system_prompt_template="""You are an AI Agent who is proficient in solve complicated task.
Each step you should wirte executable code to fulfill user query. Any Response without code means the task is completed and you do not have another chance to submit code
You are equipped with a codeinterpreter. You can give the code and get the execution result of your code. You should use the codeinterpreter in the following format:
<|execute_start|>
```python
<your code>
```
<|execute_end|>
WARNING:Do not use cv2.waitKey(0) cv2.destroyAllWindows()!!! Or the program will be destoried
Each round, your answer should ALWAYS use the following format(Each of your response should contain code, until you complete the task):
Analyse:(Analyse the message you received and plan what you should do)
This Step Todo: One Subtask need to be done at this step
Code(WARNING:MAKE SURE YOU CODE FOLLOW THE FORMAT AND WRITE CODE OR THE TASK WILL BE FAILED):
<|execute_start|>
```python
<your code>
```
<|execute_end|>
You will got the result of your code after each step. When the code of previous subtask is excuted successfully, you can write and excuet the code for next subtask
When all the code your write are executed and you got the code result that can fulfill the user query, you should summarize the previous analyse process and make a formal response to user, The response should follow this format:
WARNING:MAKE SURE YOU GET THE CODE EXECUTED RESULT THAT FULFILLED ALL REQUIREMENT OF USER BEFORE USE "Finished"
Finished: <Answer to user query>
Some notice:
1. When you want to draw a plot, use plt.savefig() and print the image path in markdown format instead of plt.show()
2. Save anything to ./output folder
3. End the process whenever you complete the task, When you do not have Action(Code), Use: Finished: <summary the analyse process and make response>
4. Do not ask for user input in your python code.
"""
defexecute_code(code):
stdout_capture=io.StringIO()
stderr_capture=io.StringIO()
# Note here we simplely imitate notebook output.
# if you want to run more complex tasks, try to use nbclient to run python code
"description":"Get the delivery date for a customer's order. Call this whenever you need to know the delivery date, for example when a customer asks 'Where is my package'",
"parameters":{
"type":"object",
"properties":{
"order_id":{
"type":"string",
"description":"The customer's order ID.",
},
},
"required":["order_id"],
"additionalProperties":False,
},
},
}
]
messages=[
{
"role":"system",
"content":"You are a helpful customer support assistant. Use the supplied tools to assist the user.",
},
{
"role":"user",
"content":"Hi, can you tell me the delivery date for my order? The order id is 1234 and 4321.",
{%- set param_default = param_fields.default|tojson if param_fields.default is string else param_fields.default|string if param_fields.default is defined else 'None' %}
{%- set o_ns.f = o_ns.f + ('Optional[' + json_to_python_type(param_name, param_fields) + ']' if param_name not in json_spec.required else json_to_python_type(param_name, param_fields)) %}
{%- if not param_fields.title and not param_fields.description and not param_fields.pattern %}
{%- set o_ns.f = o_ns.f + (' = ' + param_default if param_name not in json_spec.required else '') %}
{%- else %}
{%- set o_ns.f = o_ns.f + (' = Field(...' if param_name in json_spec.required else ' = Field(' + param_default) %}
{%- set o_ns.f = o_ns.f + (', description=' + param_fields.description|tojson if param_fields.description else '') %}
{%- set o_ns.f = o_ns.f + (', regex=' + param_fields.pattern|tojson if param_fields.pattern else '') %}
{%- set o_ns.f = o_ns.f + (', title=' + param_fields.title|tojson if param_fields.title else '') %}
{%- set o_ns.f = o_ns.f + ')' %}
{%- endif %}
{%- set o_ns.f = o_ns.f + '\n' %}
{%- endfor %}
{{- o_ns.f }}
{%- endmacro %}
{%- macro tool_parser(tools) %}
{%- for tool in tools %}
{%- if tool.type is not defined or tool.type == 'function' %}
{%- if tool.function is defined %}
{%- set tool = tool.function %}
{%- endif %}
{%- set tool_params = tool.parameters if tool.parameters is defined else none %}
{%- call object_to_fields(tool_params, ' ') %}
{{- '\n\ndef ' + tool.name + '(' }}
{%- if tool_params %}
{%- for param_name, param_fields in tool_params.properties|items %}
{%- set param_default = param_fields.default|tojson if param_fields.default is string else param_fields.default|string if param_fields.default is defined else 'None' %}
{{- ', ' if loop.index0 != 0 }}
{{- param_name }}
{{- '=' + param_default if param_name not in tool_params.required }}
{%- endfor %}
{%- endif %}
