
[CK_TILE] layernorm support fused-quant/fused-add (#1604)
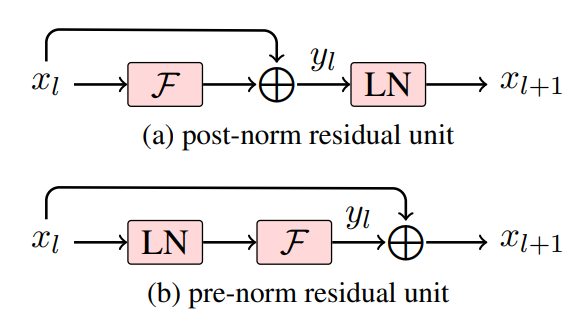
* add prenorm/postnorm support, refactor using generate.py * update README * update README * fix format * update some description and fix format * update format * format * use non-raw for loading * format and update n4096 * dynamic-quant ready * update readme * support fused dynamic-quant * update fused-quant, with smooth * update README * update args * update some based on comment
Showing
{kind=link}

36 KB
{kind=link}
31.4 KB