# HLLM
字节提出的双层LLM模型HLLM仅需相当于基于传统ID方法1/6至1/4的数据量即可达到同等性能水平,较SOTA模型性能提升0.705%。
## 论文
`HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling`
- https://arxiv.org/pdf/2409.12740
## 模型结构
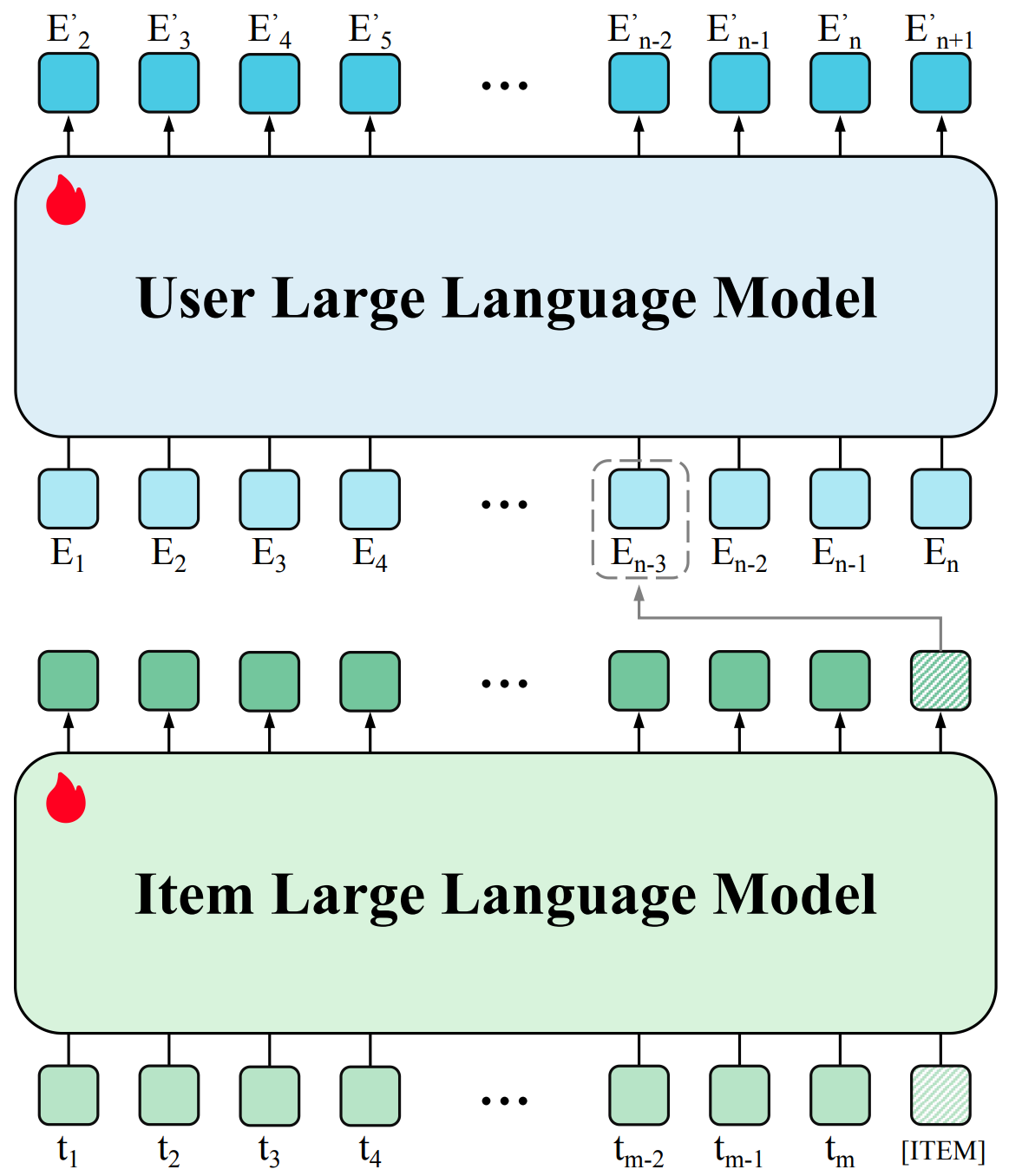
提取特征的Item LLM和User LLM采用TinyLlama-1.1B或Baichuan2-7B,LLM模型结构参照大模型通用的模型结构llama。
## 算法原理
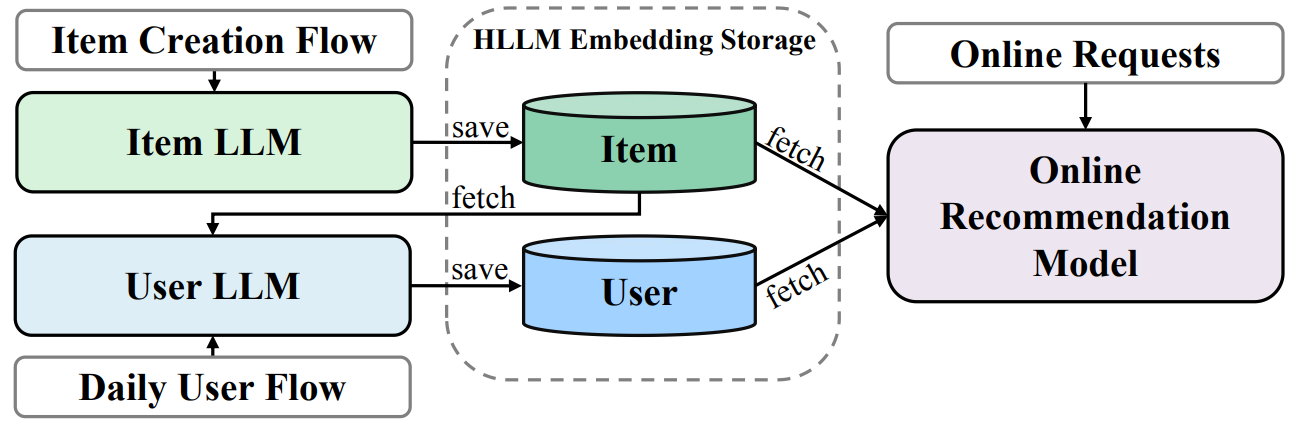
HLLM将Item建模与用户建模解耦,首先利用Item LLM提取Item特征,将复杂的文本描述压缩为Embedding,随后基于这些Item特征通过User LLM对用户画像进行建模,从而利用到LLM预训练模型的世界知识。
## 环境配置
```
mv HLLM_pytorch HLLM # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-py3.10-dtk24.04.3-ubuntu20.04
# 为以上拉取的docker的镜像ID替换,本镜像为:b272aae8ec72
docker run -it --shm-size=64G -v $PWD/HLLM:/home/HLLM -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name hllm bash
cd /home/HLLM
pip install -r requirements.txt
```
### Dockerfile(方法二)
```
cd /home/HLLM/docker
docker build --no-cache -t hllm:latest .
docker run --shm-size=64G --name hllm -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../HLLM:/home/HLLM -it hllm bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk24.04.3
python:python3.10
torch:2.3.0
torchvision:0.18.1
torchaudio:2.1.2
triton:2.1.0
flash-attn:2.6.1
deepspeed:0.14.2
xformers:0.0.25
transformers:4.41.1
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/HLLM
pip install -r requirements.txt
```
## 数据集
`PixelRec:`
[interaction](https://drive.google.com/drive/folders/1vR1lgQUZCy1cuhzPkM2q7AsdYRP43feQ?usp=drive_link)、[iteminfo](https://drive.google.com/drive/folders/1rXBM-zi5sSdLHNshXWtGgVReWLuYNgDB?usp=drive_link)
