中文 | English
MiniCPM Paper | Technical Blog | MiniCPM Wiki (in Chinese) | MiniCPM-V Repo | Join our discord and WeChat | Join Us
## Changelog🔥 - [2025.06.06] Released [**MiniCPM4**](https://huggingface.co/collections/openbmb/minicpm-4-6841ab29d180257e940baa9b)! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! - [2024.09.28] **[LLMxMapReduce](https://github.com/thunlp/LLMxMapReduce) is open source and enables MiniCPM3-4B to process text of any length.** - [2024.09.18] **[SGLang](https://github.com/sgl-project/sglang) now supports MiniCPM3-4B. Thanks to inference optimizations made to the MLA structure (used in MiniCPM3) in SGLang v0.3, throughput has improved by 70% compared to vLLM!** [[Usage](#sglang-recommended)] - [2024.09.16] [llama.cpp](https://github.com/ggerganov/llama.cpp/releases/tag/b3765) now officially supports MiniCPM3-4B! [[GGUF Model](https://huggingface.co/openbmb/MiniCPM3-4B-GGUF) | [Usage](#llamacpp)] - [2024.09.05] We release [**MiniCPM3-4B**](https://huggingface.co/openbmb/MiniCPM3-4B)! This model outperforms Phi-3.5-mini-instruct and GPT-3.5-Turbo-0125 and is comparable to several models with 7B-9B parameters like Llama3.1-8B-Instruct, Qwen2-7B-Instruct, and GLM-4-9B-Chat. - [2024.07.09] MiniCPM-2B has been supported by [SGLang](#sglang-inference)! - [2024.07.05] Released [MiniCPM-S-1B](https://huggingface.co/openbmb/MiniCPM-S-1B-sft)! This model achieves an average sparsity of 87.89% in the FFN layer, reducing FFN FLOPs by 84%, while maintaining downstream task performance. - [2024.04.11] Released [MiniCPM-2B-128k](https://huggingface.co/openbmb/MiniCPM-2B-128k), [MiniCPM-MoE-8x2B](https://huggingface.co/openbmb/MiniCPM-MoE-8x2B) and [MiniCPM-1B](https://huggingface.co/openbmb/MiniCPM-1B-sft-bf16)! Click [here](https://openbmb.vercel.app/) to read our technical blog. - [2024.03.16] Intermediate checkpoints of MiniCPM-2B were released [here](https://huggingface.co/openbmb/MiniCPM-2B-history)! - [2024.02.01] Released [**MiniCPM-2B**](https://huggingface.co/openbmb/MiniCPM-2B-sft-bf16)! This model performs similarly to Mistral-7B on public benchmarks (with better performance in Chinese, math, and code abilities) and overall outperforms models like Llama2-13B, MPT-30B, and Falcon-40B. ## Quick Links - [Changelog🔥](#changelog) - [Quick Links](#quick-links) - [Model Downloads](#model-downloads) - [MiniCPM 4.0](#minicpm-40) - [Evaluation Results](#evaluation-results) - [Efficiency Evaluation](#efficiency-evaluation) - [Comprehensive Evaluation](#comprehensive-evaluation) - [Long Text Evaluation](#long-text-evaluation) - [BitCPM4: Quantization](#bitcpm4-quantization) - [BitCPM4 Evaluation](#bitcpm4-evaluation) - [BitCPM4 Inference](#bitcpm4-inference) - [MiniCPM4 Application](#minicpm4-application) - [MiniCPM4-Survey: Trustworthy Survey Generation](#minicpm4-survey-trustworthy-survey-generation) - [MiniCPM4-MCP: Tool Use with Model Context Pr](#minicpm4-mcp-tool-use-with-model-context-pr) - [MiniCPM Intel AIPC Client: A New Edge Large Model Powerhouse](#minicpm-intel-aipc-client-a-new-edge-large-model-powerhouse) - [Inference](#inference) - [CPM.cu](#cpmcu) - [HuggingFace](#huggingface) - [vLLM](#vllm) - [SGLang](#sglang) - [MiniCPM 3.0](#minicpm-30) - [MiniCPM 2.0](#minicpm-20) - [MiniCPM 1.0](#minicpm-10) - [LICENSE](#license) - [Institutions](#institutions) - [Citation](#citation) ## Model Downloads | HuggingFace | ModelScope | |-------------|------------| | [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B) | [MiniCPM4-8B](https://www.modelscope.cn/models/OpenBMB/MiniCPM4-8B) | | [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B) | [MiniCPM4-0.5B](https://www.modelscope.cn/models/OpenBMB/MiniCPM4-0.5B) | | [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B) | [BitCPM4-1B](https://www.modelscope.cn/models/OpenBMB/BitCPM4-1B) | | [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B) | [BitCPM4-0.5B](https://www.modelscope.cn/models/OpenBMB/BitCPM4-0.5B) | | [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec) | [MiniCPM4-8B-Eagle-FRSpec](https://www.modelscope.cn/models/OpenBMB/MiniCPM4-8B-Eagle-FRSpec) | | [MiniCPM4-8B-Eagle-FRSpec-QAT](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT) | [MiniCPM4-8B-Eagle-FRSpec-QAT](https://www.modelscope.cn/models/OpenBMB/MiniCPM4-8B-Eagle-FRSpec-QAT) | | [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM) | [MiniCPM4-8B-Eagle-vLLM](https://www.modelscope.cn/models/OpenBMB/MiniCPM4-8B-Eagle-vLLM) | | [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM) | [MiniCPM4-8B-marlin-Eagle-vLLM](https://www.modelscope.cn/models/OpenBMB/MiniCPM4-8B-marlin-Eagle-vLLM) | | [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey) | [MiniCPM4-Survey](https://www.modelscope.cn/models/OpenBMB/MiniCPM4-Survey) | | [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP) | [MiniCPM4-MCP](https://www.modelscope.cn/models/OpenBMB/MiniCPM4-MCP) | |[MiniCPM3-4B](https://huggingface.co/openbmb/MiniCPM3-4B)|[MiniCPM3-4B](https://www.modelscope.cn/models/OpenBMB/MiniCPM3-4B)| |[MiniCPM-2B-sft](https://huggingface.co/openbmb/MiniCPM-2B-sft-bf16)|[MiniCPM-2B-sft](https://modelscope.cn/models/OpenBMB/miniCPM-bf16)| |[MiniCPM-2B-dpo](https://huggingface.co/openbmb/MiniCPM-2B-dpo-bf16)|[MiniCPM-2B-dpo](https://modelscope.cn/models/OpenBMB/MiniCPM-2B-dpo-bf16/summary)| |[MiniCPM-2B-128k](https://huggingface.co/openbmb/MiniCPM-2B-128k) |[MiniCPM-2B-128k](https://modelscope.cn/models/openbmb/MiniCPM-2B-128k/summary)| |[MiniCPM-MoE-8x2B](https://huggingface.co/openbmb/MiniCPM-MoE-8x2B) |[MiniCPM-MoE-8x2B](https://modelscope.cn/models/OpenBMB/MiniCPM-MoE-8x2B)| |[MiniCPM-1B](https://huggingface.co/openbmb/MiniCPM-1B-sft-bf16) | [MiniCPM-1B](https://modelscope.cn/models/OpenBMB/MiniCPM-1B-sft-bf16) | |[MiniCPM-S-1B](https://huggingface.co/openbmb/MiniCPM-S-1B-sft)|[MiniCPM-S-1B](https://modelscope.cn/models/OpenBMB/MiniCPM-S-1B-sft)| Note: More model versions can be found [here](https://huggingface.co/collections/openbmb/minicpm-2b-65d48bf958302b9fd25b698f). ## MiniCPM 4.0 MiniCPM 4 is an extremely efficient edge-side large model that has undergone efficient optimization across four dimensions: model architecture, learning algorithms, training data, and inference systems, achieving ultimate efficiency improvements. - 🏗️ **Efficient Model Architecture:** - InfLLM v2 -- Trainable Sparse Attention Mechanism: Adopts a trainable sparse attention mechanism architecture where each token only needs to compute relevance with less than 5% of tokens in 128K long text processing, significantly reducing computational overhead for long texts - 🧠 **Efficient Learning Algorithms:** - Model Wind Tunnel 2.0 -- Efficient Predictable Scaling: Introduces scaling prediction methods for performance of downstream tasks, enabling more precise model training configuration search - BitCPM -- Ultimate Ternary Quantization: Compresses model parameter bit-width to 3 values, achieving 90% extreme model bit-width reduction - Efficient Training Engineering Optimization: Adopts FP8 low-precision computing technology combined with Multi-token Prediction training strategy - 📚 **High-Quality Training Data:** - UltraClean -- High-quality Pre-training Data Filtering and Generation: Builds iterative data cleaning strategies based on efficient data verification, open-sourcing high-quality Chinese and English pre-training dataset [UltraFinweb](https://huggingface.co/datasets/openbmb/Ultra-FineWeb) - UltraChat v2 -- High-quality Supervised Fine-tuning Data Generation: Constructs large-scale high-quality supervised fine-tuning datasets covering multiple dimensions including knowledge-intensive data, reasoning-intensive data, instruction-following data, long text understanding data, and tool calling data - ⚡ **Efficient Inference and Deployment System:** - CPM.cu -- Lightweight and Efficient CUDA Inference Framework: Integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. - ArkInfer -- Cross-platform Deployment System: Supports efficient deployment across multiple backend environments, providing flexible cross-platform adaptation capabilities ### Evaluation Results #### Efficiency Evaluation On two typical end-side chips, Jetson AGX Orin and RTX 4090, MiniCPM4 demonstrates significantly faster processing speed compared to similar-size models in long text processing tasks. As text length increases, MiniCPM4's efficiency advantage becomes more pronounced. On the Jetson AGX Orin platform, compared to Qwen3-8B, MiniCPM4 achieves approximately 7x decoding speed improvement. 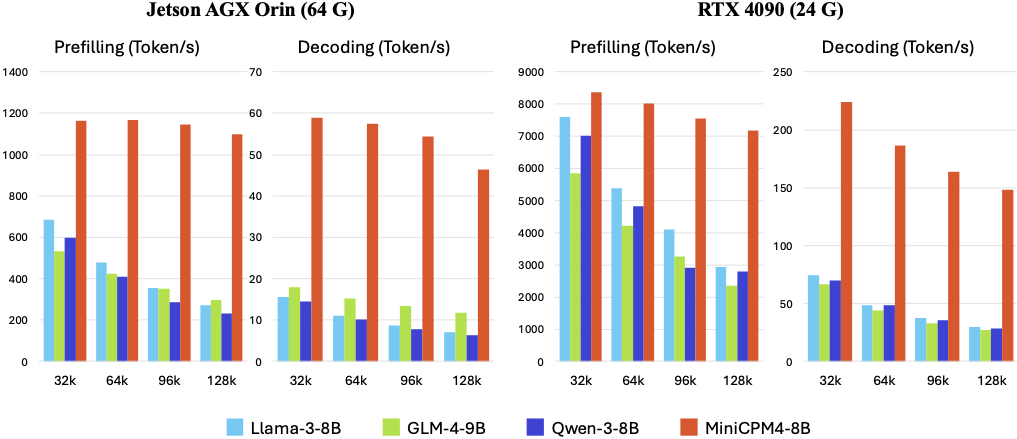 #### Comprehensive Evaluation MiniCPM4 launches end-side versions with 8B and 0.5B parameter scales, both achieving best-in-class performance in their respective categories. 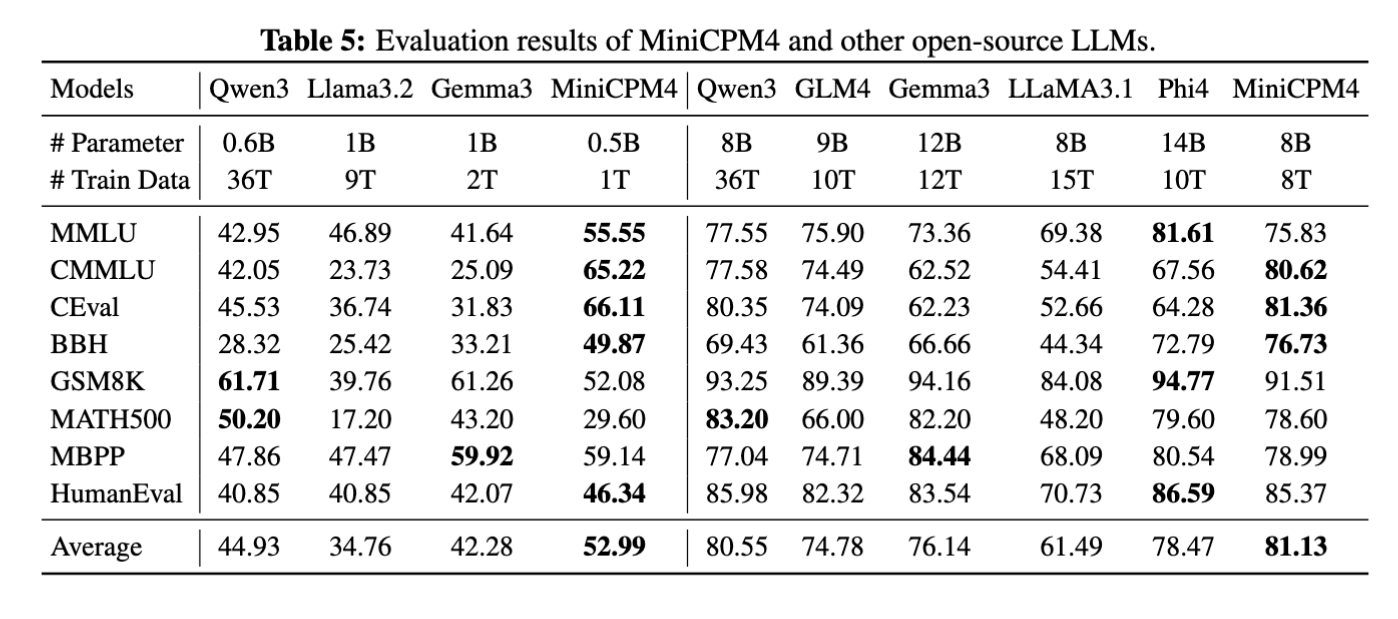 #### Long Text Evaluation MiniCPM4 is pre-trained on 32K long texts and achieves length extension through YaRN technology. In the 128K long text needle-in-a-haystack task, MiniCPM4 demonstrates outstanding performance. 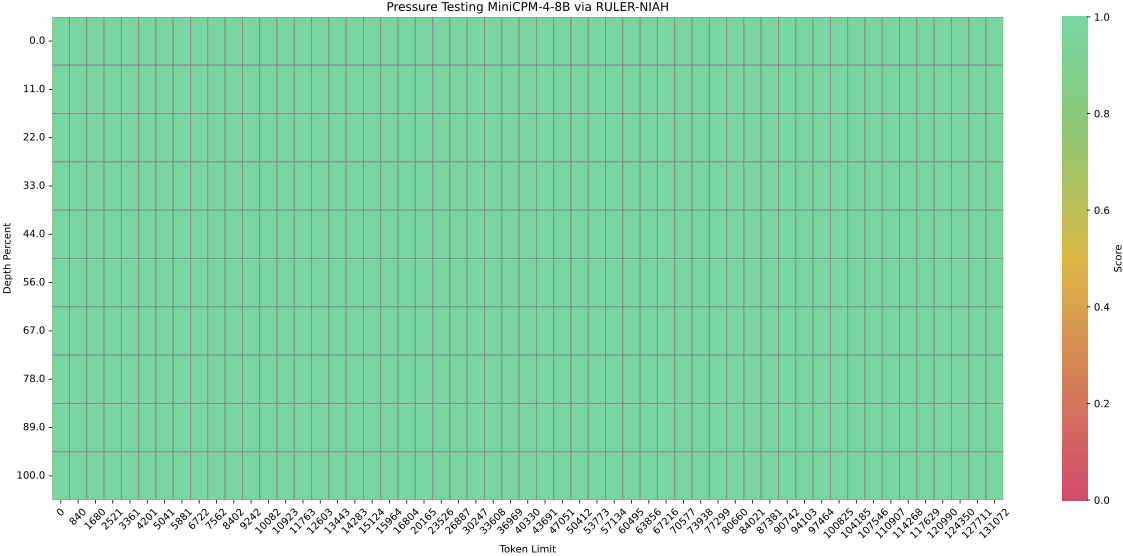 ### BitCPM4: Quantization BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency. - Improvements of the training method - Searching hyperparameters with a wind-tunnel on a small model. - Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase. - High parameter efficiency - Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency. #### BitCPM4 Evaluation BitCPM4's performance is comparable with other full-precision models in same model size. 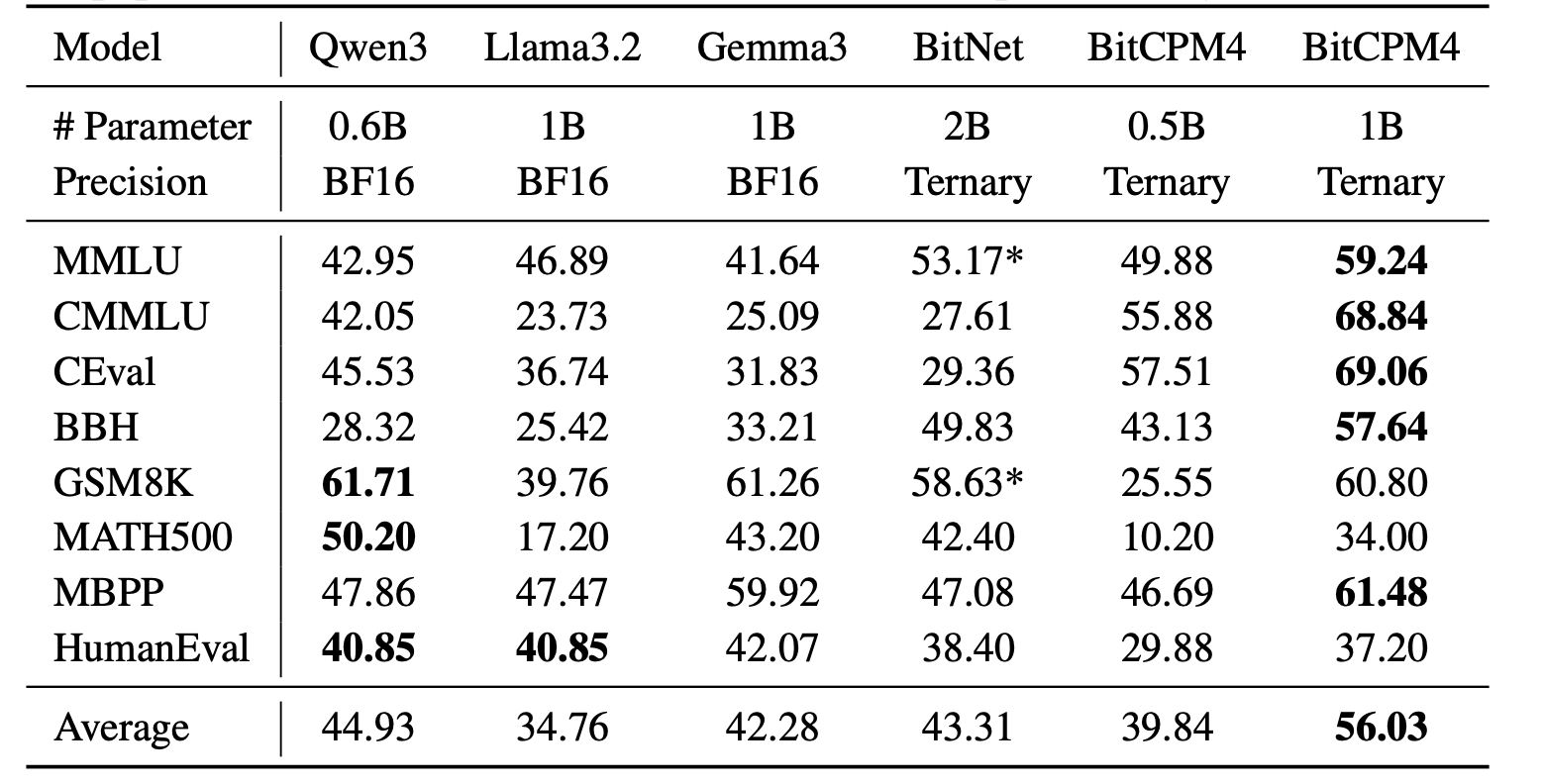 #### BitCPM4 Inference BitCPM4's parameters are stored in a fake-quantized format, which supports direct inference within the Huggingface framework. ### MiniCPM4 Application #### MiniCPM4-Survey: Trustworthy Survey Generation **MiniCPM4-Survey** is an open-source LLM agent model jointly developed by [THUNLP](https://nlp.csai.tsinghua.edu.cn), Renmin University of China and [ModelBest](https://modelbest.cn/en). Built on MiniCPM4-8B, it accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers. Key features include: - **Plan-Retrieve-Write Survey Generation Framework** — We propose a multi-agent generation framework, which operates through three core stages: planning (defining the overall structure of the survey), retrieval (generating appropriate retrieval keywords), and writing (synthesizing the retrieved information to generate coherent section-level content). - **High-Quality Dataset Construction** — We gather and process lots of expert-written survey papers to construct a high-quality training dataset. Meanwhile, we collect a large number of research papers to build a retrieval database. - **Multi-Aspect Reward Design** — We carefully design a reward system with three aspects (structure, content, and citations) to evaluate the quality of the surveys, which is used as the reward function in the RL training stage. - **Multi-Step RL Training Strategy** — We propose a *Context Manager* to ensure retention of essential information while facilitating efficient reasoning, and we construct *Parallel Environment* to maintain efficient RL training cycles. ##### Demo and Quick Start See [here](./demo/minicpm4/SurveyGeneration/README.md) ##### Performance Evaluation | Method | Relevance | Coverage | Depth | Novelty | Avg. | Fact Score | |---------------------------------------------|-----------|----------|-------|---------|-------|------------| | Naive RAG (driven by G2FT) | 3.25 | 2.95 | 3.35 | 2.60 | 3.04 | 43.68 | | AutoSurvey (driven by G2FT) | 3.10 | 3.25 | 3.15 | **3.15**| 3.16 | 46.56 | | Webthinker (driven by WTR1-7B) | 3.30 | 3.00 | 2.75 | 2.50 | 2.89 | -- | | Webthinker (driven by QwQ-32B) | 3.40 | 3.30 | 3.30 | 2.50 | 3.13 | -- | | OpenAI Deep Research (driven by GPT-4o) | 3.50 |**3.95** | 3.55 | 3.00 | **3.50** | -- | | MiniCPM-4-Survey | 3.45 | 3.70 | **3.85** | 3.00 | **3.50** | **68.73** | | *w/o* RL | **3.55** | 3.35 | 3.30 | 2.25 | 3.11 | 50.24 | *Performance comparison of the survey generation systems. "G2FT" stands for Gemini-2.0-Flash-Thinking, and "WTR1-7B" denotes Webthinker-R1-7B. FactScore evaluation was omitted for Webthinker, as it does not include citation functionality, and for OpenAI Deep Research, which does not provide citations when exporting the results.