# llava
## 论文
Visual Instruction Tuning
[2304.08485 (arxiv.org)](https://arxiv.org/pdf/2304.08485)
## 模型结构
LLaVA(大型语言和视觉助手)是一个开源的大型多模态模型,结合了视觉和语言能力。它通过将视觉编码器与语言模型 Vicuna 结合,实现了先进的视觉和语言理解,在多模态任务中表现优异,并在多个基准测试中(如 Science QA)设立了新的标准。LLaVA 以成本效益高的训练和高效扩展性著称,最近的更新着重提升了多模态推理能力,尤其是对高分辨率图像的理解。
LLaVA 的最新进展包括支持动态高分辨率处理,以及多语言的零样本能力,如中文,展现了在非英语数据上未经特定微调的情况下也能保持出色的表现
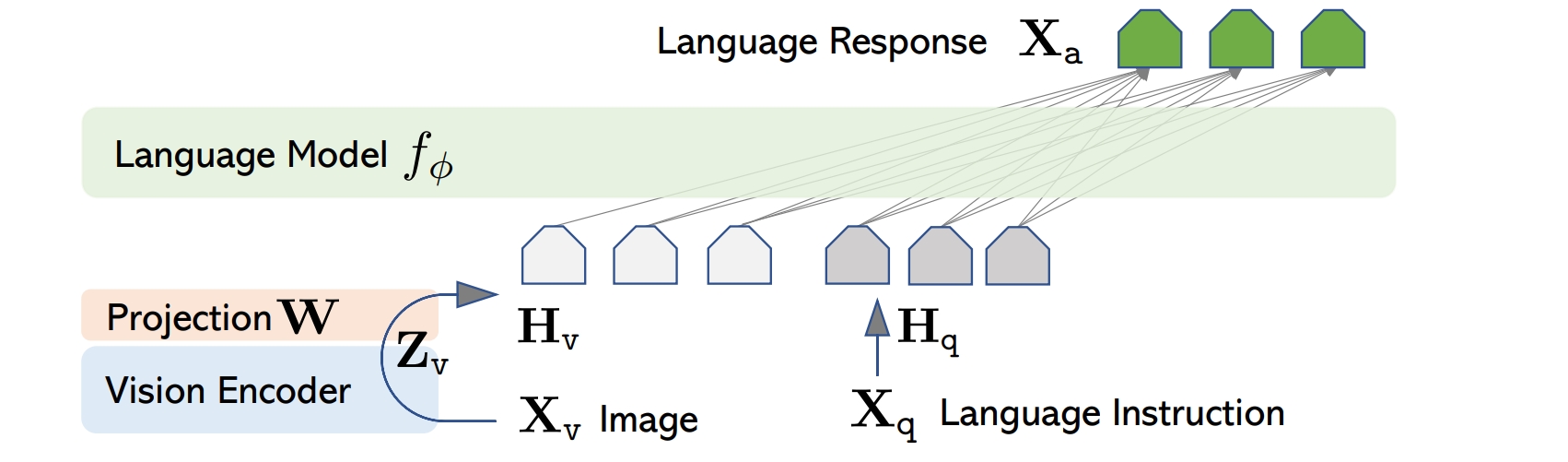
## 算法原理
LLaVA(Large Language and Vision Assistant)的算法原理主要包括以下几个方面:
* **视觉指令调优** :通过使用GPT-4生成的多模态语言-图像指令数据,对模型进行调优,以提高其在新任务上的零样本能力。
* **大规模多模态模型** :将CLIP的视觉编码器与Vicuna的语言解码器连接,形成一个端到端训练的多模态模型,用于通用的视觉和语言理解。
* **数据生成** :利用GPT-4生成多模态指令跟随数据,包括对图像内容的详细描述和复杂推理问题。
* **评估基准** :构建了两个评估基准,包含多样且具有挑战性的应用任务,以测试模型的多模态对话能力。
## 环境配置
### Docker(方法一)
提供[光源](https://www.sourcefind.cn/#/image/dcu/custom)拉取推理的docker镜像:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.2-py3.10
# 用上面拉取docker镜像的ID替换
# 主机端路径
# 容器映射路径
docker run -it --name llava_vllm --privileged --shm-size=64G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal -v : /bin/bash
```
`Tips:若在K100/Z100L上使用,使用定制镜像docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:vllm0.5.0-dtk24.04.1-ubuntu20.04-py310-zk-v1,K100/Z100L不支持awq量化`
### Dockerfile(方法二)
```
# 主机端路径
# 容器映射路径
docker build -t llava:latest .
docker run -it --name llava_vllm --privileged --shm-size=64G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v : llava:latest /bin/bash
```
### Anaconda(方法三)
```
conda create -n llava_vllm python=3.10
```
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
* DTK驱动:dtk24.04.2
* Pytorch: 2.1.0
* triton:2.1.0
* lmslim: 0.1.0
* xformers: 0.0.25
* flash_attn: 2.0.4
* vllm: 0.5.0
* python: python3.10
`Tips:需先安装相关依赖,最后安装vllm包`
## 数据集
无
## 推理
### 模型下载
| 基座模型 | | |
| ---------------------------------------------------------------- | ------------------------------------------------------------------- | ------------------------------------------------------------------------------- |
| [llava-v1.5-7b](http://113.200.138.88:18080/aimodels/llava-v1.5-7b) | [llava-v1.6-34b-hf](https://huggingface.co/llava-hf/llava-v1.6-34b-hf) | [llava-v1.6-vicuna-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-vicuna-7b-hf) |
### 模型推理
```bash
python examples/llava_example.py
```
为了确保源码能够正常运行,还需要进行以下调整:
* **去除了AWS CLI 下载逻辑** :
* **移除对 `subprocess` 和 `os` 模块的部分依赖**
### result
使用的加速卡:单卡K100_AI 模型:[llava-v1.5-7b](http://113.200.138.88:18080/aimodels/llava-v1.5-7b)
输入:
images:
text: What is the content of this image?
输出:
output: The image features a close-up view of a stop sign on a city street
精度
无
## 应用场景
### 算法类别
对话问答
### 热点应用行业
金融,科研,教育
## 源码仓库及问题反馈
* [https://developer.hpccube.com/codes/modelzoo/qwen1.5_vllm](https://developer.hpccube.com/codes/modelzoo/qwen1.5_vllm)
## 参考资料
* [https://github.com/vllm-project/vllm](https://github.com/vllm-project/vllm)