{{- '):\n """' }}
{{- tool.description }}
{{- '\n\n Args:\n' if tool_params else '\n' }}
{%- endcall %}
{{- ' """\n' }}
{%- endif %}
{%- endfor %}
{%- endmacro %}
{%- if messages[0]['role'] == 'system' %}
{%- set loop_messages = messages[1:] %}
{%- set system_message = messages[0]['content'] %}
{%- else %}
{%- set loop_messages = messages %}
{%- set system_message = '' %}
{%- endif %}
{{- '<|im_start|>system\n' + system_message if system_message or tools }}
{%- if tools %}
{{- '\n# Functions\nHere is a list of functions that you can invoke:\n```python\nfrom enum import Enum\nfrom typing import List, Dict, Optional\nfrom pydantic import BaseModel, Field\n\n' }}
{{- tool_parser(tools) }}
{{- "\n```\n\n# Function Call Rule and Output Format\n- If the user's question can be answered without calling any function, please answer the user's question directly. In this situation, you should return your thought and answer the user's question directly.\n- If the user cannot be answered without calling any function, and the user does not provide enough information to call functions, please ask the user for more information. In this situation, you should return your thought and ask the user for more information.\n- If the user's question cannot be answered without calling any function, and the user has provided enough information to call functions to solve it, you should call the functions. In this situation, the assistant should return your thought and call the functions.\n- Use default parameters unless the user has specified otherwise.\n- You should answer in the following format:\n\n<|thought_start|>\n{explain why the user's question can be answered without calling a function or why you should ask the user for more information or why you should call one or more functions and your plan to solve the user's question.}\n<|thought_end|>\n<|tool_call_start|>\n```python\nfunc1(params_name=params_value, params_name2=params_value2...)\nfunc2(params)\n```\n<|tool_call_end|>\n{answer the user's question directly or ask the user for more information}" }}
{%- endif %}
{{- '<|im_end|>\n' if system_message or tools }}
{%- for message in loop_messages %}
{%- set content = message.content %}
{%- if message.role == 'assistant' and message.tool_calls %}
{{- '<|im_start|>' + message.role + '\n' }}
{{- '<|thought_start|>\n' + message.thought + '\n<|thought_end|>\n' if message.thought }}
{{- '<|tool_call_start|>\n```python\n' }}
{%- for tool_call in message.tool_calls %}
{%- if tool_call.function is defined %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- tool_call.name + '(' }}
{%- if tool_call.arguments is defined and tool_call.arguments|length > 0 %}
{%- for param_name, param_value in tool_call.arguments|items %}
{{- param_name + '=' + param_value|tojson }}
{{- ',' if not loop.last }}
{%- endfor %}
{%- endif %}
{{- ')\n' }}
{%- endfor %}
{{- '```\n<|tool_call_end|>\n' }}
{{- content if content and not content.startswith('<|tool_call_start|>') }}
{{- '<|im_end|>\n' }}
{%- elif message.role == 'assistant' and message.thought %}
* [2025-06-05] 🚀🚀🚀 We have open-sourced MiniCPM4-MCP, built on MiniCPM4-8B, which is capable of calling a variety of MCP tools and delivers performance comparable to larger models.
## 🚩 Overview
**MiniCPM4-MCP** is an open-source on-device LLM agent model jointly developed by [THUNLP](https://nlp.csai.tsinghua.edu.cn), Renmin University of China and [ModelBest](https://modelbest.cn/en), built on [MiniCPM-4](https://huggingface.co/openbmb/MiniCPM4-8B) with 8 billion parameters. It is capable of solving a wide range of real-world tasks by interacting with various tool and data resources through MCP. As of now, MiniCPM4-MCP supports the following:
- Utilization of tools across 16 MCP servers: These servers span various categories, including office, lifestyle, communication, information, and work management.
- Single-tool-calling capability: It can perform single- or multi-step tool calls using a single tool that complies with the MCP.
- Cross-tool-calling capability: It can perform single- or multi-step tool calls using different tools that complies with the MCP.
The required package versions are listed in `./requirements.txt` to ensure compatibility.
```
pip install -r requirements.txt
```
## 📽️ Training
We primarily adopt a learning-from-demonstration approach to train our model. The demonstrations are generated through continuous interactions between an LLM and the MCP environment. MiniCPM learns from these demonstrations through Supervised Fine-Tuning (SFT). We employ LLaMa-Factory as our SFT framework, with an adapted version for MiniCPM.
