# Florence-2
Florence-2常被一些大模型公司用于多模态的数据预标注,支持10余种任务,参数量小精度高于CLIP。
## 论文
`Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks`
- https://arxiv.org/pdf/2311.06242
## 模型结构
Florence-2由图片文本编码器和普通的多模态编码器-解码器组成。
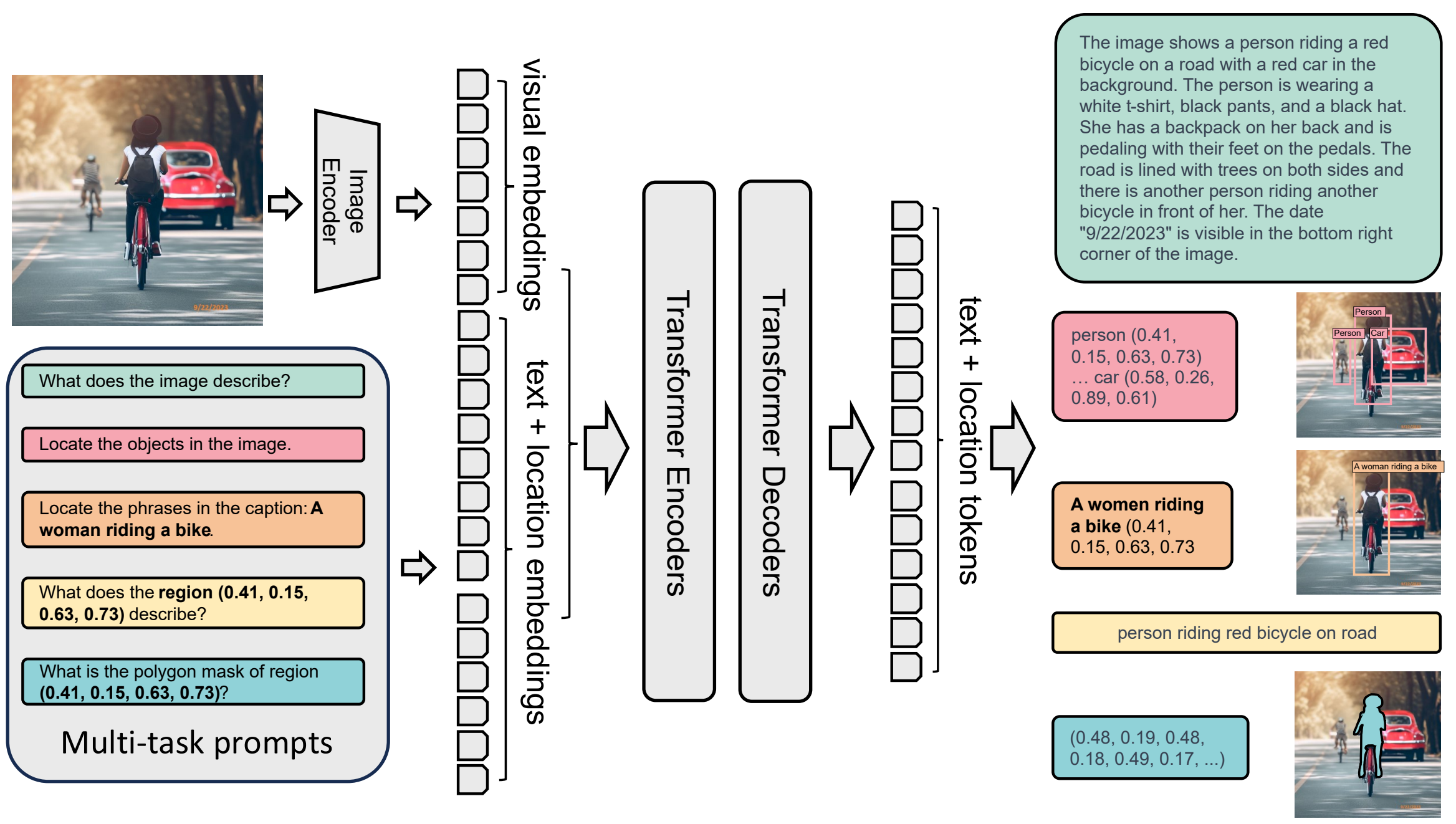
## 算法原理
Florence-2采用了DaViT视觉编码器,将图像转换为视觉嵌入,并结合BERT将文本提示转换为文本和位置嵌入,这些嵌入经过标准编码器-解码器transformer架构的处理,最终生成文本输出。
## 环境配置
```
mv Florence-2-Vision-Language-Model_pytorch Florence-2-Vision-Language-Model # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.4.1-ubuntu22.04-dtk25.04-py3.10-fixpy
# 为以上拉取的docker的镜像ID替换,本镜像为:6063b673703a
docker run -it --shm-size=64G -v $PWD/Florence-2-Vision-Language-Model:/home/Florence-2-Vision-Language-Model -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name florence2 bash
cd /home/Florence-2-Vision-Language-Model
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
```
### Dockerfile(方法二)
```
cd /home/Florence-2-Vision-Language-Model/docker
docker build --no-cache -t florence2:latest .
docker run --shm-size=64G --name florence2 -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../Florence-2-Vision-Language-Model:/home/Florence-2-Vision-Language-Model -it florence2 bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk2504
python:python3.10
torch:2.4.1
torchvision:0.19.1
triton:3.0.0
vllm:0.6.2
flash-attn:2.6.1
deepspeed:0.14.2
apex:1.4.0
transformers:4.46.3
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/Florence-2-Vision-Language-Model
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
```
## 数据集
`无`
## 训练
无
## 推理
预训练权重目录结构:
```
/home/Florence-2-Vision-Language-Mode/
└── AI-ModelScope/Florence-2-large-ft
```
### 单机单卡
```
cd /home/Florence-2-Vision-Language-Mode
python infer.py
```
Florence 2 支持许多类型的任务:
- **Caption**,
- **Detailed Caption**,
- **More Detailed Caption**,
- **Dense Region Caption**,
- **Object Detection**,
- **OCR**,
- **Caption to Phrase Grounding**,
- **segmentation**,
- **Region proposal**,
- **OCR**,
- **OCR with Region**.
更多资料可参考源项目中的[`readme_origin`](./readme_origin.md)。
## result
`输入: `
```
car.jpg
```
`输出:`
```
{'': {'bboxes': [[34.23999786376953, 160.0800018310547, 597.4400024414062, 371.7599792480469], [454.7200012207031, 97.19999694824219, 579.5199584960938, 261.3599853515625], [452.79998779296875, 276.7200012207031, 553.9199829101562, 370.79998779296875], [94.4000015258789, 280.55999755859375, 196.1599884033203, 371.2799987792969]], 'labels': ['car', 'door', 'wheel', 'wheel']}}
```
Florence-2训练用到的数据标签示例,其可能实现的标注效果可参考以下图片:
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
`多模态`
### 热点应用行业
`制造,广媒,金融,能源,医疗,家居,教育`
## 预训练权重
魔搭社区下载地址为:[AI-ModelScope/Florence-2-large-ft](https://www.modelscope.cn/models/AI-ModelScope/Florence-2-large-ft)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/Florence-2-Vision-Language-Model_pytorch.git
## 参考资料
- https://github.com/anyantudre/Florence-2-Vision-Language-Model.git
- https://github.com/andimarafioti/florence2-finetuning.git
