
初始化仓库
parents
Showing
data/SquadDownloader.py
0 → 100644
data/TextSharding.py
0 → 100644
data/WikiDownloader.py
0 → 100644
data/__init__.py
0 → 100644
data/bertPrep.py
0 → 100644
data/squad/squad_download.sh
0 → 100644
evaluate-v1.1.py
0 → 100644
extract_features.py
0 → 100644
file_utils.py
0 → 100644
images/loss_curves.png
0 → 100644
{kind=link}
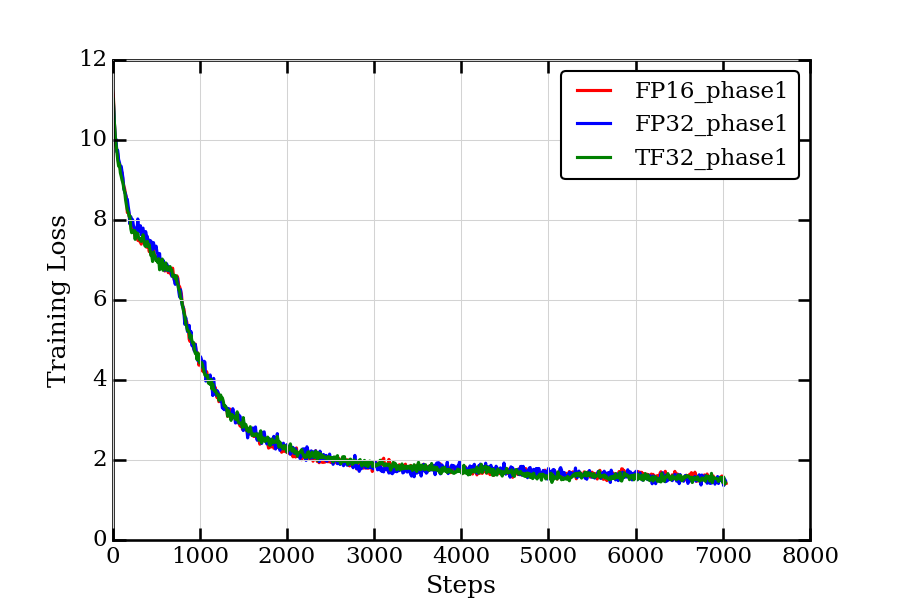
50.2 KB
images/model.png
0 → 100644
{kind=link}
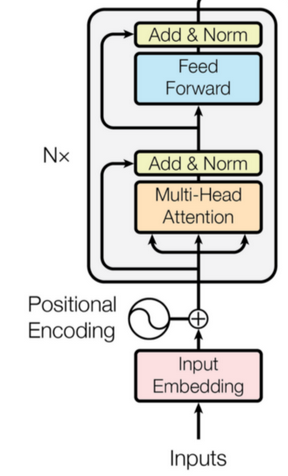
56.5 KB
images/nvlamb.png
0 → 100644
{kind=link}

86.1 KB
inference.py
0 → 100644
log/results-squad-fp16.json
0 → 100644
log/results.json
0 → 100644
modeling.py
0 → 100644
optimization.py
0 → 100644
output/dllogger.json
0 → 100644