Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
dcuai
dlexamples
Commits
316d3f90
Commit
316d3f90
authored
Jul 14, 2022
by
Pan,Huiwen
Browse files
增加ds框架测试模型
parent
aebde649
Changes
227
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
3726 additions
and
0 deletions
+3726
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/examples/pretrain_bert_distributed.sh
....1.5-3D_parallelism/examples/pretrain_bert_distributed.sh
+44
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/examples/pretrain_gpt2.sh
...gatron-LM-v1.1.5-3D_parallelism/examples/pretrain_gpt2.sh
+43
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/examples/pretrain_gpt2_distributed.sh
....1.5-3D_parallelism/examples/pretrain_gpt2_distributed.sh
+52
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/Makefile
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/Makefile
+12
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/cases.png
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/cases.png
+0
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/scaling-dp.png
...d/Megatron-LM-v1.1.5-3D_parallelism/images/scaling-dp.png
+0
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/scaling-mp.png
...d/Megatron-LM-v1.1.5-3D_parallelism/images/scaling-mp.png
+0
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/tables.tex
...speed/Megatron-LM-v1.1.5-3D_parallelism/images/tables.tex
+40
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/__init__.py
...ed/Megatron-LM-v1.1.5-3D_parallelism/megatron/__init__.py
+41
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/arguments.py
...d/Megatron-LM-v1.1.5-3D_parallelism/megatron/arguments.py
+538
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/checkpointing.py
...gatron-LM-v1.1.5-3D_parallelism/megatron/checkpointing.py
+340
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/Makefile
.../Megatron-LM-v1.1.5-3D_parallelism/megatron/data/Makefile
+9
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/__init__.py
...gatron-LM-v1.1.5-3D_parallelism/megatron/data/__init__.py
+1
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/bert_dataset.py
...on-LM-v1.1.5-3D_parallelism/megatron/data/bert_dataset.py
+232
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/dataset_utils.py
...n-LM-v1.1.5-3D_parallelism/megatron/data/dataset_utils.py
+503
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/gpt2_dataset.py
...on-LM-v1.1.5-3D_parallelism/megatron/data/gpt2_dataset.py
+317
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/helpers.cpp
...gatron-LM-v1.1.5-3D_parallelism/megatron/data/helpers.cpp
+643
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/ict_dataset.py
...ron-LM-v1.1.5-3D_parallelism/megatron/data/ict_dataset.py
+140
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/indexed_dataset.py
...LM-v1.1.5-3D_parallelism/megatron/data/indexed_dataset.py
+570
-0
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/realm_dataset_utils.py
...1.1.5-3D_parallelism/megatron/data/realm_dataset_utils.py
+201
-0
No files found.
Too many changes to show.
To preserve performance only
227 of 227+
files are displayed.
Plain diff
Email patch
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/examples/pretrain_bert_distributed.sh
0 → 100644
View file @
316d3f90
#!/bin/bash
GPUS_PER_NODE
=
8
# Change for multinode config
MASTER_ADDR
=
localhost
MASTER_PORT
=
6000
NNODES
=
1
NODE_RANK
=
0
WORLD_SIZE
=
$((
$GPUS_PER_NODE
*
$NNODES
))
DATA_PATH
=
<Specify path and file prefix>_text_sentence
CHECKPOINT_PATH
=
<Specify path>
DISTRIBUTED_ARGS
=
"--nproc_per_node
$GPUS_PER_NODE
--nnodes
$NNODES
--node_rank
$NODE_RANK
--master_addr
$MASTER_ADDR
--master_port
$MASTER_PORT
"
python
-m
torch.distributed.launch
$DISTRIBUTED_ARGS
\
pretrain_bert.py
\
--model-parallel-size
1
\
--num-layers
24
\
--hidden-size
1024
\
--num-attention-heads
16
\
--batch-size
4
\
--seq-length
512
\
--max-position-embeddings
512
\
--train-iters
1000000
\
--save
$CHECKPOINT_PATH
\
--load
$CHECKPOINT_PATH
\
--data-path
$DATA_PATH
\
--vocab-file
bert-vocab.txt
\
--data-impl
mmap
\
--split
949,50,1
\
--distributed-backend
nccl
\
--lr
0.0001
\
--lr-decay-style
linear
\
--min-lr
1.0e-5
\
--lr-decay-iters
990000
\
--weight-decay
1e-2
\
--clip-grad
1.0
\
--warmup
.01
\
--log-interval
100
\
--save-interval
10000
\
--eval-interval
1000
\
--eval-iters
10
\
--fp16
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/examples/pretrain_gpt2.sh
0 → 100644
View file @
316d3f90
#! /bin/bash
# Runs the "345M" parameter model
RANK
=
0
WORLD_SIZE
=
1
DATA_PATH
=
<Specify path and file prefix>_text_document
CHECKPOINT_PATH
=
<Specify path>
python pretrain_gpt2.py
\
--num-layers
24
\
--hidden-size
1024
\
--num-attention-heads
16
\
--batch-size
8
\
--seq-length
1024
\
--max-position-embeddings
1024
\
--train-iters
500000
\
--lr-decay-iters
320000
\
--save
$CHECKPOINT_PATH
\
--load
$CHECKPOINT_PATH
\
--data-path
$DATA_PATH
\
--vocab-file
gpt2-vocab.json
\
--merge-file
gpt2-merges.txt
\
--data-impl
mmap
\
--split
949,50,1
\
--distributed-backend
nccl
\
--lr
0.00015
\
--min-lr
1.0e-5
\
--lr-decay-style
cosine
\
--weight-decay
1e-2
\
--clip-grad
1.0
\
--warmup
.01
\
--checkpoint-activations
\
--log-interval
100
\
--save-interval
10000
\
--eval-interval
1000
\
--eval-iters
10
\
--fp16
set
+x
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/examples/pretrain_gpt2_distributed.sh
0 → 100644
View file @
316d3f90
#! /bin/bash
# Runs the "345M" parameter model
GPUS_PER_NODE
=
8
# Change for multinode config
MASTER_ADDR
=
localhost
MASTER_PORT
=
6000
NNODES
=
1
NODE_RANK
=
0
WORLD_SIZE
=
$((
$GPUS_PER_NODE
*
$NNODES
))
DATA_PATH
=
<Specify path and file prefix>_text_document
CHECKPOINT_PATH
=
<Specify path>
DISTRIBUTED_ARGS
=
"--nproc_per_node
$GPUS_PER_NODE
--nnodes
$NNODES
--node_rank
$NODE_RANK
--master_addr
$MASTER_ADDR
--master_port
$MASTER_PORT
"
python
-m
torch.distributed.launch
$DISTRIBUTED_ARGS
\
pretrain_gpt2.py
\
--model-parallel-size
1
\
--num-layers
24
\
--hidden-size
1024
\
--num-attention-heads
16
\
--batch-size
8
\
--seq-length
1024
\
--max-position-embeddings
1024
\
--train-iters
500000
\
--lr-decay-iters
320000
\
--save
$CHECKPOINT_PATH
\
--load
$CHECKPOINT_PATH
\
--data-path
$DATA_PATH
\
--vocab-file
gpt2-vocab.json
\
--merge-file
gpt2-merges.txt
\
--data-impl
mmap
\
--split
949,50,1
\
--distributed-backend
nccl
\
--lr
0.00015
\
--lr-decay-style
cosine
\
--min-lr
1.0e-5
\
--weight-decay
1e-2
\
--clip-grad
1.0
\
--warmup
.01
\
--checkpoint-activations
\
--log-interval
100
\
--save-interval
10000
\
--eval-interval
1000
\
--eval-iters
10
\
--fp16
set
+x
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/Makefile
0 → 100644
View file @
316d3f90
default
:
cases.png scaling-mp.png scaling-dp.png
# for some reason the size option to convert in scaling.tex doesn't work, manually do it after
cases.png scaling-mp.png scaling-dp.png
:
tables.tex
latex
--shell-escape
$<
convert tables-1.png
-resize
650 cases.png
convert tables-2.png
-resize
600 scaling-mp.png
convert tables-3.png
-resize
350 scaling-dp.png
clean
:
rm
-rf
*
.aux
*
.log
*
.dvi
*
.ps
rm
-rf
tables-
*
.png
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/cases.png
0 → 100644
View file @
316d3f90
11.5 KB
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/scaling-dp.png
0 → 100644
View file @
316d3f90
13.1 KB
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/scaling-mp.png
0 → 100644
View file @
316d3f90
22.3 KB
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/images/tables.tex
0 → 100644
View file @
316d3f90
\documentclass
[multi,convert]
{
standalone
}
\usepackage
{
multirow
}
\standaloneenv
{
tabular
}
\begin{document}
\begin{tabular}
{
cccccc
}
Case
&
Hidden Size
&
Attention Heads
&
Layers
&
Parameters (billions)
&
Model Parallel Partitions
\\
\hline
1B
&
1920
&
15
&
24
&
1.16
&
1
\\
2B
&
2304
&
18
&
30
&
2.03
&
2
\\
4B
&
3072
&
24
&
36
&
4.24
&
4
\\
8B
&
4096
&
32
&
42
&
8.67
&
8
\\
\end{tabular}
\begin{tabular}
{
cc|ccc|ccc
}
&
&
\multicolumn
{
3
}{
c|
}{
\textbf
{
DGX-2 (V100) batch size 8
}}
&
\multicolumn
{
3
}{
c
}{
\textbf
{
DGX-A100 batch size 16
}}
\\
\hline
\multirow
{
2
}{
*
}{
Case
}
&
Number of
&
Iteration
&
\multirow
{
2
}{
*
}{
Scaling
}
&
TeraFLOPs
&
Iteration
&
\multirow
{
2
}{
*
}{
Scaling
}
&
TeraFLOPs
\\
&
GPUs
&
Time (ms)
&
&
per GPU
&
Time (ms)
&
&
per GPU
\\
\hline
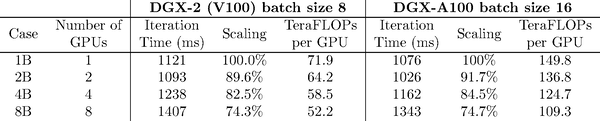
1B
&
1
&
1121
&
100.0
\%
&
71.9
&
1076
&
100
\%
&
149.8
\\
2B
&
2
&
1093
&
89.6
\%
&
64.2
&
1026
&
91.7
\%
&
136.8
\\
4B
&
4
&
1238
&
82.5
\%
&
58.5
&
1162
&
84.5
\%
&
124.7
\\
8B
&
8
&
1407
&
74.3
\%
&
52.2
&
1343
&
74.7
\%
&
109.3
\\
\end{tabular}
\begin{tabular}
{
cc|ccc
}
&
&
\multicolumn
{
3
}{
c
}{
\textbf
{
DGX-A100 batch size 2048
}}
\\
\hline
\multirow
{
2
}{
*
}{
Case
}
&
Number of
&
Iteration
&
\multirow
{
2
}{
*
}{
Scaling
}
&
TeraFLOPs
\\
&
GPUs
&
Time (ms)
&
&
per GPU
\\
\hline
1B
&
128
&
1153
&
93.3
\%
&
139.8
\\
2B
&
256
&
1101
&
85.5
\%
&
127.5
\\
4B
&
512
&
1242
&
79.0
\%
&
116.7
\\
8B
&
1024
&
1380
&
72.7
\%
&
106.5
\\
\end{tabular}
\end{document}
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/__init__.py
0 → 100644
View file @
316d3f90
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
torch
from
.package_info
import
(
__description__
,
__contact_names__
,
__url__
,
__download_url__
,
__keywords__
,
__license__
,
__package_name__
,
__version__
,
)
from
.global_vars
import
get_args
from
.global_vars
import
get_tokenizer
from
.global_vars
import
get_tensorboard_writer
from
.global_vars
import
get_adlr_autoresume
from
.global_vars
import
get_timers
from
.initialize
import
initialize_megatron
def
print_rank_0
(
message
):
"""If distributed is initialized print only on rank 0."""
if
torch
.
distributed
.
is_initialized
():
if
torch
.
distributed
.
get_rank
()
==
0
:
print
(
message
,
flush
=
True
)
else
:
print
(
message
,
flush
=
True
)
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/arguments.py
0 → 100644
View file @
316d3f90
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Megatron arguments."""
import
argparse
import
os
import
torch
from
megatron
import
fused_kernels
import
deepspeed
def
parse_args
(
extra_args_provider
=
None
,
defaults
=
{},
ignore_unknown_args
=
False
):
"""Parse all arguments."""
parser
=
argparse
.
ArgumentParser
(
description
=
'Megatron-LM Arguments'
,
allow_abbrev
=
False
)
# Standard arguments.
parser
=
_add_network_size_args
(
parser
)
parser
=
_add_regularization_args
(
parser
)
parser
=
_add_training_args
(
parser
)
parser
=
_add_initialization_args
(
parser
)
parser
=
_add_learning_rate_args
(
parser
)
parser
=
_add_checkpointing_args
(
parser
)
parser
=
_add_mixed_precision_args
(
parser
)
parser
=
_add_distributed_args
(
parser
)
parser
=
_add_validation_args
(
parser
)
parser
=
_add_data_args
(
parser
)
parser
=
_add_autoresume_args
(
parser
)
parser
=
_add_realm_args
(
parser
)
parser
=
_add_zero_args
(
parser
)
parser
=
_add_activation_checkpoint_args
(
parser
)
# Custom arguments.
if
extra_args_provider
is
not
None
:
parser
=
extra_args_provider
(
parser
)
# Include DeepSpeed configuration arguments
parser
=
deepspeed
.
add_config_arguments
(
parser
)
# Parse.
if
ignore_unknown_args
:
args
,
_
=
parser
.
parse_known_args
()
else
:
args
=
parser
.
parse_args
()
# Distributed args.
args
.
rank
=
int
(
os
.
getenv
(
'RANK'
,
'0'
))
args
.
world_size
=
int
(
os
.
getenv
(
"WORLD_SIZE"
,
'1'
))
args
.
model_parallel_size
=
min
(
args
.
model_parallel_size
,
args
.
world_size
)
if
args
.
rank
==
0
:
print
(
'using world size: {} and model-parallel size: {} '
.
format
(
args
.
world_size
,
args
.
model_parallel_size
))
# Fp16 loss scaling.
args
.
dynamic_loss_scale
=
False
if
args
.
loss_scale
is
None
:
args
.
dynamic_loss_scale
=
True
# Parameters dtype.
args
.
params_dtype
=
torch
.
float
if
args
.
fp16
:
args
.
params_dtype
=
torch
.
half
if
args
.
rank
==
0
:
print
(
'using {} for parameters ...'
.
format
(
args
.
params_dtype
),
flush
=
True
)
# Set input defaults.
for
key
in
defaults
:
# For default to be valid, it should not be provided in the
# arguments that are passed to the program. We check this by
# ensuring the arg is set to None.
if
getattr
(
args
,
key
)
is
not
None
:
if
args
.
rank
==
0
:
print
(
'WARNING: overriding default arguments for {key}:{v}
\
with {key}:{v2}'
.
format
(
key
=
key
,
v
=
defaults
[
key
],
v2
=
getattr
(
args
,
key
)),
flush
=
True
)
else
:
setattr
(
args
,
key
,
defaults
[
key
])
# Check required arguments.
required_args
=
[
'num_layers'
,
'hidden_size'
,
'num_attention_heads'
,
'max_position_embeddings'
]
for
req_arg
in
required_args
:
_check_arg_is_not_none
(
args
,
req_arg
)
# Checks.
assert
args
.
hidden_size
%
args
.
num_attention_heads
==
0
if
args
.
seq_length
is
not
None
:
assert
args
.
max_position_embeddings
>=
args
.
seq_length
if
args
.
lr
is
not
None
:
assert
args
.
min_lr
<=
args
.
lr
if
args
.
save
is
not
None
:
assert
args
.
save_interval
is
not
None
# Parameters sharing does not work with torch DDP.
if
(
args
.
num_unique_layers
is
not
None
)
and
(
args
.
num_layers
is
not
None
):
assert
args
.
num_unique_layers
<=
args
.
num_layers
assert
args
.
num_layers
%
args
.
num_unique_layers
==
0
,
\
'num-layers should be divisible by num-unique-layers.'
if
args
.
num_unique_layers
<
args
.
num_layers
:
assert
args
.
DDP_impl
==
'local'
,
\
'torch-DDP does not work with parameters sharing.'
# Mixed precision checks.
if
args
.
fp16_lm_cross_entropy
:
assert
args
.
fp16
,
'lm cross entropy in fp16 only support in fp16 mode.'
# Activation checkpointing.
if
args
.
distribute_checkpointed_activations
:
assert
args
.
checkpoint_activations
,
\
'for distribute-checkpointed-activations to work you '
\
'need to enable checkpoint-activations'
# load scaled_upper_triang_masked_softmax_fusion kernel
if
args
.
scaled_upper_triang_masked_softmax_fusion
:
fused_kernels
.
load_scaled_upper_triang_masked_softmax_fusion_kernel
()
# load scaled_masked_softmax_fusion kernel
if
args
.
scaled_masked_softmax_fusion
:
fused_kernels
.
load_scaled_masked_softmax_fusion_kernel
()
_print_args
(
args
)
return
args
def
_print_args
(
args
):
"""Print arguments."""
if
args
.
rank
==
0
:
print
(
'-------------------- arguments --------------------'
,
flush
=
True
)
str_list
=
[]
for
arg
in
vars
(
args
):
dots
=
'.'
*
(
32
-
len
(
arg
))
str_list
.
append
(
' {} {} {}'
.
format
(
arg
,
dots
,
getattr
(
args
,
arg
)))
for
arg
in
sorted
(
str_list
,
key
=
lambda
x
:
x
.
lower
()):
print
(
arg
,
flush
=
True
)
print
(
'---------------- end of arguments ----------------'
,
flush
=
True
)
def
_check_arg_is_not_none
(
args
,
arg
):
assert
getattr
(
args
,
arg
)
is
not
None
,
'{} argument is None'
.
format
(
arg
)
def
_add_network_size_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'network size'
)
group
.
add_argument
(
'--num-layers'
,
type
=
int
,
default
=
None
,
help
=
'Number of transformer layers.'
)
group
.
add_argument
(
'--num-unique-layers'
,
type
=
int
,
default
=
None
,
help
=
'Number of unique transformer layers. '
'`num-layers` should be divisible by this value.'
)
group
.
add_argument
(
'--param-sharing-style'
,
default
=
'grouped'
,
choices
=
[
'grouped'
,
'spaced'
],
help
=
'Ordering of the shared parameters. For example, '
'for a `num-layers`=4 and `--num-unique-layers`=2, '
'we will have the following ordering for two unique '
'layers 1 and 2: '
' grouped: [1, 2, 1, 2] and spaced: [1, 1, 2, 2].'
)
group
.
add_argument
(
'--hidden-size'
,
type
=
int
,
default
=
None
,
help
=
'Tansformer hidden size.'
)
group
.
add_argument
(
'--num-attention-heads'
,
type
=
int
,
default
=
None
,
help
=
'Number of transformer attention heads.'
)
group
.
add_argument
(
'--max-position-embeddings'
,
type
=
int
,
default
=
None
,
help
=
'Maximum number of position embeddings to use. '
'This is the size of position embedding.'
)
group
.
add_argument
(
'--make-vocab-size-divisible-by'
,
type
=
int
,
default
=
128
,
help
=
'Pad the vocab size to be divisible by this value.'
'This is added for computational efficieny reasons.'
)
group
.
add_argument
(
'--layernorm-epsilon'
,
type
=
float
,
default
=
1e-5
,
help
=
'Layer norm epsilon.'
)
group
.
add_argument
(
'--apply-residual-connection-post-layernorm'
,
action
=
'store_true'
,
help
=
'If set, use original BERT residula connection '
'ordering.'
