
增加keras-cv模型及训练代码
Showing
{kind=link}
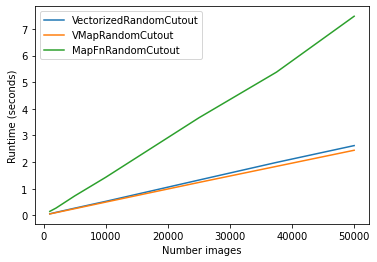
19.1 KB
Keras/keras-cv/.gitignore
0 → 100644
Keras/keras-cv/BUILD.bazel
0 → 100644
Keras/keras-cv/LICENSE
0 → 100644
Keras/keras-cv/MANIFEST.in
0 → 100644
Keras/keras-cv/README.md
0 → 100644
This diff is collapsed.