# FlashVideo
字节提出FlashVideo,高保真的高分辨率视频生成更快更强。
## 论文
`FlashVideo:Flowing Fidelity to Detail for Efficient High-Resolution Video Generation`
- https://arxiv.org/pdf/2502.05179
## 模型结构
FlashVideo采用级联范式,由低分辨率(即阶段 I)的50亿参数DiT和高分辨率(即阶段II)的20亿参数DiT组成。在两个阶段都采用3D RoPE来有效建模全局和相对时空距离。
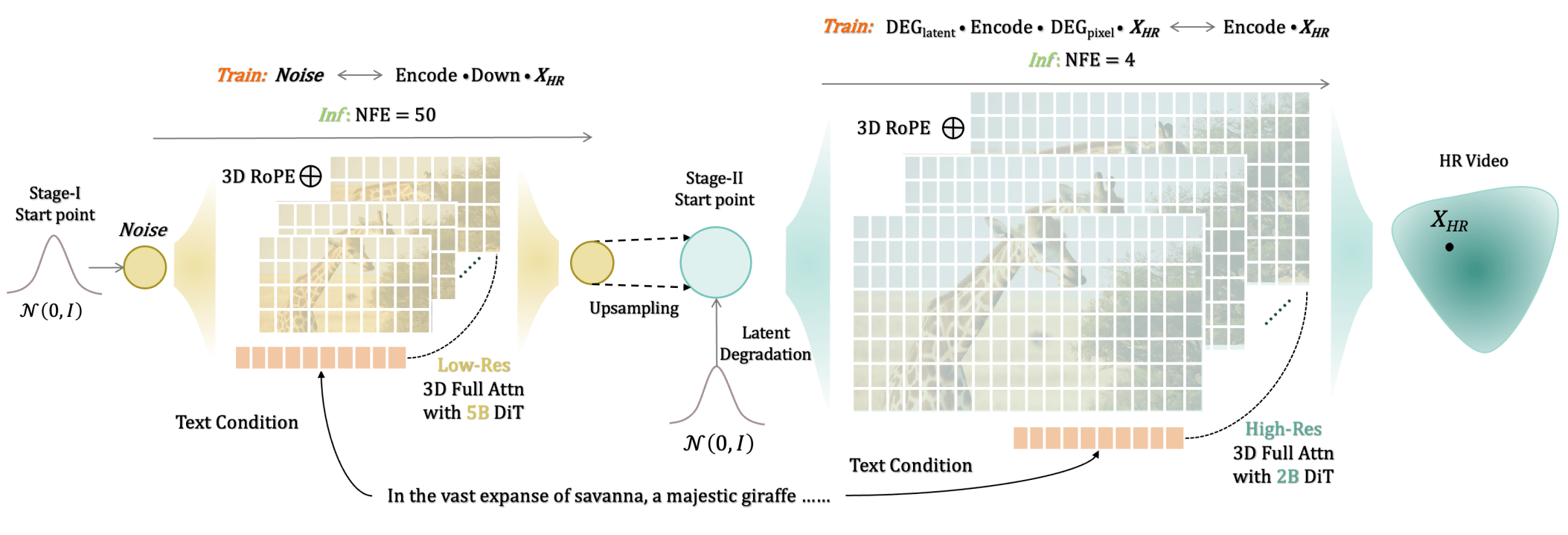
## 算法原理
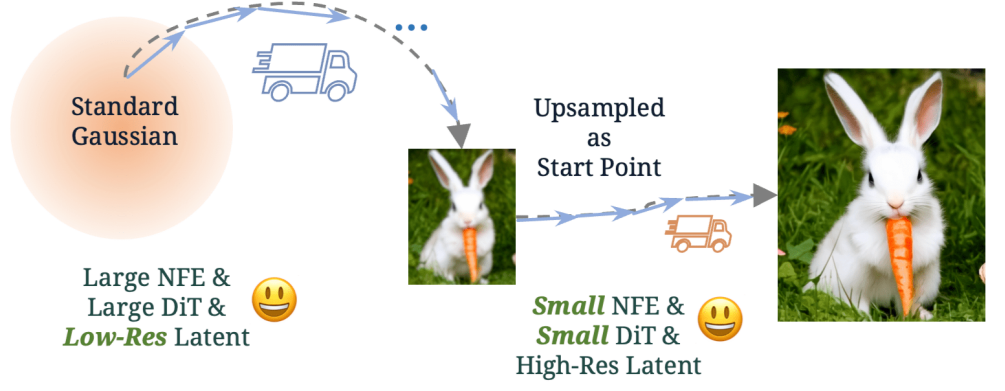
两阶段框架:分别优化了提示保真度和视觉质量。在第一阶段,FlashVideo优先考虑低分辨率下的保真度,利用较大的参数和足够的NFE;第二阶段则在低分辨率和高分辨率之间进行流匹配,利用较少的NFE有效生成细节。
## 环境配置
```
mv FlashVideo_pytorch FlashVideo # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-py3.10-dtk24.04.3-ubuntu20.04
# 为以上拉取的docker的镜像ID替换,本镜像为:b272aae8ec72
docker run -it --shm-size=64G -v $PWD/FlashVideo:/home/FlashVideo -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name fv bash
cd /home/FlashVideo
pip install -r requirements.txt
```
### Dockerfile(方法二)
```
cd /home/FlashVideo/docker
docker build --no-cache -t fv:latest .
docker run --shm-size=64G --name fs -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../FlashVideo:/home/FlashVideo -it fv bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk24.04.3
python:python3.10
torch:2.3.0
torchvision:0.18.1
torchaudio:2.1.2
triton:2.1.0
vllm:0.6.2
flash-attn:2.6.1
deepspeed:0.14.2
apex:1.3.0
xformers:0.0.25
transformers:4.48.0
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/FlashVideo