)
group
.
add_argument
(
'--openai-gelu'
,
action
=
'store_true'
,
help
=
'Use OpenAIs GeLU implementation. This option'
'should not be used unless for backward compatibility'
'reasons.'
)
group
.
add_argument
(
'--onnx-safe'
,
type
=
bool
,
required
=
False
,
help
=
'Use workarounds for known problems with Torch ONNX exporter'
)
return
parser
def
_add_regularization_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'regularization'
)
group
.
add_argument
(
'--attention-dropout'
,
type
=
float
,
default
=
0.1
,
help
=
'Post attention dropout ptobability.'
)
group
.
add_argument
(
'--hidden-dropout'
,
type
=
float
,
default
=
0.1
,
help
=
'Dropout probability for hidden state transformer.'
)
group
.
add_argument
(
'--weight-decay'
,
type
=
float
,
default
=
0.01
,
help
=
'Weight decay coefficient for L2 regularization.'
)
group
.
add_argument
(
'--clip-grad'
,
type
=
float
,
default
=
1.0
,
help
=
'Gradient clipping based on global L2 norm.'
)
group
.
add_argument
(
'--adam-beta1'
,
type
=
float
,
default
=
0.9
,
help
=
'First coefficient for computing running averages of'
'gradient and its square'
)
group
.
add_argument
(
'--adam-beta2'
,
type
=
float
,
default
=
0.999
,
help
=
'Second coefficient for computing running averages of'
'gradient and its square'
)
group
.
add_argument
(
'--adam-eps'
,
type
=
float
,
default
=
1e-08
,
help
=
'Term added to the denominator to improve'
'numerical stability'
)
return
parser
def
_add_training_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'training'
)
group
.
add_argument
(
'--batch-size'
,
type
=
int
,
default
=
None
,
help
=
'Batch size per model instance (local batch size). '
'Global batch size is local batch size times data '
'parallel size.'
)
group
.
add_argument
(
'--gas'
,
type
=
int
,
default
=
1
,
help
=
'Gradient accumulation steps (pipeline parallelism only). '
'Global batch size is local batch size times data '
'parallel size times gas.'
)
group
.
add_argument
(
'--checkpoint-activations'
,
action
=
'store_true'
,
help
=
'Checkpoint activation to allow for training '
'with larger models, sequences, and batch sizes.'
)
group
.
add_argument
(
'--distribute-checkpointed-activations'
,
action
=
'store_true'
,
help
=
'If set, distribute checkpointed activations '
'across model parallel group.'
)
group
.
add_argument
(
'--checkpoint-num-layers'
,
type
=
int
,
default
=
1
,
help
=
'chunk size (number of layers) for checkpointing.'
)
group
.
add_argument
(
'--train-iters'
,
type
=
int
,
default
=
None
,
help
=
'Total number of iterations to train over all '
'training runs.'
)
group
.
add_argument
(
'--log-interval'
,
type
=
int
,
default
=
100
,
help
=
'Report loss and timing interval.'
)
group
.
add_argument
(
'--exit-interval'
,
type
=
int
,
default
=
None
,
help
=
'Exit the program after the iteration is divisible '
'by this value.'
)
group
.
add_argument
(
'--tensorboard-dir'
,
type
=
str
,
default
=
None
,
help
=
'Write TensorBoard logs to this directory.'
)
group
.
add_argument
(
'--scaled-upper-triang-masked-softmax-fusion'
,
action
=
'store_true'
,
help
=
'Enable fusion of query_key_value_scaling '
'time (upper diagonal) masking and softmax.'
)
group
.
add_argument
(
'--scaled-masked-softmax-fusion'
,
action
=
'store_true'
,
help
=
'Enable fusion of query_key_value_scaling '
'general masking and softmax.'
)
group
.
add_argument
(
'--bias-gelu-fusion'
,
action
=
'store_true'
,
help
=
'Enable bias and gelu fusion.'
)
group
.
add_argument
(
'--bias-dropout-fusion'
,
action
=
'store_true'
,
help
=
'Enable bias and dropout fusion.'
)
group
.
add_argument
(
'--cpu-optimizer'
,
action
=
'store_true'
,
help
=
'Run optimizer on CPU'
)
group
.
add_argument
(
'--cpu_torch_adam'
,
action
=
'store_true'
,
help
=
'Use Torch Adam as optimizer on CPU.'
)
return
parser
def
_add_initialization_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'initialization'
)
group
.
add_argument
(
'--seed'
,
type
=
int
,
default
=
1234
,
help
=
'Random seed used for python, numpy, '
'pytorch, and cuda.'
)
group
.
add_argument
(
'--init-method-std'
,
type
=
float
,
default
=
0.02
,
help
=
'Standard deviation of the zero mean normal '
'distribution used for weight initialization.'
)
return
parser
def
_add_learning_rate_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'learning rate'
)
group
.
add_argument
(
'--lr'
,
type
=
float
,
default
=
None
,
help
=
'Initial learning rate. Depending on decay style '
'and initial warmup, the learing rate at each '
'iteration would be different.'
)
group
.
add_argument
(
'--lr-decay-style'
,
type
=
str
,
default
=
'linear'
,
choices
=
[
'constant'
,
'linear'
,
'cosine'
,
'exponential'
],
help
=
'Learning rate decay function.'
)
group
.
add_argument
(
'--lr-decay-iters'
,
type
=
int
,
default
=
None
,
help
=
'number of iterations to decay learning rate over,'
' If None defaults to `--train-iters`'
)
group
.
add_argument
(
'--min-lr'
,
type
=
float
,
default
=
0.0
,
help
=
'Minumum value for learning rate. The scheduler'
'clip values below this threshold.'
)
group
.
add_argument
(
'--warmup'
,
type
=
float
,
default
=
0.01
,
help
=
'Percentage of total iterations to warmup on '
'(.01 = 1 percent of all training iters).'
)
group
.
add_argument
(
'--override-lr-scheduler'
,
action
=
'store_true'
,
help
=
'Reset the values of the scheduler (learning rate,'
'warmup iterations, minimum learning rate, maximum '
'number of iterations, and decay style from input '
'arguments and ignore values from checkpoints. Note'
'that all the above values will be reset.'
)
group
.
add_argument
(
'--use-checkpoint-lr-scheduler'
,
action
=
'store_true'
,
help
=
'Use checkpoint to set the values of the scheduler '
'(learning rate, warmup iterations, minimum learning '
'rate, maximum number of iterations, and decay style '
'from checkpoint and ignore input arguments.'
)
return
parser
def
_add_checkpointing_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'checkpointing'
)
group
.
add_argument
(
'--save'
,
type
=
str
,
default
=
None
,
help
=
'Output directory to save checkpoints to.'
)
group
.
add_argument
(
'--save-interval'
,
type
=
int
,
default
=
None
,
help
=
'Number of iterations between checkpoint saves.'
)
group
.
add_argument
(
'--no-save-optim'
,
action
=
'store_true'
,
help
=
'Do not save current optimizer.'
)
group
.
add_argument
(
'--no-save-rng'
,
action
=
'store_true'
,
help
=
'Do not save current rng state.'
)
group
.
add_argument
(
'--load'
,
type
=
str
,
default
=
None
,
help
=
'Directory containing a model checkpoint.'
)
group
.
add_argument
(
'--no-load-optim'
,
action
=
'store_true'
,
help
=
'Do not load optimizer when loading checkpoint.'
)
group
.
add_argument
(
'--no-load-rng'
,
action
=
'store_true'
,
help
=
'Do not load rng state when loading checkpoint.'
)
group
.
add_argument
(
'--finetune'
,
action
=
'store_true'
,
help
=
'Load model for finetuning. Do not load optimizer '
'or rng state from checkpoint and set iteration to 0. '
'Assumed when loading a release checkpoint.'
)
return
parser
def
_add_mixed_precision_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'mixed precision'
)
group
.
add_argument
(
'--fp16'
,
action
=
'store_true'
,
help
=
'Run model in fp16 mode.'
)
group
.
add_argument
(
'--apply-query-key-layer-scaling'
,
action
=
'store_true'
,
help
=
'Scale Q * K^T by 1 / layer-number. If this flag '
'is set, then it will automatically set '
'attention-softmax-in-fp32 to true'
)
group
.
add_argument
(
'--attention-softmax-in-fp32'
,
action
=
'store_true'
,
help
=
'Run attention masking and softmax in fp32.'
)
group
.
add_argument
(
'--fp32-allreduce'
,
action
=
'store_true'
,
help
=
'All-reduce in fp32'
)
group
.
add_argument
(
'--hysteresis'
,
type
=
int
,
default
=
2
,
help
=
'hysteresis for dynamic loss scaling'
)
group
.
add_argument
(
'--loss-scale'
,
type
=
float
,
default
=
None
,
help
=
'Static loss scaling, positive power of 2 '
'values can improve fp16 convergence. If None, dynamic'
'loss scaling is used.'
)
group
.
add_argument
(
'--loss-scale-window'
,
type
=
float
,
default
=
1000
,
help
=
'Window over which to raise/lower dynamic scale.'
)
group
.
add_argument
(
'--min-scale'
,
type
=
float
,
default
=
1
,
help
=
'Minimum loss scale for dynamic loss scale.'
)
group
.
add_argument
(
'--fp16-lm-cross-entropy'
,
action
=
'store_true'
,
help
=
'Move the cross entropy unreduced loss calculation'
'for lm head to fp16.'
)
return
parser
def
_add_distributed_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'mixed precision'
)
group
.
add_argument
(
'--model-parallel-size'
,
type
=
int
,
default
=
1
,
help
=
'Size of the model parallel.'
)
group
.
add_argument
(
'--pipe-parallel-size'
,
type
=
int
,
default
=
0
,
help
=
'Size of the pipeline parallel. Disable with 0.'
)
group
.
add_argument
(
'--distributed-backend'
,
default
=
'nccl'
,
choices
=
[
'nccl'
,
'gloo'
],
help
=
'Which backend to use for distributed training.'
)
group
.
add_argument
(
'--DDP-impl'
,
default
=
'local'
,
choices
=
[
'local'
,
'torch'
],
help
=
'which DistributedDataParallel implementation '
'to use.'
)
group
.
add_argument
(
'--local_rank'
,
type
=
int
,
default
=
None
,
help
=
'local rank passed from distributed launcher.'
)
group
.
add_argument
(
'--lazy-mpu-init'
,
type
=
bool
,
required
=
False
,
help
=
'If set to True, initialize_megatron() skips DDP initialization'
' and returns function to complete it instead.'
'Also turns on --use-cpu-initialization flag.'
'This is for external DDP manager.'
)
group
.
add_argument
(
'--use-cpu-initialization'
,
action
=
'store_true'
,
help
=
'If set, affine parallel weights initialization uses CPU'
)
return
parser
def
_add_validation_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'validation'
)
group
.
add_argument
(
'--eval-iters'
,
type
=
int
,
default
=
100
,
help
=
'Number of iterations to run for evaluation'
'validation/test for.'
)
group
.
add_argument
(
'--eval-interval'
,
type
=
int
,
default
=
1000
,
help
=
'Interval between running evaluation on '
'validation set.'
)
return
parser
def
_add_data_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'data and dataloader'
)
group
.
add_argument
(
'--data-path'
,
type
=
str
,
default
=
None
,
help
=
'Path to combined dataset to split.'
)
group
.
add_argument
(
'--split'
,
type
=
str
,
default
=
'969, 30, 1'
,
help
=
'Comma-separated list of proportions for training,'
' validation, and test split. For example the split '
'`90,5,5` will use 90% of data for training, 5% for '
'validation and 5% for test.'
)
group
.
add_argument
(
'--vocab-file'
,
type
=
str
,
default
=
None
,
help
=
'Path to the vocab file.'
)
group
.
add_argument
(
'--merge-file'
,
type
=
str
,
default
=
None
,
help
=
'Path to the BPE merge file.'
)
group
.
add_argument
(
'--seq-length'
,
type
=
int
,
default
=
None
,
help
=
"Maximum sequence length to process."
)
group
.
add_argument
(
'--mask-prob'
,
type
=
float
,
default
=
0.15
,
help
=
'Probability of replacing a token with mask.'
)
group
.
add_argument
(
'--short-seq-prob'
,
type
=
float
,
default
=
0.1
,
help
=
'Probability of producing a short sequence.'
)
group
.
add_argument
(
'--mmap-warmup'
,
action
=
'store_true'
,
help
=
'Warm up mmap files.'
)
group
.
add_argument
(
'--num-workers'
,
type
=
int
,
default
=
2
,
help
=
"Dataloader number of workers."
)
group
.
add_argument
(
'--tokenizer-type'
,
type
=
str
,
default
=
None
,
choices
=
[
'BertWordPieceLowerCase'
,
'BertWordPieceCase'
,
'GPT2BPETokenizer'
],
help
=
'What type of tokenizer to use.'
)
group
.
add_argument
(
'--data-impl'
,
type
=
str
,
default
=
'infer'
,
choices
=
[
'lazy'
,
'cached'
,
'mmap'
,
'infer'
],
help
=
'Implementation of indexed datasets.'
)
group
.
add_argument
(
'--reset-position-ids'
,
action
=
'store_true'
,
help
=
'Reset posistion ids after end-of-document token.'
)
group
.
add_argument
(
'--reset-attention-mask'
,
action
=
'store_true'
,
help
=
'Reset self attention maske after '
'end-of-document token.'
)
group
.
add_argument
(
'--eod-mask-loss'
,
action
=
'store_true'
,
help
=
'Mask loss for the end of document tokens.'
)
return
parser
def
_add_autoresume_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'autoresume'
)
group
.
add_argument
(
'--adlr-autoresume'
,
action
=
'store_true'
,
help
=
'Enable autoresume on adlr cluster.'
)
group
.
add_argument
(
'--adlr-autoresume-interval'
,
type
=
int
,
default
=
1000
,
help
=
'Intervals over which check for autoresume'
'termination signal'
)
return
parser
def
_add_realm_args
(
parser
):
group
=
parser
.
add_argument_group
(
title
=
'realm'
)
# network size
group
.
add_argument
(
'--ict-head-size'
,
type
=
int
,
default
=
None
,
help
=
'Size of block embeddings to be used in ICT and REALM (paper default: 128)'
)
# checkpointing
group
.
add_argument
(
'--ict-load'
,
type
=
str
,
default
=
None
,
help
=
'Directory containing an ICTBertModel checkpoint'
)
group
.
add_argument
(
'--bert-load'
,
type
=
str
,
default
=
None
,
help
=
'Directory containing an BertModel checkpoint (needed to start ICT and REALM)'
)
# data
group
.
add_argument
(
'--titles-data-path'
,
type
=
str
,
default
=
None
,
help
=
'Path to titles dataset used for ICT'
)
group
.
add_argument
(
'--query-in-block-prob'
,
type
=
float
,
default
=
0.1
,
help
=
'Probability of keeping query in block for ICT dataset'
)
group
.
add_argument
(
'--use-one-sent-docs'
,
action
=
'store_true'
,
help
=
'Whether to use one sentence documents in ICT'
)
# training
group
.
add_argument
(
'--report-topk-accuracies'
,
nargs
=
'+'
,
default
=
[],
help
=
"Which top-k accuracies to report (e.g. '1 5 20')"
)
# faiss index
group
.
add_argument
(
'--faiss-use-gpu'
,
action
=
'store_true'
,
help
=
'Whether create the FaissMIPSIndex on GPU'
)
group
.
add_argument
(
'--block-data-path'
,
type
=
str
,
default
=
None
,
help
=
'Where to save/load BlockData to/from'
)
# indexer
group
.
add_argument
(
'--indexer-batch-size'
,
type
=
int
,
default
=
128
,
help
=
'How large of batches to use when doing indexing jobs'
)
group
.
add_argument
(
'--indexer-log-interval'
,
type
=
int
,
default
=
1000
,
help
=
'After how many batches should the indexer report progress'
)
return
parser
def
_add_zero_args
(
parser
):
"""Text generate arguments."""
group
=
parser
.
add_argument_group
(
'Text generation'
,
'configurations'
)
group
.
add_argument
(
"--zero-stage"
,
type
=
int
,
default
=
1.0
)
group
.
add_argument
(
'--zero-reduce-scatter'
,
action
=
'store_true'
,
help
=
'Use reduce scatter if specified'
)
group
.
add_argument
(
'--zero-contigious-gradients'
,
action
=
'store_true'
,
help
=
'Use contigious memory optimizaiton if specified'
)
group
.
add_argument
(
"--zero-reduce-bucket-size"
,
type
=
int
,
default
=
0.0
)
group
.
add_argument
(
"--zero-allgather-bucket-size"
,
type
=
int
,
default
=
0.0
)
return
parser
def
_add_activation_checkpoint_args
(
parser
):
group
=
parser
.
add_argument_group
(
'Activation Checkpointing'
,
'Checkpointing Configurations'
)
group
.
add_argument
(
'--deepspeed-activation-checkpointing'
,
action
=
'store_true'
,
help
=
'uses activation checkpointing from deepspeed'
)
group
.
add_argument
(
'--partition-activations'
,
action
=
'store_true'
,
help
=
'partition Activations across GPUs before checkpointing.'
)
group
.
add_argument
(
'--contigious-checkpointing'
,
action
=
'store_true'
,
help
=
'Contigious memory checkpointing for activatoins.'
)
group
.
add_argument
(
'--checkpoint-in-cpu'
,
action
=
'store_true'
,
help
=
'Move the activation checkpoints to CPU.'
)
group
.
add_argument
(
'--synchronize-each-layer'
,
action
=
'store_true'
,
help
=
'does a synchronize at the beginning and end of each checkpointed layer.'
)
group
.
add_argument
(
'--profile-backward'
,
action
=
'store_true'
,
help
=
'Enables backward pass profiling for checkpointed layers.'
)
return
parser
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/checkpointing.py
0 → 100644
View file @
316d3f90
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Input/output checkpointing."""
import
os
import
random
import
sys
import
numpy
as
np
import
torch
from
torch.nn.parallel
import
DistributedDataParallel
as
torchDDP
from
megatron
import
mpu
,
get_args
from
megatron
import
get_args
from
megatron
import
print_rank_0
_CHECKPOINT_VERSION
=
None
def
set_checkpoint_version
(
value
):
global
_CHECKPOINT_VERSION
assert
_CHECKPOINT_VERSION
is
None
,
\
"checkpoint version already set"
_CHECKPOINT_VERSION
=
value
def
get_checkpoint_version
():
global
_CHECKPOINT_VERSION
return
_CHECKPOINT_VERSION
def
check_checkpoint_args
(
checkpoint_args
):
"""Ensure fixed arguments for a model are the same for the input
arguments and the one retreived frm checkpoint."""
args
=
get_args
()
def
_compare
(
arg_name
):
checkpoint_value
=
getattr
(
checkpoint_args
,
arg_name
)
args_value
=
getattr
(
args
,
arg_name
)
error_message
=
'{} value from checkpoint ({}) is not equal to the '
\
'input argument value ({}).'
