DLRM:Deep Learning Recommendation Model for Personalization and Recommendation Systems
=================================================================================
简介
------------
一个深度学习推荐模型(DLRM)的实现。
模型的输入由稠密特征和稀疏特征组成。前者是一个浮点值向量;后者是一组稀疏索引,用于查找嵌入表中的向量(这些嵌入表由浮点向量组成)。
选取到的这些向量会被送入若干 多层感知机(MLP)网络(通常在示意图中用三角形表示),在某些情况下,这些向量之间还会通过特定的算子(Ops)进行交互
```
output:
probability of a click
model: |
/\
/__\
|
_____________________> Op <___________________
/ | \
/\ /\ /\
/__\ /__\ ... /__\
| | |
| Op Op
| ____/__\_____ ____/__\____
| |_Emb_|____|__| ... |_Emb_|__|___|
input:
[ dense features ] [sparse indices] , ..., [sparse indices]
```
对模型各层的更精确定义:
1)MLP(多层感知机)的全连接层
z = f(y)
y = Wx + b
2)嵌入查找(针对一组稀疏索引 p=[p1,...,pk]p = [p_1, ..., p_k]p=[p1,...,pk])
z = Op(e1,...,ek)
obtain vectors e1=E[:,p1], ..., ek=E[:,pk]
3)算子 Op 可以是以下几种之一
Sum(e1,...,ek) = e1 + ... + ek
Dot(e1,...,ek) = [e1'e1, ..., e1'ek, ..., ek'e1, ..., ek'ek]
Cat(e1,...,ek) = [e1', ..., ek']'
where ' denotes transpose operation
部署
--------------
### Docker
**容器创建**
```bash
