*This model was released on 2021-02-05 and added to Hugging Face Transformers on 2022-01-19.*
# ViLT
## Overview
The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334)
by Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design
for Vision-and-Language Pre-training (VLP).
The abstract from the paper is the following:
*Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks.
Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision
(e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we
find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more
computation than the multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive
power of the visual embedder and its predefined visual vocabulary. In this paper, we present a minimal VLP model,
Vision-and-Language Transformer (ViLT), monolithic in the sense that the processing of visual inputs is drastically
simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of
times faster than previous VLP models, yet with competitive or better downstream task performance.*
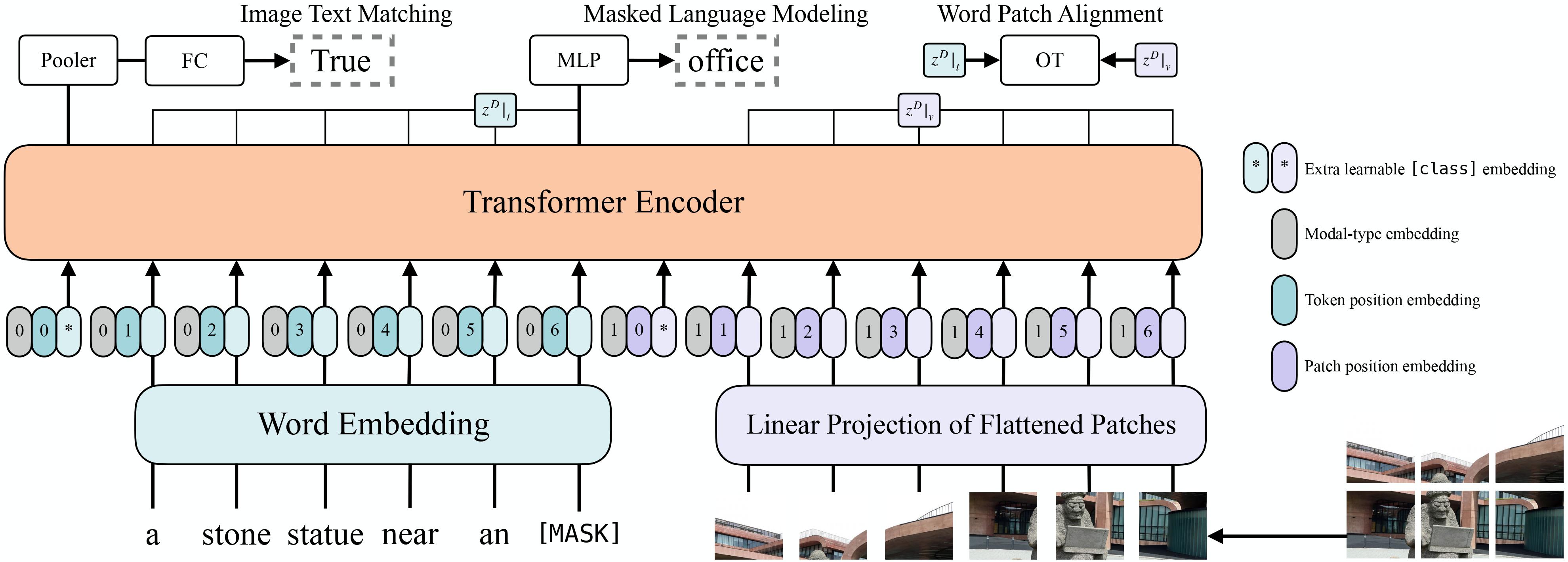 ViLT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
## Usage tips
- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
(which showcase both inference and fine-tuning on custom data).
- ViLT is a model that takes both `pixel_values` and `input_ids` as input. One can use [`ViltProcessor`] to prepare data for the model.
This processor wraps a image processor (for the image modality) and a tokenizer (for the language modality) into one.
- ViLT is trained with images of various sizes: the authors resize the shorter edge of input images to 384 and limit the longer edge to
under 640 while preserving the aspect ratio. To make batching of images possible, the authors use a `pixel_mask` that indicates
which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
- The PyTorch version of this model is only available in torch 1.10 and higher.
## ViltConfig
[[autodoc]] ViltConfig
## ViltImageProcessor
[[autodoc]] ViltImageProcessor
- preprocess
## ViltImageProcessorFast
[[autodoc]] ViltImageProcessorFast
- preprocess
## ViltProcessor
[[autodoc]] ViltProcessor
- __call__
## ViltModel
[[autodoc]] ViltModel
- forward
## ViltForMaskedLM
[[autodoc]] ViltForMaskedLM
- forward
## ViltForQuestionAnswering
[[autodoc]] ViltForQuestionAnswering
- forward
## ViltForImagesAndTextClassification
[[autodoc]] ViltForImagesAndTextClassification
- forward
## ViltForImageAndTextRetrieval
[[autodoc]] ViltForImageAndTextRetrieval
- forward
## ViltForTokenClassification
[[autodoc]] ViltForTokenClassification
- forward
ViLT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
## Usage tips
- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
(which showcase both inference and fine-tuning on custom data).
- ViLT is a model that takes both `pixel_values` and `input_ids` as input. One can use [`ViltProcessor`] to prepare data for the model.
This processor wraps a image processor (for the image modality) and a tokenizer (for the language modality) into one.
- ViLT is trained with images of various sizes: the authors resize the shorter edge of input images to 384 and limit the longer edge to
under 640 while preserving the aspect ratio. To make batching of images possible, the authors use a `pixel_mask` that indicates
which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
- The PyTorch version of this model is only available in torch 1.10 and higher.
## ViltConfig
[[autodoc]] ViltConfig
## ViltImageProcessor
[[autodoc]] ViltImageProcessor
- preprocess
## ViltImageProcessorFast
[[autodoc]] ViltImageProcessorFast
- preprocess
## ViltProcessor
[[autodoc]] ViltProcessor
- __call__
## ViltModel
[[autodoc]] ViltModel
- forward
## ViltForMaskedLM
[[autodoc]] ViltForMaskedLM
- forward
## ViltForQuestionAnswering
[[autodoc]] ViltForQuestionAnswering
- forward
## ViltForImagesAndTextClassification
[[autodoc]] ViltForImagesAndTextClassification
- forward
## ViltForImageAndTextRetrieval
[[autodoc]] ViltForImageAndTextRetrieval
- forward
## ViltForTokenClassification
[[autodoc]] ViltForTokenClassification
- forward