.
format
(
arg_name
,
checkpoint_value
,
args_value
)
assert
checkpoint_value
==
args_value
,
error_message
_compare
(
'num_layers'
)
_compare
(
'hidden_size'
)
_compare
(
'num_attention_heads'
)
_compare
(
'max_position_embeddings'
)
_compare
(
'make_vocab_size_divisible_by'
)
_compare
(
'padded_vocab_size'
)
_compare
(
'tokenizer_type'
)
_compare
(
'model_parallel_size'
)
def
ensure_directory_exists
(
filename
):
"""Build filename's path if it does not already exists."""
dirname
=
os
.
path
.
dirname
(
filename
)
if
not
os
.
path
.
exists
(
dirname
):
os
.
makedirs
(
dirname
)
def
get_checkpoint_name
(
checkpoints_path
,
iteration
,
release
=
False
,
mp_rank
=
None
):
"""A unified checkpoint name."""
if
release
:
directory
=
'release'
else
:
directory
=
'iter_{:07d}'
.
format
(
iteration
)
return
os
.
path
.
join
(
checkpoints_path
,
directory
,
'mp_rank_{:02d}'
.
format
(
mpu
.
get_model_parallel_rank
()
if
mp_rank
is
None
else
mp_rank
),
'model_optim_rng.pt'
)
def
get_checkpoint_tracker_filename
(
checkpoints_path
):
"""Tracker file rescords the latest chckpoint during
training to restart from."""
return
os
.
path
.
join
(
checkpoints_path
,
'latest_checkpointed_iteration.txt'
)
def
save_ds_checkpoint
(
iteration
,
model
,
args
):
"""Save a model checkpoint."""
sd
=
{}
sd
[
'iteration'
]
=
iteration
# rng states.
if
not
args
.
no_save_rng
:
sd
[
'random_rng_state'
]
=
random
.
getstate
()
sd
[
'np_rng_state'
]
=
np
.
random
.
get_state
()
sd
[
'torch_rng_state'
]
=
torch
.
get_rng_state
()
sd
[
'cuda_rng_state'
]
=
torch
.
cuda
.
get_rng_state
()
sd
[
'rng_tracker_states'
]
=
mpu
.
get_cuda_rng_tracker
().
get_states
()
if
args
.
pipe_parallel_size
==
0
:
#megatron model uses state_dict_for_save_checkpointing instead of the standard state_dict
#state_dict is used by deepspeed for module saving so it needs to point to the right function
model
.
module
.
state_dict
=
model
.
module
.
state_dict_for_save_checkpoint
else
:
# Pipeline parallelism manages its own state_dict.
pass
model
.
save_checkpoint
(
args
.
save
,
client_state
=
sd
)
def
save_checkpoint
(
iteration
,
model
,
optimizer
,
lr_scheduler
):
"""Save a model checkpoint."""
args
=
get_args
()
if
args
.
deepspeed
:
save_ds_checkpoint
(
iteration
,
model
,
args
)
else
:
# Only rank zero of the data parallel writes to the disk.
if
isinstance
(
model
,
torchDDP
):
model
=
model
.
module
if
mpu
.
get_data_parallel_rank
()
==
0
:
# Arguments, iteration, and model.
state_dict
=
{}
state_dict
[
'args'
]
=
args
state_dict
[
'checkpoint_version'
]
=
2.0
state_dict
[
'iteration'
]
=
iteration
state_dict
[
'model'
]
=
model
.
state_dict_for_save_checkpoint
()
# Optimizer stuff.
if
not
args
.
no_save_optim
:
if
optimizer
is
not
None
:
state_dict
[
'optimizer'
]
=
optimizer
.
state_dict
()
if
lr_scheduler
is
not
None
:
state_dict
[
'lr_scheduler'
]
=
lr_scheduler
.
state_dict
()
# RNG states.
if
not
args
.
no_save_rng
:
state_dict
[
'random_rng_state'
]
=
random
.
getstate
()
state_dict
[
'np_rng_state'
]
=
np
.
random
.
get_state
()
state_dict
[
'torch_rng_state'
]
=
torch
.
get_rng_state
()
state_dict
[
'cuda_rng_state'
]
=
torch
.
cuda
.
get_rng_state
()
state_dict
[
'rng_tracker_states'
]
\
=
mpu
.
get_cuda_rng_tracker
().
get_states
()
# Save.
checkpoint_name
=
get_checkpoint_name
(
args
.
save
,
iteration
)
print
(
'global rank {} is saving checkpoint at iteration {:7d} to {}'
.
format
(
torch
.
distributed
.
get_rank
(),
iteration
,
checkpoint_name
))
ensure_directory_exists
(
checkpoint_name
)
torch
.
save
(
state_dict
,
checkpoint_name
)
print
(
' successfully saved {}'
.
format
(
checkpoint_name
))
# Wait so everyone is done (necessary)
torch
.
distributed
.
barrier
()
# And update the latest iteration
if
torch
.
distributed
.
get_rank
()
==
0
:
tracker_filename
=
get_checkpoint_tracker_filename
(
args
.
save
)
with
open
(
tracker_filename
,
'w'
)
as
f
:
f
.
write
(
str
(
iteration
))
# Wait so everyone is done (not necessary)
torch
.
distributed
.
barrier
()
def
load_checkpoint
(
model
,
optimizer
,
lr_scheduler
,
load_arg
=
'load'
):
"""Load a model checkpoint and return the iteration."""
args
=
get_args
()
load_dir
=
getattr
(
args
,
load_arg
)
if
isinstance
(
model
,
torchDDP
):
model
=
model
.
module
# Read the tracker file and set the iteration.
tracker_filename
=
get_checkpoint_tracker_filename
(
load_dir
)
# If no tracker file, return iretation zero.
if
not
os
.
path
.
isfile
(
tracker_filename
):
print_rank_0
(
'WARNING: could not find the metadata file {} '
.
format
(
tracker_filename
))
print_rank_0
(
' will not load any checkpoints and will start from '
'random'
)
return
0
# Otherwise, read the tracker file and either set the iteration or
# mark it as a release checkpoint.
iteration
=
0
release
=
False
with
open
(
tracker_filename
,
'r'
)
as
f
:
metastring
=
f
.
read
().
strip
()
try
:
iteration
=
int
(
metastring
)
except
ValueError
:
release
=
metastring
==
'release'
if
not
release
:
print_rank_0
(
'ERROR: Invalid metadata file {}. Exiting'
.
format
(
tracker_filename
))
sys
.
exit
()
assert
iteration
>
0
or
release
,
'error parsing metadata file {}'
.
format
(
tracker_filename
)
if
args
.
deepspeed
:
checkpoint_name
,
state_dict
=
model
.
load_checkpoint
(
load_dir
)
if
checkpoint_name
is
None
:
if
mpu
.
get_data_parallel_rank
()
==
0
:
print
(
"Unable to load checkpoint."
)
return
iteration
else
:
# Checkpoint.
checkpoint_name
=
get_checkpoint_name
(
load_dir
,
iteration
,
release
)
if
mpu
.
get_data_parallel_rank
()
==
0
:
print
(
'global rank {} is loading checkpoint {}'
.
format
(
torch
.
distributed
.
get_rank
(),
checkpoint_name
))
# Load the checkpoint.
try
:
state_dict
=
torch
.
load
(
checkpoint_name
,
map_location
=
'cpu'
)
except
ModuleNotFoundError
:
# For backward compatibility.
print_rank_0
(
' > deserializing using the old code structure ...'
)
sys
.
modules
[
'fp16.loss_scaler'
]
=
sys
.
modules
[
'megatron.fp16.loss_scaler'
]
state_dict
=
torch
.
load
(
checkpoint_name
,
map_location
=
'cpu'
)
sys
.
modules
.
pop
(
'fp16.loss_scaler'
,
None
)
except
BaseException
:
print_rank_0
(
'could not load the checkpoint'
)
sys
.
exit
()
# Model.
model
.
load_state_dict
(
state_dict
[
'model'
])
# Optimizer.
if
not
release
and
not
args
.
finetune
and
not
args
.
no_load_optim
:
try
:
if
optimizer
is
not
None
:
optimizer
.
load_state_dict
(
state_dict
[
'optimizer'
])
if
lr_scheduler
is
not
None
:
lr_scheduler
.
load_state_dict
(
state_dict
[
'lr_scheduler'
])
except
KeyError
:
print_rank_0
(
'Unable to load optimizer from checkpoint {}. '
'Specify --no-load-optim or --finetune to prevent '
'attempting to load the optimizer state, '
'exiting ...'
.
format
(
checkpoint_name
))
sys
.
exit
()
# set checkpoint version
set_checkpoint_version
(
state_dict
.
get
(
'checkpoint_version'
,
0
))
# Set iteration.
if
args
.
finetune
or
release
:
iteration
=
0
else
:
try
:
iteration
=
state_dict
[
'iteration'
]
except
KeyError
:
try
:
# Backward compatible with older checkpoints
iteration
=
state_dict
[
'total_iters'
]
except
KeyError
:
print_rank_0
(
'A metadata file exists but unable to load '
'iteration from checkpoint {}, exiting'
.
format
(
checkpoint_name
))
sys
.
exit
()
# Check arguments.
if
'args'
in
state_dict
:
checkpoint_args
=
state_dict
[
'args'
]
check_checkpoint_args
(
checkpoint_args
)
else
:
print_rank_0
(
'could not find arguments in the checkpoint ...'
)
# rng states.
if
not
release
and
not
args
.
finetune
and
not
args
.
no_load_rng
:
try
:
random
.
setstate
(
state_dict
[
'random_rng_state'
])
np
.
random
.
set_state
(
state_dict
[
'np_rng_state'
])
torch
.
set_rng_state
(
state_dict
[
'torch_rng_state'
])
torch
.
cuda
.
set_rng_state
(
state_dict
[
'cuda_rng_state'
])
mpu
.
get_cuda_rng_tracker
().
set_states
(
state_dict
[
'rng_tracker_states'
])
except
KeyError
:
print_rank_0
(
'Unable to load optimizer from checkpoint {}. '
'Specify --no-load-rng or --finetune to prevent '
'attempting to load the optimizer state, '
'exiting ...'
.
format
(
checkpoint_name
))
sys
.
exit
()
torch
.
distributed
.
barrier
()
if
mpu
.
get_data_parallel_rank
()
==
0
:
print
(
' successfully loaded {}'
.
format
(
checkpoint_name
))
return
iteration
def
load_ict_checkpoint
(
model
,
only_query_model
=
False
,
only_block_model
=
False
,
from_realm_chkpt
=
False
):
"""selectively load ICT models for indexing/retrieving from ICT or REALM checkpoints"""
args
=
get_args
()
if
isinstance
(
model
,
torchDDP
):
model
=
model
.
module
load_path
=
args
.
load
if
from_realm_chkpt
else
args
.
ict_load
tracker_filename
=
get_checkpoint_tracker_filename
(
load_path
)
with
open
(
tracker_filename
,
'r'
)
as
f
:
iteration
=
int
(
f
.
read
().
strip
())
# assert iteration > 0
checkpoint_name
=
get_checkpoint_name
(
load_path
,
iteration
,
False
)
if
mpu
.
get_data_parallel_rank
()
==
0
:
print
(
'global rank {} is loading checkpoint {}'
.
format
(
torch
.
distributed
.
get_rank
(),
checkpoint_name
))
state_dict
=
torch
.
load
(
checkpoint_name
,
map_location
=
'cpu'
)
ict_state_dict
=
state_dict
[
'model'
]
if
from_realm_chkpt
and
mpu
.
get_data_parallel_rank
()
==
0
:
print
(
" loading ICT state dict from REALM"
,
flush
=
True
)
ict_state_dict
=
ict_state_dict
[
'retriever'
][
'ict_model'
]
if
only_query_model
:
ict_state_dict
.
pop
(
'context_model'
)
if
only_block_model
:
ict_state_dict
.
pop
(
'question_model'
)
model
.
load_state_dict
(
ict_state_dict
)
torch
.
distributed
.
barrier
()
if
mpu
.
get_data_parallel_rank
()
==
0
:
print
(
' successfully loaded {}'
.
format
(
checkpoint_name
))
return
model
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/Makefile
0 → 100644
View file @
316d3f90
CXXFLAGS
+=
-O3
-Wall
-shared
-std
=
c++11
-fPIC
-fdiagnostics-color
CPPFLAGS
+=
$(
shell
python3
-m
pybind11
--includes
)
LIBNAME
=
helpers
LIBEXT
=
$(
shell
python3-config
--extension-suffix
)
default
:
$(LIBNAME)$(LIBEXT)
%$(LIBEXT)
:
%.cpp
$(CXX)
$(CXXFLAGS)
$(CPPFLAGS)
$<
-o
$@
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/__init__.py
0 → 100644
View file @
316d3f90
from
.
import
indexed_dataset
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/bert_dataset.py
0 → 100644
View file @
316d3f90
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""BERT Style dataset."""
import
os
import
time
import
numpy
as
np
import
torch
from
torch.utils.data
import
Dataset
from
megatron
import
get_tokenizer
,
get_args
from
megatron
import
print_rank_0
from
megatron
import
mpu
from
megatron.data.dataset_utils
import
get_a_and_b_segments
from
megatron.data.dataset_utils
import
truncate_segments
from
megatron.data.dataset_utils
import
create_tokens_and_tokentypes
from
megatron.data.dataset_utils
import
pad_and_convert_to_numpy
from
megatron.data.dataset_utils
import
create_masked_lm_predictions
class
BertDataset
(
Dataset
):
def
__init__
(
self
,
name
,
indexed_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
masked_lm_prob
,
max_seq_length
,
short_seq_prob
,
seed
):
# Params to store.
self
.
name
=
name
self
.
seed
=
seed
self
.
masked_lm_prob
=
masked_lm_prob
self
.
max_seq_length
=
max_seq_length
# Dataset.
self
.
indexed_dataset
=
indexed_dataset
# Build the samples mapping.
self
.
samples_mapping
=
get_samples_mapping_
(
self
.
indexed_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
self
.
max_seq_length
,
short_seq_prob
,
self
.
seed
,
self
.
name
)
# Vocab stuff.
tokenizer
=
get_tokenizer
()
self
.
vocab_id_list
=
list
(
tokenizer
.
inv_vocab
.
keys
())
self
.
vocab_id_to_token_dict
=
tokenizer
.
inv_vocab
self
.
cls_id
=
tokenizer
.
cls
self
.
sep_id
=
tokenizer
.
sep
self
.
mask_id
=
tokenizer
.
mask
self
.
pad_id
=
tokenizer
.
pad
def
__len__
(
self
):
return
self
.
samples_mapping
.
shape
[
0
]
def
__getitem__
(
self
,
idx
):
start_idx
,
end_idx
,
seq_length
=
self
.
samples_mapping
[
idx
]
sample
=
[
self
.
indexed_dataset
[
i
]
for
i
in
range
(
start_idx
,
end_idx
)]
# Note that this rng state should be numpy and not python since
# python randint is inclusive whereas the numpy one is exclusive.
np_rng
=
np
.
random
.
RandomState
(
seed
=
(
self
.
seed
+
idx
))
return
build_training_sample
(
sample
,
seq_length
,
self
.
max_seq_length
,
# needed for padding
self
.
vocab_id_list
,
self
.
vocab_id_to_token_dict
,
self
.
cls_id
,
self
.
sep_id
,
self
.
mask_id
,
self
.
pad_id
,
self
.
masked_lm_prob
,
np_rng
)
def
get_samples_mapping_
(
indexed_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
max_seq_length
,
short_seq_prob
,
seed
,
name
):
if
not
num_epochs
:
if
not
max_num_samples
:
raise
ValueError
(
"Need to specify either max_num_samples "
"or num_epochs"
)
num_epochs
=
np
.
iinfo
(
np
.
int32
).
max
-
1
if
not
max_num_samples
:
max_num_samples
=
np
.
iinfo
(
np
.
int64
).
max
-
1
# Filename of the index mapping
indexmap_filename
=
data_prefix
indexmap_filename
+=
'_{}_indexmap'
.
format
(
name
)
if
num_epochs
!=
(
np
.
iinfo
(
np
.
int32
).
max
-
1
):
indexmap_filename
+=
'_{}ep'
.
format
(
num_epochs
)
if
max_num_samples
!=
(
np
.
iinfo
(
np
.
int64
).
max
-
1
):
indexmap_filename
+=
'_{}mns'
.
format
(
max_num_samples
)
indexmap_filename
+=
'_{}msl'
.
format
(
max_seq_length
)
indexmap_filename
+=
'_{:0.2f}ssp'
.
format
(
short_seq_prob
)
indexmap_filename
+=
'_{}s'
.
format
(
seed
)
indexmap_filename
+=
'.npy'
# Build the indexed mapping if not exist.
if
torch
.
distributed
.
get_rank
()
==
0
and
\
not
os
.
path
.
isfile
(
indexmap_filename
):
print
(
' > WARNING: could not find index map file {}, building '
'the indices on rank 0 ...'
.
format
(
indexmap_filename
))
# Make sure the types match the helpers input types.
assert
indexed_dataset
.
doc_idx
.
dtype
==
np
.
int64
assert
indexed_dataset
.
sizes
.
dtype
==
np
.
int32
# Build samples mapping
verbose
=
torch
.
distributed
.
get_rank
()
==
0
start_time
=
time
.
time
()
print_rank_0
(
' > building sapmles index mapping for {} ...'
.
format
(
name
))
# First compile and then import.
from
megatron.data.dataset_utils
import
compile_helper
compile_helper
()
from
megatron.data
import
helpers
samples_mapping
=
helpers
.
build_mapping
(
indexed_dataset
.
doc_idx
,
indexed_dataset
.
sizes
,
num_epochs
,
max_num_samples
,
max_seq_length
-
3
,
# account for added tokens
short_seq_prob
,
seed
,
verbose
)
print_rank_0
(
' > done building sapmles index maping'
)
np
.
save
(
indexmap_filename
,
samples_mapping
,
allow_pickle
=
True
)
print_rank_0
(
' > saved the index mapping in {}'
.
format
(
indexmap_filename
))
# Make sure all the ranks have built the mapping
print_rank_0
(
' > elasped time to build and save samples mapping '
'(seconds): {:4f}'
.
format
(
time
.
time
()
-
start_time
))
# This should be a barrier but nccl barrier assumes
# device_index=rank which is not the case for model
# parallel case
counts
=
torch
.
cuda
.
LongTensor
([
1
])
torch
.
distributed
.
all_reduce
(
counts
,
group
=
mpu
.
get_data_parallel_group
())
assert
counts
[
0
].
item
()
==
torch
.
distributed
.
get_world_size
(
group
=
mpu
.
get_data_parallel_group
())
# Load indexed dataset.
print_rank_0
(
' > loading indexed mapping from {}'
.
format
(
indexmap_filename
))
start_time
=
time
.
time
()
samples_mapping
=
np
.
load
(
indexmap_filename
,
allow_pickle
=
True
,
mmap_mode
=
'r'
)
print_rank_0
(
' loaded indexed file in {:3.3f} seconds'
.
format
(
time
.
time
()
-
start_time
))
print_rank_0
(
' total number of samples: {}'
.
format
(
samples_mapping
.
shape
[
0
]))
return
samples_mapping
def
build_training_sample
(
sample
,
target_seq_length
,
max_seq_length
,
vocab_id_list
,
vocab_id_to_token_dict
,
cls_id
,
sep_id
,
mask_id
,
pad_id
,
masked_lm_prob
,
np_rng
):
"""Biuld training sample.
Arguments:
sample: A list of sentences in which each sentence is a list token ids.
target_seq_length: Desired sequence length.
max_seq_length: Maximum length of the sequence. All values are padded to
this length.
vocab_id_list: List of vocabulary ids. Used to pick a random id.
vocab_id_to_token_dict: A dictionary from vocab ids to text tokens.
cls_id: Start of example id.
sep_id: Separator id.
mask_id: Mask token id.
pad_id: Padding token id.
masked_lm_prob: Probability to mask tokens.
np_rng: Random number genenrator. Note that this rng state should be
numpy and not python since python randint is inclusive for
the opper bound whereas the numpy one is exclusive.