docker run --shm-size 500g --network=host --name=dlrm --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v /path/to/workspace/:/path/to/workspace/ -v /opt/hyhal:/opt/hyhal:ro -it image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.4.1-ubuntu22.04-dtk25.04.1-py3.10 bash
```
**依赖安装**
```bash
cd dlrm
pip install -r requirements.txt
pip install tensorboard
```
注意:使用 `-i https://pypi.tuna.tsinghua.edu.cn/simple` 会导致 `torchrec-nightly` 相关依赖安装失败
Demo
--------------------
1)使用微型模型运行代码
```bash
python dlrm_s_pytorch.py --mini-batch-size=2 --data-size=6
```
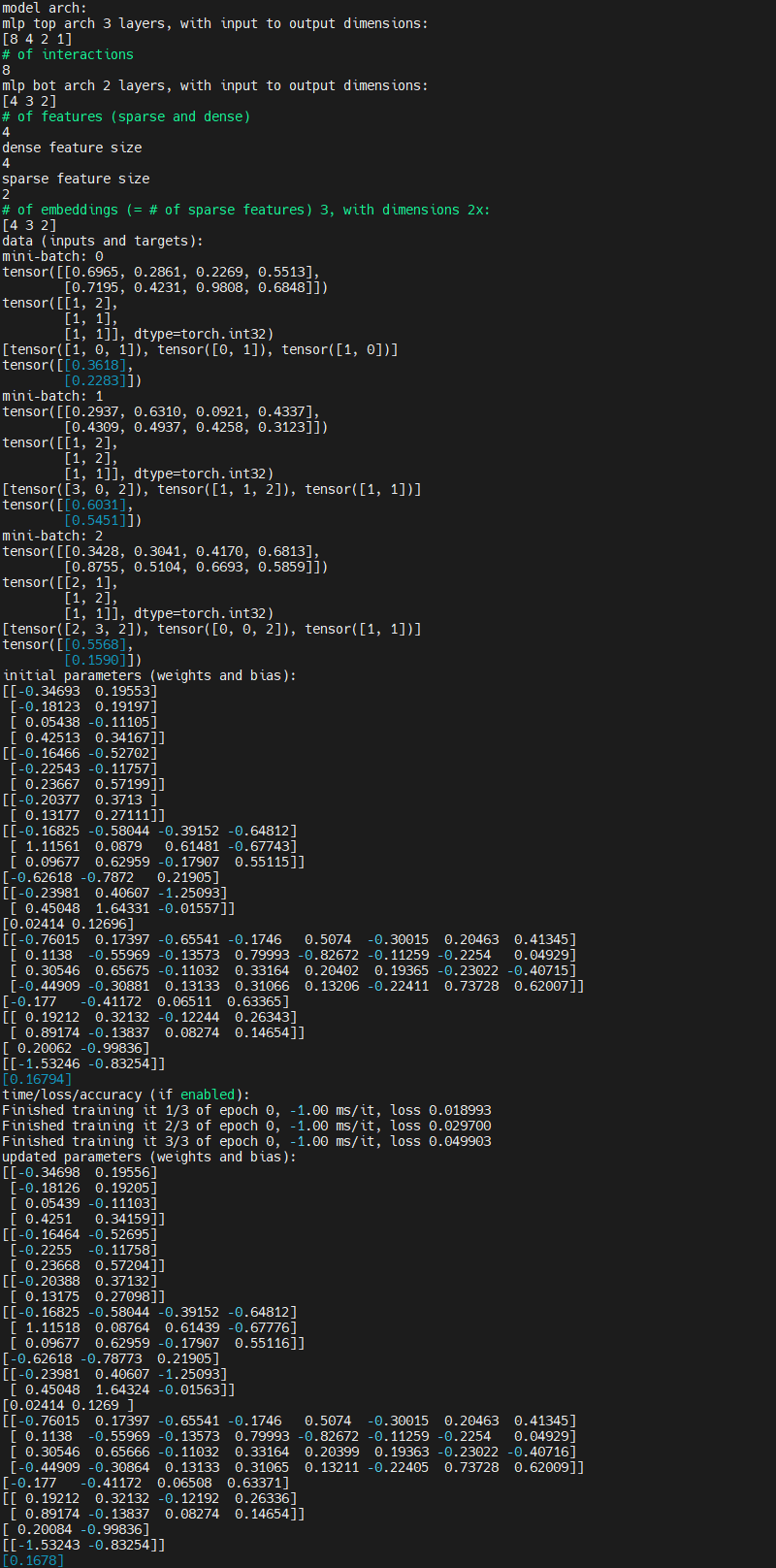
 2)在调试模式下使用微型模型运行代码
```bash
python dlrm_s_pytorch.py --mini-batch-size=2 --data-size=6 --debug-mode
```
2)在调试模式下使用微型模型运行代码
```bash
python dlrm_s_pytorch.py --mini-batch-size=2 --data-size=6 --debug-mode
```
 测试
-------
验证代码功能正确性
```bash
./test/dlrm_s_test.sh
```
测试
-------
验证代码功能正确性
```bash
./test/dlrm_s_test.sh
```
 基准测试
------------
1)性能基准测试
```bash
./bench/dlrm_s_benchmark.sh
```
2)代码支持数据集 [Criteo Kaggle Display Advertising Challenge Dataset](https://ailab.criteo.com/ressources/)
- 请按以下步骤准备数据,以便在 DLRM 代码中使用:
- 首先,指定下载好的原始数据文件(train.txt),使用参数 `--raw-data-file=`
- 然后对数据进行预处理(分类、跨天合并等),以便在 DLRM 代码中使用
- 预处理后的数据会存储为 `*.npz` 文件,路径为 `/input/*.npz`
- 预处理后的文件 (`*.npz`) 可以在后续运行中直接使用,参数为 `--processed-data-file=`
