The [Multi-Storage Client](https://github.com/NVIDIA/multi-storage-client)(MSC) provides a unified interface for reading datasets and storing checkpoints from both filesystems (e.g., local disk, NFS, Lustre) and object storage providers such as S3, GCS, OCI, Azure, AIStore, and SwiftStack.
This guide will walk you through how to:
1. How to install and configure MSC
2. How to train models directly using datasets in object storage
3. How to save and load model checkpoints to/from object storage
### Installation
To install the Multi-Storage Client package:
```bash
pip install multi-storage-client
```
For S3 access, you'll also need to install boto3:
```bash
pip install multi-storage-client[boto3]
```
### Configuration File
MSC uses a YAML configuration file to define how it connects to object storage systems. This design allows you to specify one or more storage profiles, each representing a different storage backend or bucket. MSC keeps your training scripts clean and portable by centralizing details in a config file. There is no need to hardcode access keys, bucket names, or other provider-specific options directly into your code.
Here's an example configuration:
```yaml
profiles:
my-profile:
storage_provider:
type:s3
options:
# Set the bucket/container name as the base_path
base_path:my-bucket
region_name:us-west-2
# Optional credentials (can also use environment variables for S3)
credentials_provider:
type:S3Credentials
options:
access_key:${AWS_ACCESS_KEY}
secret_key:${AWS_SECRET_KEY}
cache:
# Maximum cache size
size:500G
cache_backend:
# Cache directory on filesystem
cache_path:/tmp/msc_cache
```
To tell MSC where to find this file, set the following environment variable before running your Megatron-LM script:
```bash
export MSC_CONFIG=/path/to/msc_config.yaml
```
### MSC URL Format
MSC uses a custom URL scheme to identify and access files across different object storage providers. This scheme makes it easy to reference data and checkpoints without worrying about the underlying storage implementation. An MSC URL has the following structure:
```
msc://<profile-name>/<path/to/object>
```
**Components:**
*`msc://` This is the scheme identifier indicating the path should be interpreted by the Multi-Storage Client.
*`<profile-name>` This corresponds to a named profile defined in your YAML configuration file under the profiles section. Each profile specifies the storage provider (e.g., S3, GCS), credentials, and storage-specific options such as the bucket name or base path.
*`<path/to/object>` This is the logical path to the object or directory within the storage provider, relative to the base_path configured in the profile. It behaves similarly to a path in a local filesystem but maps to object keys or blobs in the underlying storage system.
**Example:**
Given the following profile configuration:
```yaml
profiles:
my-profile:
storage_provider:
type:s3
options:
base_path:my-bucket
```
The MSC URL:
```
msc://my-profile/dataset/train/data.bin
```
is interpreted as accessing the object with the key `dataset/train/data.bin` inside the S3 bucket named `my-bucket`. If this were a GCS or OCI profile instead, MSC would apply the appropriate backend logic based on the profile definition, but your code using the MSC URL would remain unchanged.
This abstraction allows training scripts to reference storage resources uniformly—whether they're hosted on AWS, GCP, Oracle, or Azure—just by switching profiles in the config file.
### Train from Object Storage
To train with datasets stored in object storage, use an MSC URL with the `--data-path` argument. This URL references a dataset stored under a profile defined in your MSC configuration file.
In addition, Megatron-LM requires the `--object-storage-cache-path` argument when reading from object storage. This path is used to cache the `.idx` index files associated with IndexedDataset, which are needed for efficient data access.
**NOTE:** All four arguments must be provided when training with datasets in object storage using MSC.
### Save and Load Checkpoints from Object Storage
MSC can be used to save and load model checkpoints directly from object storage by specifying MSC URLs for the `--save` and `--load` arguments. This allows you to manage checkpoints in object storage.
