# Instruct-Pix2Pix
## 论文
- https://arxiv.org/abs/2211.09800
## 模型结构
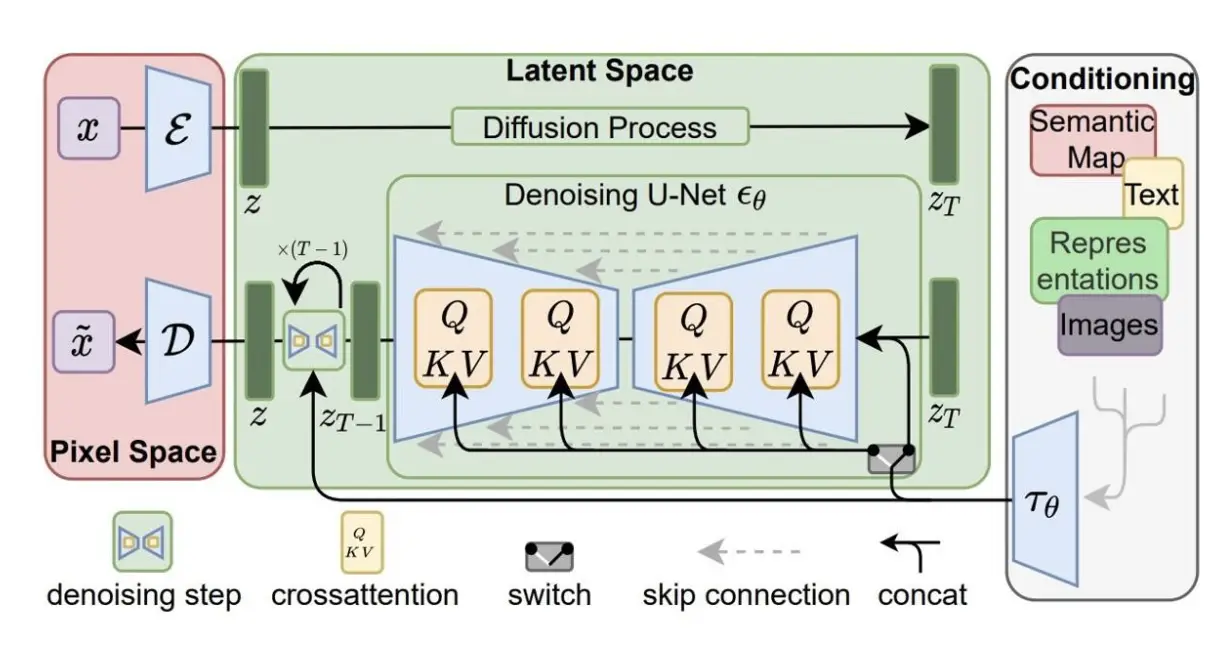
InstructPix2Pix 是在 Stable Diffusion 的基础上扩展和微调的一个基于指令微调的图像编辑模型,其核心任务是实现基于自然语言指令的图像编辑:
这里的conditioning输入为图像编辑指令
## 算法原理
InstrcutPix2Pix只需要编辑指令就可以对图像进行编辑(编辑指令:把自行车变成摩托车),而其他的方法( SDEdit 和 Text2Live)需要对图像进行描述,基于GPT-3、Stable Diffusion、Prompt-to-prompt、Classifier-free guidance;其中Prompt-to-prompt 是图像局部修改的原理性基础,也是数据生成的关键之一
算法步骤包括:
- 1、生成多模态训练数据集
生成过程分为两步:
第一、微调 GPT3 来生成配对的文本编辑的命令:给一张图的图像描述(Input Caption),生成一个命令(Instruction)来说明要改的内容,同时生成一个对应的编辑后的图片描述(Edited Caption)(上面结构图的左半部分)
文章中使用GPT3在一个小的自制数据集上微调,这个数据集包括:1)编辑前的图像描述;2)图像编辑命令;3)编辑后的图像描述,文章从LAION-Aesthetics V2 6.5+ 数据集里采集了700个输入图像描述(captions),手写了命令和输出图像描述
第二,使用文生图模型(SD+P2P),根据两个文本提示(编辑前图像描述和编辑后图像描述)生成一对相应图像
- 2、用生成数据来训一个条件扩散模型
基于 Stable Diffusion 模型框架训练图像生成模型
## 环境配置
### Docker(方法一)
从[光源](https://www.sourcefind.cn/#/service-list)中拉取docker镜像:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.2-py3.10
```
创建容器并挂载目录进行开发:
```
docker run -it --name {name} --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v {}:{} {docker_image} /bin/bash
# 修改1 {name} 需要改为自定义名称
# 修改2 {docker_image} 需要需要创建容器的对应镜像名称
# 修改3 -v 挂载路径到容器指定路径
pip install -r requirements.txt
```
### Dockerfile(方法二)
```
cd docker
docker build --no-cache -t instruct_pytorch:1.0 .
docker run -it --name {name} --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v {}:{} {docker_image} /bin/bash
pip install -r requirements.txt
```
### Anaconda(方法三)
线上节点推荐使用conda进行环境配置。
创建python=3.10的conda环境并激活
```
conda create -n instruct python=3.10
conda activate instruct
```
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.2
python:python3.10
pytorch:2.1.0
torchvision:0.16.0
```
安装其他依赖包
```
pip install -r requirements.txt
```
## 数据集
无
## 训练
无
## 推理
下载预训练权重文件并解压:
instruct_pix2pix预训练权重下载:[官网下载](http://instruct-pix2pix.eecs.berkeley.edu/instruct-pix2pix-00-22000.ckpt)
SCNet快速下载连接[SCNet下载](http://113.200.138.88:18080/aimodels/findsource-dependency/instruct_pix2pix),将ckpt文件保存至checkpoints文件夹中
解压命令:
```
cat instruct-pix2pix-00-22000_a* > instruct-pix2pix-00-22000.tar.gz
tar -zxf instruct-pix2pix-00-22000.tar.gz
```
clip-vit-large-patch14权重数据下载:
[huggingface下载](https://huggingface.co/openai/clip-vit-large-patch14)
SCNet快速下载连接[SCNet下载](http://113.200.138.88:18080/aimodels/findsource-dependency/clip-vit-large-patch14),所有文件下载后保存到openai/clip-vit-large-patch14文件夹中
```
# 图片+编辑生成编辑后的图像
python edit_cli.py --input imgs/example.jpg --output imgs/output.jpg --edit "turn him into a cyborg"
```
## result
输入原始图像为:
输入编辑指令为:
```
turn him into a cyborg
```
模型生成图片:
编辑后的图像保存位置:imgs/output.jpg
## 精度
无
## 应用场景
### 算法类别
多模态
### 热点应用行业
AIGC,设计,教育
## 源码仓库及问题反馈
[https://developer.sourcefind.cn/codes/dongchy920/instruct_pix2pix](https://developer.sourcefind.cn/codes/dongchy920/instruct_pix2pix)
## 参考资料
[https://github.com/timothybrooks/instruct-pix2pix](https://github.com/timothybrooks/instruct-pix2pix)