diff --git a/.clang-format b/.clang-format
deleted file mode 100644
index 075810c56ec67d2b12c3554a9cc36d6784c8f885..0000000000000000000000000000000000000000
--- a/.clang-format
+++ /dev/null
@@ -1,62 +0,0 @@
-Language: Cpp
-AccessModifierOffset: -4
-AlignAfterOpenBracket: Align
-AllowShortEnumsOnASingleLine: false
-AlignConsecutiveAssignments: true
-AlignConsecutiveDeclarations: true
-AlignEscapedNewlines: Right
-AlignOperands: true
-AlignTrailingComments: true
-AllowAllParametersOfDeclarationOnNextLine: true
-AllowAllArgumentsOnNextLine: true
-AllowShortBlocksOnASingleLine: Empty
-AllowShortCaseLabelsOnASingleLine: false
-AllowShortFunctionsOnASingleLine: Empty
-AllowShortIfStatementsOnASingleLine: Never
-AllowShortLoopsOnASingleLine: false
-AlwaysBreakAfterReturnType: None
-AlwaysBreakBeforeMultilineStrings: false
-AlwaysBreakTemplateDeclarations: true
-BinPackArguments: false
-BinPackParameters: false
-BreakBeforeBinaryOperators: NonAssignment
-BreakBeforeBraces: Stroustrup
-BreakBeforeTernaryOperators: false
-BreakConstructorInitializers: AfterColon
-BreakInheritanceList: AfterColon
-BreakStringLiterals: false
-ColumnLimit: 120
-CompactNamespaces: false
-ConstructorInitializerAllOnOneLineOrOnePerLine: true
-ConstructorInitializerIndentWidth: 4
-ContinuationIndentWidth: 4
-Cpp11BracedListStyle: true
-DerivePointerAlignment: false
-FixNamespaceComments: true
-IndentCaseLabels: true
-IndentPPDirectives: None
-IndentWidth: 4
-IndentWrappedFunctionNames: false
-KeepEmptyLinesAtTheStartOfBlocks: true
-MaxEmptyLinesToKeep: 1
-NamespaceIndentation: None
-PointerAlignment: Left
-ReflowComments: true
-SortIncludes: true
-SortUsingDeclarations: false
-SpaceAfterCStyleCast: false
-SpaceAfterTemplateKeyword: false
-SpaceBeforeAssignmentOperators: true
-SpaceBeforeCtorInitializerColon: false
-SpaceBeforeInheritanceColon: false
-SpaceBeforeParens: ControlStatements
-SpaceInEmptyParentheses: false
-SpacesBeforeTrailingComments: 2
-SpacesInAngles: false
-SpacesInCStyleCastParentheses: false
-SpacesInContainerLiterals: false
-SpacesInParentheses: false
-SpacesInSquareBrackets: false
-Standard: c++17
-TabWidth: 4
-UseTab: Never
diff --git a/.github/CONTRIBUTING.md b/.github/CONTRIBUTING.md
deleted file mode 100644
index 846795ba2b10b195328cc0f00ab5974f677b6e4d..0000000000000000000000000000000000000000
--- a/.github/CONTRIBUTING.md
+++ /dev/null
@@ -1,234 +0,0 @@
-## Contributing to InternLM
-
-Welcome to the InternLM community, all kinds of contributions are welcomed, including but not limited to
-
-**Fix bug**
-
-You can directly post a Pull Request to fix typo in code or documents
-
-The steps to fix the bug of code implementation are as follows.
-
-1. If the modification involve significant changes, you should create an issue first and describe the error information and how to trigger the bug. Other developers will discuss with you and propose an proper solution.
-
-2. Posting a pull request after fixing the bug and adding corresponding unit test.
-
-**New Feature or Enhancement**
-
-1. If the modification involve significant changes, you should create an issue to discuss with our developers to propose an proper design.
-2. Post a Pull Request after implementing the new feature or enhancement and add corresponding unit test.
-
-**Document**
-
-You can directly post a pull request to fix documents. If you want to add a document, you should first create an issue to check if it is reasonable.
-
-### Pull Request Workflow
-
-If you're not familiar with Pull Request, don't worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the develop mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
-
-#### 1. Fork and clone
-
-If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
-
- -
-Then, you can clone the repositories to local:
-
-```shell
-git clone git@github.com:{username}/lmdeploy.git
-```
-
-After that, you should add official repository as the upstream repository
-
-```bash
-git remote add upstream git@github.com:InternLM/lmdeploy.git
-```
-
-Check whether remote repository has been added successfully by `git remote -v`
-
-```bash
-origin git@github.com:{username}/lmdeploy.git (fetch)
-origin git@github.com:{username}/lmdeploy.git (push)
-upstream git@github.com:InternLM/lmdeploy.git (fetch)
-upstream git@github.com:InternLM/lmdeploy.git (push)
-```
-
-> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
-
-#### 2. Configure pre-commit
-
-You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of InternLM. **Note**: The following code should be executed under the lmdeploy directory.
-
-```shell
-pip install -U pre-commit
-pre-commit install
-```
-
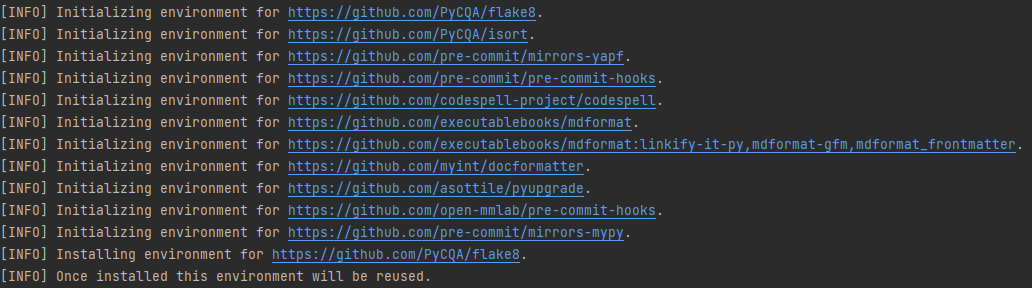
-Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
-
-```shell
-pre-commit run --all-files
-```
-
-
-
-Then, you can clone the repositories to local:
-
-```shell
-git clone git@github.com:{username}/lmdeploy.git
-```
-
-After that, you should add official repository as the upstream repository
-
-```bash
-git remote add upstream git@github.com:InternLM/lmdeploy.git
-```
-
-Check whether remote repository has been added successfully by `git remote -v`
-
-```bash
-origin git@github.com:{username}/lmdeploy.git (fetch)
-origin git@github.com:{username}/lmdeploy.git (push)
-upstream git@github.com:InternLM/lmdeploy.git (fetch)
-upstream git@github.com:InternLM/lmdeploy.git (push)
-```
-
-> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
-
-#### 2. Configure pre-commit
-
-You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of InternLM. **Note**: The following code should be executed under the lmdeploy directory.
-
-```shell
-pip install -U pre-commit
-pre-commit install
-```
-
-Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
-
-```shell
-pre-commit run --all-files
-```
-
- -
-
-
-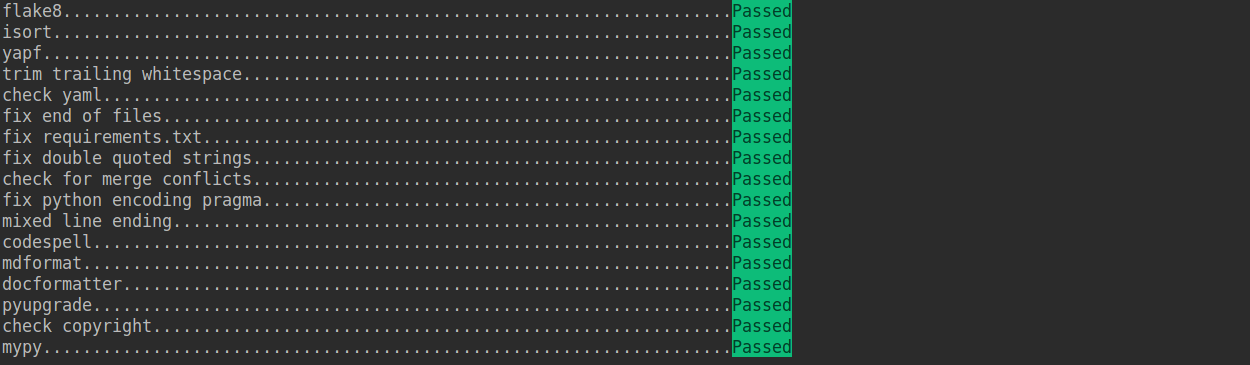 -
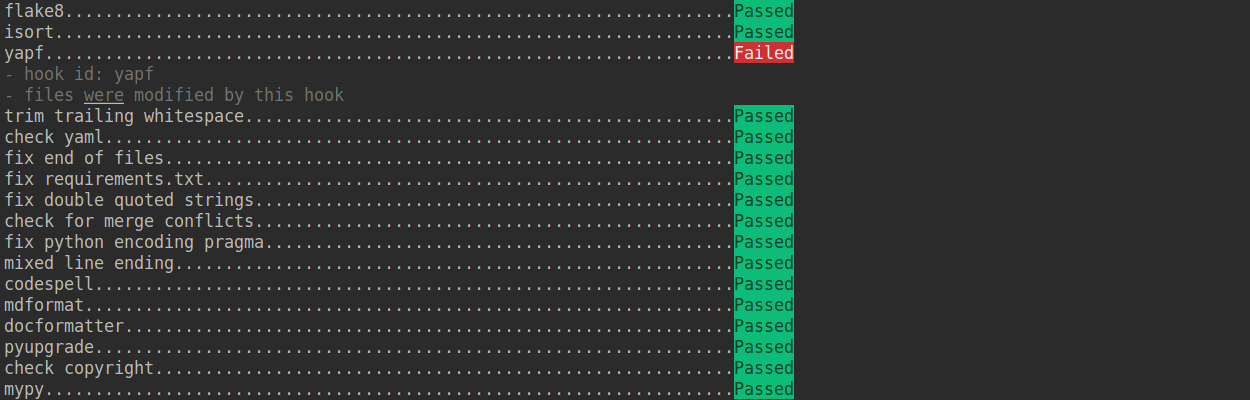
-If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
-
-If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
-
-
-
-If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
-
-If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
-
- -
-If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
-
-```shell
-git commit -m "xxx" --no-verify
-```
-
-#### 3. Create a development branch
-
-After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
-
-```shell
-git checkout -b yhc/refactor_contributing_doc
-```
-
-In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
-
-```shell
-git pull upstream master
-```
-
-#### 4. Commit the code and pass the unit test
-
-- lmdeploy introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
-
-- The committed code should pass through the unit test
-
- ```shell
- # Pass all unit tests
- pytest tests
-
- # Pass the unit test of runner
- pytest tests/test_runner/test_runner.py
- ```
-
- If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
-
-- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
-
-#### 5. Push the code to remote
-
-We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
-
-```shell
-git push -u origin {branch_name}
-```
-
-This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
-
-#### 6. Create a Pull Request
-
-(1) Create a pull request in GitHub's Pull request interface
-
-
-
-If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
-
-```shell
-git commit -m "xxx" --no-verify
-```
-
-#### 3. Create a development branch
-
-After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
-
-```shell
-git checkout -b yhc/refactor_contributing_doc
-```
-
-In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
-
-```shell
-git pull upstream master
-```
-
-#### 4. Commit the code and pass the unit test
-
-- lmdeploy introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
-
-- The committed code should pass through the unit test
-
- ```shell
- # Pass all unit tests
- pytest tests
-
- # Pass the unit test of runner
- pytest tests/test_runner/test_runner.py
- ```
-
- If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
-
-- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
-
-#### 5. Push the code to remote
-
-We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
-
-```shell
-git push -u origin {branch_name}
-```
-
-This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
-
-#### 6. Create a Pull Request
-
-(1) Create a pull request in GitHub's Pull request interface
-
- -
-(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
-
-
-
-(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
-
- -
-Find more details about Pull Request description in [pull request guidelines](#pr-specs).
-
-**note**
-
-(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
-
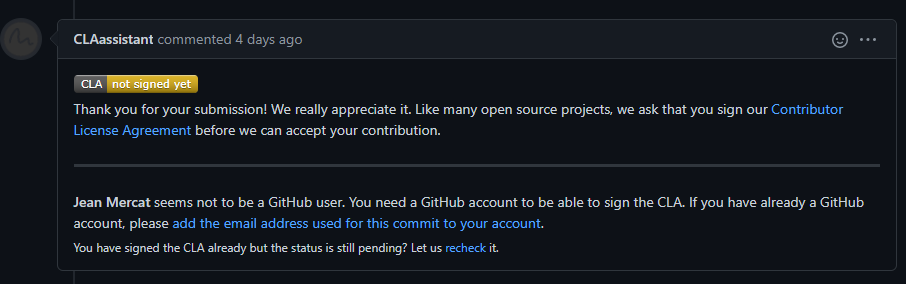
-(b) If it is your first contribution, please sign the CLA
-
-
-
-Find more details about Pull Request description in [pull request guidelines](#pr-specs).
-
-**note**
-
-(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
-
-(b) If it is your first contribution, please sign the CLA
-
- -
-(c) Check whether the Pull Request pass through the CI
-
-
-
-(c) Check whether the Pull Request pass through the CI
-
- -
-IternLM will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
-
-(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
-
-
-
-IternLM will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
-
-(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
-
- -
-#### 7. Resolve conflicts
-
-If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
-
-```shell
-git fetch --all --prune
-git rebase upstream/master
-```
-
-or
-
-```shell
-git fetch --all --prune
-git merge upstream/master
-```
-
-If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
-
-### Guidance
-
-#### Document rendering
-
-If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
-
-```shell
-pip install -r requirements/docs.txt
-cd docs/zh_cn/
-# or docs/en
-make html
-# check file in ./docs/zh_cn/_build/html/index.html
-```
-
-### Code style
-
-#### Python
-
-We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
-
-We use the following tools for linting and formatting:
-
-- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
-- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
-- [yapf](https://github.com/google/yapf): A formatter for Python files.
-- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
-- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
-- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
-
-We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
-fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
-The config for a pre-commit hook is stored in [.pre-commit-config](../.pre-commit-config.yaml).
-
-#### C++ and CUDA
-
-The clang-format config is stored in [.clang-format](../.clang-format).
-
-### PR Specs
-
-1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
-
-2. One short-time branch should be matched with only one PR
-
-3. Accomplish a detailed change in one PR. Avoid large PR
-
- - Bad: Support Faster R-CNN
- - Acceptable: Add a box head to Faster R-CNN
- - Good: Add a parameter to box head to support custom conv-layer number
-
-4. Provide clear and significant commit message
-
-5. Provide clear and meaningful PR description
-
- - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
- - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
- - Introduce main changes, results and influences on other modules in short description
- - Associate related issues and pull requests with a milestone
diff --git a/.github/ISSUE_TEMPLATE/1-bug-report.yml b/.github/ISSUE_TEMPLATE/1-bug-report.yml
deleted file mode 100644
index 86838836de567f984fc4e0829012a3a702ebb535..0000000000000000000000000000000000000000
--- a/.github/ISSUE_TEMPLATE/1-bug-report.yml
+++ /dev/null
@@ -1,40 +0,0 @@
-name: 🐞 Bug report
-description: Create a report to help us reproduce and fix the bug
-title: "[Bug] "
-labels: ['Bug']
-
-body:
-- type: checkboxes
- attributes:
- label: Checklist
- options:
- - label: 1. I have searched related issues but cannot get the expected help.