* #### MiniCPM4-MCP: Tool Use with Model Context Protocol **MiniCPM4-MCP** is an open-source on-device LLM agent model jointly developed by [THUNLP](https://nlp.csai.tsinghua.edu.cn), Renmin University of China and [ModelBest](https://modelbest.cn/en), built on [MiniCPM-4](https://huggingface.co/openbmb/MiniCPM4-8B) with 8 billion parameters. It is capable of solving a wide range of real-world tasks by interacting with various tool and data resources through MCP. As of now, MiniCPM4-MCP supports the following: - Utilization of tools across 16 MCP servers: These servers span various categories, including office, lifestyle, communication, information, and work management. - Single-tool-calling capability: It can perform single- or multi-step tool calls using a single tool that complies with the MCP. - Cross-tool-calling capability: It can perform single- or multi-step tool calls using different tools that complies with the MCP. ##### Demo Demo is available in this [link](./demo/minicpm4/MCP/README_en.md). ##### Performance Evaluation | MCP Server | | gpt-4o | | | qwen3 | | | minicpm4 | | |-----------------------|----------------|--------------|--------------|---------------|--------------|--------------|----------------|--------------|--------------| | | func | param | value | func | param | value | func | param | value | | Airbnb | 89.3 | 67.9 | 53.6 | 92.8 | 60.7 | 50.0 | 96.4 | 67.9 | 50.0 | | Amap-Maps | 79.8 | 77.5 | 50.0 | 74.4 | 72.0 | 41.0 | 89.3 | 85.7 | 39.9 | | Arxiv-MCP-Server | 85.7 | 85.7 | 85.7 | 81.8 | 54.5 | 50.0 | 57.1 | 57.1 | 52.4 | | Calculator | 100.0 | 100.0 | 20.0 | 80.0 | 80.0 | 13.3 | 100.0 | 100.0 | 6.67 | | Computor-Control-MCP | 90.0 | 90.0 | 90.0 | 90.0 | 90.0 | 90.0 | 90.0 | 90.0 | 86.7 | | Desktop-Commander | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | | Filesystem | 63.5 | 63.5 | 31.3 | 69.7 | 69.7 | 26.0 | 83.3 | 83.3 | 42.7 | |Github | 92.0 | 80.0 | 58.0 | 80.5 | 50.0 | 27.7 | 62.8 | 25.7 | 17.1 | | Gaode | 71.1 | 55.6 | 17.8 | 68.8 | 46.6 | 24.4 | 68.9 | 46.7 | 15.6 | | MCP-Code-Executor | 85.0 | 80.0 | 70.0 | 80.0 | 80.0 | 70.0 | 90.0 | 90.0 | 65.0 | | MCP-Docx | 95.8 | 86.7 | 67.1 | 94.9 | 81.6 | 60.1 | 95.1 | 86.6 | 76.1 | | PPT | 72.6 | 49.8 | 40.9 | 85.9 | 50.7 | 37.5 | 91.2 | 72.1 | 56.7 | | PPTx | 64.2 | 53.7 | 13.4 | 91.0 | 68.6 | 20.9 | 91.0 | 58.2 | 26.9 | | Simple-Time-Server | 90.0 | 70.0 | 70.0 | 90.0 | 90.0 | 90.0 | 90.0 | 60.0 | 60.0 | | Slack | 100.0 | 90.0 | 70.0 | 100.0 | 100.0 | 65.0 | 100.0 | 100.0 | 100.0 | | Whisper | 90.0 | 90.0 | 90.0 | 90.0 | 90.0 | 90.0 | 90.0 | 90.0 | 30.0 | | **Average** | **80.2** | **70.2** | **49.1** | **83.5** | **67.7** | **43.8** | **88.3** | **76.1** | **51.2** | #### MiniCPM Intel AIPC Client: A New Edge Large Model Powerhouse Developed in collaboration between Mianbi Intelligence and Intel, the MiniCPM Intel AIPC Client is an edge large model client specially designed for devices equipped with Intel Core Ultra series processors. It delivers a low-latency, high-efficiency, and privacy-preserving local large model experience for developers, researchers, and AI enthusiasts. Its core features include: ### Key Features - Deep Intel Hardware Adaptation Fully compatible with Intel Core Ultra series processors, enabling deep integration with hardware to unleash peak performance. Users can run large models smoothly on local devices without relying on cloud services. - Extreme Optimization Based on OpenVINO Deeply optimized with the OpenVINO inference framework, it significantly boosts inference