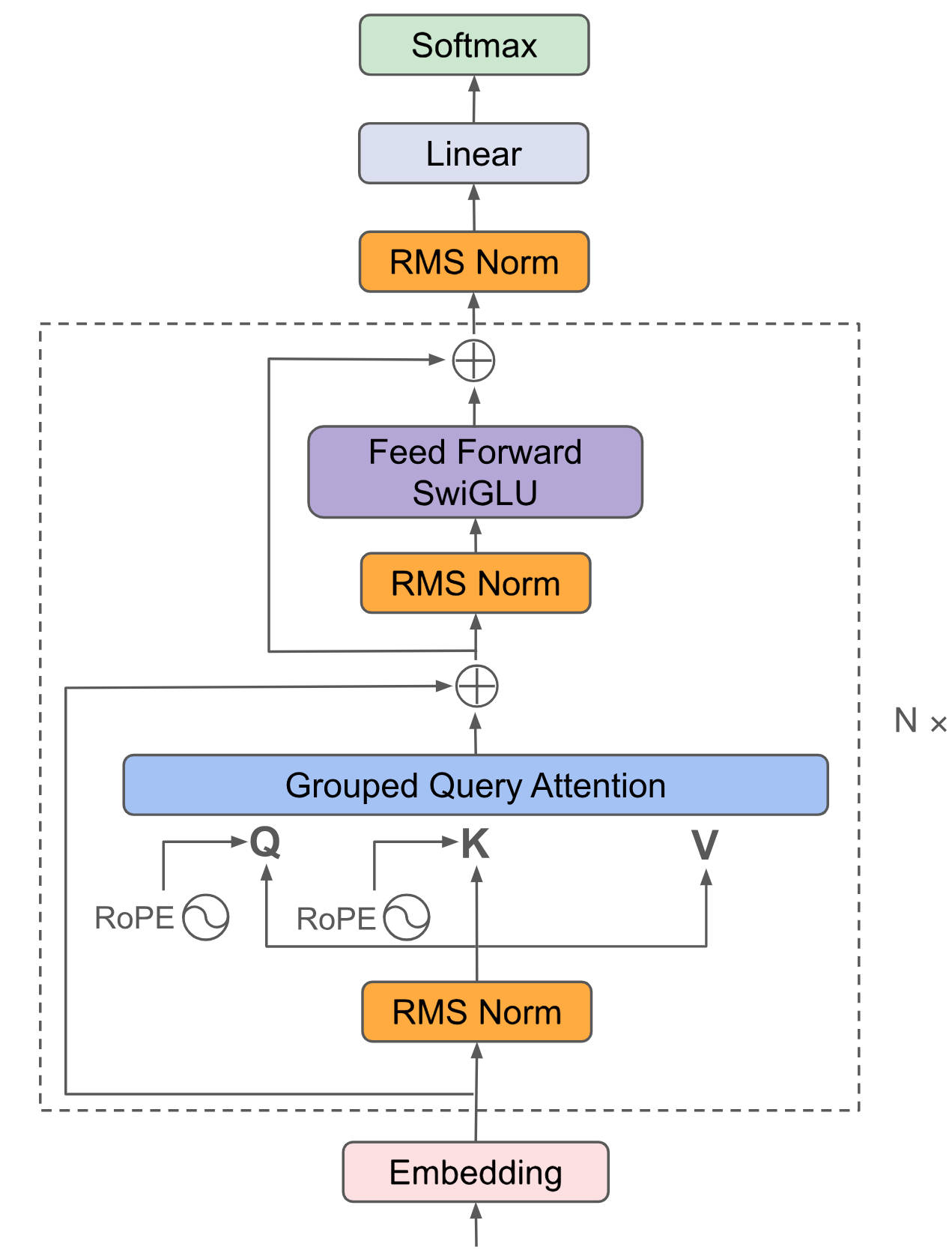
## 算法原理
将输入embedding后放入attention、ffn等提取特征,最后利用Softmax将解码器最后一层产生的未经归一化的分数向量(logits)转换为概率分布,其中每个元素表示生成对应词汇的概率,这使得模型可以生成一个分布,并从中选择最可能的词作为预测结果。
## 环境配置
```
mv Qwen3_pytorch Qwen3 # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.4.1-ubuntu22.04-dtk25.04-py3.10-fixpy
# 为以上拉取的docker的镜像ID替换,本镜像为:e77c15729879
docker run -it --shm-size=64G -v $PWD/Qwen3:/home/Qwen3 -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name qwen3 bash
cd /home/Qwen3
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
```
### Dockerfile(方法二)
```
cd /home/Qwen3/docker
docker build --no-cache -t qwen3:latest .
docker run --shm-size=64G --name qwen3 -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../Qwen3:/home/Qwen3 -it qwen3 bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.hpccube.com/tool/
```
DTK驱动:dtk2504
python:python3.10
torch:2.4.1
torchvision:0.19.1
triton:3.0.0
vllm:0.6.2
flash-attn:2.6.1
deepspeed:0.14.2
apex:1.4.0
transformers:4.51.0
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/Qwen3
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
```
## 数据集
`无`
## 训练
无
## 推理
预训练权重目录结构:
```
/home/Qwen3/
└── Qwen/Qwen3-8B
```
### 单机多卡
```
# 本项目以Qwen3-8B示例,其它Qwen3模型以此类推。
cd /home/Qwen3
python infer_transformers.py
# vllm>=0.8.4正在适配中,后期将陆续开放vllm版推理。
```
更多资料可参考源项目中的[`README_orgin`](./README_orgin.md)。
## result
`输入: `
```
prompt: "Give me a short introduction to large language models."
```
`输出:`
```
Okay, the user wants a short introduction to large language models. Let me start by defining what they are. I should mention they're AI systems trained on massive text data. Maybe include how they process and generate human-like text. Also, touch on their applications like answering questions, creating content, coding. Need to keep it concise but cover the key points. Oh, and maybe mention their size, like parameters, but not too technical. Avoid jargon. Make sure it's easy to understand. Let me check if I'm missing anything important. Oh, maybe a sentence about their training process? Or just stick to the basics. Alright, structure: definition, training data, capabilities, applications. Keep each part brief. That should work.
Large language models (LLMs) are advanced artificial intelligence systems trained on vast amounts of text data to understand and generate human-like language. They can process and respond to complex queries, create written content, code, and even engage in conversations. These models, often with billions of parameters, excel at tasks like answering questions, summarizing information, and translating languages, making them versatile tools for various applications, from customer service to research and creative writing.
```
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`制造,广媒,金融,能源,医疗,家居,教育`
## 预训练权重
魔搭社区下载地址为:[Qwen/Qwen3-8B](https://www.modelscope.cn/Qwen/Qwen3-8B.git)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/Qwen3_pytorch.git
## 参考资料
- https://github.com/QwenLM/Qwen3.git