### Model Download
Download the model in this [link](https://huggingface.co/openbmb/MiniCPM4-MCP).
### Data Format
```json
{
"conversations":[
{"from":"human","value":"Hi, I need to convert 500 US dollars to Euros. Can you help me with that?"},
{"from":"gpt","value":"<|thought_start|>\nI will call the get_currency_exchange_rate function to convert 500 US dollars to Euros.\n<|thought_end|>\n<|tool_call_start|>\n```python\nget_currency_exchange_rate(from_currency=\"USD\",to_currency=\"EUR\",amount=500)\n```\n<|tool_call_end|>\n"},
{"from":"gpt","value":"<|thought_start|>\nThe assistant thought that the user asked for a currency conversion, which is a task that can be handled by the 'get_currency_exchange_rate' function, and the assistant has received the necessary parameters to execute this function.\n<|thought_end|>\nSure, 500 US dollars will convert to approximately 425.50 Euros. The current exchange rate is 0.851."}
],
"tools":"[{\"name\": \"get_currency_exchange_rate\", \"description\": \"Get the exchange rate between two currencies\", \"parameters\": {\"type\": \"object\", \"properties\": {\"from_currency\": {\"type\": \"string\", \"description\": \"The currency to convert from\"}, \"to_currency\": {\"type\": \"string\", \"description\": \"The currency to convert to\"}, \"amount\": {\"type\": \"number\", \"description\": \"The amount to convert\"}}, \"required\": [\"from_currency\", \"to_currency\", \"amount\"]}}, {\"name\": \"generate_random_password\", \"description\": \"Generate a random password with specified requirements\", \"parameters\": {\"type\": \"object\", \"properties\": {\"length\": {\"type\": \"integer\", \"description\": \"The length of the password\"}, \"include_numbers\": {\"type\": \"boolean\", \"description\": \"Include numbers in the password\"}, \"include_symbols\": {\"type\": \"boolean\", \"description\": \"Include symbols in the password\"}}, \"required\": [\"length\"]}}]",
"system":"You are a helpful assistant with access to some functions. Use them if required."}
```
### Single-Node Training
To run training on a single machine, simply use the following command:
[Slack](https://github.com/modelcontextprotocol/servers-archived/tree/main/src/slack), and
[Whisper](https://github.com/arcaputo3/mcp-server-whisper). Follow the instructions provided in each server's repository for successful deployment. Note that not all tools in these servers will function properly in every environment. Some tools are unstable and may return errors such as timeouts or HTTP errors. During training data construction, tools with consistently high failure rates (e.g., those for which the LLM fails to produce a successful query even after hundreds of attempts) are filtered out.
### MCP Client Setup
We modified the existing MCP Client from the [mcp-cli](https://github.com/chrishayuk/mcp-cli) repository to enable interaction between MiniCPM and MCP Servers.
After the MCP Client performs a handshake with a Server, it retrieves a list of available tools. An example of tool information contained in this list is provided in `available_tool_example.json`.
Once the available tools and user query are obtained, results can be generated using the following script logic:
```bash
python generate_example.py \
--tokenizer_path{path to MiniCPM4 tokenizer}\
--base_url{vllm deployment URL}\
--model{model name used in vllm deployment}\
--output_path{path to save results}
```
where MiniCPM4 generates tool calls in the following format:
```
<|tool_call_start|>
```python
read_file(path="/path/to/file")
```
<|tool_call_end|>
```
You can build a custom parser for MiniCPM4 tool calls based on this format. The relevant parsing logic is located in `generate_example.py`.
Since the [mcp-cli](https://github.com/chrishayuk/mcp-cli) repository supports the vLLM inference framework, MiniCPM4-MCP can also be integrated into `mcp-cli` by modifying vLLM accordingly.
Specifically, follow the instructions in [this link](https://github.com/OpenBMB/MiniCPM/tree/main/demo/minicpm3/function_call) to enable interaction between a client running the MiniCPM4-MCP model and the MCP Server.
## 📈 Evaluation
Once generation is complete, run the following example evaluation script:
```bash
python eval_scripts.py \
--input_path{path where the results generated by `generate` are saved}
```
This script is used to evaluate the model's performance in predicting function names during single-turn tool calls. In multi-turn scenarios, the accuracy of the tool call generated at the current step can be evaluated by providing the ground-truth information from previous steps. The evaluation logic for each step is the same as that of the single-turn setting.