"""
# We assume that we have at least two sentences in the sample
assert
len
(
sample
)
>
1
assert
target_seq_length
<=
max_seq_length
# Divide sample into two segments (A and B).
tokens_a
,
tokens_b
,
is_next_random
=
get_a_and_b_segments
(
sample
,
np_rng
)
# Truncate to `target_sequence_length`.
max_num_tokens
=
target_seq_length
truncated
=
truncate_segments
(
tokens_a
,
tokens_b
,
len
(
tokens_a
),
len
(
tokens_b
),
max_num_tokens
,
np_rng
)
# Build tokens and toketypes.
tokens
,
tokentypes
=
create_tokens_and_tokentypes
(
tokens_a
,
tokens_b
,
cls_id
,
sep_id
)
# Masking.
max_predictions_per_seq
=
masked_lm_prob
*
max_num_tokens
(
tokens
,
masked_positions
,
masked_labels
,
_
)
=
create_masked_lm_predictions
(
tokens
,
vocab_id_list
,
vocab_id_to_token_dict
,
masked_lm_prob
,
cls_id
,
sep_id
,
mask_id
,
max_predictions_per_seq
,
np_rng
)
# Padding.
tokens_np
,
tokentypes_np
,
labels_np
,
padding_mask_np
,
loss_mask_np
\
=
pad_and_convert_to_numpy
(
tokens
,
tokentypes
,
masked_positions
,
masked_labels
,
pad_id
,
max_seq_length
)
train_sample
=
{
'text'
:
tokens_np
,
'types'
:
tokentypes_np
,
'labels'
:
labels_np
,
'is_random'
:
int
(
is_next_random
),
'loss_mask'
:
loss_mask_np
,
'padding_mask'
:
padding_mask_np
,
'truncated'
:
int
(
truncated
)}
return
train_sample
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/dataset_utils.py
0 → 100644
View file @
316d3f90
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors, and NVIDIA.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Most of the code here has been copied from:
# https://github.com/google-research/albert/blob/master/create_pretraining_data.py
# with some modifications.
import
time
import
collections
import
numpy
as
np
from
megatron
import
get_args
,
print_rank_0
from
megatron.data.indexed_dataset
import
make_dataset
as
make_indexed_dataset
DSET_TYPE_STD
=
'standard_bert'
DSET_TYPE_ICT
=
'ict'
DSET_TYPES
=
[
DSET_TYPE_ICT
,
DSET_TYPE_STD
]
def
compile_helper
():
"""Compile helper function ar runtime. Make sure this
is invoked on a single process."""
import
os
import
subprocess
path
=
os
.
path
.
abspath
(
os
.
path
.
dirname
(
__file__
))
ret
=
subprocess
.
run
([
'make'
,
'-C'
,
path
])
if
ret
.
returncode
!=
0
:
print
(
"Making C++ dataset helpers module failed, exiting."
)
import
sys
sys
.
exit
(
1
)
def
get_a_and_b_segments
(
sample
,
np_rng
):
"""Divide sample into a and b segments."""
# Number of sentences in the sample.
n_sentences
=
len
(
sample
)
# Make sure we always have two sentences.
assert
n_sentences
>
1
,
'make sure each sample has at least two sentences.'
# First part:
# `a_end` is how many sentences go into the `A`.
a_end
=
1
if
n_sentences
>=
3
:
# Note that randin in numpy is exclusive.
a_end
=
np_rng
.
randint
(
1
,
n_sentences
)
tokens_a
=
[]
for
j
in
range
(
a_end
):
tokens_a
.
extend
(
sample
[
j
])
# Second part:
tokens_b
=
[]
for
j
in
range
(
a_end
,
n_sentences
):
tokens_b
.
extend
(
sample
[
j
])
# Random next:
is_next_random
=
False
if
np_rng
.
random
()
<
0.5
:
is_next_random
=
True
tokens_a
,
tokens_b
=
tokens_b
,
tokens_a
return
tokens_a
,
tokens_b
,
is_next_random
def
truncate_segments
(
tokens_a
,
tokens_b
,
len_a
,
len_b
,
max_num_tokens
,
np_rng
):
"""Truncates a pair of sequences to a maximum sequence length."""
#print(len_a, len_b, max_num_tokens)
assert
len_a
>
0
assert
len_b
>
0
if
len_a
+
len_b
<=
max_num_tokens
:
return
False
while
len_a
+
len_b
>
max_num_tokens
:
if
len_a
>
len_b
:
len_a
-=
1
tokens
=
tokens_a
else
:
len_b
-=
1
tokens
=
tokens_b
if
np_rng
.
random
()
<
0.5
:
del
tokens
[
0
]
else
:
tokens
.
pop
()
return
True
def
create_tokens_and_tokentypes
(
tokens_a
,
tokens_b
,
cls_id
,
sep_id
):
"""Merge segments A and B, add [CLS] and [SEP] and build tokentypes."""
tokens
=
[]
tokentypes
=
[]
# [CLS].
tokens
.
append
(
cls_id
)
tokentypes
.
append
(
0
)
# Segment A.
for
token
in
tokens_a
:
tokens
.
append
(
token
)
tokentypes
.
append
(
0
)
# [SEP].
tokens
.
append
(
sep_id
)
tokentypes
.
append
(
0
)
# Segment B.
for
token
in
tokens_b
:
tokens
.
append
(
token
)
tokentypes
.
append
(
1
)
# [SEP].
tokens
.
append
(
sep_id
)
tokentypes
.
append
(
1
)
return
tokens
,
tokentypes
MaskedLmInstance
=
collections
.
namedtuple
(
"MaskedLmInstance"
,
[
"index"
,
"label"
])
def
is_start_piece
(
piece
):
"""Check if the current word piece is the starting piece (BERT)."""
# When a word has been split into
# WordPieces, the first token does not have any marker and any subsequence
# tokens are prefixed with ##. So whenever we see the ## token, we
# append it to the previous set of word indexes.
return
not
piece
.
startswith
(
"##"
)
def
create_masked_lm_predictions
(
tokens
,
vocab_id_list
,
vocab_id_to_token_dict
,
masked_lm_prob
,
cls_id
,
sep_id
,
mask_id
,
max_predictions_per_seq
,
np_rng
,
max_ngrams
=
3
,
do_whole_word_mask
=
True
,
favor_longer_ngram
=
False
,
do_permutation
=
False
):
"""Creates the predictions for the masked LM objective.
Note: Tokens here are vocab ids and not text tokens."""
cand_indexes
=
[]
# Note(mingdachen): We create a list for recording if the piece is
# the starting piece of current token, where 1 means true, so that
# on-the-fly whole word masking is possible.
token_boundary
=
[
0
]
*
len
(
tokens
)
for
(
i
,
token
)
in
enumerate
(
tokens
):
if
token
==
cls_id
or
token
==
sep_id
:
token_boundary
[
i
]
=
1
continue
# Whole Word Masking means that if we mask all of the wordpieces
# corresponding to an original word.
#
# Note that Whole Word Masking does *not* change the training code
# at all -- we still predict each WordPiece independently, softmaxed
# over the entire vocabulary.
if
(
do_whole_word_mask
and
len
(
cand_indexes
)
>=
1
and
not
is_start_piece
(
vocab_id_to_token_dict
[
token
])):
cand_indexes
[
-
1
].
append
(
i
)
else
:
cand_indexes
.
append
([
i
])
if
is_start_piece
(
vocab_id_to_token_dict
[
token
]):
token_boundary
[
i
]
=
1
output_tokens
=
list
(
tokens
)
masked_lm_positions
=
[]
masked_lm_labels
=
[]
if
masked_lm_prob
==
0
:
return
(
output_tokens
,
masked_lm_positions
,
masked_lm_labels
,
token_boundary
)
num_to_predict
=
min
(
max_predictions_per_seq
,
max
(
1
,
int
(
round
(
len
(
tokens
)
*
masked_lm_prob
))))
# Note(mingdachen):
# By default, we set the probilities to favor shorter ngram sequences.
ngrams
=
np
.
arange
(
1
,
max_ngrams
+
1
,
dtype
=
np
.
int64
)
pvals
=
1.
/
np
.
arange
(
1
,
max_ngrams
+
1
)
pvals
/=
pvals
.
sum
(
keepdims
=
True
)
if
favor_longer_ngram
:
pvals
=
pvals
[::
-
1
]
ngram_indexes
=
[]
for
idx
in
range
(
len
(
cand_indexes
)):
ngram_index
=
[]
for
n
in
ngrams
:
ngram_index
.
append
(
cand_indexes
[
idx
:
idx
+
n
])
ngram_indexes
.
append
(
ngram_index
)
np_rng
.
shuffle
(
ngram_indexes
)
masked_lms
=
[]
covered_indexes
=
set
()
for
cand_index_set
in
ngram_indexes
:
if
len
(
masked_lms
)
>=
num_to_predict
:
break
if
not
cand_index_set
:
continue
# Note(mingdachen):
# Skip current piece if they are covered in lm masking or previous ngrams.
for
index_set
in
cand_index_set
[
0
]:
for
index
in
index_set
:
if
index
in
covered_indexes
:
continue
n
=
np_rng
.
choice
(
ngrams
[:
len
(
cand_index_set
)],
p
=
pvals
[:
len
(
cand_index_set
)]
/
pvals
[:
len
(
cand_index_set
)].
sum
(
keepdims
=
True
))
index_set
=
sum
(
cand_index_set
[
n
-
1
],
[])
n
-=
1
# Note(mingdachen):
# Repeatedly looking for a candidate that does not exceed the
# maximum number of predictions by trying shorter ngrams.
while
len
(
masked_lms
)
+
len
(
index_set
)
>
num_to_predict
:
if
n
==
0
:
break
index_set
=
sum
(
cand_index_set
[
n
-
1
],
[])
n
-=
1
# If adding a whole-word mask would exceed the maximum number of
# predictions, then just skip this candidate.
if
len
(
masked_lms
)
+
len
(
index_set
)
>
num_to_predict
:
continue
is_any_index_covered
=
False
for
index
in
index_set
:
if
index
in
covered_indexes
:
is_any_index_covered
=
True
break
if
is_any_index_covered
:
continue
for
index
in
index_set
:
covered_indexes
.
add
(
index
)
masked_token
=
None
# 80% of the time, replace with [MASK]
if
np_rng
.
random
()
<
0.8
:
masked_token
=
mask_id
else
:
# 10% of the time, keep original
if
np_rng
.
random
()
<
0.5
:
masked_token
=
tokens
[
index
]
# 10% of the time, replace with random word
else
:
masked_token
=
vocab_id_list
[
np_rng
.
randint
(
0
,
len
(
vocab_id_list
))]
output_tokens
[
index
]
=
masked_token
masked_lms
.
append
(
MaskedLmInstance
(
index
=
index
,
label
=
tokens
[
index
]))
assert
len
(
masked_lms
)
<=
num_to_predict
np_rng
.
shuffle
(
ngram_indexes
)
select_indexes
=
set
()
if
do_permutation
:
for
cand_index_set
in
ngram_indexes
:
if
len
(
select_indexes
)
>=
num_to_predict
:
break
if
not
cand_index_set
:
continue
# Note(mingdachen):
# Skip current piece if they are covered in lm masking or previous ngrams.
for
index_set
in
cand_index_set
[
0
]:
for
index
in
index_set
:
if
index
in
covered_indexes
or
index
in
select_indexes
:
continue
n
=
np
.
random
.
choice
(
ngrams
[:
len
(
cand_index_set
)],
p
=
pvals
[:
len
(
cand_index_set
)]
/
pvals
[:
len
(
cand_index_set
)].
sum
(
keepdims
=
True
))
index_set
=
sum
(
cand_index_set
[
n
-
1
],
[])
n
-=
1
while
len
(
select_indexes
)
+
len
(
index_set
)
>
num_to_predict
:
if
n
==
0
:
break
index_set
=
sum
(
cand_index_set
[
n
-
1
],
[])
n
-=
1
# If adding a whole-word mask would exceed the maximum number of
# predictions, then just skip this candidate.
if
len
(
select_indexes
)
+
len
(
index_set
)
>
num_to_predict
:
continue
is_any_index_covered
=
False
for
index
in
index_set
:
if
index
in
covered_indexes
or
index
in
select_indexes
:
is_any_index_covered
=
True
break
if
is_any_index_covered
:
continue
for
index
in
index_set
:
select_indexes
.
add
(
index
)
assert
len
(
select_indexes
)
<=
num_to_predict
select_indexes
=
sorted
(
select_indexes
)
permute_indexes
=
list
(
select_indexes
)
np_rng
.
shuffle
(
permute_indexes
)
orig_token
=
list
(
output_tokens
)
for
src_i
,
tgt_i
in
zip
(
select_indexes
,
permute_indexes
):
output_tokens
[
src_i
]
=
orig_token
[
tgt_i
]
masked_lms
.
append
(
MaskedLmInstance
(
index
=
src_i
,
label
=
orig_token
[
src_i
]))
masked_lms
=
sorted
(
masked_lms
,
key
=
lambda
x
:
x
.
index
)
for
p
in
masked_lms
:
masked_lm_positions
.
append
(
p
.
index
)
masked_lm_labels
.
append
(
p
.
label
)
return
(
output_tokens
,
masked_lm_positions
,
masked_lm_labels
,
token_boundary
)
def
pad_and_convert_to_numpy
(
tokens
,
tokentypes
,
masked_positions
,
masked_labels
,
pad_id
,
max_seq_length
):
"""Pad sequences and convert them to numpy."""
# Some checks.
num_tokens
=
len
(
tokens
)
padding_length
=
max_seq_length
-
num_tokens
assert
padding_length
>=
0
assert
len
(
tokentypes
)
==
num_tokens
assert
len
(
masked_positions
)
==
len
(
masked_labels
)
# Tokens and token types.
filler
=
[
pad_id
]
*
padding_length
tokens_np
=
np
.
array
(
tokens
+
filler
,
dtype
=
np
.
int64
)
tokentypes_np
=
np
.
array
(
tokentypes
+
filler
,
dtype
=
np
.
int64
)
# Padding mask.
padding_mask_np
=
np
.
array
([
1
]
*
num_tokens
+
[
0
]
*
padding_length
,
dtype
=
np
.
int64
)
# Lables and loss mask.
labels
=
[
-
1
]
*
max_seq_length
loss_mask
=
[
0
]
*
max_seq_length
for
i
in
range
(
len
(
masked_positions
)):
assert
masked_positions
[
i
]
<
num_tokens
labels
[
masked_positions
[
i
]]
=
masked_labels
[
i
]
loss_mask
[
masked_positions
[
i
]]
=
1
labels_np
=
np
.
array
(
labels
,
dtype
=
np
.
int64
)
loss_mask_np
=
np
.
array
(
loss_mask
,
dtype
=
np
.
int64
)
return
tokens_np
,
tokentypes_np
,
labels_np
,
padding_mask_np
,
loss_mask_np
def
build_train_valid_test_datasets
(
data_prefix
,
data_impl
,
splits_string
,
train_valid_test_num_samples
,
max_seq_length
,
masked_lm_prob
,
short_seq_prob
,
seed
,
skip_warmup
,
dataset_type
=
'standard_bert'
):
if
dataset_type
not
in
DSET_TYPES
:
raise
ValueError
(
"Invalid dataset_type: "
,
dataset_type
)
# Indexed dataset.
indexed_dataset
=
get_indexed_dataset_
(
data_prefix
,
data_impl
,
skip_warmup
)
if
dataset_type
==
DSET_TYPE_ICT
:
args
=
get_args
()
title_dataset
=
get_indexed_dataset_
(
args
.
titles_data_path
,
data_impl
,
skip_warmup
)
# Get start and end indices of train/valid/train into doc-idx
# Note that doc-idx is desinged to be num-docs + 1 so we can
# easily iterate over it.
total_num_of_documents
=
indexed_dataset
.
doc_idx
.
shape
[
0
]
-
1
splits
=
get_train_valid_test_split_
(
splits_string
,
total_num_of_documents
)
# Print stats about the splits.
print_rank_0
(
' > dataset split:'
)
def
print_split_stats
(
name
,
index
):
print_rank_0
(
' {}:'
.
format
(
name
))
print_rank_0
(
' document indices in [{}, {}) total of {} '
'documents'
.
format
(
splits
[
index
],
splits
[
index
+
1
],
splits
[
index
+
1
]
-
splits
[
index
]))
start_index
=
indexed_dataset
.
doc_idx
[
splits
[
index
]]
end_index
=
indexed_dataset
.
doc_idx
[
splits
[
index
+
1
]]
print_rank_0
(
' sentence indices in [{}, {}) total of {} '
'sentences'
.
format
(
start_index
,
end_index
,
end_index
-
start_index
))
print_split_stats
(
'train'
,
0
)
print_split_stats
(
'validation'
,
1
)
print_split_stats
(
'test'
,
2
)
def
build_dataset
(
index
,
name
):
from
megatron.data.bert_dataset
import
BertDataset
from
megatron.data.ict_dataset
import
ICTDataset
dataset
=
None
if
splits
[
index
+
1
]
>
splits
[
index
]:
# Get the pointer to the original doc-idx so we can set it later.
doc_idx_ptr
=
indexed_dataset
.
get_doc_idx
()
# Slice the doc-idx
start_index
=
splits
[
index
]
# Add +1 so we can index into the dataset to get the upper bound.
end_index
=
splits
[
index
+
1
]
+
1
# New doc_idx view.
indexed_dataset
.
set_doc_idx
(
doc_idx_ptr
[
start_index
:
end_index
])
# Build the dataset accordingly.
kwargs
=
dict
(
name
=
name
,
data_prefix
=
data_prefix
,
num_epochs
=
None
,
max_num_samples
=
train_valid_test_num_samples
[
index
],
max_seq_length
=
max_seq_length
,
seed
=
seed
)
if
dataset_type
==
DSET_TYPE_ICT
:
args
=
get_args
()
dataset
=
ICTDataset
(
block_dataset
=
indexed_dataset
,
title_dataset
=
title_dataset
,
query_in_block_prob
=
args
.
query_in_block_prob
,
use_one_sent_docs
=
args
.
use_one_sent_docs
,
**
kwargs
)
else
:
dataset
=
BertDataset
(
indexed_dataset
=
indexed_dataset
,
masked_lm_prob
=
masked_lm_prob
,
short_seq_prob
=
short_seq_prob
,
**
kwargs
)
# Set the original pointer so dataset remains the main dataset.
indexed_dataset
.
set_doc_idx
(
doc_idx_ptr
)
# Checks.
assert
indexed_dataset
.
doc_idx
[
0
]
==
0
assert
indexed_dataset
.
doc_idx
.
shape
[
0
]
==
\
(
total_num_of_documents
+
1
)
return
dataset
train_dataset
=
build_dataset
(
0
,
'train'
)
valid_dataset
=
build_dataset
(
1
,
'valid'
)
test_dataset
=
build_dataset
(
2
,
'test'
)
return
(
train_dataset
,
valid_dataset
,
test_dataset
)
def
get_indexed_dataset_
(
data_prefix
,
data_impl
,
skip_warmup
):
print_rank_0
(
' > building dataset index ...'
)
start_time
=
time
.
time
()
indexed_dataset
=
make_indexed_dataset
(
data_prefix
,
data_impl
,
skip_warmup
)
assert
indexed_dataset
.
sizes
.
shape
[
0
]
==
indexed_dataset
.
doc_idx
[
-
1
]
print_rank_0
(
' > finished creating indexed dataset in {:4f} '
'seconds'
.
format
(
time
.
time
()
-
start_time
))
print_rank_0
(
' > indexed dataset stats:'
)
print_rank_0
(
' number of documents: {}'
.
format
(
indexed_dataset
.
doc_idx
.
shape
[
0
]
-
1
))
print_rank_0
(
' number of sentences: {}'
.
format
(
indexed_dataset
.
sizes
.
shape
[
0
]))
return
indexed_dataset
def
get_train_valid_test_split_
(
splits_string
,
size
):
""" Get dataset splits from comma or '/' separated string list."""
splits
=
[]
if
splits_string
.
find
(
','
)
!=
-
1
:
splits
=
[
float
(
s
)
for
s
in
splits_string
.
split
(
','
)]
elif
splits_string
.
find
(
'/'
)
!=
-
1
:
splits
=
[
float
(
s
)
for
s
in
splits_string
.
split
(
'/'
)]
else
:
splits
=
[
float
(
splits_string
)]
while
len
(
splits
)
<
3
:
splits
.
append
(
0.
