# Sentence-BERT
## 论文
`Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks`
- https://arxiv.org/pdf/1908.10084.pdf
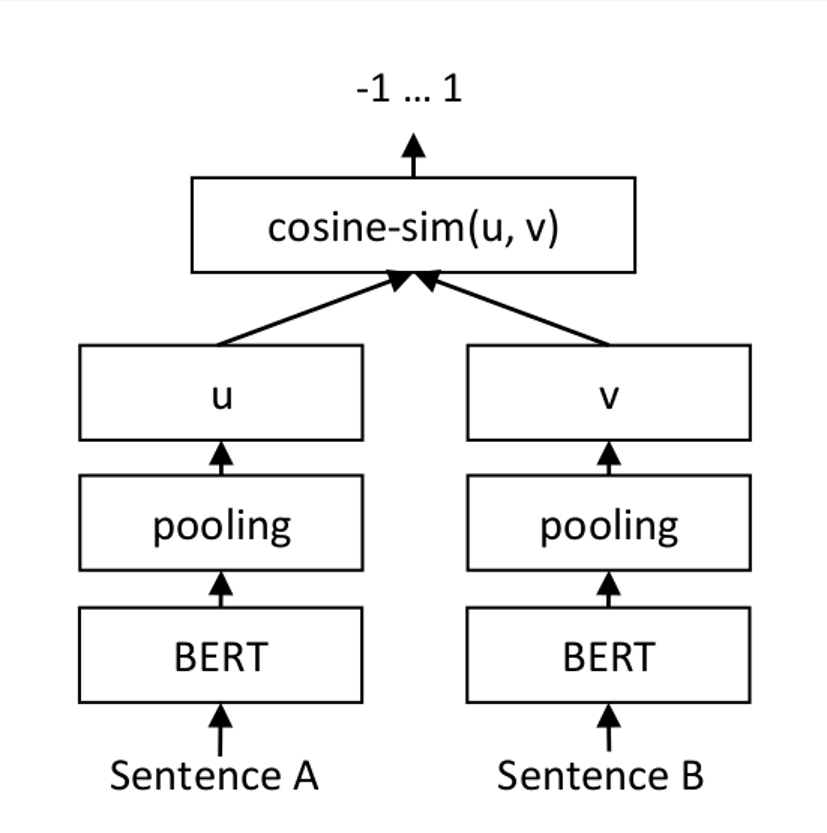
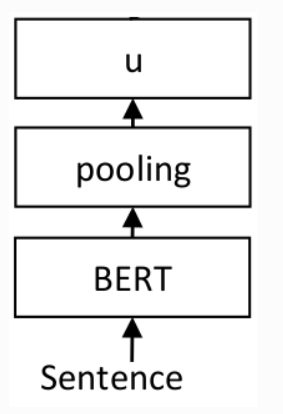
## 模型结构
## 算法原理
对于每个句子对,通过网络传递句子A和句子B,从而得到embeddings u 和 v。使用余弦相似度计算embedding的相似度,并将结果与 gold similarity score进行比较。这允许网络进行微调,并识别句子的相似性.
## 环境配置
1. -v 路径、docker_name和imageID根据实际情况修改
2. transformers文件需要修改:
transformers/trainer_pt_utils.py line 37 修改为:
try:
from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
except ImportError:
from torch.optim.lr_scheduler import LRScheduler as LRScheduler
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-ubuntu20.04-dtk23.10-py38
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/sentence-bert_pytorch
pip install -r requirements.txt
pip install -U sentence-transformers
pip install -e .
```
### Dockerfile(方法二)
```
cd ./docker
cp ../requirements.txt requirements.txt
docker build --no-cache -t sbert:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/sentence-bert_pytorch
pip install -r requirements.txt
pip install -U sentence-transformers
pip install -e .
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```
DTK软件栈:dtk23.10
python:python3.8
torch:1.13.1
torchvision:0.14.1
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
2、其他非特殊库直接按照requirements.txt安装
```
cd /your_code_path/sentence-bert_pytorch
pip install -r requirements.txt
pip install -U sentence-transformers
pip install -e .
```
## 数据集
[sentence-compression](https://huggingface.co/datasets/embedding-data/sentence-compression)
[COCO Captions](https://huggingface.co/datasets/embedding-data/coco_captions_quintets)
[Flickr30k captions](https://huggingface.co/datasets/embedding-data/flickr30k_captions_quintets)
数据集的目录结构如下:
```
├── datasets
│ ├──
│ ├──
│ ├──daybreadwn
│ └──
```
## 训练
### 单机多卡
```
bash train_finetune.sh
```
### 单机单卡
```
python funetune.py
```
## 推理
预训练模型下载[pretrained models](https://www.sbert.net/docs/pretrained_models.html)
```
python infer.py --data_path ./datasets/tmp.txt
```
## result
### 精度
测试数据:[test data]('./datasets/test.txt'), 使用的加速卡:Z100 16G。
根据测试结果情况填写表格:
| xxx | xxx | xxx | xxx | xxx |
| :------: | :------: | :------: | :------: |:------: |
| xxx | xxx | xxx | xxx | xxx |
| xxx | xx | xxx | xxx | xxx |
## 应用场景
### 算法类别
相似度判别
### 热点应用行业
多轮对话
## 源码仓库及问题反馈
-
## 参考资料
-