efficiency, reaching up to **80 tokens per second**. This ensures rapid model response for both quick queries and complex task processing. - Privacy and Security Assurance Adopting local deployment, all data processing is completed on the device, eliminating privacy risks from cloud uploads. This provides users with peace of mind, especially for scenarios with high data privacy requirements. - Catering to Diverse User Groups Whether for developers chasing cutting-edge technologies, researchers focused on academic studies, or enthusiasts eager to explore AI applications, the MiniCPM Intel AIPC Client enables easy access to the power of local large models, opening the door to personalized AI exploration. ### System Requirements - Recommended processor: Intel Core Ultra 7 or higher (mobile version) - Recommended RAM: 32GB or above ### Download [download](https://github.com/OpenBMB/MiniCPM/releases/tag/2.4.2) ### Inference #### CPM.cu We **recommend** using [CPM.cu](https://github.com/OpenBMB/CPM.cu) for the inference of MiniCPM4. CPM.cu is a CUDA inference framework developed by OpenBMB, which integrates efficient sparse, speculative sampling, and quantization techniques, fully leveraging the efficiency advantages of MiniCPM4. You can install CPM.cu by running the following command: ```bash git clone https://github.com/OpenBMB/CPM.cu.git --recursive cd CPM.cu python3 setup.py install ``` You can run the following command to test the speed of the model. ```bash python3 tests/long_prompt_gen.py # generate prompt.txt python3 tests/test_generate.py --prompt-file prompt.txt ``` For more details about CPM.cu, please refer to the repo of [CPM.cu](https://github.com/OpenBMB/CPM.cu). #### HuggingFace ```python from transformers import AutoModelForCausalLM, AutoTokenizer import torch torch.manual_seed(0) path = 'openbmb/MiniCPM4-8B' device = "cuda" tokenizer = AutoTokenizer.from_pretrained(path) model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True) # User can directly use the chat interface # responds, history = model.chat(tokenizer, "Write an article about Artificial Intelligence.", temperature=0.7, top_p=0.7) # print(responds) # User can also use the generate interface messages = [ {"role": "user", "content": "Write an article about Artificial Intelligence."}, ] prompt_text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, ) model_inputs = tokenizer([prompt_text], return_tensors="pt").to(device) model_outputs = model.generate( **model_inputs, max_new_tokens=1024, top_p=0.7, temperature=0.7 ) output_token_ids = [ model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs['input_ids'])) ] responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0] print(responses) ``` This model supports InfLLM v2, a sparse attention mechanism designed for efficient long-sequence inference. It requires the [infllmv2_cuda_impl](https://github.com/OpenBMB/infllmv2_cuda_impl) library. You can install it by running the following command: ```bash git clone -b feature_infer https://github.com/OpenBMB/infllmv2_cuda_impl.git cd infllmv2_cuda_impl git submodule update --init --recursive pip install -e . # or python setup.py install ``` To enable InfLLM v2, you need to add the `sparse_config` field in `config.json`: ```json { ..., "sparse_config": { "kernel_size": 32, "kernel_stride": 16, "init_blocks": 1, "block_size": 64, "window_size": 2048, "topk": 64, "use_nope": false, "dense_len": 8192 } } ``` These parameters control the behavior of InfLLM v2: * `kernel_size` (default: 32): The size of semantic kernels. * `kernel_stride` (default: 16): The stride between adjacent kernels. * `init_blocks` (default: 1): The number of initial blocks that every query token attends to. This ensures attention to the beginning of the sequence. * `block_size` (default: 64): The block size for key-value blocks. * `window_size` (default: 2048): The size of the local sliding window. * `topk` (default: 64): The specifies that each token