- - label: 2. The bug has not been fixed in the latest version.
-- type: textarea
- attributes:
- label: Describe the bug
- description: A clear and concise description of what the bug is.
- validations:
- required: true
-- type: textarea
- attributes:
- label: Reproduction
- description: |
- 1. What command or script did you run?
- placeholder: |
- A placeholder for the command.
- validations:
- required: true
-- type: textarea
- attributes:
- label: Error traceback
- description: |
- If applicable, paste the error trackback here.
- placeholder: Logs and traceback here.
- render: Shell
-- type: markdown
- attributes:
- value: >
- If you have already identified the reason, you can provide the information here. If you are willing to create a PR to fix it, please also leave a comment here and that would be much appreciated!
-
- Thanks for your bug report. We appreciate it a lot.
diff --git a/.github/ISSUE_TEMPLATE/2-feature-request.yml b/.github/ISSUE_TEMPLATE/2-feature-request.yml
deleted file mode 100644
index 976997e14c0b401f7ae58ed9959478880962f62c..0000000000000000000000000000000000000000
--- a/.github/ISSUE_TEMPLATE/2-feature-request.yml
+++ /dev/null
@@ -1,31 +0,0 @@
-name: 🚀 Feature request
-description: Suggest an idea for this project
-title: "[Feature] "
-
-body:
-- type: markdown
- attributes:
- value: |
- We strongly appreciate you creating a PR to implement this feature [here](https://github.com/InternLM/lmdeploy/pulls)!
- If you need our help, please fill in as much of the following form as you're able to.
-
- **The less clear the description, the longer it will take to solve it.**
-- type: textarea
- attributes:
- label: Motivation
- description: |
- A clear and concise description of the motivation of the feature.
- Ex1. It is inconvenient when \[....\].
- validations:
- required: true
-- type: textarea
- attributes:
- label: Related resources
- description: |
- If there is an official code release or third-party implementations, please also provide the information here, which would be very helpful.
-- type: textarea
- attributes:
- label: Additional context
- description: |
- Add any other context or screenshots about the feature request here.
- If you would like to implement the feature and create a PR, please leave a comment here and that would be much appreciated.
diff --git a/.github/ISSUE_TEMPLATE/3-documentation.yml b/.github/ISSUE_TEMPLATE/3-documentation.yml
deleted file mode 100644
index b112c2aea6ad2d5fe68fbfec9bfb2ff43da996e7..0000000000000000000000000000000000000000
--- a/.github/ISSUE_TEMPLATE/3-documentation.yml
+++ /dev/null
@@ -1,23 +0,0 @@
-name: 📚 Documentation
-description: Report an issue related to the documentation.
-labels: "kind/doc,status/unconfirmed"
-title: "[Docs] "
-
-body:
-- type: textarea
- attributes:
- label: 📚 The doc issue
- description: >
- A clear and concise description the issue.
- validations:
- required: true
-
-- type: textarea
- attributes:
- label: Suggest a potential alternative/fix
- description: >
- Tell us how we could improve the documentation in this regard.
-- type: markdown
- attributes:
- value: >
- Thanks for contributing 🎉!
diff --git a/.github/md-link-config.json b/.github/md-link-config.json
deleted file mode 100644
index 76986cbd01cf43f1bad7effa03409e0c053c4cca..0000000000000000000000000000000000000000
--- a/.github/md-link-config.json
+++ /dev/null
@@ -1,33 +0,0 @@
-{
- "ignorePatterns": [
-
- {
- "pattern": "^https://developer.nvidia.com/"
- },
- {
- "pattern": "^https://docs.openvino.ai/"
- },
- {
- "pattern": "^https://developer.android.com/"
- },
- {
- "pattern": "^https://developer.qualcomm.com/"
- },
- {
- "pattern": "^http://localhost"
- }
- ],
- "httpHeaders": [
- {
- "urls": ["https://github.com/", "https://guides.github.com/", "https://help.github.com/", "https://docs.github.com/"],
- "headers": {
- "Accept-Encoding": "zstd, br, gzip, deflate"
- }
- }
- ],
- "timeout": "20s",
- "retryOn429": true,
- "retryCount": 5,
- "fallbackRetryDelay": "30s",
- "aliveStatusCodes": [200, 206, 429]
-}
diff --git a/.github/pull_request_template.md b/.github/pull_request_template.md
deleted file mode 100644
index addb1f6dd8412d8f77683594b4a5551536e6c0d6..0000000000000000000000000000000000000000
--- a/.github/pull_request_template.md
+++ /dev/null
@@ -1,25 +0,0 @@
-Thanks for your contribution and we appreciate it a lot. The following instructions would make your pull request more healthy and more easily receiving feedbacks. If you do not understand some items, don't worry, just make the pull request and seek help from maintainers.
-
-## Motivation
-
-Please describe the motivation of this PR and the goal you want to achieve through this PR.
-
-## Modification
-
-Please briefly describe what modification is made in this PR.
-
-## BC-breaking (Optional)
-
-Does the modification introduce changes that break the backward-compatibility of the downstream repositories?
-If so, please describe how it breaks the compatibility and how the downstream projects should modify their code to keep compatibility with this PR.
-
-## Use cases (Optional)
-
-If this PR introduces a new feature, it is better to list some use cases here, and update the documentation.
-
-## Checklist
-
-1. Pre-commit or other linting tools are used to fix the potential lint issues.
-2. The modification is covered by complete unit tests. If not, please add more unit tests to ensure the correctness.
-3. If the modification has a dependency on downstream projects of a newer version, this PR should be tested with all supported versions of downstream projects.
-4. The documentation has been modified accordingly, like docstring or example tutorials.
diff --git a/.github/release.yml b/.github/release.yml
deleted file mode 100644
index 4feb7be54a47c72f7e9671bf0d5378cce5e5fb2d..0000000000000000000000000000000000000000
--- a/.github/release.yml
+++ /dev/null
@@ -1,33 +0,0 @@
-changelog:
- categories:
- - title: 🚀 Features
- labels:
- - feature
- - enhancement
- - title: 💥 Improvements
- labels:
- - improvement
- - title: 🐞 Bug fixes
- labels:
- - bug
- - Bug:P0
- - Bug:P1
- - Bug:P2
- - Bug:P3
- - title: 📚 Documentations
- labels:
- - documentation
- - title: 🌐 Other
- labels:
- - '*'
- exclude:
- labels:
- - feature
- - enhancement
- - improvement
- - bug
- - documentation
- - Bug:P0
- - Bug:P1
- - Bug:P2
- - Bug:P3
diff --git a/.github/scripts/doc_link_checker.py b/.github/scripts/doc_link_checker.py
deleted file mode 100644
index 3933360c88f5e1cbe46d93886c4494c165e98409..0000000000000000000000000000000000000000
--- a/.github/scripts/doc_link_checker.py
+++ /dev/null
@@ -1,86 +0,0 @@
-# Copyright (c) MegFlow. All rights reserved.
-# /bin/python3
-
-import argparse
-import os
-import re
-
-
-def make_parser():
- parser = argparse.ArgumentParser('Doc link checker')
- parser.add_argument('--http',
- default=False,
- type=bool,
- help='check http or not ')
- parser.add_argument('--target',
- default='./docs',
- type=str,
- help='the directory or file to check')
- return parser
-
-
-pattern = re.compile(r'\[.*?\]\(.*?\)')
-
-
-def analyze_doc(home, path):
- print('analyze {}'.format(path))
- problem_list = []
- code_block = 0
- with open(path) as f:
- lines = f.readlines()
- for line in lines:
- line = line.strip()
- if line.startswith('```'):
- code_block = 1 - code_block
-
- if code_block > 0:
- continue
-
- if '[' in line and ']' in line and '(' in line and ')' in line:
- all = pattern.findall(line)
- for item in all:
- # skip ![]()
- if item.find('[') == item.find(']') - 1:
- continue
-
- # process the case [text()]()
- offset = item.find('](')
- if offset == -1:
- continue
- item = item[offset:]
- start = item.find('(')
- end = item.find(')')
- ref = item[start + 1:end]
-
- if ref.startswith('http') or ref.startswith('#'):
- continue
- if '.md#' in ref:
- ref = ref[ref.find('#'):]
- fullpath = os.path.join(home, ref)
- if not os.path.exists(fullpath):
- problem_list.append(ref)
- else:
- continue
- if len(problem_list) > 0:
- print(f'{path}:')
- for item in problem_list:
- print(f'\t {item}')
- print('\n')
- raise Exception('found link error')
-
-
-def traverse(target):
- if os.path.isfile(target):
- analyze_doc(os.path.dirname(target), target)
- return
- for home, dirs, files in os.walk(target):
- for filename in files:
- if filename.endswith('.md'):
- path = os.path.join(home, filename)
- if os.path.islink(path) is False:
- analyze_doc(home, path)
-
-
-if __name__ == '__main__':
- args = make_parser().parse_args()
- traverse(args.target)
diff --git a/.github/workflows/docker.yml b/.github/workflows/docker.yml
deleted file mode 100644
index dc511080783059e5575b2c9d5782c51f1270dbeb..0000000000000000000000000000000000000000
--- a/.github/workflows/docker.yml
+++ /dev/null
@@ -1,62 +0,0 @@
-name: publish-docker
-
-on:
- push:
- paths-ignore:
- - "!.github/workflows/docker.yml"
- - ".github/**"
- - "docs/**"
- - "resources/**"
- - "benchmark/**"
- - "tests/**"
- - "**/*.md"
- branches:
- - main
- tags:
- - "v*.*.*"
-
-jobs:
- publish_docker_image:
- runs-on: ubuntu-latest
- environment: 'prod'
- env:
- TAG_PREFIX: "openmmlab/lmdeploy"
- steps:
- - name: Checkout repository
- uses: actions/checkout@v3
- - name: Free disk space
- uses: jlumbroso/free-disk-space@main
- with:
- # This might remove tools that are actually needed, if set to "true" but frees about 6 GB
- tool-cache: false
- docker-images: false
- # All of these default to true, but feel free to set to "false" if necessary for your workflow
- android: true
- dotnet: true
- haskell: true
- large-packages: true
- swap-storage: false
- - name: Get docker info
- run: |
- docker info
- - name: Login to Docker Hub
- uses: docker/login-action@v2
- with:
- username: ${{ secrets.DOCKERHUB_USERNAME }}
- password: ${{ secrets.DOCKERHUB_TOKEN }}
- - name: Build and push the latest Docker image
- run: |
- export TAG=$TAG_PREFIX:latest
- echo $TAG
- docker build docker/ -t ${TAG} --no-cache
- docker push $TAG
- echo "TAG=${TAG}" >> $GITHUB_ENV
- - name: Push docker image with released tag
- if: startsWith(github.ref, 'refs/tags/') == true
- run: |
- export LMDEPLOY_VERSION=$(python3 -c "import sys; sys.path.append('lmdeploy');from version import __version__;print(__version__)")
- echo $LMDEPLOY_VERSION
- export RELEASE_TAG=${TAG_PREFIX}:v${LMDEPLOY_VERSION}
- echo $RELEASE_TAG
- docker tag $TAG $RELEASE_TAG
- docker push $RELEASE_TAG
diff --git a/.github/workflows/lint.yml b/.github/workflows/lint.yml
deleted file mode 100644
index a6f2e6374a41ba21cf2eb7cb5c7554b22ceaae86..0000000000000000000000000000000000000000
--- a/.github/workflows/lint.yml
+++ /dev/null
@@ -1,46 +0,0 @@
-name: lint
-
-on: [push, pull_request]
-
-jobs:
- lint:
- runs-on: ubuntu-20.04
- steps:
- - uses: actions/checkout@v2
- - name: Set up Python 3.8
- uses: actions/setup-python@v2
- with:
- python-version: 3.8
- - name: Install pre-commit hook
- run: |
- python -m pip install pre-commit
- pre-commit install
- - name: Linting
- run: pre-commit run --all-files
- - name: Format c/cuda codes with clang-format
- uses: DoozyX/clang-format-lint-action@v0.13
- with:
- source: src
- extensions: h,c,cpp,hpp,cu,cuh
- clangFormatVersion: 11
- style: file
- - name: Check markdown link
- uses: gaurav-nelson/github-action-markdown-link-check@v1
- with:
- use-quiet-mode: 'yes'
- use-verbose-mode: 'yes'
-# check-modified-files-only: 'yes'
- config-file: '.github/md-link-config.json'
- file-path: './README.md, ./LICENSE, ./README_zh-CN.md'
- - name: Check doc link
- run: |
- python .github/scripts/doc_link_checker.py --target README_zh-CN.md
- python .github/scripts/doc_link_checker.py --target README.md
- - name: Check docstring coverage
- run: |
- python -m pip install interrogate
- interrogate -v --ignore-init-method --ignore-magic --ignore-module --ignore-private --ignore-nested-functions --ignore-nested-classes --fail-under 80 lmdeploy
- - name: Check pylint score
- run: |
- python -m pip install pylint
- pylint lmdeploy
diff --git a/.github/workflows/linux-x64-gpu.yml b/.github/workflows/linux-x64-gpu.yml
deleted file mode 100644
index d940408ce7536cbdbf082528d00da79c01f81571..0000000000000000000000000000000000000000
--- a/.github/workflows/linux-x64-gpu.yml
+++ /dev/null
@@ -1,56 +0,0 @@
-name: linux-x64-gpu
-on:
- push:
- paths:
- - '.github/workflows/linux-x64-gpu.yml'
- - 'src/**'
- - 'CMakeLists.txt'
- - 'cmake/**'
- - 'examples/**'
- - '3rdparty/**'
- - 'tests/csrc/**'
- pull_request:
- paths:
- - '.github/workflows/linux-x64-gpu.yml'
- - 'src/**'
- - 'CMakeLists.txt'
- - 'cmake/**'
- - 'examples/**'
- - '3rdparty/**'
- - 'tests/csrc/**'
-concurrency:
- group: linux-x64-gpu-${{ github.ref }}
- cancel-in-progress: true
-permissions:
- contents: read
-
-jobs:
- cuda-118:
- runs-on: ubuntu-latest
- steps:
- - name: Free disk space
- uses: jlumbroso/free-disk-space@main
- with:
- # This might remove tools that are actually needed, if set to "true" but frees about 6 GB
- tool-cache: false
- docker-images: false
- # All of these default to true, but feel free to set to "false" if necessary for your workflow
- android: true
- dotnet: true
- haskell: true
- large-packages: true
- swap-storage: false
- - name: Checkout repository
- uses: actions/checkout@v3
- - name: Build
- uses: addnab/docker-run-action@v3
- with:
- image: openmmlab/lmdeploy-builder:cuda11.8
- options: -v ${{ github.workspace }}:/work --cpus=1.8
- run: |
- cd /work
- source /opt/conda/bin/activate
- conda activate py38
- mkdir build && cd build
- bash ../generate.sh
- make -j$(nproc) && make install
diff --git a/.github/workflows/pypi.yml b/.github/workflows/pypi.yml
deleted file mode 100644
index 7c56e08f7d4ac0009bd96ac73fa73dd1a3437aa6..0000000000000000000000000000000000000000
--- a/.github/workflows/pypi.yml
+++ /dev/null
@@ -1,109 +0,0 @@
-name: publish to pypi
-
-on:
- push:
- branches:
- - main
- paths:
- - "lmdeploy/version.py"
- workflow_dispatch:
-
-
-jobs:
- linux-build:
- strategy:
- matrix:
- pyver: [py38, py39, py310, py311]
- runs-on: ubuntu-latest
- env:
- PYTHON_VERSION: ${{ matrix.pyver }}
- PLAT_NAME: manylinux2014_x86_64
- DOCKER_TAG: cuda11.8
- OUTPUT_FOLDER: cuda11.8_dist
- steps:
- - name: Free disk space
- uses: jlumbroso/free-disk-space@main
- with:
- # This might remove tools that are actually needed, if set to "true" but frees about 6 GB
- tool-cache: false
- docker-images: false
- # All of these default to true, but feel free to set to "false" if necessary for your workflow
- android: true
- dotnet: true
- haskell: true
- large-packages: true
- swap-storage: false
- - name: Checkout repository
- uses: actions/checkout@v3
- - name: Build
- run: |
- echo ${PYTHON_VERSION}
- echo ${PLAT_NAME}
- echo ${DOCKER_TAG}
- echo ${OUTPUT_FOLDER}
- # remove -it
- sed -i 's/docker run --rm -it/docker run --rm/g' builder/manywheel/build_wheel.sh
- bash builder/manywheel/build_wheel.sh ${PYTHON_VERSION} ${PLAT_NAME} ${DOCKER_TAG} ${OUTPUT_FOLDER}
- - name: Upload Artifacts
- uses: actions/upload-artifact@v3
- with:
- if-no-files-found: error
- path: builder/manywheel/${{ env.OUTPUT_FOLDER }}/*
- retention-days: 1
-
- windows-build:
- strategy:
- matrix:
- pyver: ['3.8', '3.9', '3.10', '3.11']
- runs-on: windows-latest
- steps:
- - name: Checkout repository
- uses: actions/checkout@v3
- - name: Set up python
- uses: actions/setup-python@v4
- with:
- python-version: ${{ matrix.pyver }}
- - name: Install python packages
- run: |
- pip install pybind11 wheel
- - uses: Jimver/cuda-toolkit@v0.2.11
- id: cuda-toolkit
- with:
- cuda: '11.8.0'
- use-github-cache: false
- - name: Build wheel
- run: |
- mkdir build
- cd build
- ..\builder\windows\generate.ps1
- cmake --build . --config Release -- /m > build.log.txt
- cmake --install . --config Release
- cd ..
