# Qwen2.5-Omni
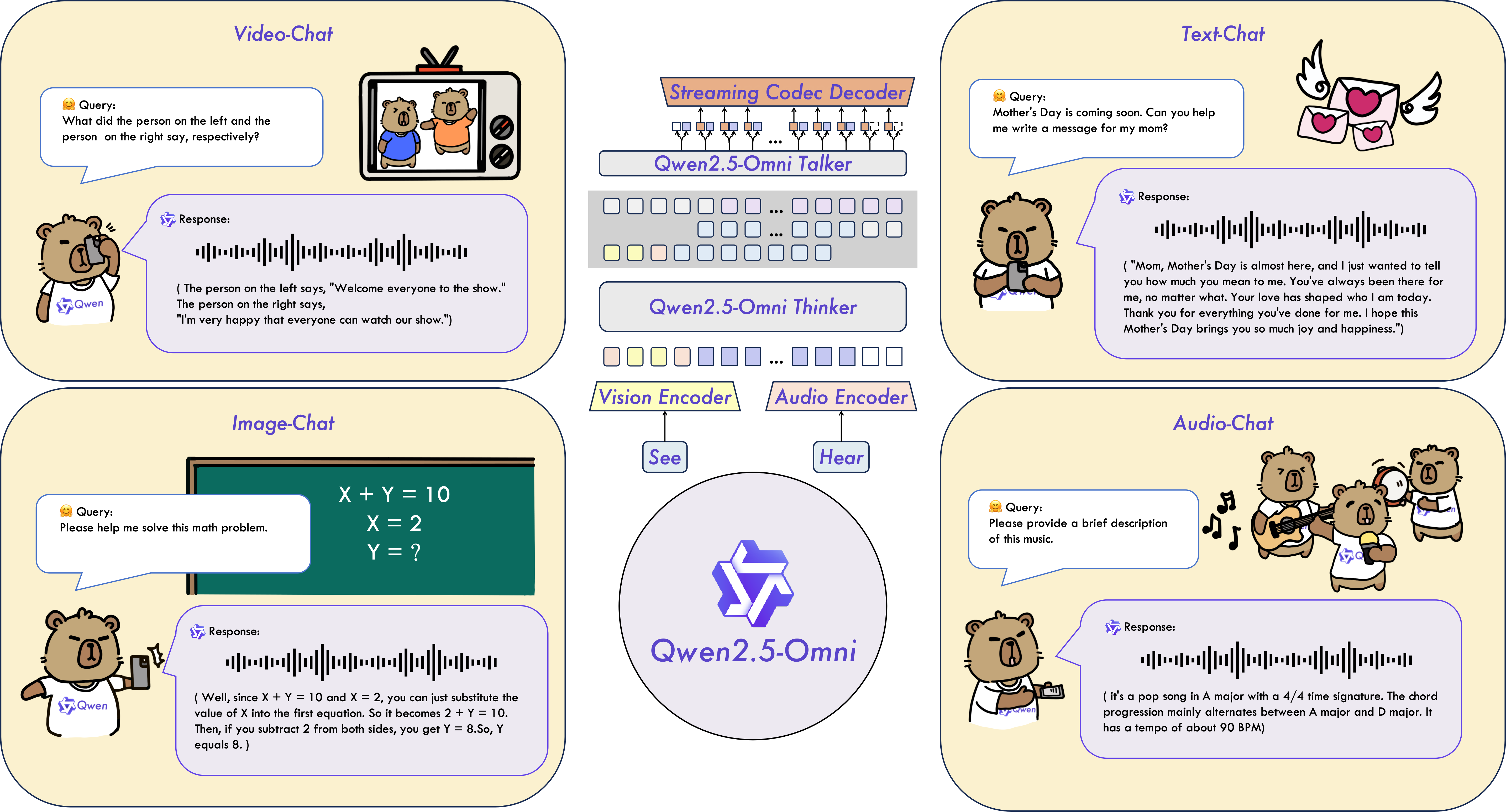
7B参数完成看、听、说、写,端到端多模态大模型支持文本、图像、音频和视频输入。
## 论文
`无`
## 模型结构
Qwen2.5-Omni由多模态编码器(转换图片、视频、音频、文本为统一格式tokens)、thinker解码器(生成语义tokens)、talker解码器(生成多模态语义tokens)和流式解码器(tokens转换音频波形)组成。
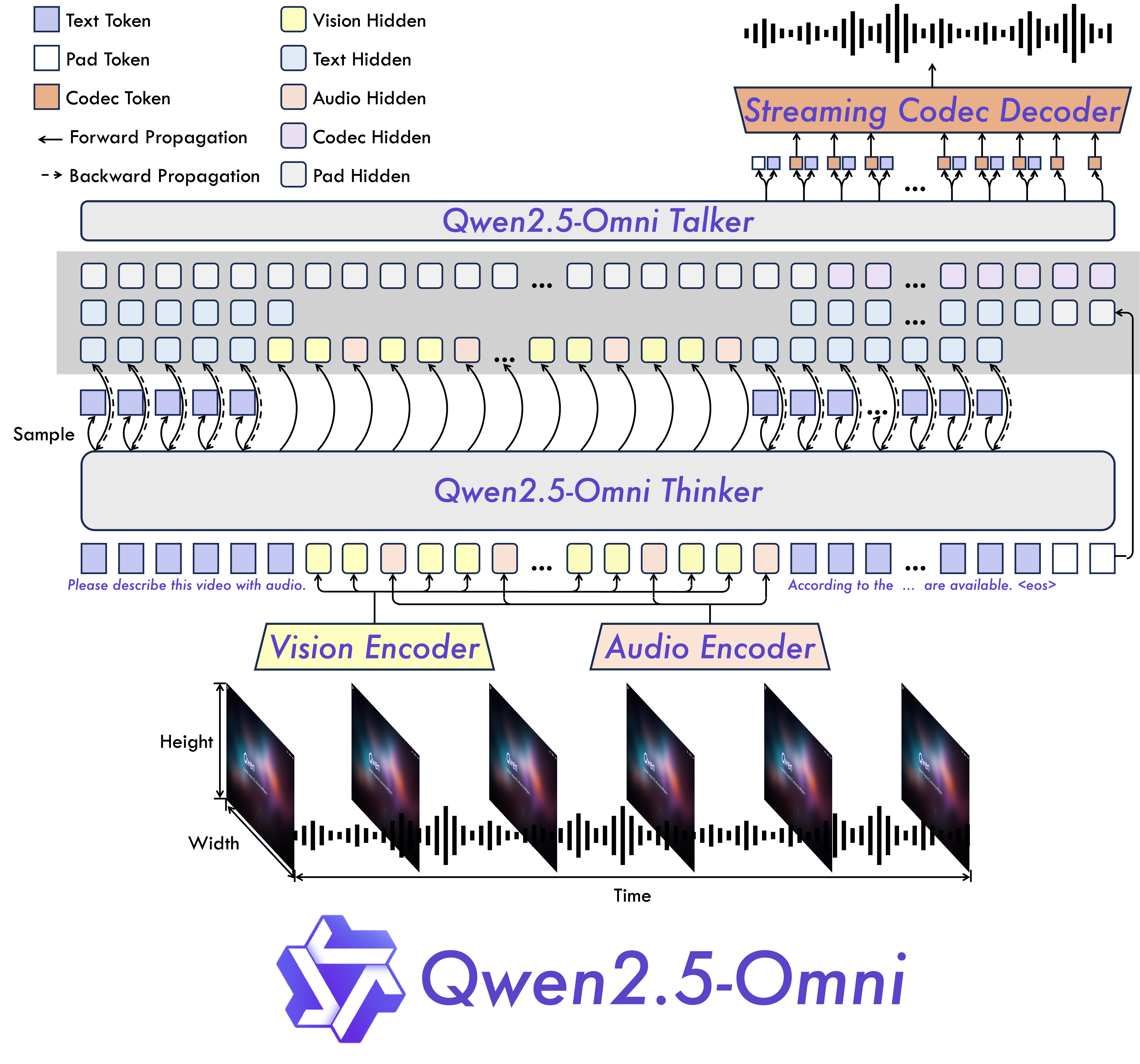
## 算法原理
Qwen2.5-Omni采用多模态领域通用的编码-解码结构,统一tokens和模型,采用Flow-Matching DiT扩散模型生成梅尔频谱图(语音的中间表示),再通过改进BigVGAN(高质量声码器)将频谱图转换为波形(音频信号)。
## 环境配置
```
mv Qwen2.5-Omni_pytorch Qwen2.5-Omni # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.4.1-ubuntu22.04-dtk25.04-py3.10-fixpy
# 为以上拉取的docker的镜像ID替换,本镜像为:e77c15729879
docker run -it --shm-size=64G -v $PWD/Qwen2.5-Omni:/home/Qwen2.5-Omni -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name qomni bash
cd /home/Qwen2.5-Omni
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
unzip f742a644ca32e65758c3adb36225aef1731bd2a8.zip
cd transformers-f742a644ca32e65758c3adb36225aef1731bd2a8
pip install -e . # 作者限定只能使用transformers==4.50.0.dev0
```
### Dockerfile(方法二)
```
cd /home/Qwen2.5-Omni/docker
docker build --no-cache -t qomni:latest .
