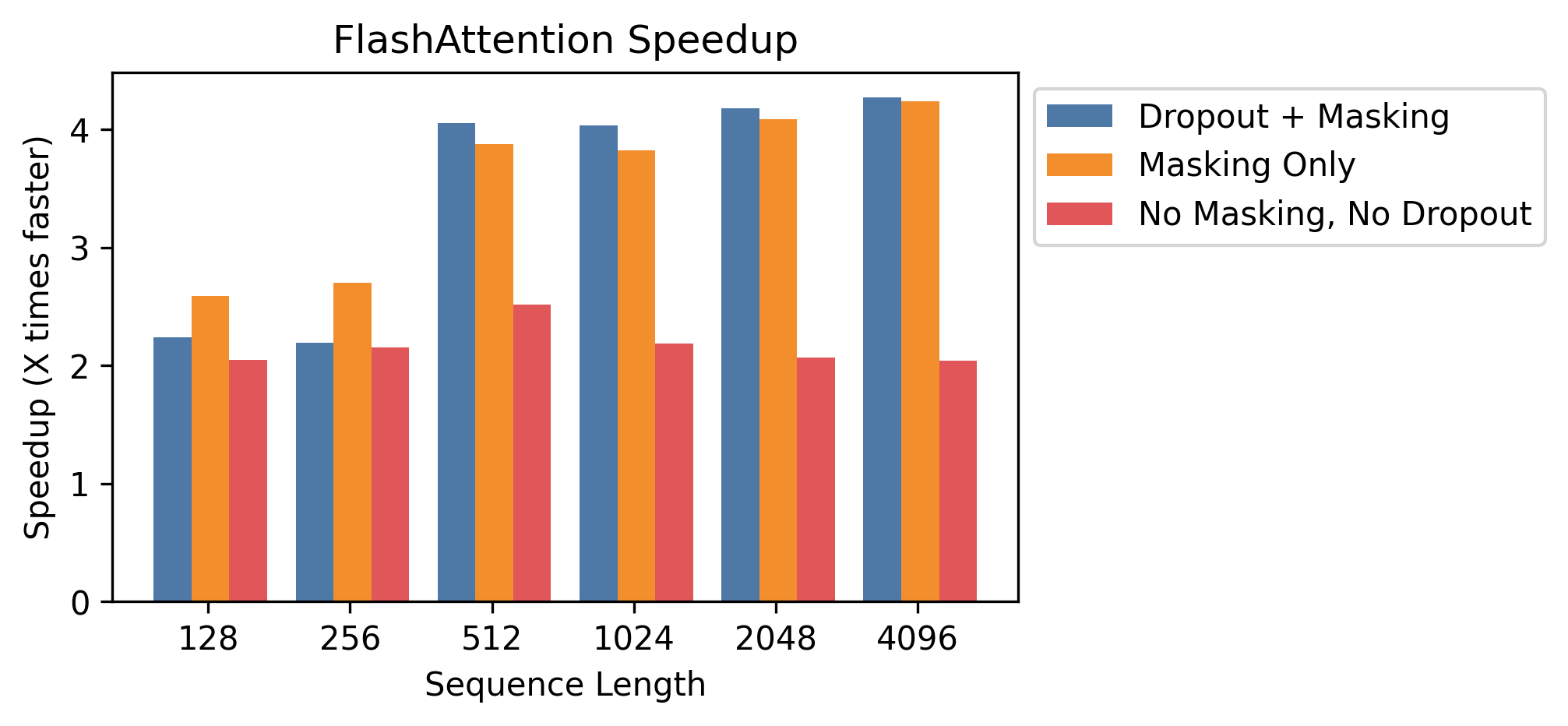
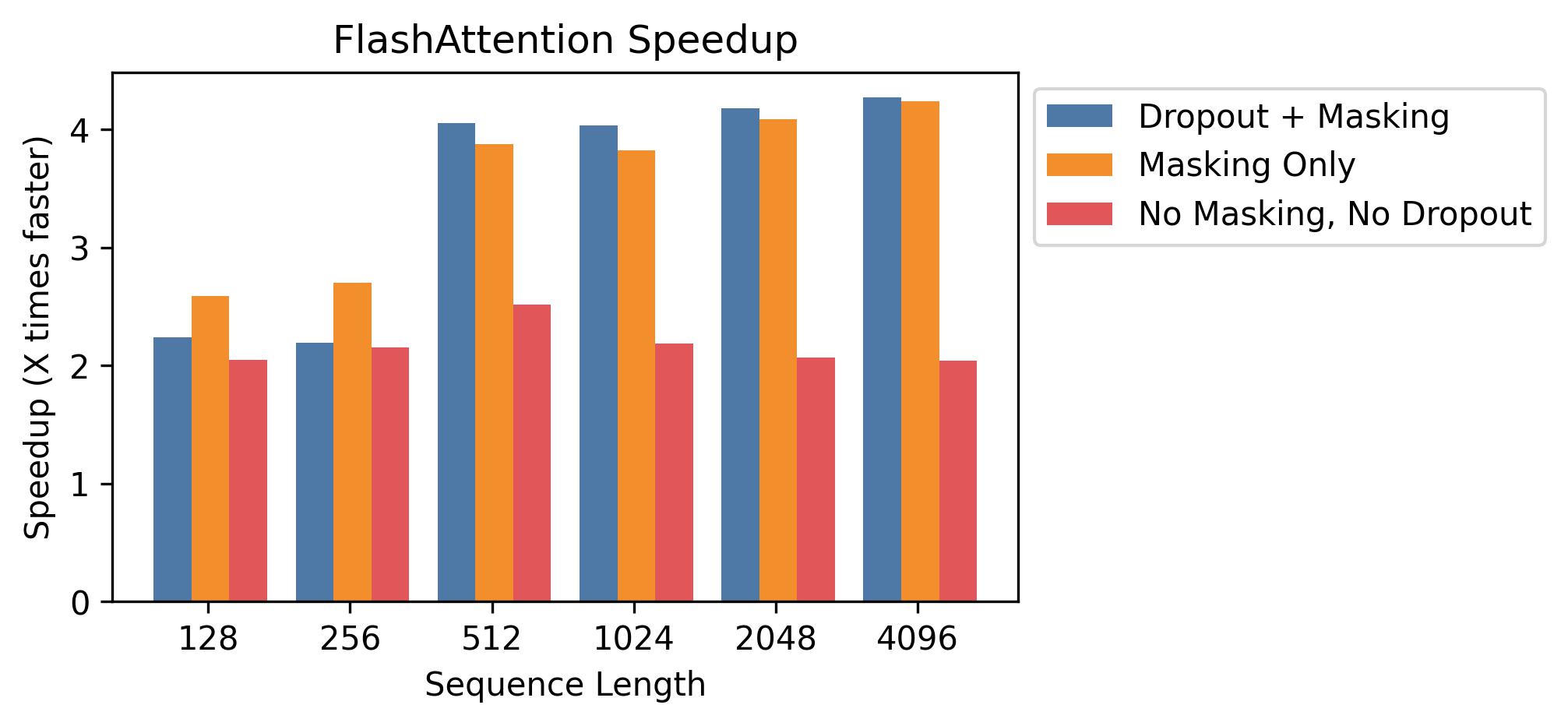
We generally see 2-4X speedup at sequence lengths between 128 and 4K, and we see more speedup when using dropout and masking, since we fuse the kernels.
At sequence lengths that are popular with language models like 512 and 1K, we see speedups up to 4X when using dropout and masking.