`Amazon Book Reviews:`
[HLLM Interactions ](https://huggingface.co/ByteDance/HLLM/resolve/main/Interactions/amazon_books.csv)
[HLLM Item Information ](https://huggingface.co/ByteDance/HLLM/resolve/main/ItemInformation/amazon_books.csv)
此步骤以`Pixel200K`为例进行使用说明 ,只使用`Pixel200K`即可进行步骤实验。
数据的完整目录结构如下,下载数据集后按照以下目录结构整理:
```
/home/HLLM/
├── dataset # Store Interactions
│ ├── amazon_books.csv
│ ├── Pixel1M.csv
│ ├── Pixel200K.csv
│ └── Pixel8M.csv
└── information # Store Item Information
├── amazon_books.csv
├── Pixel1M.csv
├── Pixel200K.csv
└── Pixel8M.csv
```
## 训练
### 单机多卡
```
cd /home/HLLM
sh train.sh # 以数据集Pixel200K、预训练模型TinyLlama-1.1B-Chat-v1.0作为示例
```
若希望单独对验证集做验证(前面训练过程已包含验证):
```
# 训练完成后,权重文件夹`code/saved_path/HLLM-0.pth/`中会生成`zero_to_fp32.py`, 参照代码说明转换权重.pt到.bin
cd code
python saved_path/HLLM-0.pth/zero_to_fp32.py saved_path/HLLM-0.pth saved_path/pytorch_model.bin
#
cd /home/HLLM
sh infer.sh
```
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## 推理
无
## result
无
### 精度
数据集:Pixel200K,epoch为5,训练框架:pytorch。
| device | nce_top1_acc |
|:----------:|:-------:|
| DCU K100AI | 0.164 |
| GPU A800 | 0.164|
## 应用场景
### 算法类别
`推荐系统`
### 热点应用行业
`零售,广媒,金融,通信`
## 预训练权重
Hugging Face下载地址为:[HLLM](https://huggingface.co/ByteDance/HLLM)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/HLLM_pytorch.git
## 参考资料
- https://github.com/bytedance/HLLM.git