- rm build -Force -Recurse
- python setup.py bdist_wheel -d build/wheel
- - name: Upload Artifacts
- uses: actions/upload-artifact@v3
- with:
- if-no-files-found: error
- path: build/wheel/*
- retention-days: 1
-
- publish:
- runs-on: ubuntu-latest
- environment: 'prod'
- needs:
- - linux-build
- - windows-build
- steps:
- - name: Download artifacts
- uses: actions/download-artifact@v3
- - name: Display artifacts
- run: ls artifact/ -lh
- - name: Set up python3.8
- uses: actions/setup-python@v4
- with:
- python-version: '3.8'
- - name: Upload to pypi
- run: |
- pip install twine
- twine upload artifact/* -u __token__ -p ${{ secrets.pypi_password }}
diff --git a/.github/workflows/stale.yml b/.github/workflows/stale.yml
deleted file mode 100644
index 93df0cd47c7ddef6870ae3e4d0e0acfd55f792a6..0000000000000000000000000000000000000000
--- a/.github/workflows/stale.yml
+++ /dev/null
@@ -1,32 +0,0 @@
-name: 'Close stale issues and PRs'
-
-on:
- schedule:
- # check issue and pull request once at 01:30 a.m. every day
- - cron: '30 1 * * *'
-
-permissions:
- contents: read
-
-jobs:
- stale:
- permissions:
- issues: write
- pull-requests: write
- runs-on: ubuntu-latest
- steps:
- - uses: actions/stale@v7
- with:
- stale-issue-message: 'This issue is marked as stale because it has been marked as invalid or awaiting response for 7 days without any further response. It will be closed in 5 days if the stale label is not removed or if there is no further response.'
- stale-pr-message: 'This PR is marked as stale because there has been no activity in the past 45 days. It will be closed in 10 days if the stale label is not removed or if there is no further updates.'
- close-issue-message: 'This issue is closed because it has been stale for 5 days. Please open a new issue if you have similar issues or you have any new updates now.'
- close-pr-message: 'This PR is closed because it has been stale for 10 days. Please reopen this PR if you have any updates and want to keep contributing the code.'
- # only issues/PRS with following labels are checked
- any-of-labels: 'invalid, awaiting response, duplicate'
- days-before-issue-stale: 7
- days-before-pr-stale: 45
- days-before-issue-close: 5
- days-before-pr-close: 10
- # automatically remove the stale label when the issues or the pull requests are updated or commented
- remove-stale-when-updated: true
- operations-per-run: 50
diff --git a/.github/workflows/windows-x64-gpu.yml b/.github/workflows/windows-x64-gpu.yml
deleted file mode 100644
index 93839cfb89b07d47e80fb6d30305028caf92e93a..0000000000000000000000000000000000000000
--- a/.github/workflows/windows-x64-gpu.yml
+++ /dev/null
@@ -1,60 +0,0 @@
-name: windows-x64-gpu
-on:
- push:
- paths:
- - '.github/workflows/windows-x64-gpu.yml'
- - 'src/**'
- - 'CMakeLists.txt'
- - 'cmake/**'
- - 'examples/**'
- - '3rdparty/**'
- - 'tests/csrc/**'
- pull_request:
- paths:
- - '.github/workflows/windows-x64-gpu.yml'
- - 'src/**'
- - 'CMakeLists.txt'
- - 'cmake/**'
- - 'examples/**'
- - '3rdparty/**'
- - 'tests/csrc/**'
-concurrency:
- group: windows-x64-gpu-${{ github.ref }}
- cancel-in-progress: true
-permissions:
- contents: read
-
-jobs:
- cuda-118:
- runs-on: windows-latest
- steps:
- - name: Checkout repository
- uses: actions/checkout@v3
- - name: Set up python
- uses: actions/setup-python@v4
- with:
- python-version: '3.8'
- - name: Install python packages
- run: |
- pip install pybind11 wheel
- - uses: Jimver/cuda-toolkit@v0.2.11
- id: cuda-toolkit
- with:
- cuda: '11.8.0'
- use-github-cache: false
- - name: Build wheel
- run: |
- ((Get-Content -path CMakeLists.txt -Raw) -replace '-Wall','/W0') | Set-Content CMakeLists.txt
- $env:BUILD_TEST="ON"
- mkdir build
- cd build
- ..\builder\windows\generate.ps1
- cmake --build . --config Release -- /m /v:q
- if (-Not $?) {
- echo "build failed"
- exit 1
- }
- cmake --install . --config Release
- cd ..
- rm build -Force -Recurse
- python setup.py bdist_wheel -d build/wheel
diff --git a/.gitignore b/.gitignore
deleted file mode 100644
index ccfad036dcd04f55b0eac63fb40377e15509f409..0000000000000000000000000000000000000000
--- a/.gitignore
+++ /dev/null
@@ -1,74 +0,0 @@
-# Byte-compiled / optimized / DLL files
-__pycache__/
-*.py[cod]
-*$py.class
-.vscode/
-.idea/
-# C extensions
-*.so
-
-# Distribution / packaging
-.Python
-develop-eggs/
-dist/
-downloads/
-eggs/
-.eggs/
-lib/
-lib64/
-parts/
-sdist/
-var/
-wheels/
-*.egg-info/
-.installed.cfg
-*.egg
-MANIFEST
-
-# PyInstaller
-# Usually these files are written by a python script from a template
-# before PyInstaller builds the exe, so as to inject date/other infos into it.
-*.manifest
-*.spec
-
-# Installer logs
-pip-log.txt
-pip-delete-this-directory.txt
-
-# Unit test / coverage reports
-htmlcov/
-.tox/
-.coverage
-.coverage.*
-.cache
-*build*/
-!builder/
-lmdeploy/lib/
-lmdeploy/bin/
-dist/
-examples/cpp/llama/*.csv
-*.npy
-*.weight
-
-# LMDeploy
-workspace/
-work_dir*/
-
-# Huggingface
-*.bin
-*config.json
-*generate_config.json
-
-# Pytorch
-*.pth
-*.py~
-*.sh~
-*.pyc
-**/src/pytorch-sphinx-theme/
-
-# Outputs and logs
-*.txt
-*.log
-*.out
-*.csv
-*.pkl
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
deleted file mode 100644
index fb5f4d1b36481da818614029b8fa51c696dfe9d8..0000000000000000000000000000000000000000
--- a/.pre-commit-config.yaml
+++ /dev/null
@@ -1,53 +0,0 @@
-repos:
- - repo: https://github.com/PyCQA/flake8
- rev: 4.0.1
- hooks:
- - id: flake8
- args: ["--exclude=lmdeploy/turbomind/triton_models/*"]
- - repo: https://github.com/PyCQA/isort
- rev: 5.11.5
- hooks:
- - id: isort
- - repo: https://github.com/pre-commit/mirrors-yapf
- rev: v0.32.0
- hooks:
- - id: yapf
- - repo: https://github.com/pre-commit/pre-commit-hooks
- rev: v4.2.0
- hooks:
- - id: trailing-whitespace
- - id: check-yaml
- - id: end-of-file-fixer
- - id: requirements-txt-fixer
- - id: double-quote-string-fixer
- - id: check-merge-conflict
- - id: fix-encoding-pragma
- args: ["--remove"]
- - id: mixed-line-ending
- args: ["--fix=lf"]
- - repo: https://github.com/executablebooks/mdformat
- rev: 0.7.9
- hooks:
- - id: mdformat
- args: ["--number"]
- additional_dependencies:
- - mdformat-openmmlab
- - mdformat_frontmatter
- - linkify-it-py
- - repo: https://github.com/codespell-project/codespell
- rev: v2.1.0
- hooks:
- - id: codespell
- args: ["--skip=third_party/*,*.ipynb,*.proto"]
-
- - repo: https://github.com/myint/docformatter
- rev: v1.4
- hooks:
- - id: docformatter
- args: ["--in-place", "--wrap-descriptions", "79"]
-
- - repo: https://github.com/open-mmlab/pre-commit-hooks
- rev: v0.2.0
- hooks:
- - id: check-copyright
- args: ["lmdeploy"]
diff --git a/.pylintrc b/.pylintrc
deleted file mode 100644
index d46a1c7f31f05969869ec52d7508f70130d40e32..0000000000000000000000000000000000000000
--- a/.pylintrc
+++ /dev/null
@@ -1,625 +0,0 @@
-[MASTER]
-
-# A comma-separated list of package or module names from where C extensions may
-# be loaded. Extensions are loading into the active Python interpreter and may
-# run arbitrary code.
-extension-pkg-whitelist=
-
-# Specify a score threshold to be exceeded before program exits with error.
-fail-under=8.5
-
-# Add files or directories to the blacklist. They should be base names, not
-# paths.
-ignore=CVS,configs
-
-# Add files or directories matching the regex patterns to the blacklist. The
-# regex matches against base names, not paths.
-ignore-patterns=
-
-# Python code to execute, usually for sys.path manipulation such as
-# pygtk.require().
-#init-hook=
-
-# Use multiple processes to speed up Pylint. Specifying 0 will auto-detect the
-# number of processors available to use.
-jobs=1
-
-# Control the amount of potential inferred values when inferring a single
-# object. This can help the performance when dealing with large functions or
-# complex, nested conditions.
-limit-inference-results=100
-
-# List of plugins (as comma separated values of python module names) to load,
-# usually to register additional checkers.
-load-plugins=
-
-# Pickle collected data for later comparisons.
-persistent=yes
-
-# When enabled, pylint would attempt to guess common misconfiguration and emit
-# user-friendly hints instead of false-positive error messages.
-suggestion-mode=yes
-
-# Allow loading of arbitrary C extensions. Extensions are imported into the
-# active Python interpreter and may run arbitrary code.
-unsafe-load-any-extension=no
-
-
-[MESSAGES CONTROL]
-
-# Only show warnings with the listed confidence levels. Leave empty to show
-# all. Valid levels: HIGH, INFERENCE, INFERENCE_FAILURE, UNDEFINED.
-confidence=
-
-# Disable the message, report, category or checker with the given id(s). You
-# can either give multiple identifiers separated by comma (,) or put this
-# option multiple times (only on the command line, not in the configuration
-# file where it should appear only once). You can also use "--disable=all" to
-# disable everything first and then reenable specific checks. For example, if
-# you want to run only the similarities checker, you can use "--disable=all
-# --enable=similarities". If you want to run only the classes checker, but have
-# no Warning level messages displayed, use "--disable=all --enable=classes
-# --disable=W".
-disable=print-statement,
- parameter-unpacking,
- unpacking-in-except,
- old-raise-syntax,
- backtick,
- long-suffix,
- old-ne-operator,
- old-octal-literal,
- import-star-module-level,
- non-ascii-bytes-literal,
- raw-checker-failed,
- bad-inline-option,
- locally-disabled,
- file-ignored,
- suppressed-message,
- useless-suppression,
- deprecated-pragma,
- use-symbolic-message-instead,
- apply-builtin,
- basestring-builtin,
- buffer-builtin,
- cmp-builtin,
- coerce-builtin,
- execfile-builtin,
- file-builtin,
- long-builtin,
- raw_input-builtin,
- reduce-builtin,
- standarderror-builtin,
- unicode-builtin,
- xrange-builtin,
- coerce-method,
- delslice-method,
- getslice-method,
- setslice-method,
- no-absolute-import,
- old-division,
- dict-iter-method,
- dict-view-method,
- next-method-called,
- metaclass-assignment,
- indexing-exception,
- raising-string,
- reload-builtin,
- oct-method,
- hex-method,
- nonzero-method,
- cmp-method,
- input-builtin,
- round-builtin,
- intern-builtin,
- unichr-builtin,
- map-builtin-not-iterating,
- zip-builtin-not-iterating,
- range-builtin-not-iterating,
- filter-builtin-not-iterating,
- using-cmp-argument,
- eq-without-hash,
- div-method,
- idiv-method,
- rdiv-method,
- exception-message-attribute,
- invalid-str-codec,
- sys-max-int,
- bad-python3-import,
- deprecated-string-function,
- deprecated-str-translate-call,
- deprecated-itertools-function,
- deprecated-types-field,
- next-method-defined,
- dict-items-not-iterating,
- dict-keys-not-iterating,
- dict-values-not-iterating,
- deprecated-operator-function,
- deprecated-urllib-function,
- xreadlines-attribute,
- deprecated-sys-function,
- exception-escape,
- comprehension-escape,
- no-member,
- invalid-name,
- too-many-branches,
- wrong-import-order,
- too-many-arguments,
- missing-function-docstring,
- missing-module-docstring,
- too-many-locals,
- too-few-public-methods,
- abstract-method,
- broad-except,
- too-many-nested-blocks,
- too-many-instance-attributes,
- missing-class-docstring,
- duplicate-code,
- not-callable,
- protected-access,
- dangerous-default-value,
- no-name-in-module,
- logging-fstring-interpolation,
- super-init-not-called,
- redefined-builtin,
- attribute-defined-outside-init,
- arguments-differ,
- cyclic-import,
- bad-super-call,
- too-many-statements,
- unused-argument,
- import-outside-toplevel,
- import-error,
- super-with-arguments
-
-# Enable the message, report, category or checker with the given id(s). You can
-# either give multiple identifier separated by comma (,) or put this option
-# multiple time (only on the command line, not in the configuration file where
-# it should appear only once). See also the "--disable" option for examples.