computes attention with only the top-k most relevant key-value blocks. * `use_nope` (default: false): Whether to use the NOPE technique in block selection for improved performance. * `dense_len` (default: 8192): Since Sparse Attention offers limited benefits for short sequences, the model can use standard (dense) attention for shorter texts. The model will use dense attention for sequences with a token length below `dense_len` and switch to sparse attention for sequences exceeding this length. Set this to `-1` to always use sparse attention regardless of sequence length. Minicpm4 natively supports context lengths of up to 32,768 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques for effective handling of long texts. We have validated the model's performance on context lengths of up to 131,072 tokens by modifying the LongRoPE factor. You can apply the LongRoPE factor modification by modifying the model files. Specifically, in the `config.json` file, adjust the `rope_scaling` fields. ```json { ..., "rope_scaling": { "rope_type": "longrope", "long_factor": [0.9977997200264581, 1.014658295992452, 1.0349680404997148, 1.059429246056193, 1.0888815016813513, 1.1243301355211495, 1.166977103606075, 1.2182568066927284, 1.2798772354275727, 1.3538666751582975, 1.4426259039919596, 1.5489853358570191, 1.6762658237220625, 1.8283407612492941, 2.0096956085876183, 2.225478927469756, 2.481536379650452, 2.784415934557119, 3.1413289096347365, 3.560047844772632, 4.048719380066383, 4.752651957515948, 5.590913044973868, 6.584005926629993, 7.7532214876576155, 9.119754865903639, 10.704443927019176, 12.524994176518703, 14.59739595363613, 16.93214476166354, 19.53823297353041, 22.417131025031697, 25.568260840911098, 28.991144156566317, 32.68408069090375, 36.65174474170465, 40.90396065611201, 45.4664008671033, 50.37147343433591, 55.6804490772103, 61.470816952306556, 67.8622707390618, 75.00516023410414, 83.11898235973767, 92.50044360202462, 103.57086856690864, 116.9492274587385, 118.16074567836519, 119.18497548708795, 120.04810876261652, 120.77352815196981, 121.38182790207875, 121.89094985353891, 122.31638758099915, 122.6714244963338, 122.9673822552567, 123.21386397019609, 123.41898278254268, 123.58957065488238, 123.73136519024158, 123.84917421274221, 123.94701903496814, 124.02825801299717, 124.09569231686116], "short_factor": [0.9977997200264581, 1.014658295992452, 1.0349680404997148, 1.059429246056193, 1.0888815016813513, 1.1243301355211495, 1.166977103606075, 1.2182568066927284, 1.2798772354275727, 1.3538666751582975, 1.4426259039919596, 1.5489853358570191, 1.6762658237220625, 1.8283407612492941, 2.0096956085876183, 2.225478927469756, 2.481536379650452, 2.784415934557119, 3.1413289096347365, 3.560047844772632, 4.048719380066383, 4.752651957515948, 5.590913044973868, 6.584005926629993, 7.7532214876576155, 9.119754865903639, 10.704443927019176, 12.524994176518703, 14.59739595363613, 16.93214476166354, 19.53823297353041, 22.417131025031697, 25.568260840911098, 28.991144156566317, 32.68408069090375, 36.65174474170465, 40.90396065611201, 45.4664008671033, 50.37147343433591, 55.6804490772103, 61.470816952306556, 67.8622707390618, 75.00516023410414, 83.11898235973767, 92.50044360202462, 103.57086856690864, 116.9492274587385, 118.16074567836519, 119.18497548708795, 120.04810876261652, 120.77352815196981, 121.38182790207875, 121.89094985353891, 122.31638758099915, 122.6714244963338, 122.9673822552567, 123.21386397019609, 123.41898278254268, 123.58957065488238, 123.73136519024158, 123.84917421274221, 123.94701903496814, 124.02825801299717, 124.09569231686116], "original_max_position_embeddings": 32768 } } ``` #### vLLM - Install vLLM Reference vLLM [official repository](https://github.com/vllm-project/vllm), install the latest version through *source code*. ``` pip install -U vllm \ --pre \ --extra-index-url https://wheels.vllm.ai/nightly ``` - Inference MiniCPM4-8B with vLLM: ```python from transformers import AutoTokenizer