```bash
python pretrain_gpt.py \
--save msc://my-profile/checkpoints \
--load msc://my-profile/checkpoints \
--save-interval 1000
```
**Notes:** Only the `torch_dist` checkpoint format is currently supported when saving to or loading from MSC URLs.
### Disable MSC
By default, MSC integration is automatically enabled when the `multi-storage-client` library is installed. MSC is also used for regular filesystem paths (like `/filesystem_mountpoint/path` in `--data-path`, `--save`, or `--load`) even when not using explicit MSC URLs. MSC functions as a very thin abstraction layer with negligible performance impact when used with regular paths, so there's typically no need to disable it. If you need to disable MSC, you can do so using the `--disable-msc` flag:
```bash
python pretrain_gpt.py --disable-msc
```
### Performance Considerations
When using object storage with MSC, there are a few important performance implications to keep in mind:
**Reading Datasets**
Reading training datasets directly from object storage is typically slower than reading from local disk. This is primarily due to:
* High latency of object storage systems, especially for small and random read operations (e.g., reading samples from .bin files).
* HTTP-based protocols used by object stores (e.g., S3 GET with range requests), which are slower than local filesystem I/O.
To compensate for this latency, it is recommended to increase the number of data loading workers using the `--num-workers` argument in your training command:
```
python pretrain_gpt.py --num-workers 8 ...
```
Increasing the number of workers allows more parallel reads from object storage, helping to mask I/O latency and maintain high GPU utilization during training.
**Checkpoint Loading**
When using MSC to load checkpoints from object storage, it is important to configure the cache section in your MSC configuration file. This local cache is used to store downloaded checkpoint data and metadata, which significantly reduces load time and memory usage.
Example:
```
cache:
size: 500G
cache_backend:
cache_path: /tmp/msc_cache
```
Make sure this cache directory is located on a fast local disk (e.g., NVMe SSD) for optimal performance.
### Additional Resources and Advanced Configuration
Refer to the [MSC Configuration Documentation](https://nvidia.github.io/multi-storage-client/config/index.html) for complete documentation on MSC configuration options, including detailed information about supported storage providers, credentials management, and advanced caching strategies.