-enable=c-extension-no-member
-
-
-[REPORTS]
-
-# Python expression which should return a score less than or equal to 10. You
-# have access to the variables 'error', 'warning', 'refactor', and 'convention'
-# which contain the number of messages in each category, as well as 'statement'
-# which is the total number of statements analyzed. This score is used by the
-# global evaluation report (RP0004).
-evaluation=10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10)
-
-# Template used to display messages. This is a python new-style format string
-# used to format the message information. See doc for all details.
-#msg-template=
-
-# Set the output format. Available formats are text, parseable, colorized, json
-# and msvs (visual studio). You can also give a reporter class, e.g.
-# mypackage.mymodule.MyReporterClass.
-output-format=text
-
-# Tells whether to display a full report or only the messages.
-reports=yes
-
-# Activate the evaluation score.
-score=yes
-
-
-[REFACTORING]
-
-# Maximum number of nested blocks for function / method body
-max-nested-blocks=5
-
-# Complete name of functions that never returns. When checking for
-# inconsistent-return-statements if a never returning function is called then
-# it will be considered as an explicit return statement and no message will be
-# printed.
-never-returning-functions=sys.exit
-
-
-[TYPECHECK]
-
-# List of decorators that produce context managers, such as
-# contextlib.contextmanager. Add to this list to register other decorators that
-# produce valid context managers.
-contextmanager-decorators=contextlib.contextmanager
-
-# List of members which are set dynamically and missed by pylint inference
-# system, and so shouldn't trigger E1101 when accessed. Python regular
-# expressions are accepted.
-generated-members=
-
-# Tells whether missing members accessed in mixin class should be ignored. A
-# mixin class is detected if its name ends with "mixin" (case insensitive).
-ignore-mixin-members=yes
-
-# Tells whether to warn about missing members when the owner of the attribute
-# is inferred to be None.
-ignore-none=yes
-
-# This flag controls whether pylint should warn about no-member and similar
-# checks whenever an opaque object is returned when inferring. The inference
-# can return multiple potential results while evaluating a Python object, but
-# some branches might not be evaluated, which results in partial inference. In
-# that case, it might be useful to still emit no-member and other checks for
-# the rest of the inferred objects.
-ignore-on-opaque-inference=yes
-
-# List of class names for which member attributes should not be checked (useful
-# for classes with dynamically set attributes). This supports the use of
-# qualified names.
-ignored-classes=optparse.Values,thread._local,_thread._local
-
-# List of module names for which member attributes should not be checked
-# (useful for modules/projects where namespaces are manipulated during runtime
-# and thus existing member attributes cannot be deduced by static analysis). It
-# supports qualified module names, as well as Unix pattern matching.
-ignored-modules=
-
-# Show a hint with possible names when a member name was not found. The aspect
-# of finding the hint is based on edit distance.
-missing-member-hint=yes
-
-# The minimum edit distance a name should have in order to be considered a
-# similar match for a missing member name.
-missing-member-hint-distance=1
-
-# The total number of similar names that should be taken in consideration when
-# showing a hint for a missing member.
-missing-member-max-choices=1
-
-# List of decorators that change the signature of a decorated function.
-signature-mutators=
-
-
-[SPELLING]
-
-# Limits count of emitted suggestions for spelling mistakes.
-max-spelling-suggestions=4
-
-# Spelling dictionary name. Available dictionaries: none. To make it work,
-# install the python-enchant package.
-spelling-dict=
-
-# List of comma separated words that should not be checked.
-spelling-ignore-words=
-
-# A path to a file that contains the private dictionary; one word per line.
-spelling-private-dict-file=
-
-# Tells whether to store unknown words to the private dictionary (see the
-# --spelling-private-dict-file option) instead of raising a message.
-spelling-store-unknown-words=no
-
-
-[LOGGING]
-
-# The type of string formatting that logging methods do. `old` means using %
-# formatting, `new` is for `{}` formatting.
-logging-format-style=old
-
-# Logging modules to check that the string format arguments are in logging
-# function parameter format.
-logging-modules=logging
-
-
-[VARIABLES]
-
-# List of additional names supposed to be defined in builtins. Remember that
-# you should avoid defining new builtins when possible.
-additional-builtins=
-
-# Tells whether unused global variables should be treated as a violation.
-allow-global-unused-variables=yes
-
-# List of strings which can identify a callback function by name. A callback
-# name must start or end with one of those strings.
-callbacks=cb_,
- _cb
-
-# A regular expression matching the name of dummy variables (i.e. expected to
-# not be used).
-dummy-variables-rgx=_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|dummy|^ignored_|^unused_
-
-# Argument names that match this expression will be ignored. Default to name
-# with leading underscore.
-ignored-argument-names=_.*|^ignored_|^unused_
-
-# Tells whether we should check for unused import in __init__ files.
-init-import=no
-
-# List of qualified module names which can have objects that can redefine
-# builtins.
-redefining-builtins-modules=six.moves,past.builtins,future.builtins,builtins,io
-
-
-[FORMAT]
-
-# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
-expected-line-ending-format=
-
-# Regexp for a line that is allowed to be longer than the limit.
-ignore-long-lines=^\s*(# )??$
-
-# Number of spaces of indent required inside a hanging or continued line.
-indent-after-paren=4
-
-# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1
-# tab).
-indent-string=' '
-
-# Maximum number of characters on a single line.
-max-line-length=100
-
-# Maximum number of lines in a module.
-max-module-lines=1000
-
-# Allow the body of a class to be on the same line as the declaration if body
-# contains single statement.
-single-line-class-stmt=no
-
-# Allow the body of an if to be on the same line as the test if there is no
-# else.
-single-line-if-stmt=no
-
-
-[STRING]
-
-# This flag controls whether inconsistent-quotes generates a warning when the
-# character used as a quote delimiter is used inconsistently within a module.
-check-quote-consistency=no
-
-# This flag controls whether the implicit-str-concat should generate a warning
-# on implicit string concatenation in sequences defined over several lines.
-check-str-concat-over-line-jumps=no
-
-
-[SIMILARITIES]
-
-# Ignore comments when computing similarities.
-ignore-comments=yes
-
-# Ignore docstrings when computing similarities.
-ignore-docstrings=yes
-
-# Ignore imports when computing similarities.
-ignore-imports=no
-
-# Minimum lines number of a similarity.
-min-similarity-lines=4
-
-
-[MISCELLANEOUS]
-
-# List of note tags to take in consideration, separated by a comma.
-notes=FIXME,
- XXX,
- TODO
-
-# Regular expression of note tags to take in consideration.
-#notes-rgx=
-
-
-[BASIC]
-
-# Naming style matching correct argument names.
-argument-naming-style=snake_case
-
-# Regular expression matching correct argument names. Overrides argument-
-# naming-style.
-#argument-rgx=
-
-# Naming style matching correct attribute names.
-attr-naming-style=snake_case
-
-# Regular expression matching correct attribute names. Overrides attr-naming-
-# style.
-#attr-rgx=
-
-# Bad variable names which should always be refused, separated by a comma.
-bad-names=foo,
- bar,
- baz,
- toto,
- tutu,
- tata
-
-# Bad variable names regexes, separated by a comma. If names match any regex,
-# they will always be refused
-bad-names-rgxs=
-
-# Naming style matching correct class attribute names.
-class-attribute-naming-style=any
-
-# Regular expression matching correct class attribute names. Overrides class-
-# attribute-naming-style.
-#class-attribute-rgx=
-
-# Naming style matching correct class names.
-class-naming-style=PascalCase
-
-# Regular expression matching correct class names. Overrides class-naming-
-# style.
-#class-rgx=
-
-# Naming style matching correct constant names.
-const-naming-style=UPPER_CASE
-
-# Regular expression matching correct constant names. Overrides const-naming-
-# style.
-#const-rgx=
-
-# Minimum line length for functions/classes that require docstrings, shorter
-# ones are exempt.
-docstring-min-length=-1
-
-# Naming style matching correct function names.
-function-naming-style=snake_case
-
-# Regular expression matching correct function names. Overrides function-
-# naming-style.
-#function-rgx=
-
-# Good variable names which should always be accepted, separated by a comma.
-good-names=i,
- j,
- k,
- ex,
- Run,
- _,
- x,
- y,
- w,
- h,
- a,
- b
-
-# Good variable names regexes, separated by a comma. If names match any regex,
-# they will always be accepted
-good-names-rgxs=
-
-# Include a hint for the correct naming format with invalid-name.
-include-naming-hint=no
-
-# Naming style matching correct inline iteration names.
-inlinevar-naming-style=any
-
-# Regular expression matching correct inline iteration names. Overrides
-# inlinevar-naming-style.
-#inlinevar-rgx=
-
-# Naming style matching correct method names.
-method-naming-style=snake_case
-
-# Regular expression matching correct method names. Overrides method-naming-
-# style.
-#method-rgx=
-
-# Naming style matching correct module names.
-module-naming-style=snake_case
-
-# Regular expression matching correct module names. Overrides module-naming-
-# style.
-#module-rgx=
-
-# Colon-delimited sets of names that determine each other's naming style when
-# the name regexes allow several styles.
-name-group=
-
-# Regular expression which should only match function or class names that do
-# not require a docstring.
-no-docstring-rgx=^_
-
-# List of decorators that produce properties, such as abc.abstractproperty. Add
-# to this list to register other decorators that produce valid properties.
-# These decorators are taken in consideration only for invalid-name.
-property-classes=abc.abstractproperty
-
-# Naming style matching correct variable names.
-variable-naming-style=snake_case
-
-# Regular expression matching correct variable names. Overrides variable-
-# naming-style.
-#variable-rgx=
-
-
-[DESIGN]
-
-# Maximum number of arguments for function / method.
-max-args=5
-
-# Maximum number of attributes for a class (see R0902).
-max-attributes=7
-
-# Maximum number of boolean expressions in an if statement (see R0916).
-max-bool-expr=5
-
-# Maximum number of branch for function / method body.
-max-branches=12
-
-# Maximum number of locals for function / method body.
-max-locals=15
-
-# Maximum number of parents for a class (see R0901).
-max-parents=7
-
-# Maximum number of public methods for a class (see R0904).
-max-public-methods=20
-
-# Maximum number of return / yield for function / method body.
-max-returns=6
-
-# Maximum number of statements in function / method body.
-max-statements=50
-
-# Minimum number of public methods for a class (see R0903).
-min-public-methods=2
-
-
-[IMPORTS]
-
-# List of modules that can be imported at any level, not just the top level
-# one.
-allow-any-import-level=
-
-# Allow wildcard imports from modules that define __all__.
-allow-wildcard-with-all=no
-
-# Analyse import fallback blocks. This can be used to support both Python 2 and
-# 3 compatible code, which means that the block might have code that exists
-# only in one or another interpreter, leading to false positives when analysed.
-analyse-fallback-blocks=no
-
-# Deprecated modules which should not be used, separated by a comma.
-deprecated-modules=optparse,tkinter.tix
-
-# Create a graph of external dependencies in the given file (report RP0402 must
-# not be disabled).
-ext-import-graph=
-
-# Create a graph of every (i.e. internal and external) dependencies in the
-# given file (report RP0402 must not be disabled).
-import-graph=
-
-# Create a graph of internal dependencies in the given file (report RP0402 must
-# not be disabled).
-int-import-graph=
-
-# Force import order to recognize a module as part of the standard
-# compatibility libraries.
-known-standard-library=
-
-# Force import order to recognize a module as part of a third party library.
-known-third-party=enchant
-
-# Couples of modules and preferred modules, separated by a comma.
-preferred-modules=
-
-
-[CLASSES]
-
-# List of method names used to declare (i.e. assign) instance attributes.
-defining-attr-methods=__init__,
- __new__,
- setUp,
- __post_init__
-
-# List of member names, which should be excluded from the protected access
-# warning.
-exclude-protected=_asdict,
- _fields,
- _replace,
- _source,
- _make
-
-# List of valid names for the first argument in a class method.
-valid-classmethod-first-arg=cls
-
-# List of valid names for the first argument in a metaclass class method.
-valid-metaclass-classmethod-first-arg=cls
-
-
-[EXCEPTIONS]
-
-# Exceptions that will emit a warning when being caught. Defaults to
-# "BaseException, Exception".
-overgeneral-exceptions=BaseException,
- Exception
diff --git a/.readthedocs.yaml b/.readthedocs.yaml
deleted file mode 100644
index 05ec15cca325e1486907dcf6774b83f4388c6cc7..0000000000000000000000000000000000000000
--- a/.readthedocs.yaml
+++ /dev/null
@@ -1,13 +0,0 @@
-version: 2
-
-formats: all
-
-build:
- os: "ubuntu-22.04"
- tools:
- python: "3.8"
-
-python:
- install:
- - requirements: requirements/docs.txt
- - requirements: requirements/readthedocs.txt
diff --git a/3rdparty/INIReader.h b/3rdparty/INIReader.h
deleted file mode 100644
index 6ed9b5a5aa0bed583811babe8d816178e512feef..0000000000000000000000000000000000000000
--- a/3rdparty/INIReader.h
+++ /dev/null
@@ -1,501 +0,0 @@
-// Read an INI file into easy-to-access name/value pairs.
-
-// inih and INIReader are released under the New BSD license.
-// Go to the project home page for more info:
-//
-// https://github.com/benhoyt/inih (Initial repo)
-// https://github.com/jtilly/inih (The reference of this header file)
-/* inih -- simple .INI file parser
-inih is released under the New BSD license (see LICENSE.txt). Go to the project
-home page for more info:
-https://github.com/benhoyt/inih
-https://github.com/jtilly/inih
-*/
-
-#ifndef __INI_H__
-#define __INI_H__
-
-/* Make this header file easier to include in C++ code */
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-#include
-
-/* Typedef for prototype of handler function. */
-typedef int (*ini_handler)(void* user, const char* section,
- const char* name, const char* value);
-
-/* Typedef for prototype of fgets-style reader function. */
-typedef char* (*ini_reader)(char* str, int num, void* stream);
-
-/* Parse given INI-style file. May have [section]s, name=value pairs
- (whitespace stripped), and comments starting with ';' (semicolon). Section
- is "" if name=value pair parsed before any section heading. name:value
- pairs are also supported as a concession to Python's configparser.
- For each name=value pair parsed, call handler function with given user
- pointer as well as section, name, and value (data only valid for duration
- of handler call). Handler should return nonzero on success, zero on error.
- Returns 0 on success, line number of first error on parse error (doesn't
- stop on first error), -1 on file open error, or -2 on memory allocation
- error (only when INI_USE_STACK is zero).