)
splits
=
splits
[:
3
]
splits_sum
=
sum
(
splits
)
assert
splits_sum
>
0.0
splits
=
[
split
/
splits_sum
for
split
in
splits
]
splits_index
=
[
0
]
for
index
,
split
in
enumerate
(
splits
):
splits_index
.
append
(
splits_index
[
index
]
+
int
(
round
(
split
*
float
(
size
))))
diff
=
splits_index
[
-
1
]
-
size
for
index
in
range
(
1
,
len
(
splits_index
)):
splits_index
[
index
]
-=
diff
assert
len
(
splits_index
)
==
4
assert
splits_index
[
-
1
]
==
size
return
splits_index
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/gpt2_dataset.py
0 → 100644
View file @
316d3f90
# coding=utf-8
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""GPT2 style dataset."""
import
os
import
time
import
numpy
as
np
import
torch
from
megatron
import
mpu
,
print_rank_0
from
megatron.data.dataset_utils
import
get_train_valid_test_split_
from
megatron.data.indexed_dataset
import
make_dataset
as
make_indexed_dataset
def
build_train_valid_test_datasets
(
data_prefix
,
data_impl
,
splits_string
,
train_valid_test_num_samples
,
seq_length
,
seed
,
skip_warmup
):
"""Build train, valid, and test datasets."""
# Indexed dataset.
indexed_dataset
=
get_indexed_dataset_
(
data_prefix
,
data_impl
,
skip_warmup
)
total_num_of_documents
=
indexed_dataset
.
sizes
.
shape
[
0
]
splits
=
get_train_valid_test_split_
(
splits_string
,
total_num_of_documents
)
# Print stats about the splits.
print_rank_0
(
' > dataset split:'
)
def
print_split_stats
(
name
,
index
):
print_rank_0
(
' {}:'
.
format
(
name
))
print_rank_0
(
' document indices in [{}, {}) total of {} '
'documents'
.
format
(
splits
[
index
],
splits
[
index
+
1
],
splits
[
index
+
1
]
-
splits
[
index
]))
print_split_stats
(
'train'
,
0
)
print_split_stats
(
'validation'
,
1
)
print_split_stats
(
'test'
,
2
)
def
build_dataset
(
index
,
name
):
dataset
=
None
if
splits
[
index
+
1
]
>
splits
[
index
]:
documents
=
np
.
arange
(
start
=
splits
[
index
],
stop
=
splits
[
index
+
1
],
step
=
1
,
dtype
=
np
.
int32
)
dataset
=
GPT2Dataset
(
name
,
data_prefix
,
documents
,
indexed_dataset
,
train_valid_test_num_samples
[
index
],
seq_length
,
seed
)
return
dataset
train_dataset
=
build_dataset
(
0
,
'train'
)
valid_dataset
=
build_dataset
(
1
,
'valid'
)
test_dataset
=
build_dataset
(
2
,
'test'
)
return
(
train_dataset
,
valid_dataset
,
test_dataset
)
def
get_indexed_dataset_
(
data_prefix
,
data_impl
,
skip_warmup
):
"""Build indexed dataset."""
print_rank_0
(
' > building dataset index ...'
)
start_time
=
time
.
time
()
indexed_dataset
=
make_indexed_dataset
(
data_prefix
,
data_impl
,
skip_warmup
)
print_rank_0
(
' > finished creating indexed dataset in {:4f} '
'seconds'
.
format
(
time
.
time
()
-
start_time
))
print_rank_0
(
' number of documents: {}'
.
format
(
indexed_dataset
.
sizes
.
shape
[
0
]))
return
indexed_dataset
class
GPT2Dataset
(
torch
.
utils
.
data
.
Dataset
):
def
__init__
(
self
,
name
,
data_prefix
,
documents
,
indexed_dataset
,
num_samples
,
seq_length
,
seed
):
self
.
name
=
name
self
.
indexed_dataset
=
indexed_dataset
# Checks
assert
np
.
min
(
documents
)
>=
0
assert
np
.
max
(
documents
)
<
indexed_dataset
.
sizes
.
shape
[
0
]
# Build index mappings.
self
.
doc_idx
,
self
.
sample_idx
,
self
.
shuffle_idx
=
_build_index_mappings
(
self
.
name
,
data_prefix
,
documents
,
self
.
indexed_dataset
.
sizes
,
num_samples
,
seq_length
,
seed
)
def
__len__
(
self
):
# -1 is due to data structure used to retieve the index:
# sample i --> [sample_idx[i], sample_idx[i+1])
return
self
.
sample_idx
.
shape
[
0
]
-
1
def
__getitem__
(
self
,
idx
):
# Get the shuffled index.
idx
=
self
.
shuffle_idx
[
idx
]
# Start and end documents and offsets.
doc_index_f
=
self
.
sample_idx
[
idx
][
0
]
doc_index_l
=
self
.
sample_idx
[
idx
+
1
][
0
]
offset_f
=
self
.
sample_idx
[
idx
][
1
]
offset_l
=
self
.
sample_idx
[
idx
+
1
][
1
]
# If we are within the same document, just extract the chunk.
if
doc_index_f
==
doc_index_l
:
sample
=
self
.
indexed_dataset
.
get
(
self
.
doc_idx
[
doc_index_f
],
offset
=
offset_f
,
length
=
offset_l
-
offset_f
+
1
)
else
:
# Otherwise, get the rest of the initial document.
sample_list
=
[
self
.
indexed_dataset
.
get
(
self
.
doc_idx
[
doc_index_f
],
offset
=
offset_f
)]
# Loop over all in between documents and add the entire document.
for
i
in
range
(
doc_index_f
+
1
,
doc_index_l
):
sample_list
.
append
(
self
.
indexed_dataset
.
get
(
self
.
doc_idx
[
i
]))
# And finally add the relevant portion of last document.
sample_list
.
append
(
self
.
indexed_dataset
.
get
(
self
.
doc_idx
[
doc_index_l
],
length
=
offset_l
+
1
))
sample
=
np
.
concatenate
(
sample_list
)
return
{
'text'
:
np
.
array
(
sample
,
dtype
=
np
.
int64
)}
def
_build_index_mappings
(
name
,
data_prefix
,
documents
,
sizes
,
num_samples
,
seq_length
,
seed
):
"""Build doc-idx, sample-idx, and shuffle-idx.
doc-idx: is an array (ordered) of documents to be used in training.
sample-idx: is the start document index and document offset for each
training sample.
shuffle-idx: maps the sample index into a random index into sample-idx.
"""
# Number of tokens in each epoch and number of required epochs.
tokens_per_epoch
=
_num_tokens
(
documents
,
sizes
)
num_epochs
=
_num_epochs
(
tokens_per_epoch
,
seq_length
,
num_samples
)
# rng state
np_rng
=
np
.
random
.
RandomState
(
seed
=
seed
)
# Filename of the index mappings.
_filename
=
data_prefix
_filename
+=
'_{}_indexmap'
.
format
(
name
)
_filename
+=
'_{}ns'
.
format
(
num_samples
)
_filename
+=
'_{}sl'
.
format
(
seq_length
)
_filename
+=
'_{}s'
.
format
(
seed
)
doc_idx_filename
=
_filename
+
'_doc_idx.npy'
sample_idx_filename
=
_filename
+
'_sample_idx.npy'
shuffle_idx_filename
=
_filename
+
'_shuffle_idx.npy'
# Build the indexed mapping if not exist.
if
torch
.
distributed
.
get_rank
()
==
0
:
if
(
not
os
.
path
.
isfile
(
doc_idx_filename
))
or
\
(
not
os
.
path
.
isfile
(
sample_idx_filename
))
or
\
(
not
os
.
path
.
isfile
(
shuffle_idx_filename
)):
print_rank_0
(
' > WARNING: could not find index map files, building '
'the indices on rank 0 ...'
)
# doc-idx.
start_time
=
time
.
time
()
doc_idx
=
_build_doc_idx
(
documents
,
num_epochs
,
np_rng
)
np
.
save
(
doc_idx_filename
,
doc_idx
,
allow_pickle
=
True
)
print_rank_0
(
' > elasped time to build and save doc-idx mapping '
'(seconds): {:4f}'
.
format
(
time
.
time
()
-
start_time
))
# sample-idx.
start_time
=
time
.
time
()
# Use C++ implementation for speed.
# First compile and then import.
from
megatron.data.dataset_utils
import
compile_helper
compile_helper
()
from
megatron.data
import
helpers
assert
doc_idx
.
dtype
==
np
.
int32
assert
sizes
.
dtype
==
np
.
int32
sample_idx
=
helpers
.
build_sample_idx
(
sizes
,
doc_idx
,
seq_length
,
num_epochs
,
tokens_per_epoch
)
# sample_idx = _build_sample_idx(sizes, doc_idx, seq_length,
# num_epochs, tokens_per_epoch)
np
.
save
(
sample_idx_filename
,
sample_idx
,
allow_pickle
=
True
)
print_rank_0
(
' > elasped time to build and save sample-idx mapping '
'(seconds): {:4f}'
.
format
(
time
.
time
()
-
start_time
))
# shuffle-idx.
start_time
=
time
.
time
()
# -1 is due to data structure used to retieve the index:
# sample i --> [sample_idx[i], sample_idx[i+1])
shuffle_idx
=
_build_shuffle_idx
(
sample_idx
.
shape
[
0
]
-
1
,
np_rng
)
np
.
save
(
shuffle_idx_filename
,
shuffle_idx
,
allow_pickle
=
True
)
print_rank_0
(
' > elasped time to build and save shuffle-idx mapping'
' (seconds): {:4f}'
.
format
(
time
.
time
()
-
start_time
))
# This should be a barrier but nccl barrier assumes
# device_index=rank which is not the case for model
# parallel case
counts
=
torch
.
cuda
.
LongTensor
([
1
])
torch
.
distributed
.
all_reduce
(
counts
,
group
=
mpu
.
get_io_parallel_group
())
assert
counts
[
0
].
item
()
==
torch
.
distributed
.
get_world_size
(
group
=
mpu
.
get_io_parallel_group
())
# Load mappings.
start_time
=
time
.
time
()
print_rank_0
(
' > loading doc-idx mapping from {}'
.
format
(
doc_idx_filename
))
doc_idx
=
np
.
load
(
doc_idx_filename
,
allow_pickle
=
True
,
mmap_mode
=
'r'
)
print_rank_0
(
' > loading sample-idx mapping from {}'
.
format
(
sample_idx_filename
))
sample_idx
=
np
.
load
(
sample_idx_filename
,
allow_pickle
=
True
,
mmap_mode
=
'r'
)
print_rank_0
(
' > loading shuffle-idx mapping from {}'
.
format
(
shuffle_idx_filename
))
shuffle_idx
=
np
.
load
(
shuffle_idx_filename
,
allow_pickle
=
True
,
mmap_mode
=
'r'
)
print_rank_0
(
' loaded indexed file in {:3.3f} seconds'
.
format
(
time
.
time
()
-
start_time
))
print_rank_0
(
' total number of samples: {}'
.
format
(
sample_idx
.
shape
[
0
]))
print_rank_0
(
' total number of epochs: {}'
.
format
(
num_epochs
))
return
doc_idx
,
sample_idx
,
shuffle_idx
def
_num_tokens
(
documents
,
sizes
):
"""Total number of tokens in the dataset."""
return
np
.
sum
(
sizes
[
documents
])
def
_num_epochs
(
tokens_per_epoch
,
seq_length
,
num_samples
):
"""Based on number of samples and sequence lenght, calculate how many
epochs will be needed."""
num_epochs
=
0
total_tokens
=
0
while
True
:
num_epochs
+=
1
total_tokens
+=
tokens_per_epoch
# -1 is because we need to retrieve seq_length + 1 token each time
# but the last token will overlap with the first token of the next
# sample except for the last sample.
if
((
total_tokens
-
1
)
//
seq_length
)
>=
num_samples
:
return
num_epochs
def
_build_doc_idx
(
documents
,
num_epochs
,
np_rng
):
"""Build an array with length = number-of-epochs * number-of-dcuments.
Each index is mapped to a corresponding document."""
doc_idx
=
np
.
mgrid
[
0
:
num_epochs
,
0
:
len
(
documents
)][
1
]
doc_idx
[:]
=
documents
doc_idx
=
doc_idx
.
reshape
(
-
1
)
doc_idx
=
doc_idx
.
astype
(
np
.
int32
)
np_rng
.
shuffle
(
doc_idx
)
return
doc_idx
def
_build_sample_idx
(
sizes
,
doc_idx
,
seq_length
,
num_epochs
,
tokens_per_epoch
):
"""Sample index mapping is a 2D array with sizes
[number-of-samples + 1, 2] where [..., 0] contains
the index into `doc_idx` and [..., 1] is the
starting offset in that document."""
# Total number of samples. For -1 see comments in `_num_epochs`.
num_samples
=
(
num_epochs
*
tokens_per_epoch
-
1
)
//
seq_length
sample_idx
=
np
.
zeros
([
num_samples
+
1
,
2
],
dtype
=
np
.
int32
)
# Index into sample_idx.
sample_index
=
0
# Index into doc_idx.
doc_idx_index
=
0
# Begining offset for each document.
doc_offset
=
0
# Start with first document and no offset.
sample_idx
[
sample_index
][
0
]
=
doc_idx_index
sample_idx
[
sample_index
][
1
]
=
doc_offset
sample_index
+=
1
while
sample_index
<=
num_samples
:
# Start with a fresh sequence.
remaining_seq_length
=
seq_length
+
1
while
remaining_seq_length
!=
0
:
# Get the document length.
doc_id
=
doc_idx
[
doc_idx_index
]
doc_length
=
sizes
[
doc_id
]
-
doc_offset
# And add it to the current sequence.
remaining_seq_length
-=
doc_length
# If we have more than a full sequence, adjust offset and set
# remaining length to zero so we return from the while loop.
# Note that -1 here is for the same reason we have -1 in
# `_num_epochs` calculations.
if
remaining_seq_length
<=
0
:
doc_offset
+=
(
remaining_seq_length
+
doc_length
-
1
)
remaining_seq_length
=
0
else
:
# Otherwise, start from the begining of the next document.
doc_idx_index
+=
1
doc_offset
=
0
# Record the sequence.
sample_idx
[
sample_index
][
0
]
=
doc_idx_index
sample_idx
[
sample_index
][
1
]
=
doc_offset
sample_index
+=
1
return
sample_idx
def
_build_shuffle_idx
(
size
,
np_rng
):
"""Build the range [0, size) and shuffle."""
dtype_
=
np
.
uint32
if
size
>=
(
np
.
iinfo
(
np
.
uint32
).
max
-
1
):
dtype_
=
np
.
int64
shuffle_idx
=
np
.
arange
(
start
=
0
,
stop
=
size
,
step
=
1
,
dtype
=
dtype_
)
np_rng
.
shuffle
(
shuffle_idx
)
return
shuffle_idx
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/helpers.cpp
0 → 100644
View file @
316d3f90
/*
coding=utf-8
Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
/* Helper methods for fast index mapping builds */
#include <algorithm>
#include <iostream>
#include <limits>
#include <math.h>
#include <stdexcept>
#include <pybind11/pybind11.h>
#include <pybind11/numpy.h>
#include <random>
namespace
py
=
pybind11
;
using
namespace
std
;
const
int32_t
LONG_SENTENCE_LEN
=
512
;
py
::
array
build_sample_idx
(
const
py
::
array_t
<
int32_t
>&
sizes_
,
const
py
::
array_t
<
int32_t
>&
doc_idx_
,
const
int32_t
seq_length
,
const
int32_t
num_epochs
,
const
int64_t
tokens_per_epoch
)
{
/* Sample index (sample_idx) is used for gpt2 like dataset for which
the documents are flattened and the samples are built based on this
1-D flatten array. It is a 2D array with sizes [number-of-samples + 1, 2]
where [..., 0] contains the index into `doc_idx` and [..., 1] is the
starting offset in that document.*/
// Consistency checks.
assert
(
seq_length
>
1
);
assert
(
num_epochs
>
0
);
assert
(
tokens_per_epoch
>
1
);
// Remove bound checks.
auto
sizes
=
sizes_
.
unchecked
<
1
>
();
auto
doc_idx
=
doc_idx_
.
unchecked
<
1
>
();
// Mapping and it's length (1D).
int64_t
num_samples
=
(
num_epochs
*
tokens_per_epoch
-
1
)
/
seq_length
;
int32_t
*
sample_idx
=
new
int32_t
[
2
*
(
num_samples
+
1
)];
cout
<<
" using:"
<<
endl
<<
std
::
flush
;
cout
<<
" number of documents: "
<<
doc_idx_
.
shape
(
0
)
/
num_epochs
<<
endl
<<
std
::
flush
;
cout
<<
" number of epochs: "
<<
num_epochs
<<
endl
<<
std
::
flush
;
cout
<<
" sequence length: "
<<
seq_length
<<
endl
<<
std
::
flush
;
cout
<<
" total number of samples: "
<<
num_samples
<<
endl
<<
std
::
flush
;
// Index into sample_idx.
int64_t
sample_index
=
0
;
// Index into doc_idx.
int64_t
doc_idx_index
=
0
;
// Begining offset for each document.
int32_t
doc_offset
=
0
;
// Start with first document and no offset.
sample_idx
[
2
*
sample_index
]
=
doc_idx_index
;
sample_idx
[
2
*
sample_index
+
1
]
=
doc_offset
;
++
sample_index
;
while
(
sample_index
<=
num_samples
)
{
// Start with a fresh sequence.
int32_t
remaining_seq_length
=
seq_length
+
1
;
while
(
remaining_seq_length
!=
0
)
{
// Get the document length.
auto
doc_id
=
doc_idx
[
doc_idx_index
];
auto
doc_length
=
sizes
[
doc_id
]
-
doc_offset
;
// And add it to the current sequence.
remaining_seq_length
-=
doc_length
;
// If we have more than a full sequence, adjust offset and set
// remaining length to zero so we return from the while loop.
// Note that -1 here is for the same reason we have -1 in
// `_num_epochs` calculations.
if
(
remaining_seq_length
<=
0
)
{
doc_offset
+=
(
remaining_seq_length
+
doc_length
-
1
);
remaining_seq_length
=
0
;
}
else
{
// Otherwise, start from the begining of the next document.
++
doc_idx_index
;
doc_offset
=
0
;
}
}
// Record the sequence.
sample_idx
[
2
*
sample_index
]
=
doc_idx_index
;
sample_idx
[
2
*
sample_index
+
1
]
=
doc_offset
;
++
sample_index
;
}
// Method to deallocate memory.
py
::
capsule
free_when_done
(
sample_idx
,
[](
void
*
mem_
)
{
int32_t
*
mem
=
reinterpret_cast
<
int32_t
*>
(
mem_
);
delete
[]
mem
;
});
// Return the numpy array.
const
auto
byte_size
=
sizeof
(
int32_t
);
return
py
::
array
(
std
::
vector
<
int64_t
>
{
num_samples
+
1
,
2
},
// shape
{
2
*
byte_size
,
byte_size
},
// C-style contiguous strides
sample_idx
,
// the data pointer
free_when_done
);
// numpy array references
}
inline
int32_t
get_target_sample_len
(
const
int32_t
short_seq_ratio
,
const
int32_t
max_length
,
std
::
mt19937
&
rand32_gen
)
{
/* Training sample length. */
const
auto
random_number
=
rand32_gen
();
if
((
random_number
%
short_seq_ratio
)
==
0
)
{
return
2
+
random_number
%
(
max_length
-
1
);
}
return
max_length
;
}
template
<
typename
DocIdx
>
py
::
array
build_mapping_impl
(
const
py
::
array_t
<
int64_t
>&
docs_
,
const
py
::
array_t
<
int32_t
>&
sizes_
,
const
int32_t
num_epochs
,
const
uint64_t
max_num_samples
,
const
int32_t
max_seq_length
,
const
double
short_seq_prob
,
const
int32_t
seed
,
const
bool
verbose
)
{
/* Build a mapping of (start-index, end-index, sequence-length) where
start and end index are the indices of the sentences in the sample
and sequence-length is the target sequence length.