"content":"You are an intelligent assistant with access to various tools. Your task is to answer questions by using these tools when needed.\n\nCRITICAL INSTRUCTIONS:\n\n1. Tool use is expected and encouraged, especially when information cannot be inferred from the conversation context. However, if you have gathered enough information to confidently provide the final answer, you may do so directly — but only after tool usage has been attempted or proven unnecessary.\n\n2. DO NOT describe or talk about using tools — actually CALL them using the tool_calls mechanism.\n\n3. NEVER fabricate answers. Always rely on tool results or clearly indicate when no useful result is available.\n\n4. If a tool returns an error OR fails to provide useful or new information (e.g., empty results, no content, or repeated output), DO NOT call it again with the same inputs. Avoid repeating the same failed tool calls. If a tool fails, try alternative tools if available.\n\n5. You MUST consider previous tool_calls and tool responses when deciding what to do next. Use this history to avoid redundant or circular behavior.\n\n6. If ALL relevant tools have been tried and none provide helpful results, you may gracefully end the conversation with a best-effort response, acknowledging that tools did not yield a definitive answer.\n\n7. When delivering the final answer, use the following format:\n - First provide a concise analysis or summary of your reasoning and tool findings.\n - Then end with: **\"The answer is: [your final answer]\"**\n\nTECHNICAL DETAILS:\n\n- For any step involving tool use, your response must include a \"tool_calls\" field.\n- The only valid response without tool_calls is when delivering the FINAL ANSWER after attempting or ruling out tool usage.\n\nEXAMPLES OF ACCEPTABLE BEHAVIOR:\n- Trying a tool, analyzing the response, and choosing a different tool when appropriate.\n- Avoiding re-use of failed tool calls by checking prior results.\n- Stopping and concluding if all tool paths have been exhausted.\n\nNEVER:\n- Repeat failed tool calls unnecessarily.\n- Respond with general knowledge if tools are required to verify the answer.\n\nRemember: your goal is to reason with tool assistance. Use tools thoughtfully and adaptively to solve the user's question.\n "
},
{
"role":"user",
"content":"I'm searching for movie theaters in Hangzhou and wondering about the weather forecast for this evening."
},
{
"role":"assistant",
"content":"<|tool_call_start|>\n```python\nsearchPOI(city=\"杭州\",extensions=\"base\",keywords=\"电影院\")\n```\n<|tool_call_end|>\nI'll help you find movie theaters in Hangzhou and check the weather forecast for this evening. Let me gather that information for you."