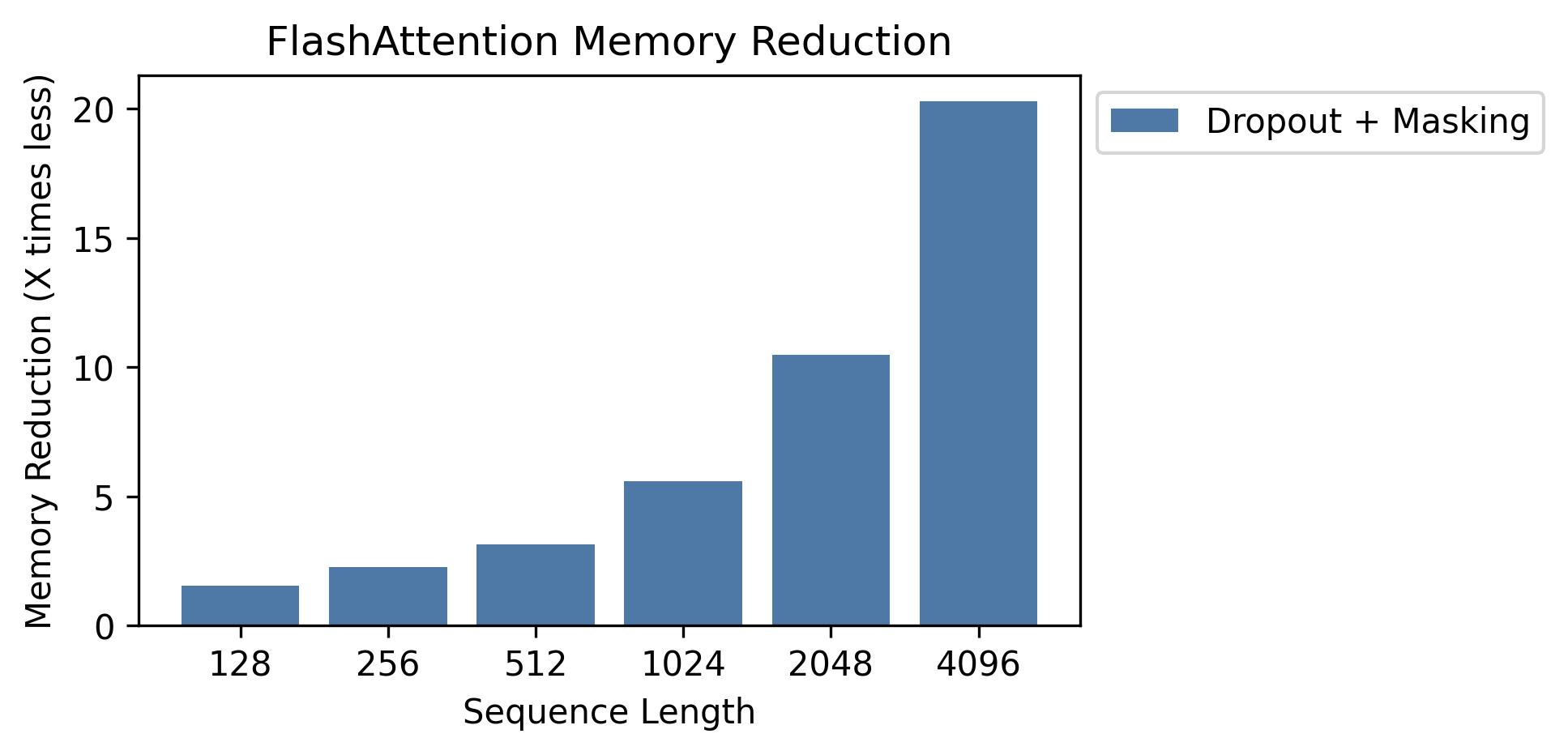
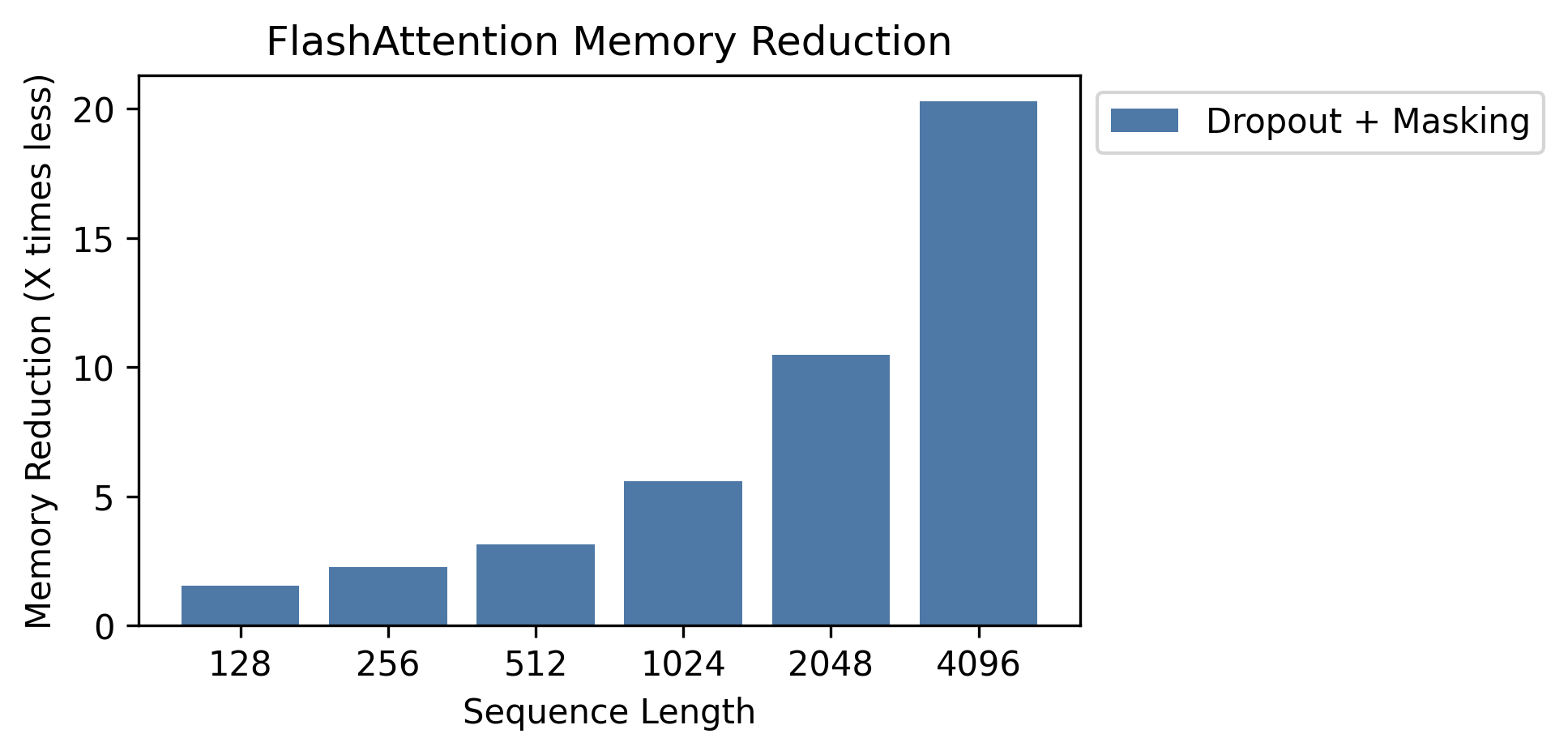
We show memory savings in this graph (note that memory footprint is the same no matter if you use dropout or masking).
Memory savings are proportional to sequence length -- since standard attention has memory quadratic in sequence length, whereas FlashAttention has memory linear in sequence length.

{kind=link}
{kind=link}
{kind=link}
{kind=link}