
Merge branch 'develop' into wavelet_model
Showing
CITATION.cff
0 → 100644
CONTRIBUTORS.md
0 → 100644
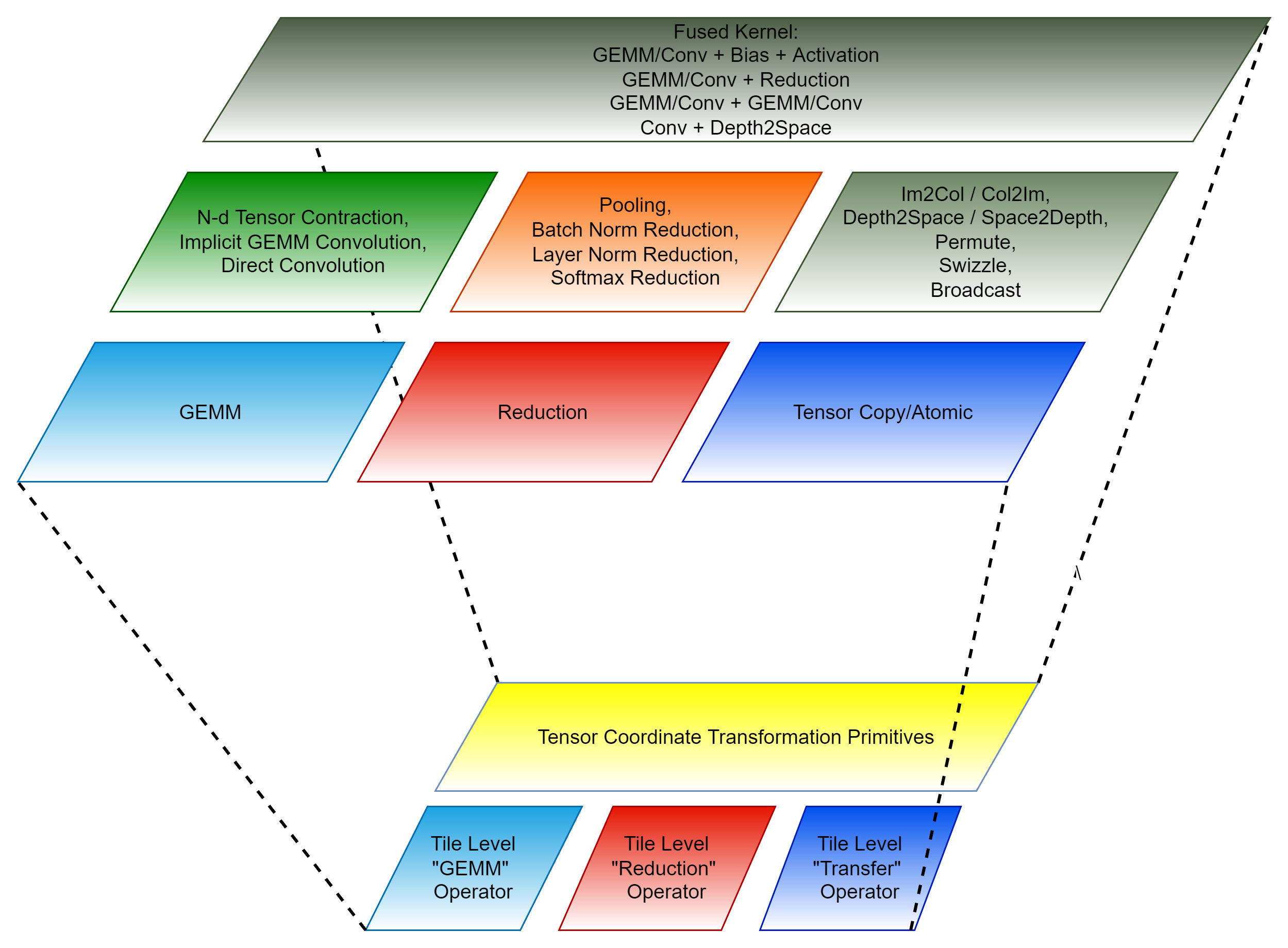
doc/image/ck_component.png
0 → 100644
{kind=link}
552 KB
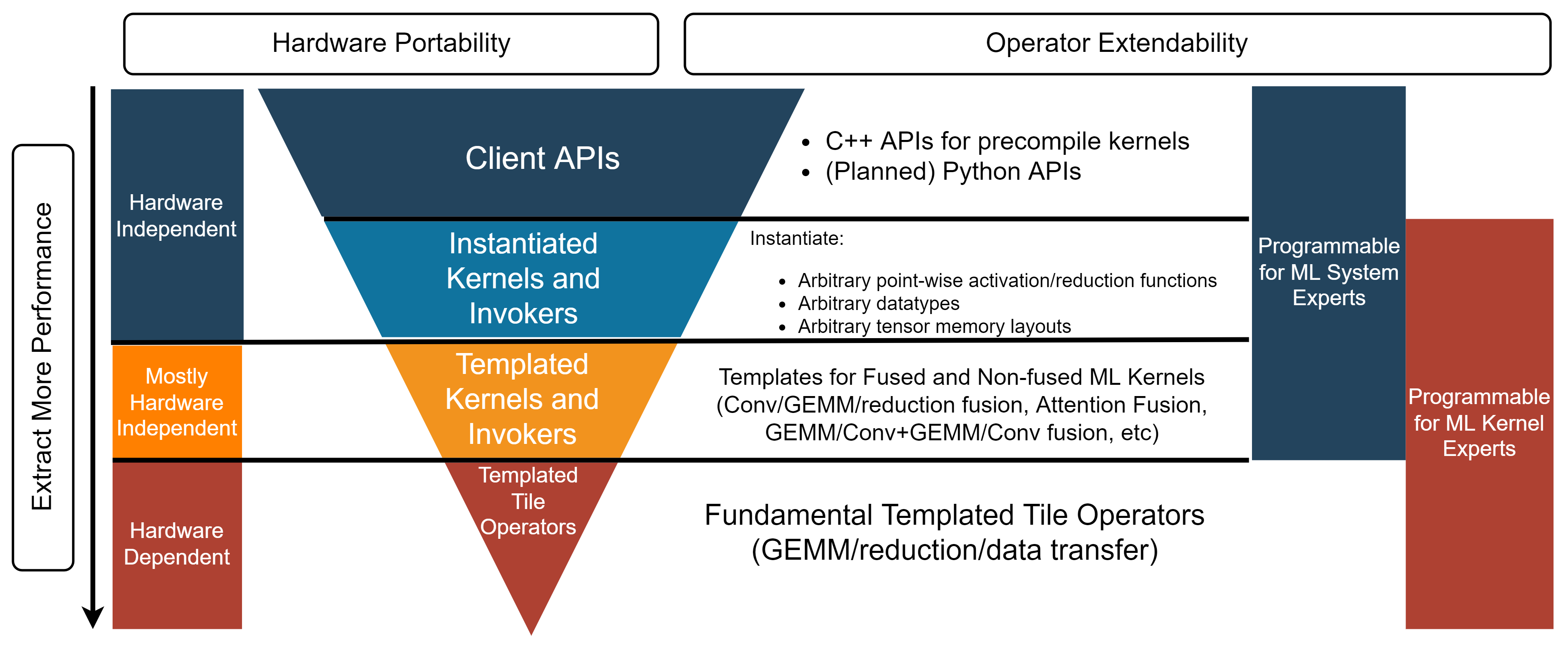
doc/image/ck_layer.png
0 → 100644
{kind=link}
536 KB