# InspireMusic
支持音乐、歌曲及音频的生成,为用户提供多样化选择。
## 论文
`无`
## 模型结构
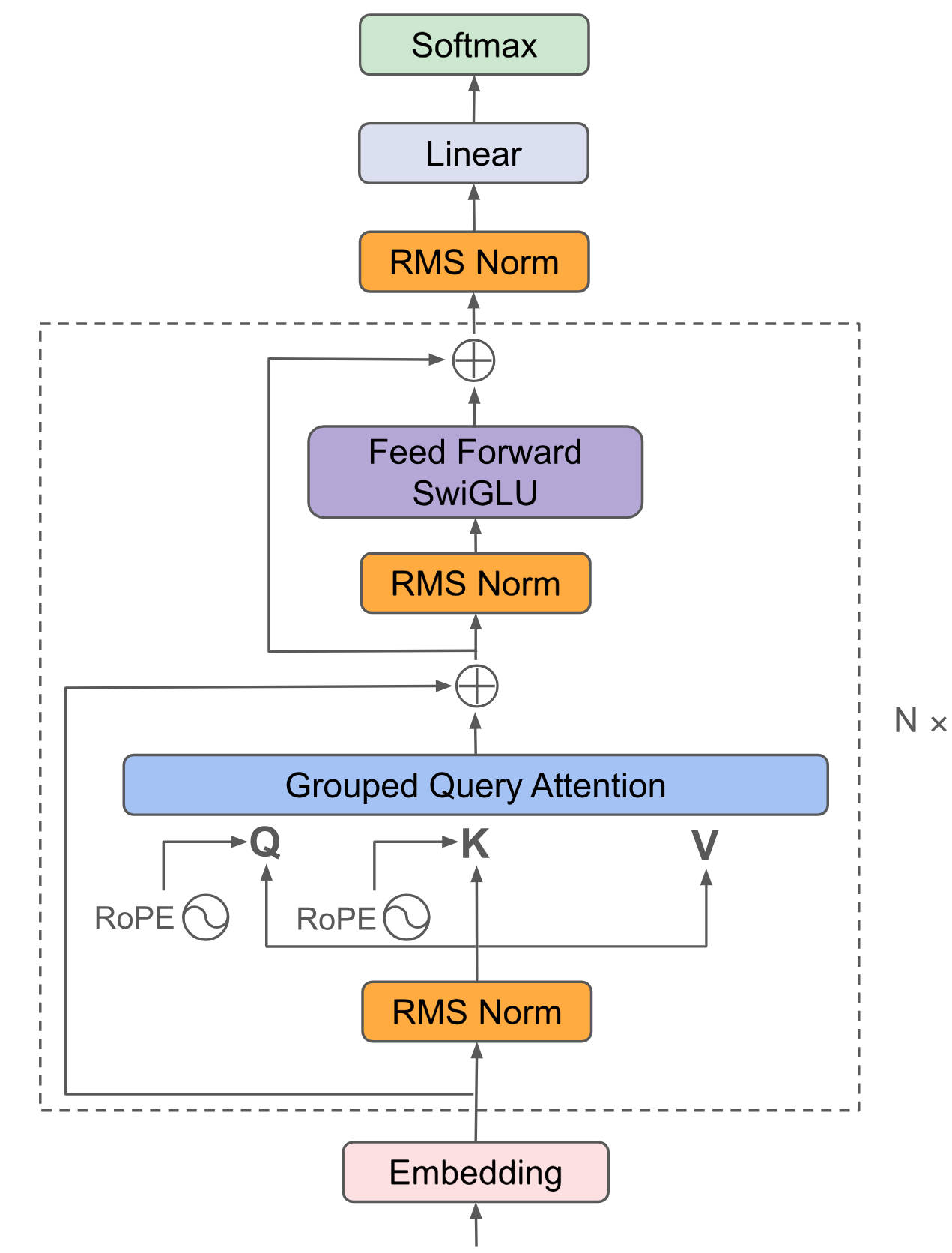
InspireMusic基于Qwen模型初始化的自回归Transformer模型预测音频token。
## 算法原理
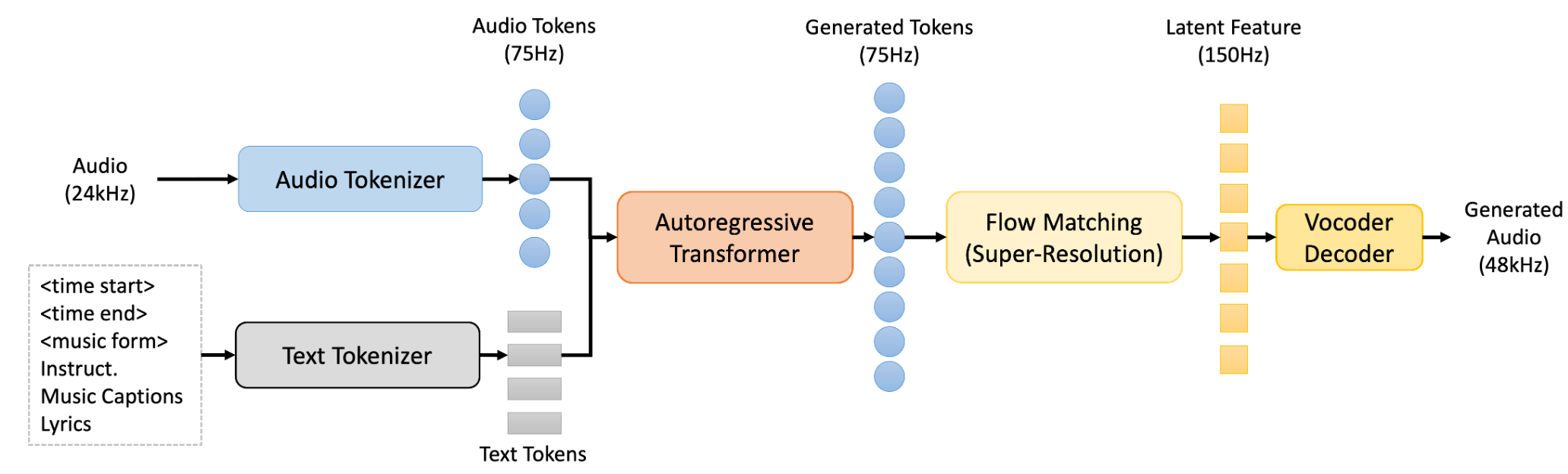
通过具有高压缩比的WavTokenizer将输入的连续音频特征转换成离散音频token,然后利用基于Qwen模型初始化的自回归Transformer模型预测音频token,再由CFM扩散模型重建音频的潜层特征,最终通过Vocoder输出高质量的音频波形。
## 环境配置
```
mv InspireMusic_pytorch InspireMusic # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-py3.10-dtk24.04.3-ubuntu20.04
# 为以上拉取的docker的镜像ID替换,本镜像为:b272aae8ec72
docker run -it --shm-size=64G -v $PWD/InspireMusic:/home/InspireMusic -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name music bash
cd /home/InspireMusic
pip install -r requirements.txt
```
### Dockerfile(方法二)
```
cd /home/InspireMusic/docker
docker build --no-cache -t music:latest .
docker run --shm-size=64G --name music -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../InspireMusic:/home/InspireMusic -it music bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.hpccube.com/tool/
```
DTK驱动:dtk24.04.3
python:python3.10
torch:2.3.0
torchvision:0.18.1
torchaudio:2.1.2
triton:2.1.0
vllm:0.6.2
flash-attn:2.6.1
deepspeed:0.14.2
apex:1.3.0
xformers:0.0.25
transformers:4.48.0
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/InspireMusic