* [2025-06-05] 🚀🚀🚀 We have open-sourced **MiniCPM4-Survey**, a model built upon MiniCPM4-8B that is capable of generating trustworthy, long-form survey papers while maintaining competitive performance relative to significantly larger models.
## Overview
**MiniCPM4-Survey** is an open-source LLM agent model jointly developed by [THUNLP](https://nlp.csai.tsinghua.edu.cn), Renmin University of China and [ModelBest](https://modelbest.cn/en). Built on [MiniCPM4](https://github.com/OpenBMB/MiniCPM4) with 8 billion parameters, it accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
Key features include:
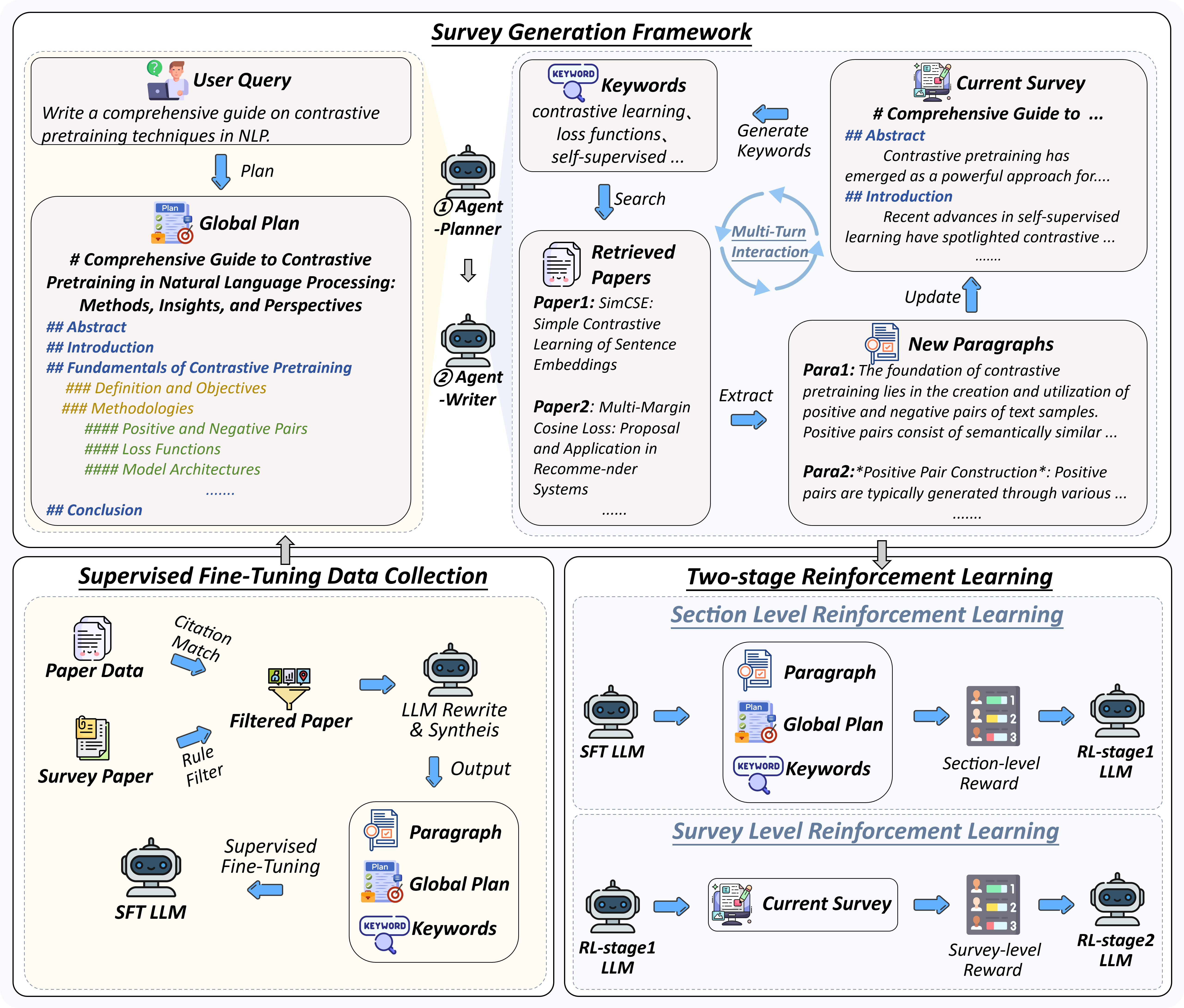
-**Plan-Retrieve-Write Survey Generation Framework** — We propose a multi-agent generation framework, which operates through three core stages: planning (defining the overall structure of the survey), retrieval (generating appropriate retrieval keywords), and writing (synthesizing the retrieved information to generate coherent section-level content).
-**High-Quality Dataset Construction** — We gather and process lots of expert-written survey papers to construct a high-quality training dataset. Meanwhile, we collect a large number of research papers to build a retrieval database.
-**Multi-Aspect Reward Design** — We carefully design a reward system with three aspects (structure, content, and citations) to evaluate the quality of the surveys, which is used as the reward function in the RL training stage.
-**Multi-Step RL Training Strategy** — We propose a *Context Manager* to ensure retention of essential information while facilitating efficient reasoning, and we construct *Parallel Environment* to maintain efficient RL training cycles.
Download [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey) from Hugging Face and place it in `model/MiniCPM4-Survey`.
We recommend using [MiniCPM-Embedding-Light](https://huggingface.co/openbmb/MiniCPM-Embedding-Light) as the embedding model, which can be downloaded from Hugging Face and placed in `model/MiniCPM-Embedding-Light`.
### Perpare the environment
You can download the [paper data](https://www.kaggle.com/datasets/Cornell-University/arxiv) from Kaggle, then extract it. You can run `python data_process.py` to process the data and generate the retrieval database. Then you can run `python build_index.py` to build the retrieval database.
*Performance comparison of the survey generation systems. "G2FT" stands for Gemini-2.0-Flash-Thinking, and "WTR1-7B" denotes Webthinker-R1-7B. FactScore evaluation was omitted for Webthinker, as it does not include citation functionality, and for OpenAI Deep Research, which does not provide citations when exporting the results.*
*GPT-4o对综述生成系统的性能比较。“G2FT”代表Gemini-2.0-Flash-Thinking,“WTR1-7B”代表Webthinker-R1-7B。由于Webthinker不包括引用功能,OpenAI Deep Research在导出结果时不提供引用,因此省略了对它们的FactScore评估。我们的技术报告中包含评测的详细信息。*

{kind=link}
{kind=link}