- 可以使用以下脚本对模型进行训练
```bash
./bench/dlrm_s_criteo_kaggle.sh [--test-freq=1024]
```
若要启用gpu,添加参数 `--use-gpu`;若要启用纯推理模式,添加参数 `--inference-only` 并使用参数 `--load-model`指定权重文件
基准测试
------------
1)性能基准测试
```bash
./bench/dlrm_s_benchmark.sh
```
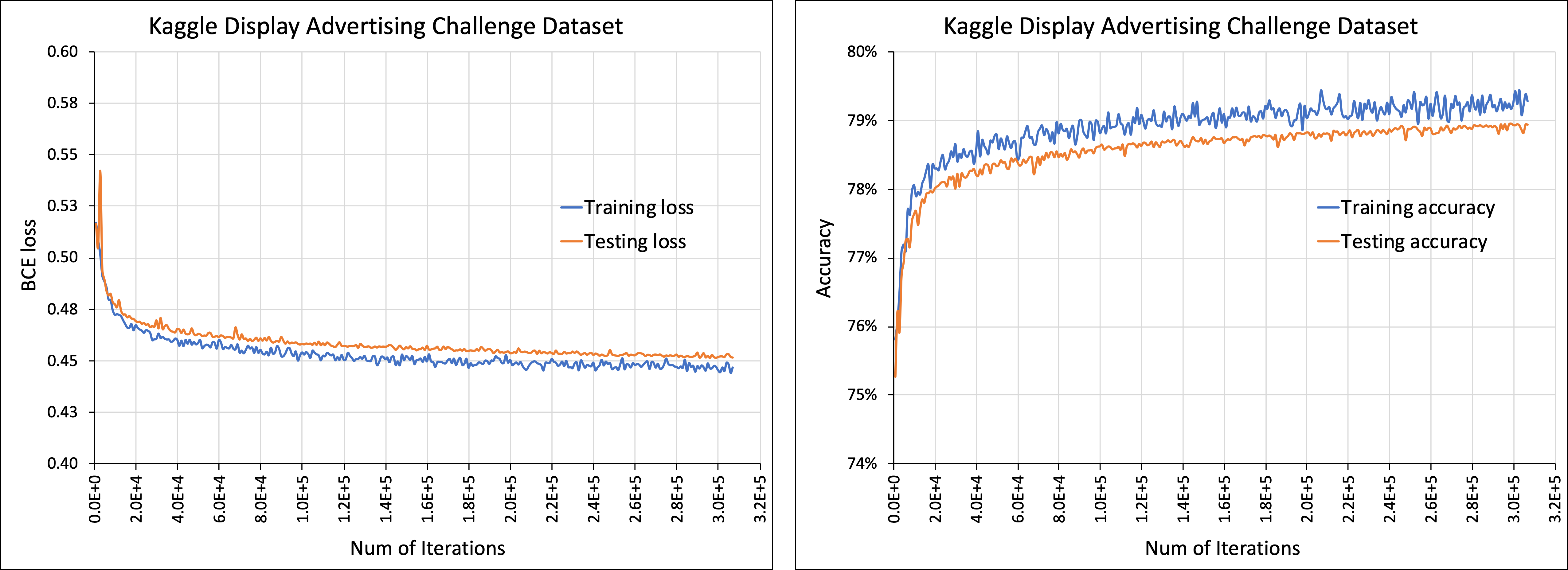
2)代码支持数据集 [Criteo Kaggle Display Advertising Challenge Dataset](https://ailab.criteo.com/ressources/)
- 请按以下步骤准备数据,以便在 DLRM 代码中使用:
- 首先,指定下载好的原始数据文件(train.txt),使用参数 `--raw-data-file=`
- 然后对数据进行预处理(分类、跨天合并等),以便在 DLRM 代码中使用
- 预处理后的数据会存储为 `*.npz` 文件,路径为 `/input/*.npz`
- 预处理后的文件 (`*.npz`) 可以在后续运行中直接使用,参数为 `--processed-data-file=`
- 可以使用以下脚本对模型进行训练
```bash
./bench/dlrm_s_criteo_kaggle.sh [--test-freq=1024]
```
若要启用gpu,添加参数 `--use-gpu`;若要启用纯推理模式,添加参数 `--inference-only` 并使用参数 `--load-model`指定权重文件
 3)代码支持数据集 [Criteo Terabyte Dataset](https://labs.criteo.com/2013/12/download-terabyte-click-logs/).
- 请按以下步骤准备数据,以便在 DLRM 代码中使用:
- 首先,下载原始数据文件 `day_0.gz` 到 `day_23.gz` 并解压
- 使用参数 `--raw-data-file=` 指定解压后的文本文件位置 `day_0` 到 `day_23`(天数会自动追加)
- 然后对数据进行预处理(分类、跨天合并等),以便在 DLRM 代码中使用
- 预处理后的数据会存储为 `*.npz` 文件,路径为 `/input/*.npz`
- 预处理后的文件 (`*.npz`) 可以在后续运行中直接使用,参数为 `--processed-data-file=`
