
“13.0”
Showing
Too many changes to show.
To preserve performance only 329 of 329+ files are displayed.

151 KB

180 KB

84.5 KB
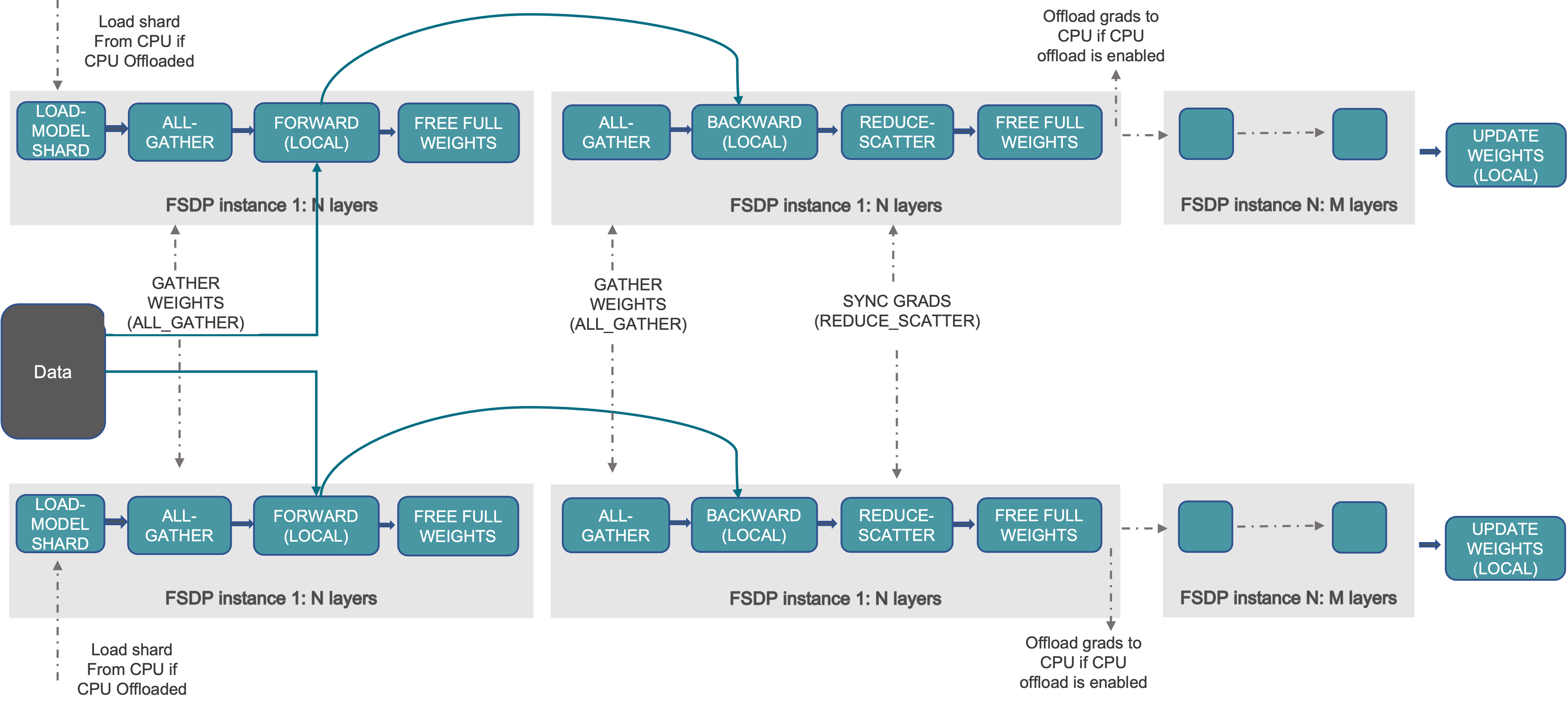
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
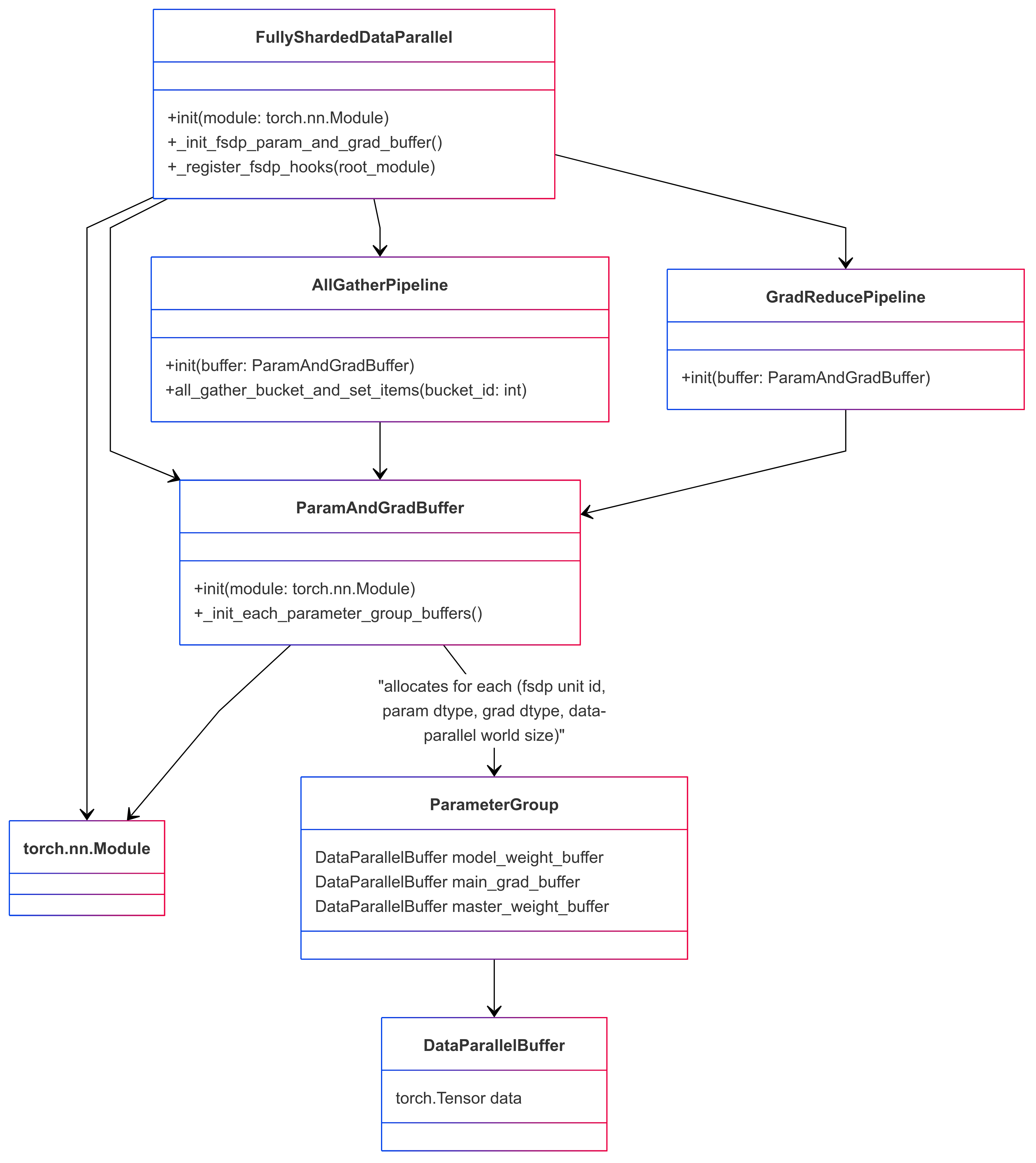
499 KB
{kind=link}