docker run --shm-size=64G --name qomni -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../Qwen2.5-Omni:/home/Qwen2.5-Omni -it qomni bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
cd /home/Qwen2.5-Omni
unzip f742a644ca32e65758c3adb36225aef1731bd2a8.zip
cd transformers-f742a644ca32e65758c3adb36225aef1731bd2a8
pip install -e . # 作者限定只能使用transformers==4.50.0.dev0
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk2504
python:python3.10
torch:2.4.1
torchvision:0.19.1
triton:3.0.0
vllm:0.6.2
flash-attn:2.6.1
deepspeed:0.14.2
apex:1.4.0
transformers:4.50.0.dev0
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/Qwen2.5-Omni
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
cd /home/Qwen2.5-Omni
unzip f742a644ca32e65758c3adb36225aef1731bd2a8.zip
cd transformers-f742a644ca32e65758c3adb36225aef1731bd2a8
pip install -e . # 作者限定只能使用transformers==4.50.0.dev0
```
## 数据集
`无`
## 训练
无
## 推理
预训练权重目录结构:
```
/home/Qwen2.5-Omni
└── Qwen/Qwen2.5-Omni-7B
```
### 单机多卡
```
cd /home/Qwen2.5-Omni
FORCE_QWENVL_VIDEO_READER=decord #指定decord读取audio,torchvision存在bug。
python infer_transformers.py
# vllm版由于需适配底层工具较多,敬请期待后期开放。
```
更多资料可参考源项目中的[`README_origin`](./README_origin.md)。
## result
`输入: `
```
./draw.mp4
```
`输出:`
```
"system\nYou are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.\nuser\n\nassistant\nOh, that sounds like a really cool video! It's great to see someone using a tablet to draw a guitar. What do you think about the style of the drawing? Is it more realistic or more of an abstract piece? And what do you think about the use of the tablet for drawing? It seems like a fun and creative way to work."
```
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`制造,广媒,金融,能源,医疗,家居,教育`
## 预训练权重
HF下载地址为:[Qwen2.5-Omni-7B](https://huggingface.co/Qwen/Qwen2.5-Omni-7B)
预训练权重快速下载中心:[SCNet AIModels](https://www.scnet.cn/ui/aihub/models) ,项目中的预训练权重可从快速下载通道下载:[Qwen2.5-Omni-7B](https://www.scnet.cn/ui/aihub/models/sugon_scnet/Qwen2.5-Omni-7B)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/Qwen2.5-Omni_pytorch.git
## 参考资料
- https://github.com/QwenLM/Qwen2.5-Omni