-*/
-int ini_parse(const char* filename, ini_handler handler, void* user);
-
-/* Same as ini_parse(), but takes a FILE* instead of filename. This doesn't
- close the file when it's finished -- the caller must do that. */
-int ini_parse_file(FILE* file, ini_handler handler, void* user);
-
-/* Same as ini_parse(), but takes an ini_reader function pointer instead of
- filename. Used for implementing custom or string-based I/O. */
-int ini_parse_stream(ini_reader reader, void* stream, ini_handler handler,
- void* user);
-
-/* Nonzero to allow multi-line value parsing, in the style of Python's
- configparser. If allowed, ini_parse() will call the handler with the same
- name for each subsequent line parsed. */
-#ifndef INI_ALLOW_MULTILINE
-#define INI_ALLOW_MULTILINE 1
-#endif
-
-/* Nonzero to allow a UTF-8 BOM sequence (0xEF 0xBB 0xBF) at the start of
- the file. See http://code.google.com/p/inih/issues/detail?id=21 */
-#ifndef INI_ALLOW_BOM
-#define INI_ALLOW_BOM 1
-#endif
-
-/* Nonzero to allow inline comments (with valid inline comment characters
- specified by INI_INLINE_COMMENT_PREFIXES). Set to 0 to turn off and match
- Python 3.2+ configparser behaviour. */
-#ifndef INI_ALLOW_INLINE_COMMENTS
-#define INI_ALLOW_INLINE_COMMENTS 1
-#endif
-#ifndef INI_INLINE_COMMENT_PREFIXES
-#define INI_INLINE_COMMENT_PREFIXES ";"
-#endif
-
-/* Nonzero to use stack, zero to use heap (malloc/free). */
-#ifndef INI_USE_STACK
-#define INI_USE_STACK 1
-#endif
-
-/* Stop parsing on first error (default is to keep parsing). */
-#ifndef INI_STOP_ON_FIRST_ERROR
-#define INI_STOP_ON_FIRST_ERROR 0
-#endif
-
-/* Maximum line length for any line in INI file. */
-#ifndef INI_MAX_LINE
-#define INI_MAX_LINE 200
-#endif
-
-#ifdef __cplusplus
-}
-#endif
-
-/* inih -- simple .INI file parser
-inih is released under the New BSD license (see LICENSE.txt). Go to the project
-home page for more info:
-https://github.com/benhoyt/inih
-*/
-
-#if defined(_MSC_VER) && !defined(_CRT_SECURE_NO_WARNINGS)
-#define _CRT_SECURE_NO_WARNINGS
-#endif
-
-#include
-#include
-#include
-
-#if !INI_USE_STACK
-#include
-#endif
-
-#define MAX_SECTION 50
-#define MAX_NAME 50
-
-/* Strip whitespace chars off end of given string, in place. Return s. */
-inline static char* rstrip(char* s)
-{
- char* p = s + strlen(s);
- while (p > s && isspace((unsigned char)(*--p)))
- *p = '\0';
- return s;
-}
-
-/* Return pointer to first non-whitespace char in given string. */
-inline static char* lskip(const char* s)
-{
- while (*s && isspace((unsigned char)(*s)))
- s++;
- return (char*)s;
-}
-
-/* Return pointer to first char (of chars) or inline comment in given string,
- or pointer to null at end of string if neither found. Inline comment must
- be prefixed by a whitespace character to register as a comment. */
-inline static char* find_chars_or_comment(const char* s, const char* chars)
-{
-#if INI_ALLOW_INLINE_COMMENTS
- int was_space = 0;
- while (*s && (!chars || !strchr(chars, *s)) &&
- !(was_space && strchr(INI_INLINE_COMMENT_PREFIXES, *s))) {
- was_space = isspace((unsigned char)(*s));
- s++;
- }
-#else
- while (*s && (!chars || !strchr(chars, *s))) {
- s++;
- }
-#endif
- return (char*)s;
-}
-
-/* Version of strncpy that ensures dest (size bytes) is null-terminated. */
-inline static char* strncpy0(char* dest, const char* src, size_t size)
-{
- strncpy(dest, src, size);
- dest[size - 1] = '\0';
- return dest;
-}
-
-/* See documentation in header file. */
-inline int ini_parse_stream(ini_reader reader, void* stream, ini_handler handler,
- void* user)
-{
- /* Uses a fair bit of stack (use heap instead if you need to) */
-#if INI_USE_STACK
- char line[INI_MAX_LINE];
-#else
- char* line;
-#endif
- char section[MAX_SECTION] = "";
- char prev_name[MAX_NAME] = "";
-
- char* start;
- char* end;
- char* name;
- char* value;
- int lineno = 0;
- int error = 0;
-
-#if !INI_USE_STACK
- line = (char*)malloc(INI_MAX_LINE);
- if (!line) {
- return -2;
- }
-#endif
-
- /* Scan through stream line by line */
- while (reader(line, INI_MAX_LINE, stream) != NULL) {
- lineno++;
-
- start = line;
-#if INI_ALLOW_BOM
- if (lineno == 1 && (unsigned char)start[0] == 0xEF &&
- (unsigned char)start[1] == 0xBB &&
- (unsigned char)start[2] == 0xBF) {
- start += 3;
- }
-#endif
- start = lskip(rstrip(start));
-
- if (*start == ';' || *start == '#') {
- /* Per Python configparser, allow both ; and # comments at the
- start of a line */
- }
-#if INI_ALLOW_MULTILINE
- else if (*prev_name && *start && start > line) {
-
-#if INI_ALLOW_INLINE_COMMENTS
- end = find_chars_or_comment(start, NULL);
- if (*end)
- *end = '\0';
- rstrip(start);
-#endif
-
- /* Non-blank line with leading whitespace, treat as continuation
- of previous name's value (as per Python configparser). */
- if (!handler(user, section, prev_name, start) && !error)
- error = lineno;
- }
-#endif
- else if (*start == '[') {
- /* A "[section]" line */
- end = find_chars_or_comment(start + 1, "]");
- if (*end == ']') {
- *end = '\0';
- strncpy0(section, start + 1, sizeof(section));
- *prev_name = '\0';
- }
- else if (!error) {
- /* No ']' found on section line */
- error = lineno;
- }
- }
- else if (*start) {
- /* Not a comment, must be a name[=:]value pair */
- end = find_chars_or_comment(start, "=:");
- if (*end == '=' || *end == ':') {
- *end = '\0';
- name = rstrip(start);
- value = lskip(end + 1);
-#if INI_ALLOW_INLINE_COMMENTS
- end = find_chars_or_comment(value, NULL);
- if (*end)
- *end = '\0';
-#endif
- rstrip(value);
-
- /* Valid name[=:]value pair found, call handler */
- strncpy0(prev_name, name, sizeof(prev_name));
- if (!handler(user, section, name, value) && !error)
- error = lineno;
- }
- else if (!error) {
- /* No '=' or ':' found on name[=:]value line */
- error = lineno;
- }
- }
-
-#if INI_STOP_ON_FIRST_ERROR
- if (error)
- break;
-#endif
- }
-
-#if !INI_USE_STACK
- free(line);
-#endif
-
- return error;
-}
-
-/* See documentation in header file. */
-inline int ini_parse_file(FILE* file, ini_handler handler, void* user)
-{
- return ini_parse_stream((ini_reader)fgets, file, handler, user);
-}
-
-/* See documentation in header file. */
-inline int ini_parse(const char* filename, ini_handler handler, void* user)
-{
- FILE* file;
- int error;
-
- file = fopen(filename, "r");
- if (!file)
- return -1;
- error = ini_parse_file(file, handler, user);
- fclose(file);
- return error;
-}
-
-#endif /* __INI_H__ */
-
-
-#ifndef __INIREADER_H__
-#define __INIREADER_H__
-
-#include
-
-#### 7. Resolve conflicts
-
-If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
-
-```shell
-git fetch --all --prune
-git rebase upstream/master
-```
-
-or
-
-```shell
-git fetch --all --prune
-git merge upstream/master
-```
-
-If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
-
-### Guidance
-
-#### Document rendering
-
-If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
-
-```shell
-pip install -r requirements/docs.txt
-cd docs/zh_cn/
-# or docs/en
-make html
-# check file in ./docs/zh_cn/_build/html/index.html
-```
-
-### Code style
-
-#### Python
-
-We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
-
-We use the following tools for linting and formatting:
-
-- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
-- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
-- [yapf](https://github.com/google/yapf): A formatter for Python files.
-- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
-- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
-- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
-
-We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
-fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
-The config for a pre-commit hook is stored in [.pre-commit-config](../.pre-commit-config.yaml).
-
-#### C++ and CUDA
-
-The clang-format config is stored in [.clang-format](../.clang-format).
-
-### PR Specs
-
-1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
-
-2. One short-time branch should be matched with only one PR
-
-3. Accomplish a detailed change in one PR. Avoid large PR
-
- - Bad: Support Faster R-CNN
- - Acceptable: Add a box head to Faster R-CNN
- - Good: Add a parameter to box head to support custom conv-layer number
-
-4. Provide clear and significant commit message
-
-5. Provide clear and meaningful PR description
-
- - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
- - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
- - Introduce main changes, results and influences on other modules in short description
- - Associate related issues and pull requests with a milestone
diff --git a/.github/ISSUE_TEMPLATE/1-bug-report.yml b/.github/ISSUE_TEMPLATE/1-bug-report.yml
deleted file mode 100644
index 86838836de567f984fc4e0829012a3a702ebb535..0000000000000000000000000000000000000000
--- a/.github/ISSUE_TEMPLATE/1-bug-report.yml
+++ /dev/null
@@ -1,40 +0,0 @@
-name: 🐞 Bug report
-description: Create a report to help us reproduce and fix the bug
-title: "[Bug] "
-labels: ['Bug']
-
-body:
-- type: checkboxes
- attributes:
- label: Checklist
- options:
- - label: 1. I have searched related issues but cannot get the expected help.
- - label: 2. The bug has not been fixed in the latest version.
-- type: textarea
- attributes:
- label: Describe the bug
- description: A clear and concise description of what the bug is.
- validations:
- required: true
-- type: textarea
- attributes:
- label: Reproduction
- description: |
- 1. What command or script did you run?
- placeholder: |
- A placeholder for the command.
- validations:
- required: true
-- type: textarea
- attributes:
- label: Error traceback
- description: |
- If applicable, paste the error trackback here.
- placeholder: Logs and traceback here.
- render: Shell
-- type: markdown
- attributes:
- value: >
- If you have already identified the reason, you can provide the information here. If you are willing to create a PR to fix it, please also leave a comment here and that would be much appreciated!
-
- Thanks for your bug report. We appreciate it a lot.
diff --git a/.github/ISSUE_TEMPLATE/2-feature-request.yml b/.github/ISSUE_TEMPLATE/2-feature-request.yml
deleted file mode 100644
index 976997e14c0b401f7ae58ed9959478880962f62c..0000000000000000000000000000000000000000
--- a/.github/ISSUE_TEMPLATE/2-feature-request.yml
+++ /dev/null
@@ -1,31 +0,0 @@
-name: 🚀 Feature request
-description: Suggest an idea for this project
-title: "[Feature] "
-
-body:
-- type: markdown
- attributes:
- value: |
- We strongly appreciate you creating a PR to implement this feature [here](https://github.com/InternLM/lmdeploy/pulls)!
- If you need our help, please fill in as much of the following form as you're able to.
-
- **The less clear the description, the longer it will take to solve it.**
-- type: textarea
- attributes:
- label: Motivation
- description: |
- A clear and concise description of the motivation of the feature.
- Ex1. It is inconvenient when \[....\].
- validations:
- required: true
-- type: textarea
- attributes:
- label: Related resources
- description: |
- If there is an official code release or third-party implementations, please also provide the information here, which would be very helpful.
-- type: textarea
- attributes:
- label: Additional context
- description: |
- Add any other context or screenshots about the feature request here.
- If you would like to implement the feature and create a PR, please leave a comment here and that would be much appreciated.
diff --git a/.github/ISSUE_TEMPLATE/3-documentation.yml b/.github/ISSUE_TEMPLATE/3-documentation.yml
deleted file mode 100644
index b112c2aea6ad2d5fe68fbfec9bfb2ff43da996e7..0000000000000000000000000000000000000000
--- a/.github/ISSUE_TEMPLATE/3-documentation.yml
+++ /dev/null
@@ -1,23 +0,0 @@
-name: 📚 Documentation
-description: Report an issue related to the documentation.
-labels: "kind/doc,status/unconfirmed"
-title: "[Docs] "
-
-body:
-- type: textarea
- attributes:
- label: 📚 The doc issue
- description: >
- A clear and concise description the issue.
- validations:
- required: true
-
-- type: textarea
- attributes:
- label: Suggest a potential alternative/fix
- description: >
- Tell us how we could improve the documentation in this regard.
-- type: markdown
- attributes:
- value: >
- Thanks for contributing 🎉!
diff --git a/.github/md-link-config.json b/.github/md-link-config.json
deleted file mode 100644
index 76986cbd01cf43f1bad7effa03409e0c053c4cca..0000000000000000000000000000000000000000
--- a/.github/md-link-config.json
+++ /dev/null
@@ -1,33 +0,0 @@
-{
- "ignorePatterns": [
-
- {
- "pattern": "^https://developer.nvidia.com/"
- },
- {
- "pattern": "^https://docs.openvino.ai/"
- },
- {
- "pattern": "^https://developer.android.com/"
- },
- {
- "pattern": "^https://developer.qualcomm.com/"
- },
- {
- "pattern": "^http://localhost"
- }
- ],
- "httpHeaders": [
- {
- "urls": ["https://github.com/", "https://guides.github.com/", "https://help.github.com/", "https://docs.github.com/"],
- "headers": {
- "Accept-Encoding": "zstd, br, gzip, deflate"
- }
- }
- ],
- "timeout": "20s",
- "retryOn429": true,
- "retryCount": 5,
- "fallbackRetryDelay": "30s",
- "aliveStatusCodes": [200, 206, 429]
-}
diff --git a/.github/pull_request_template.md b/.github/pull_request_template.md
deleted file mode 100644
index addb1f6dd8412d8f77683594b4a5551536e6c0d6..0000000000000000000000000000000000000000
--- a/.github/pull_request_template.md
+++ /dev/null
@@ -1,25 +0,0 @@
-Thanks for your contribution and we appreciate it a lot. The following instructions would make your pull request more healthy and more easily receiving feedbacks. If you do not understand some items, don't worry, just make the pull request and seek help from maintainers.
-
-## Motivation
-
-Please describe the motivation of this PR and the goal you want to achieve through this PR.
-
-## Modification
-
-Please briefly describe what modification is made in this PR.
-
-## BC-breaking (Optional)
-
-Does the modification introduce changes that break the backward-compatibility of the downstream repositories?
-If so, please describe how it breaks the compatibility and how the downstream projects should modify their code to keep compatibility with this PR.
-
-## Use cases (Optional)
-
-If this PR introduces a new feature, it is better to list some use cases here, and update the documentation.
-
-## Checklist
-
-1. Pre-commit or other linting tools are used to fix the potential lint issues.
-2. The modification is covered by complete unit tests. If not, please add more unit tests to ensure the correctness.
-3. If the modification has a dependency on downstream projects of a newer version, this PR should be tested with all supported versions of downstream projects.
-4. The documentation has been modified accordingly, like docstring or example tutorials.
diff --git a/.github/release.yml b/.github/release.yml
deleted file mode 100644
index 4feb7be54a47c72f7e9671bf0d5378cce5e5fb2d..0000000000000000000000000000000000000000
--- a/.github/release.yml
+++ /dev/null
@@ -1,33 +0,0 @@
-changelog:
- categories:
- - title: 🚀 Features
- labels:
- - feature
- - enhancement
- - title: 💥 Improvements
- labels:
- - improvement
- - title: 🐞 Bug fixes
- labels:
- - bug
- - Bug:P0
- - Bug:P1
- - Bug:P2
- - Bug:P3
- - title: 📚 Documentations
- labels:
- - documentation
- - title: 🌐 Other
- labels:
- - '*'
- exclude:
- labels:
- - feature
- - enhancement
- - improvement
- - bug
- - documentation
- - Bug:P0
- - Bug:P1
- - Bug:P2
- - Bug:P3
diff --git a/.github/scripts/doc_link_checker.py b/.github/scripts/doc_link_checker.py
deleted file mode 100644
index 3933360c88f5e1cbe46d93886c4494c165e98409..0000000000000000000000000000000000000000
--- a/.github/scripts/doc_link_checker.py
+++ /dev/null
@@ -1,86 +0,0 @@
-# Copyright (c) MegFlow. All rights reserved.