from vllm import LLM, SamplingParams model_name = "openbmb/MiniCPM4-8B" prompt = [{"role": "user", "content": "Please recommend 5 tourist attractions in Beijing. "}] tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) input_text = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True) llm = LLM( model=model_name, trust_remote_code=True, max_num_batched_tokens=32768, dtype="bfloat16", gpu_memory_utilization=0.8, ) sampling_params = SamplingParams(top_p=0.7, temperature=0.7, max_tokens=1024, repetition_penalty=1.02) outputs = llm.generate(prompts=input_text, sampling_params=sampling_params) print(outputs[0].outputs[0].text) ``` - Use Eagle Speculative Decoding in vLLM: initialize the inference engine as follows. ```python llm = LLM( model=model_name, trust_remote_code=True, max_num_batched_tokens=32768, dtype="bfloat16", gpu_memory_utilization=0.8, speculative_config={ "method": "eagle", "model": "openbmb/MiniCPM4-8B-Eagle-vLLM", "num_speculative_tokens": 2, "max_model_len": 32768, }, ) ``` - Inference quantized MiniCPM4-8B: initialize the inference engine as follows. ```python llm = LLM( model="openbmb/MiniCPM4-8B-marlin-vLLM", trust_remote_code=True, max_num_batched_tokens=32768, dtype="bfloat16", gpu_memory_utilization=0.8, ) ``` - Use Eagle Speculative Decoding for quantized MiniCPM4-8B: initialize the inference engine as follows. ```python llm = LLM( model="openbmb/MiniCPM4-8B-marlin-vLLM", trust_remote_code=True, max_num_batched_tokens=32768, dtype="bfloat16", gpu_memory_utilization=0.8, speculative_config={ "method": "eagle", "model": "openbmb/MiniCPM4-8B-marlin-Eagle-vLLM", "num_speculative_tokens": 2, "max_model_len": 32768, }, ) ``` > **Note**: If you're using an OpenAI-compatible server in vLLM, the `chat` API sets `add_special_tokens=False` by default. This will result in missing special tokens—such as the beginning-of-sequence (BOS) token—which are required for proper prompt formatting in **MiniCPM4**. To ensure correct behavior, you must explicitly set `extra_body={"add_special_tokens": True}` in your API call, like below: ```python import openai client = openai.Client(base_url="http://localhost:8000/v1", api_key="EMPTY") response = client.chat.completions.create( model="openbmb/MiniCPM4-8B", messages=[ {"role": "user", "content": "Write an article about Artificial Intelligence."}, ], temperature=0.7, max_tokens=1024, extra_body={"add_special_tokens": True}, # Ensures special tokens like BOS are added ) print(response.choices[0].message.content) ``` #### SGLang - Install SGLang Reference SGLang [official repository](https://github.com/sgl-project/sglang), install through *source code*. ``` git clone -b openbmb https://github.com/sgl-project/sglang.git cd sglang pip install --upgrade pip pip install -e "python[all]" ``` - Start inference service ```shell python -m sglang.launch_server --model openbmb/MiniCPM4-8B --trust-remote-code --port 30000 --chat-template chatml ``` - Then, users can use the chat interface by running the following command: ```python import openai client = openai.Client(base_url=f"http://localhost:30000/v1", api_key="None") response = client.chat.completions.create( model="openbmb/MiniCPM4-8B", messages=[ {"role": "user", "content": "Write an article about Artificial Intelligence."}, ], temperature=0.7, max_tokens=1024, ) print(response.choices[0].message.content) ``` - Use speculative acceleration ```shell python3 -m sglang.launch_server --model-path [model] \ --speculative_draft_model_path [draft_model] \ --host 0.0.0.0 --trust-remote-code \ --speculative-algorithm EAGLE --speculative-num-steps 1 --speculative-eagle-topk 1 --speculative-num-draft-tokens 2 \ --mem-fraction 0.5 ``` ## MiniCPM 3.0| Benchmarks | Qwen2-7B-Instruct | GLM-4-9B-Chat | Gemma2-9B-it | Llama3.1-8B-Instruct | GPT-3.5-Turbo-0125 | Phi-3.5-mini-Instruct(3.8B) | MiniCPM3-4B | |||||||
| English | ||||||||||||||
| MMLU | 70.5 | 72.4 | 72.6 | 69.4 | 69.2 | 68.4 | 67.2 | |||||||