*/
// Consistency checks.
assert
(
num_epochs
>
0
);
assert
(
max_seq_length
>
1
);
assert
(
short_seq_prob
>
0.0
);
assert
(
short_seq_prob
<=
1.0
);
assert
(
seed
>
0
);
// Remove bound checks.
auto
docs
=
docs_
.
unchecked
<
1
>
();
auto
sizes
=
sizes_
.
unchecked
<
1
>
();
// For efficiency, convert probability to ratio. Note: rand() generates int.
const
auto
short_seq_ratio
=
static_cast
<
int32_t
>
(
round
(
1.0
/
short_seq_prob
));
if
(
verbose
)
{
const
auto
sent_start_index
=
docs
[
0
];
const
auto
sent_end_index
=
docs
[
docs_
.
shape
(
0
)
-
1
];
const
auto
num_sentences
=
sent_end_index
-
sent_start_index
;
cout
<<
" using:"
<<
endl
<<
std
::
flush
;
cout
<<
" number of documents: "
<<
docs_
.
shape
(
0
)
-
1
<<
endl
<<
std
::
flush
;
cout
<<
" sentences range: ["
<<
sent_start_index
<<
", "
<<
sent_end_index
<<
")"
<<
endl
<<
std
::
flush
;
cout
<<
" total number of sentences: "
<<
num_sentences
<<
endl
<<
std
::
flush
;
cout
<<
" number of epochs: "
<<
num_epochs
<<
endl
<<
std
::
flush
;
cout
<<
" maximum number of samples: "
<<
max_num_samples
<<
endl
<<
std
::
flush
;
cout
<<
" maximum sequence length: "
<<
max_seq_length
<<
endl
<<
std
::
flush
;
cout
<<
" short sequence probability: "
<<
short_seq_prob
<<
endl
<<
std
::
flush
;
cout
<<
" short sequence ration (1/prob): "
<<
short_seq_ratio
<<
endl
<<
std
::
flush
;
cout
<<
" seed: "
<<
seed
<<
endl
<<
std
::
flush
;
}
// Mapping and it's length (1D).
int64_t
num_samples
=
-
1
;
DocIdx
*
maps
=
NULL
;
// Perform two iterations, in the first iteration get the size
// and allocate memory and in the second iteration populate the map.
bool
second
=
false
;
for
(
int32_t
iteration
=
0
;
iteration
<
2
;
++
iteration
)
{
// Set the seed so both iterations produce the same results.
std
::
mt19937
rand32_gen
(
seed
);
// Set the flag on second iteration.
second
=
(
iteration
==
1
);
// Counters:
uint64_t
empty_docs
=
0
;
uint64_t
one_sent_docs
=
0
;
uint64_t
long_sent_docs
=
0
;
// Current map index.
uint64_t
map_index
=
0
;
// For each epoch:
for
(
int32_t
epoch
=
0
;
epoch
<
num_epochs
;
++
epoch
)
{
if
(
map_index
>=
max_num_samples
)
{
if
(
verbose
&&
(
!
second
))
{
cout
<<
" reached "
<<
max_num_samples
<<
" samples after "
<<
epoch
<<
" epochs ..."
<<
endl
<<
std
::
flush
;
}
break
;
}
// For each document:
for
(
int32_t
doc
=
0
;
doc
<
(
docs
.
shape
(
0
)
-
1
);
++
doc
)
{
// Document sentences are in [sent_index_first, sent_index_last)
const
auto
sent_index_first
=
docs
[
doc
];
const
auto
sent_index_last
=
docs
[
doc
+
1
];
// At the begining of the document previous index is the
// start index.
auto
prev_start_index
=
sent_index_first
;
// Remaining documents.
auto
num_remain_sent
=
sent_index_last
-
sent_index_first
;
// Some bookkeeping
if
((
epoch
==
0
)
&&
(
!
second
))
{
if
(
num_remain_sent
==
0
)
{
++
empty_docs
;
}
if
(
num_remain_sent
==
1
)
{
++
one_sent_docs
;
}
}
// Detect documents with long sentences.
bool
contains_long_sentence
=
false
;
if
(
num_remain_sent
>
1
)
{
for
(
auto
sent_index
=
sent_index_first
;
sent_index
<
sent_index_last
;
++
sent_index
)
{
if
(
sizes
[
sent_index
]
>
LONG_SENTENCE_LEN
){
if
((
epoch
==
0
)
&&
(
!
second
))
{
++
long_sent_docs
;
}
contains_long_sentence
=
true
;
break
;
}
}
}
// If we have more than two sentences.
if
((
num_remain_sent
>
1
)
&&
(
!
contains_long_sentence
))
{
// Set values.
auto
seq_len
=
int32_t
{
0
};
auto
num_sent
=
int32_t
{
0
};
auto
target_seq_len
=
get_target_sample_len
(
short_seq_ratio
,
max_seq_length
,
rand32_gen
);
// Loop through sentences.
for
(
auto
sent_index
=
sent_index_first
;
sent_index
<
sent_index_last
;
++
sent_index
)
{
// Add the size and number of sentences.
seq_len
+=
sizes
[
sent_index
];
++
num_sent
;
--
num_remain_sent
;
// If we have reached the target length.
// and if not only one sentence is left in the document.
// and if we have at least two sentneces.
// and if we have reached end of the document.
if
(((
seq_len
>=
target_seq_len
)
&&
(
num_remain_sent
>
1
)
&&
(
num_sent
>
1
)
)
||
(
num_remain_sent
==
0
))
{
// Check for overflow.
if
((
3
*
map_index
+
2
)
>
std
::
numeric_limits
<
int64_t
>::
max
())
{
cout
<<
"number of samples exceeded maximum "
<<
"allowed by type int64: "
<<
std
::
numeric_limits
<
int64_t
>::
max
()
<<
endl
;
throw
std
::
overflow_error
(
"Number of samples"
);
}
// Populate the map.
if
(
second
)
{
const
auto
map_index_0
=
3
*
map_index
;
maps
[
map_index_0
]
=
static_cast
<
DocIdx
>
(
prev_start_index
);
maps
[
map_index_0
+
1
]
=
static_cast
<
DocIdx
>
(
sent_index
+
1
);
maps
[
map_index_0
+
2
]
=
static_cast
<
DocIdx
>
(
target_seq_len
);
}
// Update indices / counters.
++
map_index
;
prev_start_index
=
sent_index
+
1
;
target_seq_len
=
get_target_sample_len
(
short_seq_ratio
,
max_seq_length
,
rand32_gen
);
seq_len
=
0
;
num_sent
=
0
;
}
}
// for (auto sent_index=sent_index_first; ...
}
// if (num_remain_sent > 1) {
}
// for (int doc=0; doc < num_docs; ++doc) {
}
// for (int epoch=0; epoch < num_epochs; ++epoch) {
if
(
!
second
)
{
if
(
verbose
)
{
cout
<<
" number of empty documents: "
<<
empty_docs
<<
endl
<<
std
::
flush
;
cout
<<
" number of documents with one sentence: "
<<
one_sent_docs
<<
endl
<<
std
::
flush
;
cout
<<
" number of documents with long sentences: "
<<
long_sent_docs
<<
endl
<<
std
::
flush
;
cout
<<
" will create mapping for "
<<
map_index
<<
" samples"
<<
endl
<<
std
::
flush
;
}
assert
(
maps
==
NULL
);
assert
(
num_samples
<
0
);
maps
=
new
DocIdx
[
3
*
map_index
];
num_samples
=
static_cast
<
int64_t
>
(
map_index
);
}
}
// for (int iteration=0; iteration < 2; ++iteration) {
// Shuffle.
// We need a 64 bit random number generator as we might have more
// than 2 billion samples.
std
::
mt19937_64
rand64_gen
(
seed
+
1
);
for
(
auto
i
=
(
num_samples
-
1
);
i
>
0
;
--
i
)
{
const
auto
j
=
static_cast
<
int64_t
>
(
rand64_gen
()
%
(
i
+
1
));
const
auto
i0
=
3
*
i
;
const
auto
j0
=
3
*
j
;
// Swap values.
swap
(
maps
[
i0
],
maps
[
j0
]);
swap
(
maps
[
i0
+
1
],
maps
[
j0
+
1
]);
swap
(
maps
[
i0
+
2
],
maps
[
j0
+
2
]);
}
// Method to deallocate memory.
py
::
capsule
free_when_done
(
maps
,
[](
void
*
mem_
)
{
DocIdx
*
mem
=
reinterpret_cast
<
DocIdx
*>
(
mem_
);
delete
[]
mem
;
});
// Return the numpy array.
const
auto
byte_size
=
sizeof
(
DocIdx
);
return
py
::
array
(
std
::
vector
<
int64_t
>
{
num_samples
,
3
},
// shape
{
3
*
byte_size
,
byte_size
},
// C-style contiguous strides
maps
,
// the data pointer
free_when_done
);
// numpy array references
}
py
::
array
build_mapping
(
const
py
::
array_t
<
int64_t
>&
docs_
,
const
py
::
array_t
<
int
>&
sizes_
,
const
int
num_epochs
,
const
uint64_t
max_num_samples
,
const
int
max_seq_length
,
const
double
short_seq_prob
,
const
int
seed
,
const
bool
verbose
)
{
if
(
sizes_
.
size
()
>
std
::
numeric_limits
<
uint32_t
>::
max
())
{
if
(
verbose
)
{
cout
<<
" using uint64 for data mapping..."
<<
endl
<<
std
::
flush
;
}
return
build_mapping_impl
<
uint64_t
>
(
docs_
,
sizes_
,
num_epochs
,
max_num_samples
,
max_seq_length
,
short_seq_prob
,
seed
,
verbose
);
}
else
{
if
(
verbose
)
{
cout
<<
" using uint32 for data mapping..."
<<
endl
<<
std
::
flush
;
}
return
build_mapping_impl
<
uint32_t
>
(
docs_
,
sizes_
,
num_epochs
,
max_num_samples
,
max_seq_length
,
short_seq_prob
,
seed
,
verbose
);
}
}
template
<
typename
DocIdx
>
py
::
array
build_blocks_mapping_impl
(
const
py
::
array_t
<
int64_t
>&
docs_
,
const
py
::
array_t
<
int32_t
>&
sizes_
,
const
py
::
array_t
<
int32_t
>&
titles_sizes_
,
const
int32_t
num_epochs
,
const
uint64_t
max_num_samples
,
const
int32_t
max_seq_length
,
const
int32_t
seed
,
const
bool
verbose
,
const
bool
use_one_sent_blocks
)
{
/* Build a mapping of (start-index, end-index, sequence-length) where
start and end index are the indices of the sentences in the sample
and sequence-length is the target sequence length.
*/
// Consistency checks.
assert
(
num_epochs
>
0
);
assert
(
max_seq_length
>
1
);
assert
(
seed
>
0
);
// Remove bound checks.
auto
docs
=
docs_
.
unchecked
<
1
>
();
auto
sizes
=
sizes_
.
unchecked
<
1
>
();
auto
titles_sizes
=
titles_sizes_
.
unchecked
<
1
>
();
if
(
verbose
)
{
const
auto
sent_start_index
=
docs
[
0
];
const
auto
sent_end_index
=
docs
[
docs_
.
shape
(
0
)
-
1
];
const
auto
num_sentences
=
sent_end_index
-
sent_start_index
;
cout
<<
" using:"
<<
endl
<<
std
::
flush
;
cout
<<
" number of documents: "
<<
docs_
.
shape
(
0
)
-
1
<<
endl
<<
std
::
flush
;
cout
<<
" sentences range: ["
<<
sent_start_index
<<
", "
<<
sent_end_index
<<
")"
<<
endl
<<
std
::
flush
;
cout
<<
" total number of sentences: "
<<
num_sentences
<<
endl
<<
std
::
flush
;
cout
<<
" number of epochs: "
<<
num_epochs
<<
endl
<<
std
::
flush
;
cout
<<
" maximum number of samples: "
<<
max_num_samples
<<
endl
<<
std
::
flush
;
cout
<<
" maximum sequence length: "
<<
max_seq_length
<<
endl
<<
std
::
flush
;
cout
<<
" seed: "
<<
seed
<<
endl
<<
std
::
flush
;
}
// Mapping and its length (1D).
int64_t
num_samples
=
-
1
;
DocIdx
*
maps
=
NULL
;
// Acceptable number of sentences per block.
int
min_num_sent
=
2
;
if
(
use_one_sent_blocks
)
{
min_num_sent
=
1
;
}
// Perform two iterations, in the first iteration get the size
// and allocate memory and in the second iteration populate the map.
bool
second
=
false
;
for
(
int32_t
iteration
=
0
;
iteration
<
2
;
++
iteration
)
{
// Set the flag on second iteration.
second
=
(
iteration
==
1
);
// Current map index.
uint64_t
map_index
=
0
;
uint64_t
empty_docs
=
0
;
uint64_t
one_sent_docs
=
0
;
uint64_t
long_sent_docs
=
0
;
// For each epoch:
for
(
int32_t
epoch
=
0
;
epoch
<
num_epochs
;
++
epoch
)
{
// assign every block a unique id
int32_t
block_id
=
0
;
if
(
map_index
>=
max_num_samples
)
{
if
(
verbose
&&
(
!
second
))
{
cout
<<
" reached "
<<
max_num_samples
<<
" samples after "
<<
epoch
<<
" epochs ..."
<<
endl
<<
std
::
flush
;
}
break
;
}
// For each document:
for
(
int32_t
doc
=
0
;
doc
<
(
docs
.
shape
(
0
)
-
1
);
++
doc
)
{
// Document sentences are in [sent_index_first, sent_index_last)
const
auto
sent_index_first
=
docs
[
doc
];
const
auto
sent_index_last
=
docs
[
doc
+
1
];
const
auto
target_seq_len
=
max_seq_length
-
titles_sizes
[
doc
];
// At the begining of the document previous index is the
// start index.
auto
prev_start_index
=
sent_index_first
;
// Remaining documents.
auto
num_remain_sent
=
sent_index_last
-
sent_index_first
;
// Some bookkeeping
if
((
epoch
==
0
)
&&
(
!
second
))
{
if
(
num_remain_sent
==
0
)
{
++
empty_docs
;
}
if
(
num_remain_sent
==
1
)
{
++
one_sent_docs
;
}
}
// Detect documents with long sentences.
bool
contains_long_sentence
=
false
;
if
(
num_remain_sent
>=
min_num_sent
)
{
for
(
auto
sent_index
=
sent_index_first
;
sent_index
<
sent_index_last
;
++
sent_index
)
{
if
(
sizes
[
sent_index
]
>
LONG_SENTENCE_LEN
){
if
((
epoch
==
0
)
&&
(
!
second
))
{
++
long_sent_docs
;
}
contains_long_sentence
=
true
;
break
;
}
}
}
// If we have enough sentences and no long sentences.
if
((
num_remain_sent
>=
min_num_sent
)
&&
(
!
contains_long_sentence
))
{
// Set values.
auto
seq_len
=
int32_t
{
0
};
auto
num_sent
=
int32_t
{
0
};
// Loop through sentences.
for
(
auto
sent_index
=
sent_index_first
;
sent_index
<
sent_index_last
;
++
sent_index
)
{
// Add the size and number of sentences.
seq_len
+=
sizes
[
sent_index
];
++
num_sent
;
--
num_remain_sent
;
// If we have reached the target length.
// and there are an acceptable number of sentences left
// and if we have at least the minimum number of sentences.
// or if we have reached end of the document.
if
(((
seq_len
>=
target_seq_len
)
&&
(
num_remain_sent
>=
min_num_sent
)
&&
(
num_sent
>=
min_num_sent
)
)
||
(
num_remain_sent
==
0
))
{
// Populate the map.
if
(
second
)
{
const
auto
map_index_0
=
4
*
map_index
;
// Each sample has 4 items: the starting sentence index, ending sentence index,
// the index of the document from which the block comes (used for fetching titles)
// and the unique id of the block (used for creating block indexes)
maps
[
map_index_0
]
=
static_cast
<
DocIdx
>
(
prev_start_index
);
maps
[
map_index_0
+
1
]
=
static_cast
<
DocIdx
>
(
sent_index
+
1
);
maps
[
map_index_0
+
2
]
=
static_cast
<
DocIdx
>
(
doc
);
maps
[
map_index_0
+
3
]
=
static_cast
<
DocIdx
>
(
block_id
);
}
// Update indices / counters.
++
map_index
;
++
block_id
;
prev_start_index
=
sent_index
+
1
;
seq_len
=
0
;
num_sent
=
0
;
}
}
// for (auto sent_index=sent_index_first; ...
}
// if (num_remain_sent > 1) {
}
// for (int doc=0; doc < num_docs; ++doc) {
}
// for (int epoch=0; epoch < num_epochs; ++epoch) {
if
(
!
second
)
{
if
(
verbose
)
{
cout
<<
" number of empty documents: "
<<
empty_docs
<<
endl
<<
std
::
flush
;
cout
<<
" number of documents with one sentence: "
<<
one_sent_docs
<<
endl
<<
std
::
flush
;
cout
<<
" number of documents with long sentences: "
<<
long_sent_docs
<<
endl
<<
std
::
flush
;
cout
<<
" will create mapping for "
<<
map_index
<<
" samples"
<<
endl
<<
std
::
flush
;
}
assert
(
maps
==
NULL
);
assert
(
num_samples
<
0
);
maps
=
new
DocIdx
[
4
*
map_index
];
num_samples
=
static_cast
<
int64_t
>
(
map_index
);
}
}
// for (int iteration=0; iteration < 2; ++iteration) {
// Shuffle.
// We need a 64 bit random number generator as we might have more
// than 2 billion samples.
std
::
mt19937_64
rand64_gen
(
seed
+
1
);
for
(
auto
i
=
(
num_samples
-
1
);
i
>
0
;
--
i
)
{
const
auto
j
=
static_cast
<
int64_t
>
(
rand64_gen
()
%
(
i
+
1
));
const
auto
i0
=
4
*
i
;
const
auto
j0
=
4
*
j
;
// Swap values.
swap
(
maps
[
i0
],
maps
[
j0
]);
swap
(
maps
[
i0
+
1
],
maps
[
j0
+
1
]);
swap
(
maps
[
i0
+
2
],
maps
[
j0
+
2
]);
swap
(
maps
[
i0
+
3
],
maps
[
j0
+
3
]);
}
// Method to deallocate memory.
py
::
capsule
free_when_done
(
maps
,
[](
void
*
mem_
)
{
DocIdx
*
mem
=
reinterpret_cast
<
DocIdx
*>
(
mem_
);
delete
[]
mem
;
});
// Return the numpy array.
const
auto
byte_size
=
sizeof
(
DocIdx
);
return
py
::
array
(
std
::
vector
<
int64_t
>
{
num_samples
,
4
},
// shape
{
4
*
byte_size
,
byte_size
},
// C-style contiguous strides
maps
,
// the data pointer
free_when_done
);
// numpy array references
}
py
::
array
build_blocks_mapping
(
const
py
::
array_t
<
int64_t
>&
docs_
,
const
py
::
array_t
<
int
>&
sizes_
,
const
py
::
array_t
<
int
>&
titles_sizes_
,
const
int
num_epochs
,
const
uint64_t
max_num_samples
,
const
int
max_seq_length
,
const
int
seed
,
const
bool
verbose
,
const
bool
use_one_sent_blocks
)
{
if
(
sizes_
.
size
()
>
std
::
numeric_limits
<
uint32_t
>::
max
())
{
if
(
verbose
)
{
cout
<<
" using uint64 for data mapping..."