-# /bin/python3
-
-import argparse
-import os
-import re
-
-
-def make_parser():
- parser = argparse.ArgumentParser('Doc link checker')
- parser.add_argument('--http',
- default=False,
- type=bool,
- help='check http or not ')
- parser.add_argument('--target',
- default='./docs',
- type=str,
- help='the directory or file to check')
- return parser
-
-
-pattern = re.compile(r'\[.*?\]\(.*?\)')
-
-
-def analyze_doc(home, path):
- print('analyze {}'.format(path))
- problem_list = []
- code_block = 0
- with open(path) as f:
- lines = f.readlines()
- for line in lines:
- line = line.strip()
- if line.startswith('```'):
- code_block = 1 - code_block
-
- if code_block > 0:
- continue
-
- if '[' in line and ']' in line and '(' in line and ')' in line:
- all = pattern.findall(line)
- for item in all:
- # skip ![]()
- if item.find('[') == item.find(']') - 1:
- continue
-
- # process the case [text()]()
- offset = item.find('](')
- if offset == -1:
- continue
- item = item[offset:]
- start = item.find('(')
- end = item.find(')')
- ref = item[start + 1:end]
-
- if ref.startswith('http') or ref.startswith('#'):
- continue
- if '.md#' in ref:
- ref = ref[ref.find('#'):]
- fullpath = os.path.join(home, ref)
- if not os.path.exists(fullpath):
- problem_list.append(ref)
- else:
- continue
- if len(problem_list) > 0:
- print(f'{path}:')
- for item in problem_list:
- print(f'\t {item}')
- print('\n')
- raise Exception('found link error')
-
-
-def traverse(target):
- if os.path.isfile(target):
- analyze_doc(os.path.dirname(target), target)
- return
- for home, dirs, files in os.walk(target):
- for filename in files:
- if filename.endswith('.md'):
- path = os.path.join(home, filename)
- if os.path.islink(path) is False:
- analyze_doc(home, path)
-
-
-if __name__ == '__main__':
- args = make_parser().parse_args()
- traverse(args.target)
diff --git a/.github/workflows/docker.yml b/.github/workflows/docker.yml
deleted file mode 100644
index dc511080783059e5575b2c9d5782c51f1270dbeb..0000000000000000000000000000000000000000
--- a/.github/workflows/docker.yml
+++ /dev/null
@@ -1,62 +0,0 @@
-name: publish-docker
-
-on:
- push:
- paths-ignore:
- - "!.github/workflows/docker.yml"
- - ".github/**"
- - "docs/**"
- - "resources/**"
- - "benchmark/**"
- - "tests/**"
- - "**/*.md"
- branches:
- - main
- tags:
- - "v*.*.*"
-
-jobs:
- publish_docker_image:
- runs-on: ubuntu-latest
- environment: 'prod'
- env:
- TAG_PREFIX: "openmmlab/lmdeploy"
- steps:
- - name: Checkout repository
- uses: actions/checkout@v3
- - name: Free disk space
- uses: jlumbroso/free-disk-space@main
- with:
- # This might remove tools that are actually needed, if set to "true" but frees about 6 GB
- tool-cache: false
- docker-images: false
- # All of these default to true, but feel free to set to "false" if necessary for your workflow
- android: true
- dotnet: true
- haskell: true
- large-packages: true
- swap-storage: false
- - name: Get docker info
- run: |
- docker info
- - name: Login to Docker Hub
- uses: docker/login-action@v2
- with:
- username: ${{ secrets.DOCKERHUB_USERNAME }}
- password: ${{ secrets.DOCKERHUB_TOKEN }}
- - name: Build and push the latest Docker image
- run: |
- export TAG=$TAG_PREFIX:latest
- echo $TAG
- docker build docker/ -t ${TAG} --no-cache
- docker push $TAG
- echo "TAG=${TAG}" >> $GITHUB_ENV
- - name: Push docker image with released tag
- if: startsWith(github.ref, 'refs/tags/') == true
- run: |
- export LMDEPLOY_VERSION=$(python3 -c "import sys; sys.path.append('lmdeploy');from version import __version__;print(__version__)")
- echo $LMDEPLOY_VERSION
- export RELEASE_TAG=${TAG_PREFIX}:v${LMDEPLOY_VERSION}
- echo $RELEASE_TAG
- docker tag $TAG $RELEASE_TAG
- docker push $RELEASE_TAG
diff --git a/.github/workflows/lint.yml b/.github/workflows/lint.yml
deleted file mode 100644
index a6f2e6374a41ba21cf2eb7cb5c7554b22ceaae86..0000000000000000000000000000000000000000
--- a/.github/workflows/lint.yml
+++ /dev/null
@@ -1,46 +0,0 @@
-name: lint
-
-on: [push, pull_request]
-
-jobs:
- lint:
- runs-on: ubuntu-20.04
- steps:
- - uses: actions/checkout@v2
- - name: Set up Python 3.8
- uses: actions/setup-python@v2
- with:
- python-version: 3.8
- - name: Install pre-commit hook
- run: |
- python -m pip install pre-commit
- pre-commit install
- - name: Linting
- run: pre-commit run --all-files
- - name: Format c/cuda codes with clang-format
- uses: DoozyX/clang-format-lint-action@v0.13
- with:
- source: src
- extensions: h,c,cpp,hpp,cu,cuh
- clangFormatVersion: 11
- style: file
- - name: Check markdown link
- uses: gaurav-nelson/github-action-markdown-link-check@v1
- with:
- use-quiet-mode: 'yes'
- use-verbose-mode: 'yes'
-# check-modified-files-only: 'yes'
- config-file: '.github/md-link-config.json'
- file-path: './README.md, ./LICENSE, ./README_zh-CN.md'
- - name: Check doc link
- run: |
- python .github/scripts/doc_link_checker.py --target README_zh-CN.md
- python .github/scripts/doc_link_checker.py --target README.md
- - name: Check docstring coverage
- run: |
- python -m pip install interrogate
- interrogate -v --ignore-init-method --ignore-magic --ignore-module --ignore-private --ignore-nested-functions --ignore-nested-classes --fail-under 80 lmdeploy
- - name: Check pylint score
- run: |
- python -m pip install pylint
- pylint lmdeploy
diff --git a/.github/workflows/linux-x64-gpu.yml b/.github/workflows/linux-x64-gpu.yml
deleted file mode 100644
index d940408ce7536cbdbf082528d00da79c01f81571..0000000000000000000000000000000000000000
--- a/.github/workflows/linux-x64-gpu.yml
+++ /dev/null
@@ -1,56 +0,0 @@
-name: linux-x64-gpu
-on:
- push:
- paths:
- - '.github/workflows/linux-x64-gpu.yml'
- - 'src/**'
- - 'CMakeLists.txt'
- - 'cmake/**'
- - 'examples/**'
- - '3rdparty/**'
- - 'tests/csrc/**'
- pull_request:
- paths:
- - '.github/workflows/linux-x64-gpu.yml'
- - 'src/**'
- - 'CMakeLists.txt'
- - 'cmake/**'
- - 'examples/**'
- - '3rdparty/**'
- - 'tests/csrc/**'
-concurrency:
- group: linux-x64-gpu-${{ github.ref }}
- cancel-in-progress: true
-permissions:
- contents: read
-
-jobs:
- cuda-118:
- runs-on: ubuntu-latest
- steps:
- - name: Free disk space
- uses: jlumbroso/free-disk-space@main
- with:
- # This might remove tools that are actually needed, if set to "true" but frees about 6 GB
- tool-cache: false
- docker-images: false
- # All of these default to true, but feel free to set to "false" if necessary for your workflow
- android: true
- dotnet: true
- haskell: true
- large-packages: true
- swap-storage: false
- - name: Checkout repository
- uses: actions/checkout@v3
- - name: Build
- uses: addnab/docker-run-action@v3
- with:
- image: openmmlab/lmdeploy-builder:cuda11.8
- options: -v ${{ github.workspace }}:/work --cpus=1.8
- run: |
- cd /work
- source /opt/conda/bin/activate
- conda activate py38
- mkdir build && cd build
- bash ../generate.sh
- make -j$(nproc) && make install
diff --git a/.github/workflows/pypi.yml b/.github/workflows/pypi.yml
deleted file mode 100644
index 7c56e08f7d4ac0009bd96ac73fa73dd1a3437aa6..0000000000000000000000000000000000000000
--- a/.github/workflows/pypi.yml
+++ /dev/null
@@ -1,109 +0,0 @@
-name: publish to pypi
-
-on:
- push:
- branches:
- - main
- paths:
- - "lmdeploy/version.py"
- workflow_dispatch:
-
-
-jobs:
- linux-build:
- strategy:
- matrix:
- pyver: [py38, py39, py310, py311]
- runs-on: ubuntu-latest
- env:
- PYTHON_VERSION: ${{ matrix.pyver }}
- PLAT_NAME: manylinux2014_x86_64
- DOCKER_TAG: cuda11.8
- OUTPUT_FOLDER: cuda11.8_dist
- steps:
- - name: Free disk space
- uses: jlumbroso/free-disk-space@main
- with:
- # This might remove tools that are actually needed, if set to "true" but frees about 6 GB
- tool-cache: false
- docker-images: false
- # All of these default to true, but feel free to set to "false" if necessary for your workflow
- android: true
- dotnet: true
- haskell: true
- large-packages: true
- swap-storage: false
- - name: Checkout repository
- uses: actions/checkout@v3
- - name: Build
- run: |
- echo ${PYTHON_VERSION}
- echo ${PLAT_NAME}
- echo ${DOCKER_TAG}
- echo ${OUTPUT_FOLDER}
- # remove -it
- sed -i 's/docker run --rm -it/docker run --rm/g' builder/manywheel/build_wheel.sh
- bash builder/manywheel/build_wheel.sh ${PYTHON_VERSION} ${PLAT_NAME} ${DOCKER_TAG} ${OUTPUT_FOLDER}
- - name: Upload Artifacts
- uses: actions/upload-artifact@v3
- with:
- if-no-files-found: error
- path: builder/manywheel/${{ env.OUTPUT_FOLDER }}/*
- retention-days: 1
-
- windows-build:
- strategy:
- matrix:
- pyver: ['3.8', '3.9', '3.10', '3.11']
- runs-on: windows-latest
- steps:
- - name: Checkout repository
- uses: actions/checkout@v3
- - name: Set up python
- uses: actions/setup-python@v4
- with:
- python-version: ${{ matrix.pyver }}
- - name: Install python packages
- run: |
- pip install pybind11 wheel
- - uses: Jimver/cuda-toolkit@v0.2.11
- id: cuda-toolkit
- with:
- cuda: '11.8.0'
- use-github-cache: false
- - name: Build wheel
- run: |
- mkdir build
- cd build
- ..\builder\windows\generate.ps1
- cmake --build . --config Release -- /m > build.log.txt
- cmake --install . --config Release
- cd ..
- rm build -Force -Recurse
- python setup.py bdist_wheel -d build/wheel
- - name: Upload Artifacts
- uses: actions/upload-artifact@v3
- with:
- if-no-files-found: error
- path: build/wheel/*
- retention-days: 1
-
- publish:
- runs-on: ubuntu-latest
- environment: 'prod'
- needs:
- - linux-build
- - windows-build
- steps:
- - name: Download artifacts
- uses: actions/download-artifact@v3
- - name: Display artifacts
- run: ls artifact/ -lh
- - name: Set up python3.8
- uses: actions/setup-python@v4
- with:
- python-version: '3.8'
- - name: Upload to pypi
- run: |
- pip install twine
- twine upload artifact/* -u __token__ -p ${{ secrets.pypi_password }}
diff --git a/.github/workflows/stale.yml b/.github/workflows/stale.yml
deleted file mode 100644
index 93df0cd47c7ddef6870ae3e4d0e0acfd55f792a6..0000000000000000000000000000000000000000
--- a/.github/workflows/stale.yml
+++ /dev/null
@@ -1,32 +0,0 @@
-name: 'Close stale issues and PRs'
-
-on:
- schedule:
- # check issue and pull request once at 01:30 a.m. every day
- - cron: '30 1 * * *'
-
-permissions:
- contents: read
-
-jobs:
- stale:
- permissions:
- issues: write
- pull-requests: write
- runs-on: ubuntu-latest
- steps:
- - uses: actions/stale@v7
- with:
- stale-issue-message: 'This issue is marked as stale because it has been marked as invalid or awaiting response for 7 days without any further response. It will be closed in 5 days if the stale label is not removed or if there is no further response.'
- stale-pr-message: 'This PR is marked as stale because there has been no activity in the past 45 days. It will be closed in 10 days if the stale label is not removed or if there is no further updates.'
- close-issue-message: 'This issue is closed because it has been stale for 5 days. Please open a new issue if you have similar issues or you have any new updates now.'
- close-pr-message: 'This PR is closed because it has been stale for 10 days. Please reopen this PR if you have any updates and want to keep contributing the code.'
- # only issues/PRS with following labels are checked
- any-of-labels: 'invalid, awaiting response, duplicate'
- days-before-issue-stale: 7
- days-before-pr-stale: 45
- days-before-issue-close: 5
- days-before-pr-close: 10
- # automatically remove the stale label when the issues or the pull requests are updated or commented
- remove-stale-when-updated: true
- operations-per-run: 50
diff --git a/.github/workflows/windows-x64-gpu.yml b/.github/workflows/windows-x64-gpu.yml
deleted file mode 100644
index 93839cfb89b07d47e80fb6d30305028caf92e93a..0000000000000000000000000000000000000000
--- a/.github/workflows/windows-x64-gpu.yml
+++ /dev/null
@@ -1,60 +0,0 @@
-name: windows-x64-gpu
-on:
- push:
- paths:
- - '.github/workflows/windows-x64-gpu.yml'
- - 'src/**'
- - 'CMakeLists.txt'
- - 'cmake/**'
- - 'examples/**'
- - '3rdparty/**'
- - 'tests/csrc/**'
- pull_request:
- paths:
- - '.github/workflows/windows-x64-gpu.yml'
- - 'src/**'
- - 'CMakeLists.txt'
- - 'cmake/**'
- - 'examples/**'
- - '3rdparty/**'
- - 'tests/csrc/**'
-concurrency:
- group: windows-x64-gpu-${{ github.ref }}
- cancel-in-progress: true
-permissions:
- contents: read
-
-jobs:
- cuda-118:
- runs-on: windows-latest
- steps:
- - name: Checkout repository
- uses: actions/checkout@v3
- - name: Set up python
- uses: actions/setup-python@v4
- with:
- python-version: '3.8'
- - name: Install python packages
- run: |
- pip install pybind11 wheel
- - uses: Jimver/cuda-toolkit@v0.2.11
- id: cuda-toolkit
- with:
- cuda: '11.8.0'
- use-github-cache: false
- - name: Build wheel
- run: |
- ((Get-Content -path CMakeLists.txt -Raw) -replace '-Wall','/W0') | Set-Content CMakeLists.txt
- $env:BUILD_TEST="ON"
- mkdir build
- cd build
- ..\builder\windows\generate.ps1
- cmake --build . --config Release -- /m /v:q
- if (-Not $?) {
- echo "build failed"
- exit 1
- }
- cmake --install . --config Release
- cd ..