| BBH | 64.9 | 76.3 | 65.2 | 67.8 | 70.3 | 68.6 | 70.2 | |||||||
| MT-Bench | 8.41 | 8.35 | 7.88 | 8.28 | 8.17 | 8.60 | 8.41 | |||||||
| IFEVAL (Prompt Strict-Acc.) | 51.0 | 64.5 | 71.9 | 71.5 | 58.8 | 49.4 | 68.4 | |||||||
| Chinese | ||||||||||||||
| CMMLU | 80.9 | 71.5 | 59.5 | 55.8 | 54.5 | 46.9 | 73.3 | |||||||
| CEVAL | 77.2 | 75.6 | 56.7 | 55.2 | 52.8 | 46.1 | 73.6 | |||||||
| AlignBench v1.1 | 7.10 | 6.61 | 7.10 | 5.68 | 5.82 | 5.73 | 6.74 | |||||||
| FollowBench-zh (SSR) | 63.0 | 56.4 | 57.0 | 50.6 | 64.6 | 58.1 | 66.8 | |||||||
| Mathematics | ||||||||||||||
| MATH | 49.6 | 50.6 | 46.0 | 51.9 | 41.8 | 46.4 | 46.6 | |||||||
| GSM8K | 82.3 | 79.6 | 79.7 | 84.5 | 76.4 | 82.7 | 81.1 | |||||||
| MathBench | 63.4 | 59.4 | 45.8 | 54.3 | 48.9 | 54.9 | 65.6 | |||||||
| Coding | ||||||||||||||
| HumanEval+ | 70.1 | 67.1 | 61.6 | 62.8 | 66.5 | 68.9 | 68.3 | |||||||
| MBPP+ | 57.1 | 62.2 | 64.3 | 55.3 | 71.4 | 55.8 | 63.2 | |||||||
| LiveCodeBench v3 | 22.2 | 20.2 | 19.2 | 20.4 | 24.0 | 19.6 | 22.6 | |||||||
| Tool Use | ||||||||||||||
| BFCL v2 | 71.6 | 70.1 | 19.2 | 73.3 | 75.4 | 48.4 | 76.0 | |||||||
| Overall | ||||||||||||||
| Average | 65.3 | 65.0 | 57.9 | 60.8 | 61.0 | 57.2 | 66.3 | |||||||
| Model | Overall Accuracy | AST Summary | Exec Summary | Irrelevance Detection | Relevance Detection |
| MiniCPM3-4B | 76.03% | 68.55% | 85.54% | 53.71% | 90.24% |
| Llama3.1-8B-Instruct | 73.28% | 64.61% | 86.48% | 43.12% | 85.37% |
| Qwen2-7B-Instruct | 71.61% | 65.71% | 79.57% | 44.70% | 90.24% |
| GLM-4-9B-Chat | 70.08% | 60.69% | 80.02% | 55.02% | 82.93% |
| Phi-3.5-mini-instruct | 48.44% | 38.89% | 54.04% | 46.78% | 65.85% |
| Gemma2-9B-it | 19.18% | 5.41% | 18.50% | 88.88% | 7.32% |
| Model | BBH | MMLU | CEval | CMMLU | HumanEval | MBPP† | GSM8K | MATH |
|---|---|---|---|---|---|---|---|---|
| Llama2-34B* | 44.1 | 62.6 | - | - | 22.6 | 33.0 | 42.2 | 6.24 |
| Mistral-7B-Instruct-v0.2 | 39.81 | 60.51 | 42.55 | 41.92 | 36.59 | 39.63 | 40.49 | 4.95 |
| Gemma-7B* | 55.1 | 64.3 | - | - | 32.3 | 44.4 | 46.4 | 24.3 |
| Qwen1.5-7B* | 40.2 | 61 | 74.1 | 73.1 | 36 | 37.4 | 62.5 | 20.3 |
| Deepseek-MoE(16B)* | - | 45.0 | 40.6 | 42.5 | 26.8 | 39.2 | 18.8 | 4.3 |
| MiniCPM-2.4B | 36.87 | 53.46 | 51.13 | 51.07 | 50.00 | 35.93 | 53.83 | 10.24 |
| MiniCPM-MoE-8x2B | 39.22 | 58.90 | 58.11 | 58.80 | 55.49 | 41.68 | 61.56 | 10.52 |
 [Modelbest Inc.](https://modelbest.cn/)
-
[Modelbest Inc.](https://modelbest.cn/)
-  [THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-
[THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-  [Gaoling School of Artificial Intelligence of RUC](https://linyankai.github.io/)
## Citation
* Please cite our paper: [MiniCPM1](https://arxiv.org/abs/2404.06395) and [MiniCPM4](https://github.com/OpenBMB/MiniCPM/blob/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
```
@article{minicpm4,
title={MiniCPM4: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
@inproceedings{huminicpm,
title={MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies},
author={Hu, Shengding and Tu, Yuge and Han, Xu and Cui, Ganqu and He, Chaoqun and Zhao, Weilin and Long, Xiang and Zheng, Zhi and Fang, Yewei and Huang, Yuxiang and others},
booktitle={First Conference on Language Modeling},
year={2024}
}
```
[Gaoling School of Artificial Intelligence of RUC](https://linyankai.github.io/)
## Citation
* Please cite our paper: [MiniCPM1](https://arxiv.org/abs/2404.06395) and [MiniCPM4](https://github.com/OpenBMB/MiniCPM/blob/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
```
@article{minicpm4,
title={MiniCPM4: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
@inproceedings{huminicpm,
title={MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies},
author={Hu, Shengding and Tu, Yuge and Han, Xu and Cui, Ganqu and He, Chaoqun and Zhao, Weilin and Long, Xiang and Zheng, Zhi and Fang, Yewei and Huang, Yuxiang and others},
booktitle={First Conference on Language Modeling},
year={2024}
}
```