- 可以使用以下脚本对模型进行训练
```bash
./bench/dlrm_s_criteo_terabyte.sh ["--test-freq=10240 --memory-map --data-sub-sample-rate=0.875"]
```
若要启用gpu,添加参数 `--use-gpu`;若要启用纯推理模式,添加参数 `--inference-only` 并使用参数 `--load-model`指定权重文件
- 对应的预训练模型可从以下链接下载:[dlrm_emb64_subsample0.875_maxindrange10M_pretrained.pt](https://dlrm.s3-us-west-1.amazonaws.com/models/tb0875_10M.pt)
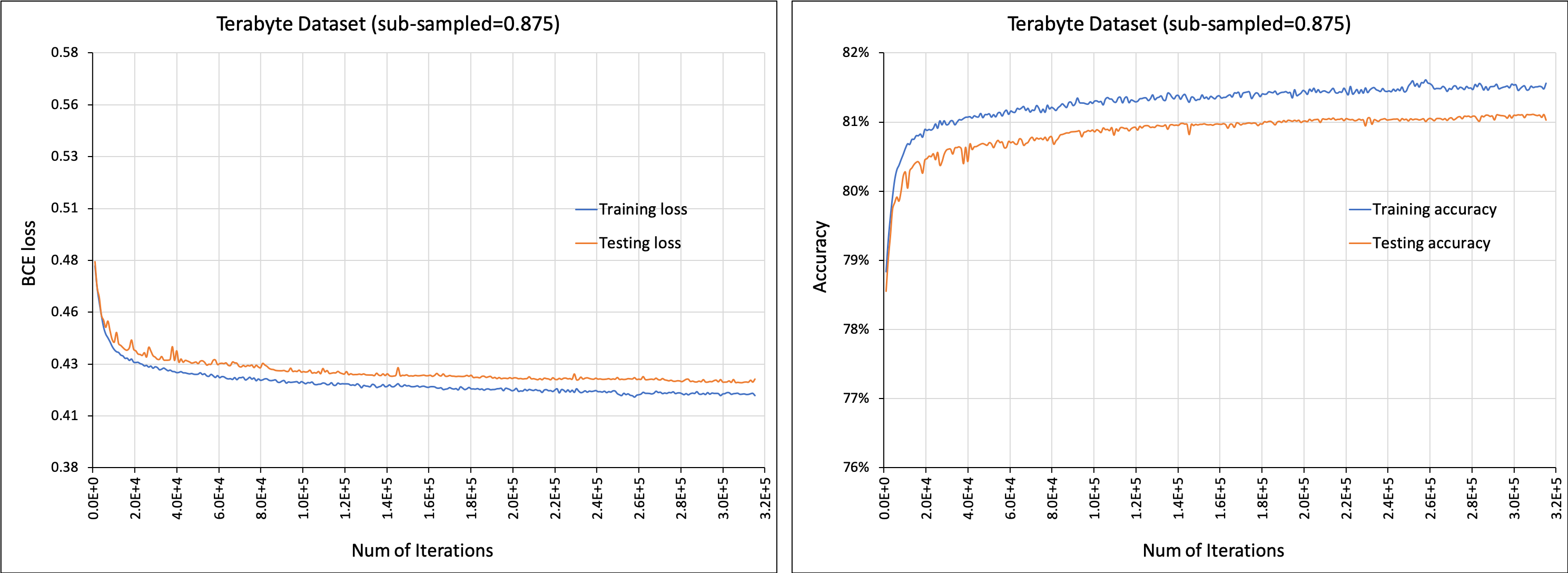
3)代码支持数据集 [Criteo Terabyte Dataset](https://labs.criteo.com/2013/12/download-terabyte-click-logs/).
- 请按以下步骤准备数据,以便在 DLRM 代码中使用:
- 首先,下载原始数据文件 `day_0.gz` 到 `day_23.gz` 并解压
- 使用参数 `--raw-data-file=` 指定解压后的文本文件位置 `day_0` 到 `day_23`(天数会自动追加)
- 然后对数据进行预处理(分类、跨天合并等),以便在 DLRM 代码中使用
- 预处理后的数据会存储为 `*.npz` 文件,路径为 `/input/*.npz`
- 预处理后的文件 (`*.npz`) 可以在后续运行中直接使用,参数为 `--processed-data-file=`
- 可以使用以下脚本对模型进行训练
```bash
./bench/dlrm_s_criteo_terabyte.sh ["--test-freq=10240 --memory-map --data-sub-sample-rate=0.875"]
```
若要启用gpu,添加参数 `--use-gpu`;若要启用纯推理模式,添加参数 `--inference-only` 并使用参数 `--load-model`指定权重文件
- 对应的预训练模型可从以下链接下载:[dlrm_emb64_subsample0.875_maxindrange10M_pretrained.pt](https://dlrm.s3-us-west-1.amazonaws.com/models/tb0875_10M.pt)
 4)代码支持 [MLPerf benchmark](https://mlperf.org).