MSC also supports collecting observability metrics and traces to help monitor and debug data access patterns during training. These metrics can help you identify bottlenecks in your data loading pipeline, optimize caching strategies, and monitor resource utilization when training with large datasets in object storage.
For more information about MSC's observability features, see the [MSC Observability Documentation](https://nvidia.github.io/multi-storage-client/config/index.html#opentelemetry).
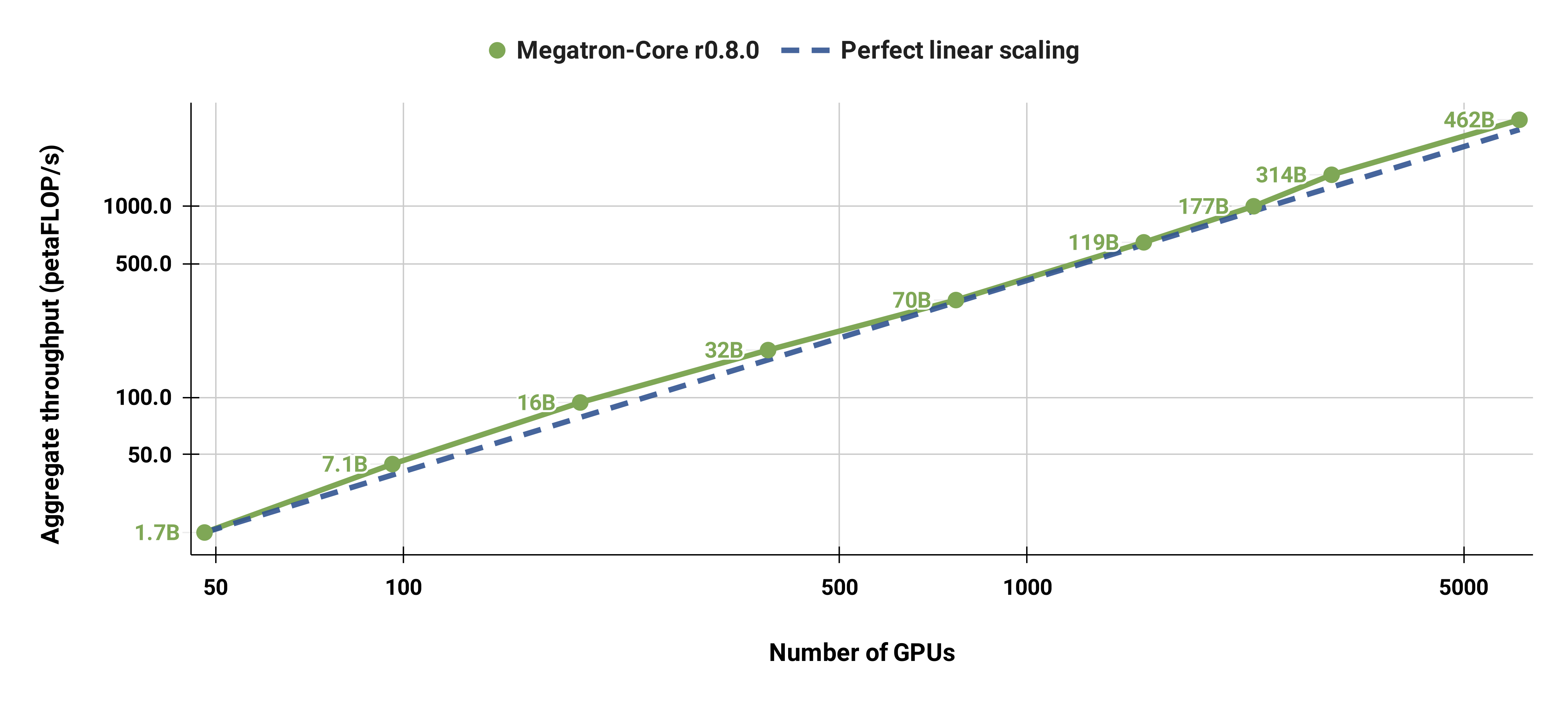
This guide for Megatron Core walks you through the following tasks:
* Initialize Megatron Core on two GPUS.
* Build a GPT model with a tensor model parallel size of two and a pipeline parallel size of one.
* Train the model for five iterations using Megatron Core schedules.
* Save the model using the distributed checkpoint format.
* Load the model.
**NOTE:** The following sample was tested using Megatron Core version 0.8.0 and NGC PyTorch Container version 24.02.
### Set Up Your Environment
1. Run a new Docker container.
1. Clone the Megatron GitHub repo in it.
```
docker run --ipc=host --shm-size=512m --gpus 2 -it nvcr.io/nvidia/pytorch:24.02-py3
git clone https://github.com/NVIDIA/Megatron-LM.git && cd Megatron-LM
```
<br>
### Write Your First Training Loop
In this task, you create a sample GPT model split across tensors (Tensor model parallel) on two GPUS, and run a forward pass through it using a MockGPT dataset helper class that was created in Megatron Core.
<br>
**NOTE:** All of the following steps are in the [run_simple_mcore_train_loop.py](https://github.com/NVIDIA/Megatron-LM/tree/main/examples/run_simple_mcore_train_loop.py) script. To run the ``run_simple_mcore_train_loop.py`` script:
Use the following code snippet to create a GPT model. For a list of other configurations that you can pass into the model, open and review [transformer_config.py](https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/core/transformer/transformer_config.py).
```
from megatron.core.transformer.transformer_config import TransformerConfig
from megatron.core.models.gpt.gpt_model import GPTModel
from megatron.core.models.gpt.gpt_layer_specs import get_gpt_layer_local_spec
Use the following code snippet to explore the mock dataset utility.
* To train the model using your data, use the `GPTDataset` class in [gpt_dataset.py](https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/core/datasets/gpt_dataset.py).
* To find more information about Megatron Core data pipeline, see the [data pipeline readme.md](https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/core/datasets/readme.md?ref_type=heads).