- rm build -Force -Recurse
- python setup.py bdist_wheel -d build/wheel
diff --git a/.gitignore b/.gitignore
deleted file mode 100644
index ccfad036dcd04f55b0eac63fb40377e15509f409..0000000000000000000000000000000000000000
--- a/.gitignore
+++ /dev/null
@@ -1,74 +0,0 @@
-# Byte-compiled / optimized / DLL files
-__pycache__/
-*.py[cod]
-*$py.class
-.vscode/
-.idea/
-# C extensions
-*.so
-
-# Distribution / packaging
-.Python
-develop-eggs/
-dist/
-downloads/
-eggs/
-.eggs/
-lib/
-lib64/
-parts/
-sdist/
-var/
-wheels/
-*.egg-info/
-.installed.cfg
-*.egg
-MANIFEST
-
-# PyInstaller
-# Usually these files are written by a python script from a template
-# before PyInstaller builds the exe, so as to inject date/other infos into it.
-*.manifest
-*.spec
-
-# Installer logs
-pip-log.txt
-pip-delete-this-directory.txt
-
-# Unit test / coverage reports
-htmlcov/
-.tox/
-.coverage
-.coverage.*
-.cache
-*build*/
-!builder/
-lmdeploy/lib/
-lmdeploy/bin/
-dist/
-examples/cpp/llama/*.csv
-*.npy
-*.weight
-
-# LMDeploy
-workspace/
-work_dir*/
-
-# Huggingface
-*.bin
-*config.json
-*generate_config.json
-
-# Pytorch
-*.pth
-*.py~
-*.sh~
-*.pyc
-**/src/pytorch-sphinx-theme/
-
-# Outputs and logs
-*.txt
-*.log
-*.out
-*.csv
-*.pkl
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
deleted file mode 100644
index fb5f4d1b36481da818614029b8fa51c696dfe9d8..0000000000000000000000000000000000000000
--- a/.pre-commit-config.yaml
+++ /dev/null
@@ -1,53 +0,0 @@
-repos:
- - repo: https://github.com/PyCQA/flake8
- rev: 4.0.1
- hooks:
- - id: flake8
- args: ["--exclude=lmdeploy/turbomind/triton_models/*"]
- - repo: https://github.com/PyCQA/isort
- rev: 5.11.5
- hooks:
- - id: isort
- - repo: https://github.com/pre-commit/mirrors-yapf
- rev: v0.32.0
- hooks:
- - id: yapf
- - repo: https://github.com/pre-commit/pre-commit-hooks
- rev: v4.2.0
- hooks:
- - id: trailing-whitespace
- - id: check-yaml
- - id: end-of-file-fixer
- - id: requirements-txt-fixer
- - id: double-quote-string-fixer
- - id: check-merge-conflict
- - id: fix-encoding-pragma
- args: ["--remove"]
- - id: mixed-line-ending
- args: ["--fix=lf"]
- - repo: https://github.com/executablebooks/mdformat
- rev: 0.7.9
- hooks:
- - id: mdformat
- args: ["--number"]
- additional_dependencies:
- - mdformat-openmmlab
- - mdformat_frontmatter
- - linkify-it-py
- - repo: https://github.com/codespell-project/codespell
- rev: v2.1.0
- hooks:
- - id: codespell
- args: ["--skip=third_party/*,*.ipynb,*.proto"]
-
- - repo: https://github.com/myint/docformatter
- rev: v1.4
- hooks:
- - id: docformatter
- args: ["--in-place", "--wrap-descriptions", "79"]
-
- - repo: https://github.com/open-mmlab/pre-commit-hooks
- rev: v0.2.0
- hooks:
- - id: check-copyright
- args: ["lmdeploy"]
diff --git a/.pylintrc b/.pylintrc
deleted file mode 100644
index d46a1c7f31f05969869ec52d7508f70130d40e32..0000000000000000000000000000000000000000
--- a/.pylintrc
+++ /dev/null
@@ -1,625 +0,0 @@
-[MASTER]
-
-# A comma-separated list of package or module names from where C extensions may
-# be loaded. Extensions are loading into the active Python interpreter and may
-# run arbitrary code.
-extension-pkg-whitelist=
-
-# Specify a score threshold to be exceeded before program exits with error.
-fail-under=8.5
-
-# Add files or directories to the blacklist. They should be base names, not
-# paths.
-ignore=CVS,configs
-
-# Add files or directories matching the regex patterns to the blacklist. The
-# regex matches against base names, not paths.
-ignore-patterns=
-
-# Python code to execute, usually for sys.path manipulation such as
-# pygtk.require().
-#init-hook=
-
-# Use multiple processes to speed up Pylint. Specifying 0 will auto-detect the
-# number of processors available to use.
-jobs=1
-
-# Control the amount of potential inferred values when inferring a single
-# object. This can help the performance when dealing with large functions or
-# complex, nested conditions.
-limit-inference-results=100
-
-# List of plugins (as comma separated values of python module names) to load,
-# usually to register additional checkers.
-load-plugins=
-
-# Pickle collected data for later comparisons.
-persistent=yes
-
-# When enabled, pylint would attempt to guess common misconfiguration and emit
-# user-friendly hints instead of false-positive error messages.
-suggestion-mode=yes
-
-# Allow loading of arbitrary C extensions. Extensions are imported into the
-# active Python interpreter and may run arbitrary code.
-unsafe-load-any-extension=no
-
-
-[MESSAGES CONTROL]
-
-# Only show warnings with the listed confidence levels. Leave empty to show
-# all. Valid levels: HIGH, INFERENCE, INFERENCE_FAILURE, UNDEFINED.
-confidence=
-
-# Disable the message, report, category or checker with the given id(s). You
-# can either give multiple identifiers separated by comma (,) or put this
-# option multiple times (only on the command line, not in the configuration
-# file where it should appear only once). You can also use "--disable=all" to
-# disable everything first and then reenable specific checks. For example, if
-# you want to run only the similarities checker, you can use "--disable=all
-# --enable=similarities". If you want to run only the classes checker, but have
-# no Warning level messages displayed, use "--disable=all --enable=classes
-# --disable=W".
-disable=print-statement,
- parameter-unpacking,
- unpacking-in-except,
- old-raise-syntax,
- backtick,
- long-suffix,
- old-ne-operator,
- old-octal-literal,
- import-star-module-level,
- non-ascii-bytes-literal,
- raw-checker-failed,
- bad-inline-option,
- locally-disabled,
- file-ignored,
- suppressed-message,
- useless-suppression,
- deprecated-pragma,
- use-symbolic-message-instead,
- apply-builtin,
- basestring-builtin,
- buffer-builtin,
- cmp-builtin,
- coerce-builtin,
- execfile-builtin,
- file-builtin,
- long-builtin,
- raw_input-builtin,
- reduce-builtin,
- standarderror-builtin,
- unicode-builtin,
- xrange-builtin,
- coerce-method,
- delslice-method,
- getslice-method,
- setslice-method,
- no-absolute-import,
- old-division,
- dict-iter-method,
- dict-view-method,
- next-method-called,
- metaclass-assignment,
- indexing-exception,
- raising-string,
- reload-builtin,
- oct-method,
- hex-method,
- nonzero-method,
- cmp-method,
- input-builtin,
- round-builtin,
- intern-builtin,
- unichr-builtin,
- map-builtin-not-iterating,
- zip-builtin-not-iterating,
- range-builtin-not-iterating,
- filter-builtin-not-iterating,
- using-cmp-argument,
- eq-without-hash,
- div-method,
- idiv-method,
- rdiv-method,
- exception-message-attribute,
- invalid-str-codec,
- sys-max-int,
- bad-python3-import,
- deprecated-string-function,
- deprecated-str-translate-call,
- deprecated-itertools-function,
- deprecated-types-field,
- next-method-defined,
- dict-items-not-iterating,
- dict-keys-not-iterating,
- dict-values-not-iterating,
- deprecated-operator-function,
- deprecated-urllib-function,
- xreadlines-attribute,
- deprecated-sys-function,
- exception-escape,
- comprehension-escape,
- no-member,
- invalid-name,
- too-many-branches,
- wrong-import-order,
- too-many-arguments,
- missing-function-docstring,
- missing-module-docstring,
- too-many-locals,
- too-few-public-methods,
- abstract-method,
- broad-except,
- too-many-nested-blocks,
- too-many-instance-attributes,
- missing-class-docstring,
- duplicate-code,
- not-callable,
- protected-access,
- dangerous-default-value,
- no-name-in-module,
- logging-fstring-interpolation,
- super-init-not-called,
- redefined-builtin,
- attribute-defined-outside-init,
- arguments-differ,
- cyclic-import,
- bad-super-call,
- too-many-statements,
- unused-argument,
- import-outside-toplevel,
- import-error,
- super-with-arguments
-
-# Enable the message, report, category or checker with the given id(s). You can
-# either give multiple identifier separated by comma (,) or put this option
-# multiple time (only on the command line, not in the configuration file where
-# it should appear only once). See also the "--disable" option for examples.
-enable=c-extension-no-member
-
-
-[REPORTS]
-
-# Python expression which should return a score less than or equal to 10. You
-# have access to the variables 'error', 'warning', 'refactor', and 'convention'
-# which contain the number of messages in each category, as well as 'statement'
-# which is the total number of statements analyzed. This score is used by the
-# global evaluation report (RP0004).
-evaluation=10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10)
-
-# Template used to display messages. This is a python new-style format string
-# used to format the message information. See doc for all details.
-#msg-template=
-
-# Set the output format. Available formats are text, parseable, colorized, json
-# and msvs (visual studio). You can also give a reporter class, e.g.
-# mypackage.mymodule.MyReporterClass.
-output-format=text
-
-# Tells whether to display a full report or only the messages.
-reports=yes
-
-# Activate the evaluation score.
-score=yes
-
-
-[REFACTORING]
-
-# Maximum number of nested blocks for function / method body
-max-nested-blocks=5
-
-# Complete name of functions that never returns. When checking for
-# inconsistent-return-statements if a never returning function is called then
-# it will be considered as an explicit return statement and no message will be
-# printed.
-never-returning-functions=sys.exit
-
-
-[TYPECHECK]
-
-# List of decorators that produce context managers, such as
-# contextlib.contextmanager. Add to this list to register other decorators that
-# produce valid context managers.
-contextmanager-decorators=contextlib.contextmanager
-
-# List of members which are set dynamically and missed by pylint inference
-# system, and so shouldn't trigger E1101 when accessed. Python regular
-# expressions are accepted.
-generated-members=
-
-# Tells whether missing members accessed in mixin class should be ignored. A
-# mixin class is detected if its name ends with "mixin" (case insensitive).
-ignore-mixin-members=yes
-
-# Tells whether to warn about missing members when the owner of the attribute
-# is inferred to be None.
-ignore-none=yes
-
-# This flag controls whether pylint should warn about no-member and similar
-# checks whenever an opaque object is returned when inferring. The inference
-# can return multiple potential results while evaluating a Python object, but
-# some branches might not be evaluated, which results in partial inference. In
-# that case, it might be useful to still emit no-member and other checks for
-# the rest of the inferred objects.
-ignore-on-opaque-inference=yes
-
-# List of class names for which member attributes should not be checked (useful
-# for classes with dynamically set attributes). This supports the use of
-# qualified names.
-ignored-classes=optparse.Values,thread._local,_thread._local
-
-# List of module names for which member attributes should not be checked
-# (useful for modules/projects where namespaces are manipulated during runtime
-# and thus existing member attributes cannot be deduced by static analysis). It
-# supports qualified module names, as well as Unix pattern matching.
-ignored-modules=
-
-# Show a hint with possible names when a member name was not found. The aspect
-# of finding the hint is based on edit distance.
-missing-member-hint=yes
-
-# The minimum edit distance a name should have in order to be considered a
-# similar match for a missing member name.
-missing-member-hint-distance=1
-
-# The total number of similar names that should be taken in consideration when
-# showing a hint for a missing member.
-missing-member-max-choices=1
-
-# List of decorators that change the signature of a decorated function.
-signature-mutators=
-
-
-[SPELLING]
-
-# Limits count of emitted suggestions for spelling mistakes.
-max-spelling-suggestions=4
-
-# Spelling dictionary name. Available dictionaries: none. To make it work,
-# install the python-enchant package.
-spelling-dict=
-
-# List of comma separated words that should not be checked.
-spelling-ignore-words=
-
-# A path to a file that contains the private dictionary; one word per line.
-spelling-private-dict-file=
-
-# Tells whether to store unknown words to the private dictionary (see the
-# --spelling-private-dict-file option) instead of raising a message.
-spelling-store-unknown-words=no
-
-
-[LOGGING]
-
-# The type of string formatting that logging methods do. `old` means using %
-# formatting, `new` is for `{}` formatting.
-logging-format-style=old
-
-# Logging modules to check that the string format arguments are in logging
-# function parameter format.
-logging-modules=logging
-
-
-[VARIABLES]
-
-# List of additional names supposed to be defined in builtins. Remember that
-# you should avoid defining new builtins when possible.
-additional-builtins=
-
-# Tells whether unused global variables should be treated as a violation.
-allow-global-unused-variables=yes
-
-# List of strings which can identify a callback function by name. A callback
-# name must start or end with one of those strings.
-callbacks=cb_,
- _cb
-
-# A regular expression matching the name of dummy variables (i.e. expected to
-# not be used).
-dummy-variables-rgx=_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|dummy|^ignored_|^unused_
-
-# Argument names that match this expression will be ignored. Default to name
-# with leading underscore.
-ignored-argument-names=_.*|^ignored_|^unused_
-
-# Tells whether we should check for unused import in __init__ files.
-init-import=no
-
-# List of qualified module names which can have objects that can redefine
-# builtins.
-redefining-builtins-modules=six.moves,past.builtins,future.builtins,builtins,io
-
-
-[FORMAT]
-
-# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
-expected-line-ending-format=
-
-# Regexp for a line that is allowed to be longer than the limit.
-ignore-long-lines=^\s*(# )??$
-
-# Number of spaces of indent required inside a hanging or continued line.
-indent-after-paren=4
-
-# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1
-# tab).
-indent-string=' '
-
-# Maximum number of characters on a single line.
-max-line-length=100
-
-# Maximum number of lines in a module.
-max-module-lines=1000
-
-# Allow the body of a class to be on the same line as the declaration if body
-# contains single statement.
-single-line-class-stmt=no
-
-# Allow the body of an if to be on the same line as the test if there is no
-# else.
-single-line-if-stmt=no
-
-
-[STRING]
-
-# This flag controls whether inconsistent-quotes generates a warning when the
-# character used as a quote delimiter is used inconsistently within a module.
-check-quote-consistency=no
-
-# This flag controls whether the implicit-str-concat should generate a warning
-# on implicit string concatenation in sequences defined over several lines.
-check-str-concat-over-line-jumps=no
-
-
-[SIMILARITIES]
-
-# Ignore comments when computing similarities.
-ignore-comments=yes
-
-# Ignore docstrings when computing similarities.
-ignore-docstrings=yes
-
-# Ignore imports when computing similarities.
-ignore-imports=no
-
-# Minimum lines number of a similarity.
-min-similarity-lines=4
-
-
-[MISCELLANEOUS]
-
-# List of note tags to take in consideration, separated by a comma.
-notes=FIXME,
- XXX,
- TODO
-
-# Regular expression of note tags to take in consideration.
-#notes-rgx=
-
-
-[BASIC]
-
-# Naming style matching correct argument names.
-argument-naming-style=snake_case
-
-# Regular expression matching correct argument names. Overrides argument-
-# naming-style.
-#argument-rgx=
-
-# Naming style matching correct attribute names.