<<
endl
<<
std
::
flush
;
}
return
build_blocks_mapping_impl
<
uint64_t
>
(
docs_
,
sizes_
,
titles_sizes_
,
num_epochs
,
max_num_samples
,
max_seq_length
,
seed
,
verbose
,
use_one_sent_blocks
);
}
else
{
if
(
verbose
)
{
cout
<<
" using uint32 for data mapping..."
<<
endl
<<
std
::
flush
;
}
return
build_blocks_mapping_impl
<
uint32_t
>
(
docs_
,
sizes_
,
titles_sizes_
,
num_epochs
,
max_num_samples
,
max_seq_length
,
seed
,
verbose
,
use_one_sent_blocks
);
}
}
PYBIND11_MODULE
(
helpers
,
m
)
{
m
.
def
(
"build_mapping"
,
&
build_mapping
);
m
.
def
(
"build_blocks_mapping"
,
&
build_blocks_mapping
);
m
.
def
(
"build_sample_idx"
,
&
build_sample_idx
);
}
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/ict_dataset.py
0 → 100644
View file @
316d3f90
import
itertools
import
random
import
numpy
as
np
from
torch.utils.data
import
Dataset
from
megatron
import
get_tokenizer
from
megatron
import
get_args
from
megatron.data.dataset_utils
import
get_indexed_dataset_
from
megatron.data.realm_dataset_utils
import
get_block_samples_mapping
def
get_ict_dataset
(
use_titles
=
True
,
query_in_block_prob
=
1
):
"""Get a dataset which uses block samples mappings to get ICT/block indexing data (via get_block())
rather than for training, since it is only built with a single epoch sample mapping.
"""
args
=
get_args
()
block_dataset
=
get_indexed_dataset_
(
args
.
data_path
,
'mmap'
,
True
)
titles_dataset
=
get_indexed_dataset_
(
args
.
titles_data_path
,
'mmap'
,
True
)
kwargs
=
dict
(
name
=
'full'
,
block_dataset
=
block_dataset
,
title_dataset
=
titles_dataset
,
data_prefix
=
args
.
data_path
,
num_epochs
=
1
,
max_num_samples
=
None
,
max_seq_length
=
args
.
seq_length
,
seed
=
1
,
query_in_block_prob
=
query_in_block_prob
,
use_titles
=
use_titles
,
use_one_sent_docs
=
args
.
use_one_sent_docs
)
dataset
=
ICTDataset
(
**
kwargs
)
return
dataset
class
ICTDataset
(
Dataset
):
"""Dataset containing sentences and their blocks for an inverse cloze task."""
def
__init__
(
self
,
name
,
block_dataset
,
title_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
max_seq_length
,
query_in_block_prob
,
seed
,
use_titles
=
True
,
use_one_sent_docs
=
False
):
self
.
name
=
name
self
.
seed
=
seed
self
.
max_seq_length
=
max_seq_length
self
.
query_in_block_prob
=
query_in_block_prob
self
.
block_dataset
=
block_dataset
self
.
title_dataset
=
title_dataset
self
.
rng
=
random
.
Random
(
self
.
seed
)
self
.
use_titles
=
use_titles
self
.
use_one_sent_docs
=
use_one_sent_docs
self
.
samples_mapping
=
get_block_samples_mapping
(
block_dataset
,
title_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
max_seq_length
,
seed
,
name
,
use_one_sent_docs
)
self
.
tokenizer
=
get_tokenizer
()
self
.
vocab_id_list
=
list
(
self
.
tokenizer
.
inv_vocab
.
keys
())
self
.
vocab_id_to_token_list
=
self
.
tokenizer
.
inv_vocab
self
.
cls_id
=
self
.
tokenizer
.
cls
self
.
sep_id
=
self
.
tokenizer
.
sep
self
.
mask_id
=
self
.
tokenizer
.
mask
self
.
pad_id
=
self
.
tokenizer
.
pad
def
__len__
(
self
):
return
len
(
self
.
samples_mapping
)
def
__getitem__
(
self
,
idx
):
"""Get an ICT example of a pseudo-query and the block of text from which it was extracted"""
sample_data
=
self
.
samples_mapping
[
idx
]
start_idx
,
end_idx
,
doc_idx
,
block_idx
=
sample_data
.
as_tuple
()
if
self
.
use_titles
:
title
=
self
.
title_dataset
[
int
(
doc_idx
)]
title_pad_offset
=
3
+
len
(
title
)
else
:
title
=
None
title_pad_offset
=
2
block
=
[
self
.
block_dataset
[
i
]
for
i
in
range
(
start_idx
,
end_idx
)]
assert
len
(
block
)
>
1
or
self
.
use_one_sent_docs
or
self
.
query_in_block_prob
==
1
# randint() is inclusive for Python rng
rand_sent_idx
=
self
.
rng
.
randint
(
0
,
len
(
block
)
-
1
)
# keep the query in the context query_in_block_prob fraction of the time.
if
self
.
rng
.
random
()
<
self
.
query_in_block_prob
:
query
=
block
[
rand_sent_idx
].
copy
()
else
:
query
=
block
.
pop
(
rand_sent_idx
)
# still need to truncate because blocks are concluded when
# the sentence lengths have exceeded max_seq_length.
query
=
query
[:
self
.
max_seq_length
-
2
]
block
=
list
(
itertools
.
chain
(
*
block
))[:
self
.
max_seq_length
-
title_pad_offset
]
query_tokens
,
query_pad_mask
=
self
.
concat_and_pad_tokens
(
query
)
block_tokens
,
block_pad_mask
=
self
.
concat_and_pad_tokens
(
block
,
title
)
block_data
=
sample_data
.
as_array
()
sample
=
{
'query_tokens'
:
query_tokens
,
'query_pad_mask'
:
query_pad_mask
,
'block_tokens'
:
block_tokens
,
'block_pad_mask'
:
block_pad_mask
,
'block_data'
:
block_data
,
}
return
sample
def
get_block
(
self
,
start_idx
,
end_idx
,
doc_idx
):
"""Get the IDs for an evidence block plus the title of the corresponding document"""
block
=
[
self
.
block_dataset
[
i
]
for
i
in
range
(
start_idx
,
end_idx
)]
title
=
self
.
title_dataset
[
int
(
doc_idx
)]
block
=
list
(
itertools
.
chain
(
*
block
))[:
self
.
max_seq_length
-
(
3
+
len
(
title
))]
block_tokens
,
block_pad_mask
=
self
.
concat_and_pad_tokens
(
block
,
title
)
return
block_tokens
,
block_pad_mask
def
get_null_block
(
self
):
"""Get empty block and title - used in REALM pretraining"""
block
,
title
=
[],
[]
block_tokens
,
block_pad_mask
=
self
.
concat_and_pad_tokens
(
block
,
title
)
return
block_tokens
,
block_pad_mask
def
concat_and_pad_tokens
(
self
,
tokens
,
title
=
None
):
"""Concat with special tokens and pad sequence to self.max_seq_length"""
tokens
=
list
(
tokens
)
if
title
is
None
:
tokens
=
[
self
.
cls_id
]
+
tokens
+
[
self
.
sep_id
]
else
:
title
=
list
(
title
)
tokens
=
[
self
.
cls_id
]
+
title
+
[
self
.
sep_id
]
+
tokens
+
[
self
.
sep_id
]
assert
len
(
tokens
)
<=
self
.
max_seq_length
num_pad
=
self
.
max_seq_length
-
len
(
tokens
)
pad_mask
=
[
1
]
*
len
(
tokens
)
+
[
0
]
*
num_pad
tokens
+=
[
self
.
pad_id
]
*
num_pad
return
np
.
array
(
tokens
),
np
.
array
(
pad_mask
)
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/indexed_dataset.py
0 → 100644
View file @
316d3f90
# Copyright (c) Facebook, Inc. and its affiliates.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
# copied from fairseq/fairseq/data/indexed_dataset.py
# Removed IndexedRawTextDataset since it relied on Fairseq dictionary
# other slight modifications to remove fairseq dependencies
# Added document index to index file and made it accessible.
# An empty sentence no longer separates documents.
from
functools
import
lru_cache
import
os
import
shutil
import
struct
from
itertools
import
accumulate
import
numpy
as
np
import
torch
from
megatron
import
print_rank_0
def
__best_fitting_dtype
(
vocab_size
=
None
):
if
vocab_size
is
not
None
and
vocab_size
<
65500
:
return
np
.
uint16
else
:
return
np
.
int32
def
get_available_dataset_impl
():
return
[
'lazy'
,
'cached'
,
'mmap'
]
def
infer_dataset_impl
(
path
):
if
IndexedDataset
.
exists
(
path
):
with
open
(
index_file_path
(
path
),
'rb'
)
as
f
:
magic
=
f
.
read
(
8
)
if
magic
==
IndexedDataset
.
_HDR_MAGIC
:
return
'cached'
elif
magic
==
MMapIndexedDataset
.
Index
.
_HDR_MAGIC
[:
8
]:
return
'mmap'
else
:
return
None
else
:
print
(
f
"Dataset does not exist:
{
path
}
"
)
print
(
"Path should be a basename that both .idx and .bin can be appended to get full filenames."
)
return
None
def
make_builder
(
out_file
,
impl
,
vocab_size
=
None
):
if
impl
==
'mmap'
:
return
MMapIndexedDatasetBuilder
(
out_file
,
dtype
=
__best_fitting_dtype
(
vocab_size
))
else
:
return
IndexedDatasetBuilder
(
out_file
)
def
make_dataset
(
path
,
impl
,
skip_warmup
=
False
):
if
not
IndexedDataset
.
exists
(
path
):
print
(
f
"Dataset does not exist:
{
path
}
"
)
print
(
"Path should be a basename that both .idx and .bin can be appended to get full filenames."
)
return
None
if
impl
==
'infer'
:
impl
=
infer_dataset_impl
(
path
)
if
impl
==
'lazy'
and
IndexedDataset
.
exists
(
path
):
return
IndexedDataset
(
path
)
elif
impl
==
'cached'
and
IndexedDataset
.
exists
(
path
):
return
IndexedCachedDataset
(
path
)
elif
impl
==
'mmap'
and
MMapIndexedDataset
.
exists
(
path
):
return
MMapIndexedDataset
(
path
,
skip_warmup
)
print
(
f
"Unknown dataset implementation:
{
impl
}
"
)
return
None
def
dataset_exists
(
path
,
impl
):
if
impl
==
'mmap'
:
return
MMapIndexedDataset
.
exists
(
path
)
else
:
return
IndexedDataset
.
exists
(
path
)
def
read_longs
(
f
,
n
):
a
=
np
.
empty
(
n
,
dtype
=
np
.
int64
)
f
.
readinto
(
a
)
return
a
def
write_longs
(
f
,
a
):
f
.
write
(
np
.
array
(
a
,
dtype
=
np
.
int64
))
dtypes
=
{
1
:
np
.
uint8
,
2
:
np
.
int8
,
3
:
np
.
int16
,
4
:
np
.
int32
,
5
:
np
.
int64
,
6
:
np
.
float
,
7
:
np
.
double
,
8
:
np
.
uint16
}
def
code
(
dtype
):
for
k
in
dtypes
.
keys
():
if
dtypes
[
k
]
==
dtype
:
return
k
raise
ValueError
(
dtype
)
def
index_file_path
(
prefix_path
):
return
prefix_path
+
'.idx'
def
data_file_path
(
prefix_path
):
return
prefix_path
+
'.bin'
def
create_doc_idx
(
sizes
):
doc_idx
=
[
0
]
for
i
,
s
in
enumerate
(
sizes
):
if
s
==
0
:
doc_idx
.
append
(
i
+
1
)
return
doc_idx
class
IndexedDataset
(
torch
.
utils
.
data
.
Dataset
):
"""Loader for IndexedDataset"""
_HDR_MAGIC
=
b
'TNTIDX
\x00\x00
'
def
__init__
(
self
,
path
):
super
().
__init__
()
self
.
path
=
path
self
.
data_file
=
None
self
.
read_index
(
path
)
def
read_index
(
self
,
path
):
with
open
(
index_file_path
(
path
),
'rb'
)
as
f
:
magic
=
f
.
read
(
8
)
assert
magic
==
self
.
_HDR_MAGIC
,
(
'Index file doesn
\'
t match expected format. '
'Make sure that --dataset-impl is configured properly.'
)
version
=
f
.
read
(
8
)
assert
struct
.
unpack
(
'<Q'
,
version
)
==
(
1
,)
code
,
self
.
element_size
=
struct
.
unpack
(
'<QQ'
,
f
.
read
(
16
))
self
.
dtype
=
dtypes
[
code
]
self
.
_len
,
self
.
s
=
struct
.
unpack
(
'<QQ'
,
f
.
read
(
16
))
self
.
doc_count
=
struct
.
unpack
(
'<Q'
,
f
.
read
(
8
))
self
.
dim_offsets
=
read_longs
(
f
,
self
.
_len
+
1
)
self
.
data_offsets
=
read_longs
(
f
,
self
.
_len
+
1
)
self
.
sizes
=
read_longs
(
f
,
self
.
s
)
self
.
doc_idx
=
read_longs
(
f
,
self
.
doc_count
)
def
read_data
(
self
,
path
):
self
.
data_file
=
open
(
data_file_path
(
path
),
'rb'
,
buffering
=
0
)
def
check_index
(
self
,
i
):
if
i
<
0
or
i
>=
self
.
_len
:
raise
IndexError
(
'index out of range'
)
def
__del__
(
self
):
if
self
.
data_file
:
self
.
data_file
.
close
()
# @lru_cache(maxsize=8)
def
__getitem__
(
self
,
idx
):
if
not
self
.
data_file
:
self
.
read_data
(
self
.
path
)
if
isinstance
(
idx
,
int
):
i
=
idx
self
.
check_index
(
i
)
tensor_size
=
self
.
sizes
[
self
.
dim_offsets
[
i
]:
self
.
dim_offsets
[
i
+
1
]]
a
=
np
.
empty
(
tensor_size
,
dtype
=
self
.
dtype
)
self
.
data_file
.
seek
(
self
.
data_offsets
[
i
]
*
self
.
element_size
)
self
.
data_file
.
readinto
(
a
)
return
a
elif
isinstance
(
idx
,
slice
):
start
,
stop
,
step
=
idx
.
indices
(
len
(
self
))
if
step
!=
1
:
raise
ValueError
(
"Slices into indexed_dataset must be contiguous"
)
sizes
=
self
.
sizes
[
self
.
dim_offsets
[
start
]:
self
.
dim_offsets
[
stop
]]
size
=
sum
(
sizes
)
a
=
np
.
empty
(
size
,
dtype
=
self
.
dtype
)
self
.
data_file
.
seek
(
self
.
data_offsets
[
start
]
*
self
.
element_size
)
self
.
data_file
.
readinto
(
a
)
offsets
=
list
(
accumulate
(
sizes
))
sents
=
np
.
split
(
a
,
offsets
[:
-
1
])
return
sents
def
__len__
(
self
):
return
self
.
_len
def
num_tokens
(
self
,
index
):
return
self
.
sizes
[
index
]
def
size
(
self
,
index
):
return
self
.
sizes
[
index
]
@
staticmethod
def
exists
(
path
):
return
(
os
.
path
.
exists
(
index_file_path
(
path
))
and
os
.
path
.
exists
(
data_file_path
(
path
))
)
@
property
def
supports_prefetch
(
self
):
return
False
# avoid prefetching to save memory
class
IndexedCachedDataset
(
IndexedDataset
):
def
__init__
(
self
,
path
):
super
().
__init__
(
path
)
self
.
cache
=
None
self
.
cache_index
=
{}
@
property
def
supports_prefetch
(
self
):
return
True
def
prefetch
(
self
,
indices
):
if
all
(
i
in
self
.
cache_index
for
i
in
indices
):
return
if
not
self
.
data_file
:
self
.
read_data
(
self
.
path
)
indices
=
sorted
(
set
(
indices
))
total_size
=
0
for
i
in
indices
:
total_size
+=
self
.
data_offsets
[
i
+
1
]
-
self
.
data_offsets
[
i
]
self
.
cache
=
np
.
empty
(
total_size
,
dtype
=
self
.
dtype
)
ptx
=
0
self
.
cache_index
.
clear
()
for
i
in
indices
:
self
.
cache_index
[
i
]
=
ptx
size
=
self
.
data_offsets
[
i
+
1
]
-
self
.
data_offsets
[
i
]
a
=
self
.
cache
[
ptx
:
ptx
+
size
]
self
.
data_file
.
seek
(
self
.
data_offsets
[
i
]
*
self
.
element_size
)
self
.
data_file
.
readinto
(
a
)
ptx
+=
size
if
self
.
data_file
:
# close and delete data file after prefetch so we can pickle
self
.
data_file
.
close
()
self
.
data_file
=
None
# @lru_cache(maxsize=8)
def
__getitem__
(
self
,
idx
):
if
isinstance
(
idx
,
int
):
i
=
idx
self
.
check_index
(
i
)
tensor_size
=
self
.
sizes
[
self
.
dim_offsets
[
i
]:
self
.
dim_offsets
[
i
+
1
]]
a
=
np
.
empty
(
tensor_size
,
dtype
=
self
.
dtype
)
ptx
=
self
.
cache_index
[
i
]
np
.
copyto
(
a
,
self
.
cache
[
ptx
:
ptx
+
a
.
size
])
return
a
elif
isinstance
(
idx
,
slice
):
# Hack just to make this work, can optimizer later if necessary
sents
=
[]
for
i
in
range
(
*
idx
.
indices
(
len
(
self
))):
sents
.
append
(
self
[
i
])
return
sents
class
IndexedDatasetBuilder
(
object
):
element_sizes
=
{
np
.
uint8
:
1
,
np
.
int8
:
1
,
np
.
int16
:
2
,
np
.
int32
:
4
,
np
.
int64
:
8
,
np
.
float
:
4
,
np
.
double
:
8
}
def
__init__
(
self
,
out_file
,
dtype
=
np
.
int32
):
self
.
out_file
=
open
(
out_file
,
'wb'
)
self
.
dtype
=
dtype
self
.
data_offsets
=
[
0
]
self
.
dim_offsets
=
[
0
]
self
.
sizes
=
[]
self
.
element_size
=
self
.
element_sizes
[
self
.
dtype
]
self
.
doc_idx
=
[
0
]
def
add_item
(
self
,
tensor
):
bytes
=
self
.
out_file
.
write
(
np
.
array
(
tensor
.
numpy
(),
dtype
=
self
.
dtype
))
self
.
data_offsets
.
append
(
self
.
data_offsets
[
-
1
]
+
bytes
/
self
.
element_size
)
for
s
in
tensor
.
size
():
self
.
sizes
.
append
(
s
)
self
.
dim_offsets
.
append
(
self
.
dim_offsets
[
-
1
]
+
len
(
tensor
.
size
()))
def
end_document
(
self
):
self
.
doc_idx
.
append
(
len
(
self
.
sizes
))
def
merge_file_
(
self
,
another_file
):
index
=
IndexedDataset
(
another_file
)
assert
index
.
dtype
==
self
.
dtype
begin
=
self
.
data_offsets
[
-
1
]
for
offset
in
index
.
data_offsets
[
1
:]:
self
.
data_offsets
.
append
(
begin
+
offset
)
self
.
sizes
.
extend
(
index
.
sizes
)
begin
=
self
.
dim_offsets
[
-
1
]
for
dim_offset
in
index
.
dim_offsets
[
1
:]:
self
.
dim_offsets
.
append
(
begin
+
dim_offset
)
with
open
(
data_file_path
(
another_file
),
'rb'
)
as
f
:
while
True
:
data
=
f
.
read
(
1024
)
if
data
:
self
.
out_file
.
write
(
data
)
else
:
break
def
finalize
(
self
,
index_file
):
self
.
out_file
.
close
()
index
=
open
(
index_file
,
'wb'
)
index
.
write
(
b
'TNTIDX
\x00\x00
'
)
index
.
write
(
struct
.
pack
(
'<Q'
,
1
))
index
.
write
(
struct
.
pack
(
'<QQ'
,
code
(
self
.
dtype
),
self
.
element_size
))
index
.
write
(
struct
.
pack
(
'<QQ'
,
len
(
self
.
data_offsets
)
-
1
,
len
(
self
.
sizes
)))
index
.
write
(
struct
.
pack
(
'<Q'
,
len
(
self
.
doc_idx
)))
write_longs
(
index
,
self
.
dim_offsets
)
write_longs
(
index
,
self
.
data_offsets
)
write_longs
(
index
,
self
.
sizes
)
write_longs
(
index
,
self
.
doc_idx
)
index
.
close
()
def
_warmup_mmap_file
(
path
):
with
open
(
path
,
'rb'
)
as
stream
:
while
stream
.
read
(
100
*
1024
*
1024
):
pass
class
MMapIndexedDataset
(
torch
.
utils
.
data
.
