# Conformer: Local Features Coupling Global Representations for Visual Recognition
**Accpeted to ICCV21!**
This repository is built upon [DeiT](https://github.com/facebookresearch/deit), [timm](https://github.com/rwightman/pytorch-image-models), and [mmdetction](https://github.com/open-mmlab/mmdetection).
# Introduction
Within Convolutional Neural Network (CNN), the convolution operations are good at extracting local features but experience difficulty to capture global representations.
Within visual transformer, the cascaded self-attention modules can capture long-distance feature dependencies but unfortunately deteriorate local feature details.
In this paper, we propose a hybrid network structure, termed Conformer, to take advantage of convolutional operations and self-attention mechanisms for enhanced representation learning.
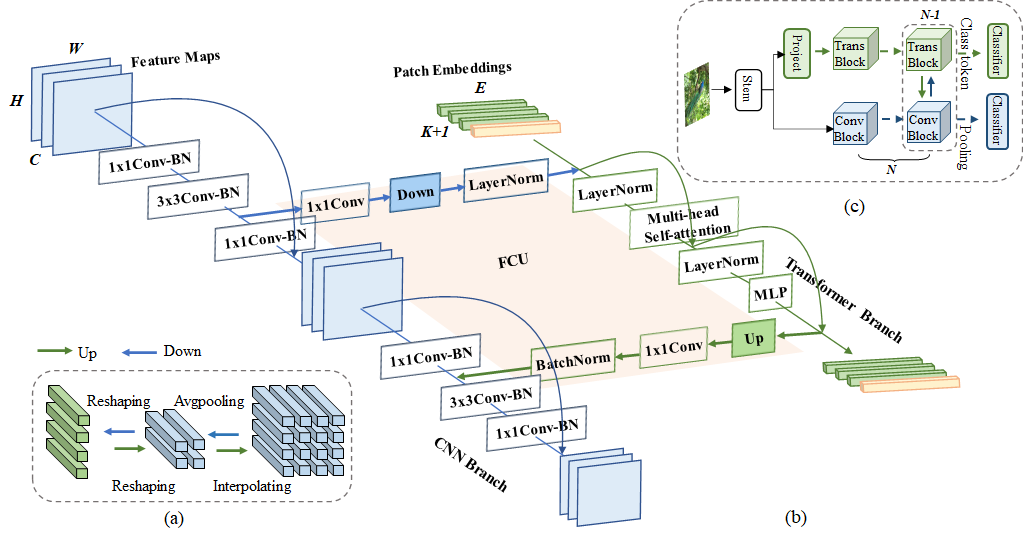
Conformer roots in the Feature Coupling Unit (FCU), which fuses local features and global representations under different resolutions in an interactive fashion.
Conformer adopts a concurrent structure so that local features and global representations are retained to the maximum extent.
Experiments show that Conformer, under the comparable parameter complexity, outperforms the visual transformer (DeiT-B) by 2.3\% on ImageNet.
On MSCOCO, it outperforms ResNet-101 by 3.7\% and 3.6\% mAPs for object detection and instance segmentation, respectively, demonstrating the great potential to be a general backbone network.
The basic architecture of the Conformer is shown as following:

We also show the comparison of feature maps of CNN (ResNet-101), Visual Transformer (DeiT-S), and the proposed Conformer as following.
The patch embeddings in transformer are reshaped to feature maps for visualization. While CNN activates discriminative local regions ($e.g.$, the peacock's head in (a) and tail in (e)),
the CNN branch of Conformer takes advantage of global cues from the visual transformer and thereby activates complete object ($e.g.$, full extent of the peacock in (b) and (f)).
Compared with CNN, local feature details of the visual transformer are deteriorated ($e.g.$, (c) and (g)). In contrast,
the transformer branch of Conformer retains the local feature details from CNN while depressing the background ($e.g.$,
the peacock contours in (d) and (h) are more complete than those in(c) and (g).

# Getting started
## Install
First, install PyTorch 1.7.0+ and torchvision 0.8.1+ and [pytorch-image-models 0.3.2](https://github.com/rwightman/pytorch-image-models):
```
conda install -c pytorch pytorch torchvision
pip install timm==0.3.2
```
## Data preparation
Download and extract ImageNet train and val images from http://image-net.org/.
The directory structure is the standard layout for the torchvision [`datasets.ImageFolder`](https://pytorch.org/docs/stable/torchvision/datasets.html#imagefolder), and the training and validation data is expected to be in the `train/` folder and `val` folder respectively:
```
/path/to/imagenet/
train/
class1/
img1.jpeg
class2/
img2.jpeg
val/
class1/
img3.jpeg
class/2
img4.jpeg
```
## Training and test
### Training
To train Conformer-S on ImageNet on a single node with 8 gpus for 300 epochs run:
All kinds of contributions are welcome, including but not limited to the following.
- Fixes (typo, bugs)
- New features and components
## Workflow
1. fork and pull the latest mmdetection
2. checkout a new branch (do not use master branch for PRs)
3. commit your changes
4. create a PR
Note
- If you plan to add some new features that involve large changes, it is encouraged to open an issue for discussion first.
- If you are the author of some papers and would like to include your method to mmdetection, please let us know (open an issue or contact the maintainers). We will much appreciate your contribution.
- For new features and new modules, unit tests are required to improve the code's robustness.
## Code style
### Python
We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
We use the following tools for linting and formatting:
Thanks for your error report and we appreciate it a lot.
**Checklist**
1. I have searched related issues but cannot get the expected help.
2. I have read the [FAQ documentation](https://mmdetection.readthedocs.io/en/latest/faq.html) but cannot get the expected help.
3. The bug has not been fixed in the latest version.
**Describe the bug**
A clear and concise description of what the bug is.
**Reproduction**
1. What command or script did you run?
```none
A placeholder for the command.
```
2. Did you make any modifications on the code or config? Did you understand what you have modified?
3. What dataset did you use?
**Environment**
1. Please run `python mmdet/utils/collect_env.py` to collect necessary environment information and paste it here.
2. You may add addition that may be helpful for locating the problem, such as
- How you installed PyTorch [e.g., pip, conda, source]
- Other environment variables that may be related (such as `$PATH`, `$LD_LIBRARY_PATH`, `$PYTHONPATH`, etc.)
**Error traceback**
If applicable, paste the error trackback here.
```none
A placeholder for trackback.
```
**Bug fix**
If you have already identified the reason, you can provide the information here. If you are willing to create a PR to fix it, please also leave a comment here and that would be much appreciated!

{kind=link}

{kind=link}