-attr-naming-style=snake_case
-
-# Regular expression matching correct attribute names. Overrides attr-naming-
-# style.
-#attr-rgx=
-
-# Bad variable names which should always be refused, separated by a comma.
-bad-names=foo,
- bar,
- baz,
- toto,
- tutu,
- tata
-
-# Bad variable names regexes, separated by a comma. If names match any regex,
-# they will always be refused
-bad-names-rgxs=
-
-# Naming style matching correct class attribute names.
-class-attribute-naming-style=any
-
-# Regular expression matching correct class attribute names. Overrides class-
-# attribute-naming-style.
-#class-attribute-rgx=
-
-# Naming style matching correct class names.
-class-naming-style=PascalCase
-
-# Regular expression matching correct class names. Overrides class-naming-
-# style.
-#class-rgx=
-
-# Naming style matching correct constant names.
-const-naming-style=UPPER_CASE
-
-# Regular expression matching correct constant names. Overrides const-naming-
-# style.
-#const-rgx=
-
-# Minimum line length for functions/classes that require docstrings, shorter
-# ones are exempt.
-docstring-min-length=-1
-
-# Naming style matching correct function names.
-function-naming-style=snake_case
-
-# Regular expression matching correct function names. Overrides function-
-# naming-style.
-#function-rgx=
-
-# Good variable names which should always be accepted, separated by a comma.
-good-names=i,
- j,
- k,
- ex,
- Run,
- _,
- x,
- y,
- w,
- h,
- a,
- b
-
-# Good variable names regexes, separated by a comma. If names match any regex,
-# they will always be accepted
-good-names-rgxs=
-
-# Include a hint for the correct naming format with invalid-name.
-include-naming-hint=no
-
-# Naming style matching correct inline iteration names.
-inlinevar-naming-style=any
-
-# Regular expression matching correct inline iteration names. Overrides
-# inlinevar-naming-style.
-#inlinevar-rgx=
-
-# Naming style matching correct method names.
-method-naming-style=snake_case
-
-# Regular expression matching correct method names. Overrides method-naming-
-# style.
-#method-rgx=
-
-# Naming style matching correct module names.
-module-naming-style=snake_case
-
-# Regular expression matching correct module names. Overrides module-naming-
-# style.
-#module-rgx=
-
-# Colon-delimited sets of names that determine each other's naming style when
-# the name regexes allow several styles.
-name-group=
-
-# Regular expression which should only match function or class names that do
-# not require a docstring.
-no-docstring-rgx=^_
-
-# List of decorators that produce properties, such as abc.abstractproperty. Add
-# to this list to register other decorators that produce valid properties.
-# These decorators are taken in consideration only for invalid-name.
-property-classes=abc.abstractproperty
-
-# Naming style matching correct variable names.
-variable-naming-style=snake_case
-
-# Regular expression matching correct variable names. Overrides variable-
-# naming-style.
-#variable-rgx=
-
-
-[DESIGN]
-
-# Maximum number of arguments for function / method.
-max-args=5
-
-# Maximum number of attributes for a class (see R0902).
-max-attributes=7
-
-# Maximum number of boolean expressions in an if statement (see R0916).
-max-bool-expr=5
-
-# Maximum number of branch for function / method body.
-max-branches=12
-
-# Maximum number of locals for function / method body.
-max-locals=15
-
-# Maximum number of parents for a class (see R0901).
-max-parents=7
-
-# Maximum number of public methods for a class (see R0904).
-max-public-methods=20
-
-# Maximum number of return / yield for function / method body.
-max-returns=6
-
-# Maximum number of statements in function / method body.
-max-statements=50
-
-# Minimum number of public methods for a class (see R0903).
-min-public-methods=2
-
-
-[IMPORTS]
-
-# List of modules that can be imported at any level, not just the top level
-# one.
-allow-any-import-level=
-
-# Allow wildcard imports from modules that define __all__.
-allow-wildcard-with-all=no
-
-# Analyse import fallback blocks. This can be used to support both Python 2 and
-# 3 compatible code, which means that the block might have code that exists
-# only in one or another interpreter, leading to false positives when analysed.
-analyse-fallback-blocks=no
-
-# Deprecated modules which should not be used, separated by a comma.
-deprecated-modules=optparse,tkinter.tix
-
-# Create a graph of external dependencies in the given file (report RP0402 must
-# not be disabled).
-ext-import-graph=
-
-# Create a graph of every (i.e. internal and external) dependencies in the
-# given file (report RP0402 must not be disabled).
-import-graph=
-
-# Create a graph of internal dependencies in the given file (report RP0402 must
-# not be disabled).
-int-import-graph=
-
-# Force import order to recognize a module as part of the standard
-# compatibility libraries.
-known-standard-library=
-
-# Force import order to recognize a module as part of a third party library.
-known-third-party=enchant
-
-# Couples of modules and preferred modules, separated by a comma.
-preferred-modules=
-
-
-[CLASSES]
-
-# List of method names used to declare (i.e. assign) instance attributes.
-defining-attr-methods=__init__,
- __new__,
- setUp,
- __post_init__
-
-# List of member names, which should be excluded from the protected access
-# warning.
-exclude-protected=_asdict,
- _fields,
- _replace,
- _source,
- _make
-
-# List of valid names for the first argument in a class method.
-valid-classmethod-first-arg=cls
-
-# List of valid names for the first argument in a metaclass class method.
-valid-metaclass-classmethod-first-arg=cls
-
-
-[EXCEPTIONS]
-
-# Exceptions that will emit a warning when being caught. Defaults to
-# "BaseException, Exception".
-overgeneral-exceptions=BaseException,
- Exception
diff --git a/.readthedocs.yaml b/.readthedocs.yaml
deleted file mode 100644
index 05ec15cca325e1486907dcf6774b83f4388c6cc7..0000000000000000000000000000000000000000
--- a/.readthedocs.yaml
+++ /dev/null
@@ -1,13 +0,0 @@
-version: 2
-
-formats: all
-
-build:
- os: "ubuntu-22.04"
- tools:
- python: "3.8"
-
-python:
- install:
- - requirements: requirements/docs.txt
- - requirements: requirements/readthedocs.txt
diff --git a/3rdparty/INIReader.h b/3rdparty/INIReader.h
deleted file mode 100644
index 6ed9b5a5aa0bed583811babe8d816178e512feef..0000000000000000000000000000000000000000
--- a/3rdparty/INIReader.h
+++ /dev/null
@@ -1,501 +0,0 @@
-// Read an INI file into easy-to-access name/value pairs.
-
-// inih and INIReader are released under the New BSD license.
-// Go to the project home page for more info:
-//
-// https://github.com/benhoyt/inih (Initial repo)
-// https://github.com/jtilly/inih (The reference of this header file)
-/* inih -- simple .INI file parser
-inih is released under the New BSD license (see LICENSE.txt). Go to the project
-home page for more info:
-https://github.com/benhoyt/inih
-https://github.com/jtilly/inih
-*/
-
-#ifndef __INI_H__
-#define __INI_H__
-
-/* Make this header file easier to include in C++ code */
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-#include
-
-/* Typedef for prototype of handler function. */
-typedef int (*ini_handler)(void* user, const char* section,
- const char* name, const char* value);
-
-/* Typedef for prototype of fgets-style reader function. */
-typedef char* (*ini_reader)(char* str, int num, void* stream);
-
-/* Parse given INI-style file. May have [section]s, name=value pairs
- (whitespace stripped), and comments starting with ';' (semicolon). Section
- is "" if name=value pair parsed before any section heading. name:value
- pairs are also supported as a concession to Python's configparser.
- For each name=value pair parsed, call handler function with given user
- pointer as well as section, name, and value (data only valid for duration
- of handler call). Handler should return nonzero on success, zero on error.
- Returns 0 on success, line number of first error on parse error (doesn't
- stop on first error), -1 on file open error, or -2 on memory allocation
- error (only when INI_USE_STACK is zero).
-*/
-int ini_parse(const char* filename, ini_handler handler, void* user);
-
-/* Same as ini_parse(), but takes a FILE* instead of filename. This doesn't
- close the file when it's finished -- the caller must do that. */
-int ini_parse_file(FILE* file, ini_handler handler, void* user);
-
-/* Same as ini_parse(), but takes an ini_reader function pointer instead of
- filename. Used for implementing custom or string-based I/O. */
-int ini_parse_stream(ini_reader reader, void* stream, ini_handler handler,
- void* user);
-
-/* Nonzero to allow multi-line value parsing, in the style of Python's
- configparser. If allowed, ini_parse() will call the handler with the same
- name for each subsequent line parsed. */
-#ifndef INI_ALLOW_MULTILINE
-#define INI_ALLOW_MULTILINE 1
-#endif
-
-/* Nonzero to allow a UTF-8 BOM sequence (0xEF 0xBB 0xBF) at the start of
- the file. See http://code.google.com/p/inih/issues/detail?id=21 */
-#ifndef INI_ALLOW_BOM
-#define INI_ALLOW_BOM 1
-#endif
-
-/* Nonzero to allow inline comments (with valid inline comment characters
- specified by INI_INLINE_COMMENT_PREFIXES). Set to 0 to turn off and match
- Python 3.2+ configparser behaviour. */
-#ifndef INI_ALLOW_INLINE_COMMENTS
-#define INI_ALLOW_INLINE_COMMENTS 1
-#endif
-#ifndef INI_INLINE_COMMENT_PREFIXES
-#define INI_INLINE_COMMENT_PREFIXES ";"
-#endif
-
-/* Nonzero to use stack, zero to use heap (malloc/free). */
-#ifndef INI_USE_STACK
-#define INI_USE_STACK 1
-#endif
-
-/* Stop parsing on first error (default is to keep parsing). */
-#ifndef INI_STOP_ON_FIRST_ERROR
-#define INI_STOP_ON_FIRST_ERROR 0
-#endif
-
-/* Maximum line length for any line in INI file. */
-#ifndef INI_MAX_LINE
-#define INI_MAX_LINE 200
-#endif
-
-#ifdef __cplusplus
-}
-#endif
-
-/* inih -- simple .INI file parser
-inih is released under the New BSD license (see LICENSE.txt). Go to the project
-home page for more info:
-https://github.com/benhoyt/inih
-*/
-
-#if defined(_MSC_VER) && !defined(_CRT_SECURE_NO_WARNINGS)
-#define _CRT_SECURE_NO_WARNINGS
-#endif
-
-#include
-#include
-#include
-
-#if !INI_USE_STACK
-#include
-#endif
-
-#define MAX_SECTION 50
-#define MAX_NAME 50
-
-/* Strip whitespace chars off end of given string, in place. Return s. */
-inline static char* rstrip(char* s)
-{
- char* p = s + strlen(s);
- while (p > s && isspace((unsigned char)(*--p)))
- *p = '\0';
- return s;
-}
-
-/* Return pointer to first non-whitespace char in given string. */
-inline static char* lskip(const char* s)
-{
- while (*s && isspace((unsigned char)(*s)))
- s++;
- return (char*)s;
-}
-
-/* Return pointer to first char (of chars) or inline comment in given string,
- or pointer to null at end of string if neither found. Inline comment must
- be prefixed by a whitespace character to register as a comment. */
-inline static char* find_chars_or_comment(const char* s, const char* chars)
-{
-#if INI_ALLOW_INLINE_COMMENTS
- int was_space = 0;
- while (*s && (!chars || !strchr(chars, *s)) &&
- !(was_space && strchr(INI_INLINE_COMMENT_PREFIXES, *s))) {
- was_space = isspace((unsigned char)(*s));
- s++;
- }
-#else
- while (*s && (!chars || !strchr(chars, *s))) {
- s++;
- }
-#endif
- return (char*)s;
-}
-
-/* Version of strncpy that ensures dest (size bytes) is null-terminated. */
-inline static char* strncpy0(char* dest, const char* src, size_t size)
-{
- strncpy(dest, src, size);
- dest[size - 1] = '\0';
- return dest;
-}
-
-/* See documentation in header file. */
-inline int ini_parse_stream(ini_reader reader, void* stream, ini_handler handler,
- void* user)
-{
- /* Uses a fair bit of stack (use heap instead if you need to) */
-#if INI_USE_STACK
- char line[INI_MAX_LINE];
-#else
- char* line;
-#endif
- char section[MAX_SECTION] = "";
- char prev_name[MAX_NAME] = "";
-
- char* start;
- char* end;
- char* name;
- char* value;
- int lineno = 0;
- int error = 0;
-
-#if !INI_USE_STACK
- line = (char*)malloc(INI_MAX_LINE);
- if (!line) {
- return -2;
- }
-#endif
-
- /* Scan through stream line by line */
- while (reader(line, INI_MAX_LINE, stream) != NULL) {
- lineno++;
-
- start = line;
-#if INI_ALLOW_BOM
- if (lineno == 1 && (unsigned char)start[0] == 0xEF &&
- (unsigned char)start[1] == 0xBB &&
- (unsigned char)start[2] == 0xBF) {
- start += 3;
- }
-#endif
- start = lskip(rstrip(start));
-
- if (*start == ';' || *start == '#') {
- /* Per Python configparser, allow both ; and # comments at the
- start of a line */
- }
-#if INI_ALLOW_MULTILINE
- else if (*prev_name && *start && start > line) {
-
-#if INI_ALLOW_INLINE_COMMENTS
- end = find_chars_or_comment(start, NULL);
- if (*end)
- *end = '\0';
- rstrip(start);
-#endif
-
- /* Non-blank line with leading whitespace, treat as continuation
- of previous name's value (as per Python configparser). */
- if (!handler(user, section, prev_name, start) && !error)
- error = lineno;
- }
-#endif
- else if (*start == '[') {
- /* A "[section]" line */
- end = find_chars_or_comment(start + 1, "]");
- if (*end == ']') {
- *end = '\0';
- strncpy0(section, start + 1, sizeof(section));
- *prev_name = '\0';
- }
- else if (!error) {
- /* No ']' found on section line */
- error = lineno;
- }
- }
- else if (*start) {
- /* Not a comment, must be a name[=:]value pair */
- end = find_chars_or_comment(start, "=:");
- if (*end == '=' || *end == ':') {
- *end = '\0';
- name = rstrip(start);
- value = lskip(end + 1);
-#if INI_ALLOW_INLINE_COMMENTS
- end = find_chars_or_comment(value, NULL);
- if (*end)
- *end = '\0';
-#endif
- rstrip(value);
-
- /* Valid name[=:]value pair found, call handler */
- strncpy0(prev_name, name, sizeof(prev_name));
- if (!handler(user, section, name, value) && !error)
- error = lineno;
- }
- else if (!error) {
- /* No '=' or ':' found on name[=:]value line */
- error = lineno;
- }
- }
-
-#if INI_STOP_ON_FIRST_ERROR
- if (error)
- break;
-#endif
- }
-
-#if !INI_USE_STACK
- free(line);
-#endif
-
- return error;
-}
-
-/* See documentation in header file. */
-inline int ini_parse_file(FILE* file, ini_handler handler, void* user)
-{
- return ini_parse_stream((ini_reader)fgets, file, handler, user);
-}
-
-/* See documentation in header file. */
-inline int ini_parse(const char* filename, ini_handler handler, void* user)
-{
- FILE* file;
- int error;
-
- file = fopen(filename, "r");
- if (!file)
- return -1;
- error = ini_parse_file(file, handler, user);
- fclose(file);
- return error;
-}
-
-#endif /* __INI_H__ */
-
-
-#ifndef __INIREADER_H__
-#define __INIREADER_H__
-
-#include