pip install -r requirements.txt
```
## 数据集
`无`
## 训练
`无`
本项目的训练需一定的乐理基础,一般人难以训练出较好的效果,感兴趣的用户请参考源项目的[`README_origin`](./README_origin.md)训练。
## 推理
### 单机单卡
```
export MIOPEN_DEBUG_CONV_WINOGRAD=0
# 预训练权重放入:/home/InspireMusic/pretrained_models/
cd /home/InspireMusic/examples/music_generation
python -m inspiremusic.cli.inference # 或 sh test.sh
```
项目当前处在初期研发时期,源项目仍存在一些bug和效果问题,逐渐完善中。
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## result
`输入: `
```
prompt(默认): "Experience soothing and sensual instrumental jazz with a touch of Bossa Nova, perfect for a relaxing restaurant or spa ambiance."
```
`输出:`
```
/home/InspireMusic/examples/music_generation/exp/inspiremusic/output_audio.wav
```
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
`音乐生成`
### 热点应用行业
`广媒,影视,动漫,医疗,家居,教育`
## 预训练权重
预训练权重快速下载中心:[SCNet AIModels](http://113.200.138.88:18080/aimodels) ,项目中的预训练权重可从快速下载通道下载:[InspireMusic-1.5B-Long](http://113.200.138.88:18080/aimodels/funaudiollm/InspireMusic-1.5B-Long.git)
Hugging Face下载地址为:[InspireMusic-1.5B-Long](https://huggingface.co/FunAudioLLM/InspireMusic-1.5B-Long)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/InspireMusic_pytorch.git
## 参考资料
- https://github.com/FunAudioLLM/InspireMusic.git