
Initial commit CI/CD
parents
Showing
Too many changes to show.
To preserve performance only 235 of 235+ files are displayed.
IndexKits/setup.py
0 → 100644
LICENSE.txt
0 → 100644
Notice
0 → 100644
README.md
0 → 100644
app/default.png
0 → 100644
{kind=link}

599 KB
app/fail.png
0 → 100644
{kind=link}

732 KB
app/hydit_app.py
0 → 100644
app/lang/en.csv
0 → 100644
app/lang/zh.csv
0 → 100644
app/multiTurnT2I_app.py
0 → 100644
File added
asset/caption_demo.jpg
0 → 100644
{kind=link}

3.36 MB
{kind=link}

5.78 MB
asset/cover.png
0 → 100644
{kind=link}
123 KB
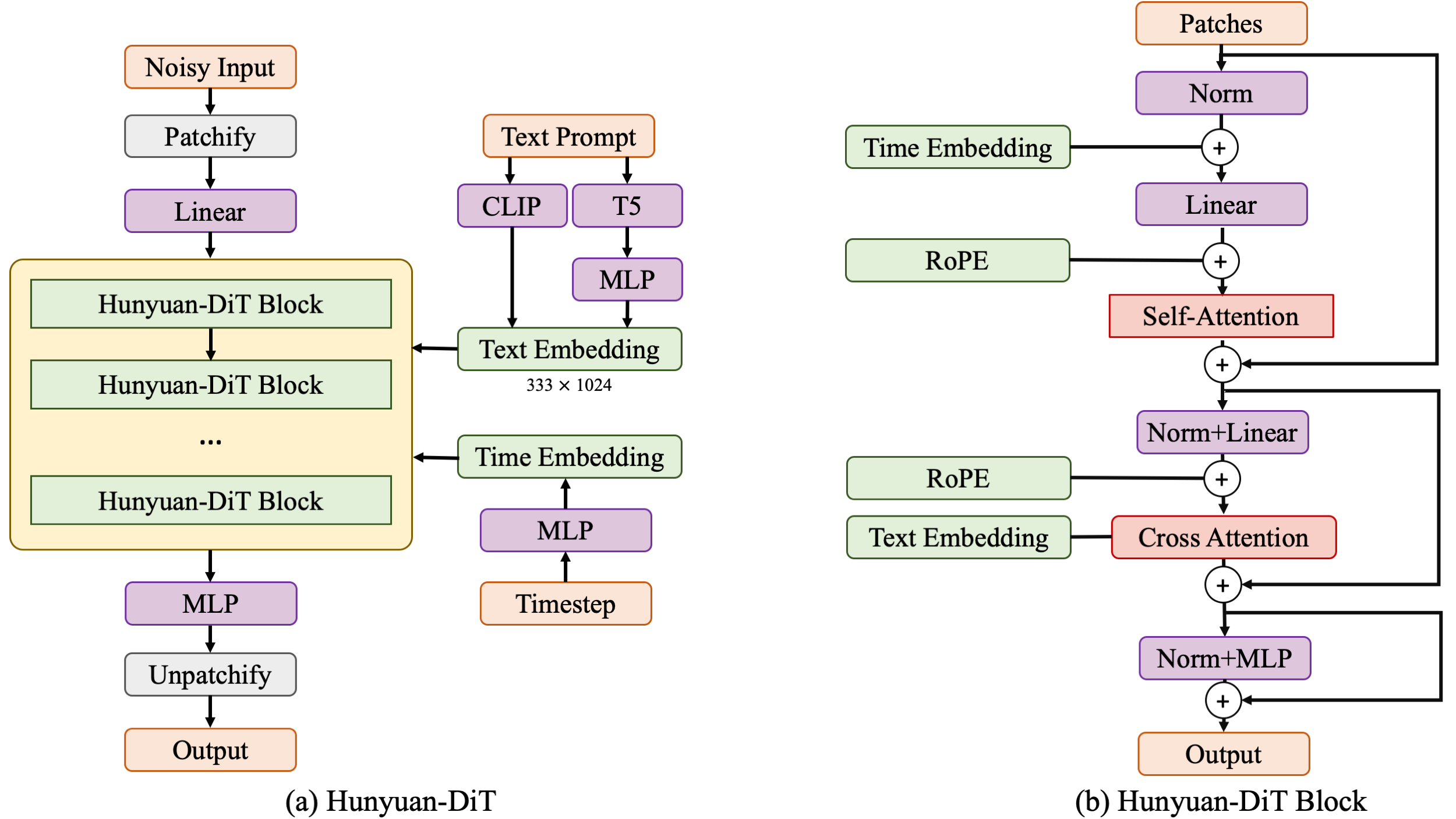
asset/framework.png
0 → 100644
{kind=link}
361 KB
asset/logo.png
0 → 100644
{kind=link}
71.5 KB
{kind=link}

4.91 MB
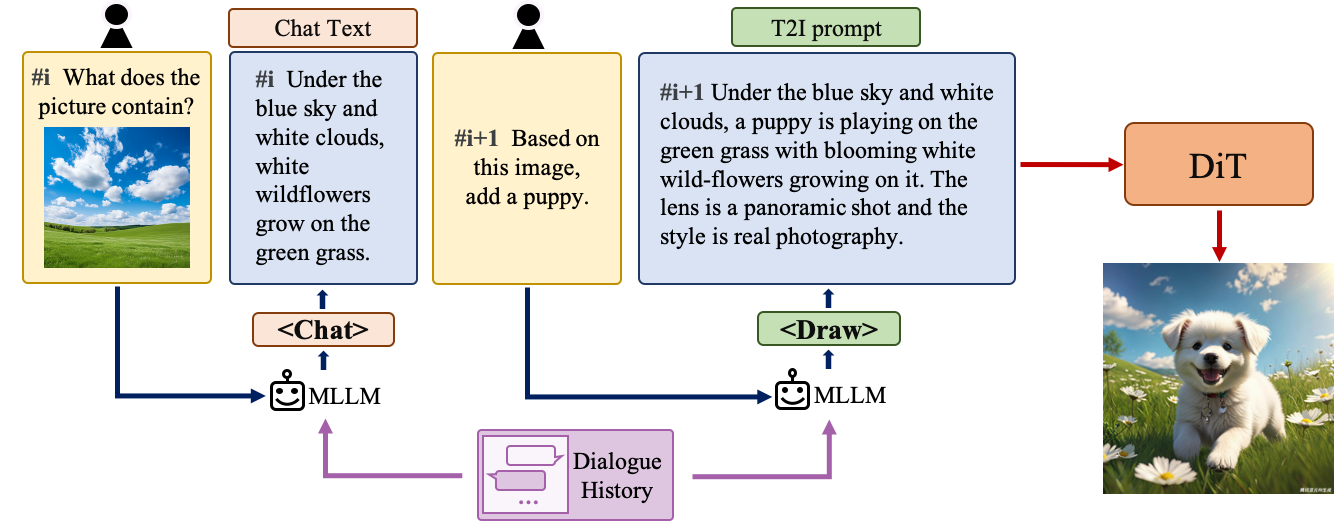
asset/mllm.png
0 → 100644
{kind=link}
290 KB