```
import torch
from torch.utils.data import DataLoader
from megatron.core.datasets.blended_megatron_dataset_builder import BlendedMegatronDatasetBuilder
from megatron.core.datasets.gpt_dataset import GPTDatasetConfig, MockGPTDataset
from megatron.training.tokenizer.tokenizer import _NullTokenizer
from megatron.core.datasets.utils import compile_helpers
_SEQUENCE_LENGTH = 64
def get_train_data_iterator():
if torch.distributed.is_available() and torch.distributed.is_initialized():
Megatron Core uses [schedules.py](https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/core/pipeline_parallel/schedules.py) to run the model. Define a forward step function that takes the data iterator and the model as input and produces the output tensor and a loss function.
1. Define your load and save distributed checkpoints:
Megatron Core uses distributed checkpoints for loading and saving models. This allows you to convert the model from one parallel setting to another when you load it.
For example, a model trained with tensor parallel size `2`, can be loaded again as a tensor model with parallel size `4`.
To review more advanced examples, explore [pretrain_gpt.py](https://github.com/NVIDIA/Megatron-LM/blob/main/pretrain_gpt.py). ``pretrain_gpt.py`` has more complex training loops and includes the following Megatron Core features:
Megatron-Core is an open-source PyTorch-based library that contains GPU-optimized techniques and cutting-edge system-level optimizations. It abstracts them into composable and modular APIs, allowing full flexibility for developers and model researchers to train custom transformers at-scale on NVIDIA accelerated computing infrastructure. This library is compatible with all NVIDIA Tensor Core GPUs, including FP8 acceleration support for [NVIDIA Hopper architectures](https://www.nvidia.com/en-us/data-center/technologies/hopper-architecture/).
Megatron-Core offers core building blocks such as attention mechanisms, transformer blocks and layers, normalization layers, and embedding techniques. Additional functionality like activation re-computation, distributed checkpointing is also natively built-in to the library. The building blocks and functionality are all GPU optimized, and can be built with advanced parallelization strategies for optimal training speed and stability on NVIDIA Accelerated Computing Infrastructure. Another key component of the Megatron-Core library includes advanced model parallelism techniques (tensor, sequence, pipeline, context, and MoE expert parallelism).
Megatron-Core can be used with [NVIDIA NeMo](https://www.nvidia.com/en-us/ai-data-science/products/nemo/), an enterprise-grade AI platform. Alternatively, you can explore Megatron-Core with the native PyTorch training loop [here](https://github.com/NVIDIA/Megatron-LM/tree/main/examples). Visit [Megatron-Core documentation](https://docs.nvidia.com/megatron-core/developer-guide/latest/index.html) to learn more.
## Quick links
-[Benchmark using NVIDIA NeMo](https://docs.nvidia.com/nemo-framework/user-guide/latest/overview.html#performance-benchmarks)
-[Multimodal example (LLaVA training pipeline)](https://github.com/NVIDIA/Megatron-LM/tree/main/examples/multimodal)
Each metric is prefixed with `Mn` or `Mx` to represent `Minimum` or `Maximum`. Each metric is also suffixed with the rank where the metric was measured. The metrics are averaged over the logging interval. Between the prefix and the rank is the name of the metric as follows
- Rtt : RoundTrip Time (time spent in all the traced ops per iteration)
- Pwr : GPU Power
- Tmp : GPU Temperature
- Utl : GPU Utilization
- Clk : GPU Clock
- DRtt: get_batch latency
- Etpt: Estimated throughput. This is derived from actual computed throughput dividied by Rtt. Since we do not collect timing for backward pass, the value is further divided by three to come up with estimated throughput.
<hr>
### Command Line activation
To start using the StragglerDetector, need to pass the following argument `--log-straggler`. It optionally also takes two additional parameters. Default disabled
-`--disable-straggler-on-startup` - whether to keept the StragglerDetector disabled on startup and enable later. Default enabled
-`--straggler-ctrlr-port` - The StragglerDetector can toggle between on/off just by sending `curl Rank0Host:port`. Default port is 65535. Every time it is turned
-`--straggler-minmax-count` - If set to > 1 (N), it prints N Top and Bottom Etpt/Rank pairs as shown below

{kind=link}
{kind=link}