60.2 KB
{kind=link}

76 KB
{kind=link}
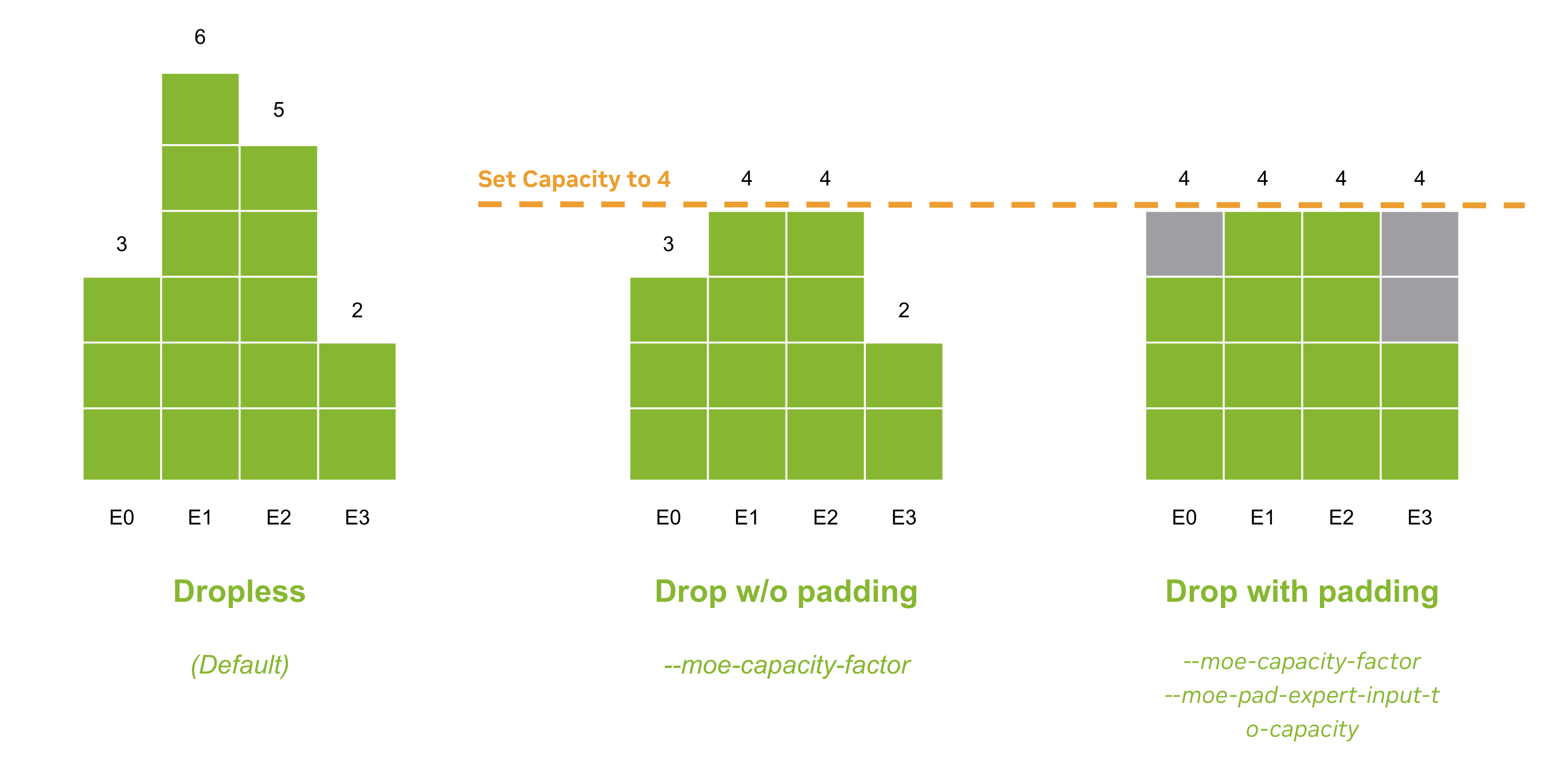
243 KB
{kind=link}

335 KB
151 KB
180 KB
84.5 KB
499 KB
60.2 KB
76 KB
243 KB
335 KB