- 请参考以下训练参数
```bash
--mlperf-logging 用于跟踪多个指标,包括曲线下面积(AUC)
--mlperf-acc-threshold 允许基于准确率指标提前停止训练
--mlperf-auc-threshold 允许基于 AUC 指标提前停止训练
--mlperf-bin-loader 启用将数据预处理成单个二进制文件
--mlperf-bin-shuffle 控制是否对小批量数据进行随机打乱
```
- MLPerf 模型可使用以下脚本进行训练。
```bash
./bench/run_and_time.sh [--use-gpu]
```
- 对应的预训练模型可从以下链接下载:[dlrm_emb128_subsample0.0_maxindrange40M_pretrained.pt](https://dlrm.s3-us-west-1.amazonaws.com/models/tb00_40M.pt)
5)该代码现在支持同步分布式训练,支持 gloo/nccl/mpi 后端,同时提供了 [PyTorch 分布式启动器](https://pytorch.org/docs/stable/distributed.html#launch-utility) 和 Mpirun 的启动方式。对于 MPI,用户需要自行编写 MPI 启动脚本来配置运行主机。例如,使用 PyTorch 分布式启动器,可以使用如下命令作为启动脚本:
```bash
# 在单节点 8 GPU 环境下,使用 NCCL 作为后端处理随机生成的数据集时:
python -m torch.distributed.launch --nproc_per_node=8 dlrm_s_pytorch.py --arch-embedding-size="80000-80000-80000-80000-80000-80000-80000-80000" --arch-sparse-feature-size=64 --arch-mlp-bot="128-128-128-128" --arch-mlp-top="512-512-512-256-1" --max-ind-range=40000000
--data-generation=random --loss-function=bce --round-targets=True --learning-rate=1.0 --mini-batch-size=2048 --print-freq=2 --print-time --test-freq=2 --test-mini-batch-size=2048 --memory-map --use-gpu --num-batches=100 --dist-backend=nccl
# 对于多节点环境,用户可以根据启动器手册添加相关参数,例如:
--nnodes=2 --node_rank=0 --master_addr="192.168.1.1" --master_port=1234
```
模型检查点保存/加载
-------------------------------
在训练过程中,可以使用参数 `--save-model=` 保存模型
当测试准确率有所提升时(按 `--test-freq` 指定的间隔检查),模型会被保存
已保存的模型可以通过 `--load-model=` 加载
加载后,模型可以用于继续训练,已保存的模型相当于一个检查点或者,也可以通过指定 `--inference-only` 选项,仅使用保存的模型在测试数据集上进行评估
参考资料
-------
https://github.com/facebookresearch/dlrm
4)代码支持 [MLPerf benchmark](https://mlperf.org).
- 请参考以下训练参数
```bash
--mlperf-logging 用于跟踪多个指标,包括曲线下面积(AUC)
--mlperf-acc-threshold 允许基于准确率指标提前停止训练
--mlperf-auc-threshold 允许基于 AUC 指标提前停止训练
--mlperf-bin-loader 启用将数据预处理成单个二进制文件
--mlperf-bin-shuffle 控制是否对小批量数据进行随机打乱
```
- MLPerf 模型可使用以下脚本进行训练。
```bash
./bench/run_and_time.sh [--use-gpu]
```
- 对应的预训练模型可从以下链接下载:[dlrm_emb128_subsample0.0_maxindrange40M_pretrained.pt](https://dlrm.s3-us-west-1.amazonaws.com/models/tb00_40M.pt)
5)该代码现在支持同步分布式训练,支持 gloo/nccl/mpi 后端,同时提供了 [PyTorch 分布式启动器](https://pytorch.org/docs/stable/distributed.html#launch-utility) 和 Mpirun 的启动方式。对于 MPI,用户需要自行编写 MPI 启动脚本来配置运行主机。例如,使用 PyTorch 分布式启动器,可以使用如下命令作为启动脚本:
```bash
# 在单节点 8 GPU 环境下,使用 NCCL 作为后端处理随机生成的数据集时:
python -m torch.distributed.launch --nproc_per_node=8 dlrm_s_pytorch.py --arch-embedding-size="80000-80000-80000-80000-80000-80000-80000-80000" --arch-sparse-feature-size=64 --arch-mlp-bot="128-128-128-128" --arch-mlp-top="512-512-512-256-1" --max-ind-range=40000000
--data-generation=random --loss-function=bce --round-targets=True --learning-rate=1.0 --mini-batch-size=2048 --print-freq=2 --print-time --test-freq=2 --test-mini-batch-size=2048 --memory-map --use-gpu --num-batches=100 --dist-backend=nccl
# 对于多节点环境,用户可以根据启动器手册添加相关参数,例如:
--nnodes=2 --node_rank=0 --master_addr="192.168.1.1" --master_port=1234
```
模型检查点保存/加载
-------------------------------
在训练过程中,可以使用参数 `--save-model=` 保存模型
当测试准确率有所提升时(按 `--test-freq` 指定的间隔检查),模型会被保存
已保存的模型可以通过 `--load-model=` 加载
加载后,模型可以用于继续训练,已保存的模型相当于一个检查点或者,也可以通过指定 `--inference-only` 选项,仅使用保存的模型在测试数据集上进行评估
参考资料
-------
https://github.com/facebookresearch/dlrm