Dataset
):
class
Index
(
object
):
_HDR_MAGIC
=
b
'MMIDIDX
\x00\x00
'
@
classmethod
def
writer
(
cls
,
path
,
dtype
):
class
_Writer
(
object
):
def
__enter__
(
self
):
self
.
_file
=
open
(
path
,
'wb'
)
self
.
_file
.
write
(
cls
.
_HDR_MAGIC
)
self
.
_file
.
write
(
struct
.
pack
(
'<Q'
,
1
))
self
.
_file
.
write
(
struct
.
pack
(
'<B'
,
code
(
dtype
)))
return
self
@
staticmethod
def
_get_pointers
(
sizes
):
dtype_size
=
dtype
().
itemsize
address
=
0
pointers
=
[]
for
size
in
sizes
:
pointers
.
append
(
address
)
address
+=
size
*
dtype_size
return
pointers
def
write
(
self
,
sizes
,
doc_idx
):
pointers
=
self
.
_get_pointers
(
sizes
)
self
.
_file
.
write
(
struct
.
pack
(
'<Q'
,
len
(
sizes
)))
self
.
_file
.
write
(
struct
.
pack
(
'<Q'
,
len
(
doc_idx
)))
sizes
=
np
.
array
(
sizes
,
dtype
=
np
.
int32
)
self
.
_file
.
write
(
sizes
.
tobytes
(
order
=
'C'
))
del
sizes
pointers
=
np
.
array
(
pointers
,
dtype
=
np
.
int64
)
self
.
_file
.
write
(
pointers
.
tobytes
(
order
=
'C'
))
del
pointers
doc_idx
=
np
.
array
(
doc_idx
,
dtype
=
np
.
int64
)
self
.
_file
.
write
(
doc_idx
.
tobytes
(
order
=
'C'
))
def
__exit__
(
self
,
exc_type
,
exc_val
,
exc_tb
):
self
.
_file
.
close
()
return
_Writer
()
def
__init__
(
self
,
path
,
skip_warmup
=
False
):
with
open
(
path
,
'rb'
)
as
stream
:
magic_test
=
stream
.
read
(
9
)
assert
self
.
_HDR_MAGIC
==
magic_test
,
(
'Index file doesn
\'
t match expected format. '
'Make sure that --dataset-impl is configured properly.'
)
version
=
struct
.
unpack
(
'<Q'
,
stream
.
read
(
8
))
assert
(
1
,)
==
version
dtype_code
,
=
struct
.
unpack
(
'<B'
,
stream
.
read
(
1
))
self
.
_dtype
=
dtypes
[
dtype_code
]
self
.
_dtype_size
=
self
.
_dtype
().
itemsize
self
.
_len
=
struct
.
unpack
(
'<Q'
,
stream
.
read
(
8
))[
0
]
self
.
_doc_count
=
struct
.
unpack
(
'<Q'
,
stream
.
read
(
8
))[
0
]
offset
=
stream
.
tell
()
if
not
skip_warmup
:
print_rank_0
(
" warming up index mmap file..."
)
_warmup_mmap_file
(
path
)
self
.
_bin_buffer_mmap
=
np
.
memmap
(
path
,
mode
=
'r'
,
order
=
'C'
)
self
.
_bin_buffer
=
memoryview
(
self
.
_bin_buffer_mmap
)
print_rank_0
(
" reading sizes..."
)
self
.
_sizes
=
np
.
frombuffer
(
self
.
_bin_buffer
,
dtype
=
np
.
int32
,
count
=
self
.
_len
,
offset
=
offset
)
print_rank_0
(
" reading pointers..."
)
self
.
_pointers
=
np
.
frombuffer
(
self
.
_bin_buffer
,
dtype
=
np
.
int64
,
count
=
self
.
_len
,
offset
=
offset
+
self
.
_sizes
.
nbytes
)
print_rank_0
(
" reading document index..."
)
self
.
_doc_idx
=
np
.
frombuffer
(
self
.
_bin_buffer
,
dtype
=
np
.
int64
,
count
=
self
.
_doc_count
,
offset
=
offset
+
self
.
_sizes
.
nbytes
+
self
.
_pointers
.
nbytes
)
def
__del__
(
self
):
self
.
_bin_buffer_mmap
.
_mmap
.
close
()
del
self
.
_bin_buffer_mmap
@
property
def
dtype
(
self
):
return
self
.
_dtype
@
property
def
sizes
(
self
):
return
self
.
_sizes
@
property
def
doc_idx
(
self
):
return
self
.
_doc_idx
@
lru_cache
(
maxsize
=
8
)
def
__getitem__
(
self
,
i
):
return
self
.
_pointers
[
i
],
self
.
_sizes
[
i
]
def
__len__
(
self
):
return
self
.
_len
def
__init__
(
self
,
path
,
skip_warmup
=
False
):
super
().
__init__
()
self
.
_path
=
None
self
.
_index
=
None
self
.
_bin_buffer
=
None
self
.
_do_init
(
path
,
skip_warmup
)
def
__getstate__
(
self
):
return
self
.
_path
def
__setstate__
(
self
,
state
):
self
.
_do_init
(
state
)
def
_do_init
(
self
,
path
,
skip_warmup
):
self
.
_path
=
path
self
.
_index
=
self
.
Index
(
index_file_path
(
self
.
_path
),
skip_warmup
)
if
not
skip_warmup
:
print_rank_0
(
" warming up data mmap file..."
)
_warmup_mmap_file
(
data_file_path
(
self
.
_path
))
print_rank_0
(
" creating numpy buffer of mmap..."
)
self
.
_bin_buffer_mmap
=
np
.
memmap
(
data_file_path
(
self
.
_path
),
mode
=
'r'
,
order
=
'C'
)
print_rank_0
(
" creating memory view of numpy buffer..."
)
self
.
_bin_buffer
=
memoryview
(
self
.
_bin_buffer_mmap
)
def
__del__
(
self
):
self
.
_bin_buffer_mmap
.
_mmap
.
close
()
del
self
.
_bin_buffer_mmap
del
self
.
_index
def
__len__
(
self
):
return
len
(
self
.
_index
)
# @lru_cache(maxsize=8)
def
__getitem__
(
self
,
idx
):
if
isinstance
(
idx
,
int
):
ptr
,
size
=
self
.
_index
[
idx
]
np_array
=
np
.
frombuffer
(
self
.
_bin_buffer
,
dtype
=
self
.
_index
.
dtype
,
count
=
size
,
offset
=
ptr
)
return
np_array
elif
isinstance
(
idx
,
slice
):
start
,
stop
,
step
=
idx
.
indices
(
len
(
self
))
if
step
!=
1
:
raise
ValueError
(
"Slices into indexed_dataset must be contiguous"
)
ptr
=
self
.
_index
.
_pointers
[
start
]
sizes
=
self
.
_index
.
_sizes
[
idx
]
offsets
=
list
(
accumulate
(
sizes
))
total_size
=
sum
(
sizes
)
np_array
=
np
.
frombuffer
(
self
.
_bin_buffer
,
dtype
=
self
.
_index
.
dtype
,
count
=
total_size
,
offset
=
ptr
)
sents
=
np
.
split
(
np_array
,
offsets
[:
-
1
])
return
sents
def
get
(
self
,
idx
,
offset
=
0
,
length
=
None
):
""" Retrieves a single item from the dataset with the option to only
return a portion of the item.
get(idx) is the same as [idx] but get() does not support slicing.
"""
ptr
,
size
=
self
.
_index
[
idx
]
if
length
is
None
:
length
=
size
-
offset
ptr
+=
offset
*
np
.
dtype
(
self
.
_index
.
dtype
).
itemsize
np_array
=
np
.
frombuffer
(
self
.
_bin_buffer
,
dtype
=
self
.
_index
.
dtype
,
count
=
length
,
offset
=
ptr
)
return
np_array
@
property
def
sizes
(
self
):
return
self
.
_index
.
sizes
@
property
def
doc_idx
(
self
):
return
self
.
_index
.
doc_idx
def
get_doc_idx
(
self
):
return
self
.
_index
.
_doc_idx
def
set_doc_idx
(
self
,
doc_idx_
):
self
.
_index
.
_doc_idx
=
doc_idx_
@
property
def
supports_prefetch
(
self
):
return
False
@
staticmethod
def
exists
(
path
):
return
(
os
.
path
.
exists
(
index_file_path
(
path
))
and
os
.
path
.
exists
(
data_file_path
(
path
))
)
class
MMapIndexedDatasetBuilder
(
object
):
def
__init__
(
self
,
out_file
,
dtype
=
np
.
int64
):
self
.
_data_file
=
open
(
out_file
,
'wb'
)
self
.
_dtype
=
dtype
self
.
_sizes
=
[]
self
.
_doc_idx
=
[
0
]
def
add_item
(
self
,
tensor
):
np_array
=
np
.
array
(
tensor
.
numpy
(),
dtype
=
self
.
_dtype
)
self
.
_data_file
.
write
(
np_array
.
tobytes
(
order
=
'C'
))
self
.
_sizes
.
append
(
np_array
.
size
)
def
end_document
(
self
):
self
.
_doc_idx
.
append
(
len
(
self
.
_sizes
))
def
merge_file_
(
self
,
another_file
):
# Concatenate index
index
=
MMapIndexedDataset
.
Index
(
index_file_path
(
another_file
))
assert
index
.
dtype
==
self
.
_dtype
for
size
in
index
.
sizes
:
self
.
_sizes
.
append
(
size
)
# Concatenate data
with
open
(
data_file_path
(
another_file
),
'rb'
)
as
f
:
shutil
.
copyfileobj
(
f
,
self
.
_data_file
)
def
finalize
(
self
,
index_file
):
self
.
_data_file
.
close
()
with
MMapIndexedDataset
.
Index
.
writer
(
index_file
,
self
.
_dtype
)
as
index
:
index
.
write
(
self
.
_sizes
,
self
.
_doc_idx
)
Deepspeed/Megatron-LM-v1.1.5-3D_parallelism/megatron/data/realm_dataset_utils.py
0 → 100644
View file @
316d3f90
import
os
import
time
import
numpy
as
np
import
torch
from
megatron
import
mpu
,
print_rank_0
from
megatron.data.dataset_utils
import
create_masked_lm_predictions
,
pad_and_convert_to_numpy
from
megatron.data.samplers
import
DistributedBatchSampler
from
megatron
import
get_args
,
get_tokenizer
,
print_rank_0
,
mpu
def
get_one_epoch_dataloader
(
dataset
,
batch_size
=
None
):
"""Specifically one epoch to be used in an indexing job."""
args
=
get_args
()
world_size
=
mpu
.
get_data_parallel_world_size
()
rank
=
mpu
.
get_data_parallel_rank
()
if
batch_size
is
None
:
batch_size
=
args
.
batch_size
global_batch_size
=
batch_size
*
world_size
num_workers
=
args
.
num_workers
sampler
=
torch
.
utils
.
data
.
SequentialSampler
(
dataset
)
# importantly, drop_last must be False to get all the data.
batch_sampler
=
DistributedBatchSampler
(
sampler
,
batch_size
=
global_batch_size
,
drop_last
=
False
,
rank
=
rank
,
world_size
=
world_size
)
return
torch
.
utils
.
data
.
DataLoader
(
dataset
,
batch_sampler
=
batch_sampler
,
num_workers
=
num_workers
,
pin_memory
=
True
)
def
get_ict_batch
(
data_iterator
):
# Items and their type.
keys
=
[
'query_tokens'
,
'query_pad_mask'
,
'block_tokens'
,
'block_pad_mask'
,
'block_data'
]
datatype
=
torch
.
int64
# Broadcast data.
if
data_iterator
is
None
:
data
=
None
else
:
data
=
next
(
data_iterator
)
data_b
=
mpu
.
broadcast_data
(
keys
,
data
,
datatype
)
# Unpack.
query_tokens
=
data_b
[
'query_tokens'
].
long
()
query_pad_mask
=
data_b
[
'query_pad_mask'
].
long
()
block_tokens
=
data_b
[
'block_tokens'
].
long
()
block_pad_mask
=
data_b
[
'block_pad_mask'
].
long
()
block_indices
=
data_b
[
'block_data'
].
long
()
return
query_tokens
,
query_pad_mask
,
\
block_tokens
,
block_pad_mask
,
block_indices
def
join_str_list
(
str_list
):
"""Join a list of strings, handling spaces appropriately"""
result
=
""
for
s
in
str_list
:
if
s
.
startswith
(
"##"
):
result
+=
s
[
2
:]
else
:
result
+=
" "
+
s
return
result
class
BlockSampleData
(
object
):
"""A struct for fully describing a fixed-size block of data as used in REALM
:param start_idx: for first sentence of the block
:param end_idx: for last sentence of the block (may be partially truncated in sample construction)
:param doc_idx: the index of the document from which the block comes in the original indexed dataset
:param block_idx: a unique integer identifier given to every block.
"""
def
__init__
(
self
,
start_idx
,
end_idx
,
doc_idx
,
block_idx
):
self
.
start_idx
=
start_idx
self
.
end_idx
=
end_idx
self
.
doc_idx
=
doc_idx
self
.
block_idx
=
block_idx
def
as_array
(
self
):
return
np
.
array
([
self
.
start_idx
,
self
.
end_idx
,
self
.
doc_idx
,
self
.
block_idx
]).
astype
(
np
.
int64
)
def
as_tuple
(
self
):
return
self
.
start_idx
,
self
.
end_idx
,
self
.
doc_idx
,
self
.
block_idx
class
BlockSamplesMapping
(
object
):
def
__init__
(
self
,
mapping_array
):
# make sure that the array is compatible with BlockSampleData
assert
mapping_array
.
shape
[
1
]
==
4
self
.
mapping_array
=
mapping_array
def
__len__
(
self
):
return
self
.
mapping_array
.
shape
[
0
]
def
__getitem__
(
self
,
idx
):
"""Get the data associated with an indexed sample."""
sample_data
=
BlockSampleData
(
*
self
.
mapping_array
[
idx
])
return
sample_data
def
get_block_samples_mapping
(
block_dataset
,
title_dataset
,
data_prefix
,
num_epochs
,
max_num_samples
,
max_seq_length
,
seed
,
name
,
use_one_sent_docs
=
False
):
"""Get samples mapping for a dataset over fixed size blocks. This function also requires
a dataset of the titles for the source documents since their lengths must be taken into account.
:return: samples_mapping (BlockSamplesMapping)
"""
if
not
num_epochs
:
if
not
max_num_samples
:
raise
ValueError
(
"Need to specify either max_num_samples "
"or num_epochs"
)
num_epochs
=
np
.
iinfo
(
np
.
int32
).
max
-
1
if
not
max_num_samples
:
max_num_samples
=
np
.
iinfo
(
np
.
int64
).
max
-
1
# Filename of the index mapping
indexmap_filename
=
data_prefix
indexmap_filename
+=
'_{}_indexmap'
.
format
(
name
)
if
num_epochs
!=
(
np
.
iinfo
(
np
.
int32
).
max
-
1
):
indexmap_filename
+=
'_{}ep'
.
format
(
num_epochs
)
if
max_num_samples
!=
(
np
.
iinfo
(
np
.
int64
).
max
-
1
):
indexmap_filename
+=
'_{}mns'
.
format
(
max_num_samples
)
indexmap_filename
+=
'_{}msl'
.
format
(
max_seq_length
)
indexmap_filename
+=
'_{}s'
.
format
(
seed
)
if
use_one_sent_docs
:
indexmap_filename
+=
'_1sentok'
indexmap_filename
+=
'.npy'
# Build the indexed mapping if not exist.
if
mpu
.
get_data_parallel_rank
()
==
0
and
\
not
os
.
path
.
isfile
(
indexmap_filename
):
print
(
' > WARNING: could not find index map file {}, building '
'the indices on rank 0 ...'
.
format
(
indexmap_filename
))
# Make sure the types match the helpers input types.
assert
block_dataset
.
doc_idx
.
dtype
==
np
.
int64
assert
block_dataset
.
sizes
.
dtype
==
np
.
int32
# Build samples mapping
verbose
=
torch
.
distributed
.
get_rank
()
==
0
start_time
=
time
.
time
()
print_rank_0
(
' > building samples index mapping for {} ...'
.
format
(
name
))
# compile/bind the C++ helper code
from
megatron.data.dataset_utils
import
compile_helper
compile_helper
()
from
megatron.data
import
helpers
mapping_array
=
helpers
.
build_blocks_mapping
(
block_dataset
.
doc_idx
,
block_dataset
.
sizes
,
title_dataset
.
sizes
,
num_epochs
,
max_num_samples
,
max_seq_length
-
3
,
# account for added tokens
seed
,
verbose
,
use_one_sent_docs
)
print_rank_0
(
' > done building samples index mapping'
)
np
.
save
(
indexmap_filename
,
mapping_array
,
allow_pickle
=
True
)
print_rank_0
(
' > saved the index mapping in {}'
.
format
(
indexmap_filename
))
# Make sure all the ranks have built the mapping
print_rank_0
(
' > elapsed time to build and save samples mapping '
'(seconds): {:4f}'
.
format
(
time
.
time
()
-
start_time
))
# This should be a barrier but nccl barrier assumes
# device_index=rank which is not the case for model
# parallel case
counts
=
torch
.
cuda
.
LongTensor
([
1
])
torch
.
distributed
.
all_reduce
(
counts
,
group
=
mpu
.
get_data_parallel_group
())
assert
counts
[
0
].
item
()
==
torch
.
distributed
.
get_world_size
(
group
=
mpu
.
get_data_parallel_group
())
# Load indexed dataset.
print_rank_0
(
' > loading indexed mapping from {}'
.
format
(
indexmap_filename
))
start_time
=
time
.
time
()
mapping_array
=
np
.
load
(
indexmap_filename
,
allow_pickle
=
True
,
mmap_mode
=
'r'
)
samples_mapping
=
BlockSamplesMapping
(
mapping_array
)
print_rank_0
(
' loaded indexed file in {:3.3f} seconds'
.
format
(
time
.
time
()
-
start_time
))
print_rank_0
(
' total number of samples: {}'
.
format
(
mapping_array
.
shape
[
0
]))
return
samples_mapping
Prev
1
2
3
4
5
6
7
8
9
…
12
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}

{kind=link}
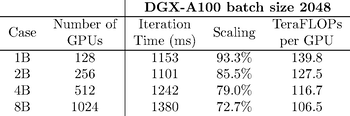
{kind=link}