sh apt.sh # 安装linux中关于音频需要的基本库,以Ubuntu为例。
pip install -r requirements.txt
```
## 数据集
`无`
## 训练
`无`
## 推理
### 单机多卡
修改torchvision解决torchvision与av库冲突bug。
```
vim /usr/local/lib/python3.10/site-packages/torchvision/io/video.py, line 132:
# frame.pict_type = "NONE"
try:
frame.pict_type = "NONE"
except TypeError:
frame.pict_type = 0 # Use the correct integer value
```
由于FlashVideo的显存占用过大(>=80Gb/GPU,源作者仍在优化效果和性能。),为了能在小算力设备试验,本项目已做两处修改:
```
1、调整显卡数量:
vim inf_270_1080p.sh
--nproc_per_node=4
2、按比例调低第二阶段的生成分辨率:
vim flashvideo/dist_inf_text_file.py
second_img_size = [270, 480]
# 用户未来具备大显存的卡后,还原以上参数即可:nproc_per_node=8、second_img_size = [1080, 1920]
```
```
# 预训练权重目录结构
/home/FlashVideo/checkpoints/
├── 3d-vae.pt
├── stage1.pt
└── stage2.pt
```
```
cd /home/FlashVideo
sh inf_270_1080p.sh
```
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## result
`输入: `
```
input-file: example.txt
```
`输出:`
```
output-dir: vis_270p_1080p_example
```
注:本项目基于1080p数据训练,故分辨率为1080p才能达到目标效果。
源作者提供的效果示例:
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
`图像超分`
### 热点应用行业
`广媒,影视,动漫,医疗,家居,教育`
## 预训练权重
Hugging Face下载地址为:[FlashVideo](https://huggingface.co/FoundationVision/FlashVideo)、[google/t5-v1_1-xxl](https://huggingface.co/google/t5-v1_1-xxl)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/FlashVideo_pytorch.git
## 参考资料
- https://github.com/FoundationVision/FlashVideo.git
