Given combination of PEFT and Int8 quantization, we would be able to fine_tune a Meta Llama 3 8B model on one consumer grade GPU such as A10.
## Requirements
To run the examples, make sure to install the llama-recipes package (See [README.md](../README.md) for details).
**Please note that the llama-recipes package will install PyTorch 2.0.1 version, in case you want to run FSDP + PEFT, please make sure to install PyTorch nightlies.**
## How to run it?
Get access to a machine with one GPU or if using a multi-GPU machine please make sure to only make one of them visible using `export CUDA_VISIBLE_DEVICES=GPU:id` and run the following. It runs by default with `samsum_dataset` for summarization application.
*`--use_peft` boolean flag to enable PEFT methods in the script
*`--peft_method` to specify the PEFT method, here we use `lora` other options are `llama_adapter`.
*`--quantization` boolean flag to enable int8 quantization
## How to run with different datasets?
Currently 4 datasets are supported that can be found in [Datasets config file](../src/llama_recipes/configs/datasets.py).
*`grammar_dataset` : use this [notebook](../src/llama_recipes/datasets/grammar_dataset/grammar_dataset_process.ipynb) to pull and process theJfleg and C4 200M datasets for grammar checking.
*`alpaca_dataset` : to get this open source data please download the `aplaca.json` to `ft_dataset` folder.
*[Training config file](../src/llama_recipes/configs/training.py) is the main config file that help to specify the settings for our run can be found in
It let us specify the training settings, everything from `model_name` to `dataset_name`, `batch_size` etc. can be set here. Below is the list of supported settings:
peft_method:str="lora"# None, llama_adapter (Caution: llama_adapter is currently not supported with FSDP)
use_peft:bool=False
from_peft_checkpoint:str=""# if not empty and use_peft=True, will load the peft checkpoint and resume the fine-tuning on that checkpoint
output_dir:str="PATH/to/save/PEFT/model"
freeze_layers:bool=False
num_freeze_layers:int=1
quantization:bool=False
one_gpu:bool=False
save_model:bool=True
dist_checkpoint_root_folder:str="PATH/to/save/FSDP/model"# will be used if using FSDP
dist_checkpoint_folder:str="fine-tuned"# will be used if using FSDP
save_optimizer:bool=False# will be used if using FSDP
use_fast_kernels:bool=False# Enable using SDPA from PyTroch Accelerated Transformers, make use Flash Attention and Xformer memory-efficient kernels
use_wandb:bool=False# Enable wandb for experient tracking
save_metrics:bool=False# saves training metrics to a json file for later plotting
flop_counter:bool=False# Enable flop counter to measure model throughput, can not be used with pytorch profiler at the same time.
flop_counter_start:int=3# The step to start profiling, default is 3, which means after 3 steps of warmup stage, the profiler will start to count flops.
use_profiler:bool=False# Enable pytorch profiler, can not be used with flop counter at the same time.
profiler_dir:str="PATH/to/save/profiler/results"# will be used if using profiler
```
*[Datasets config file](../src/llama_recipes/configs/datasets.py) provides the available options for datasets.
*[peft config file](../src/llama_recipes/configs/peft.py) provides the supported PEFT methods and respective settings that can be modified.
## FLOPS Counting and Pytorch Profiling
To help with benchmarking effort, we are adding the support for counting the FLOPS during the fine-tuning process. You can achieve this by setting `--flop_counter` when launching your single/multi GPU fine-tuning. Use `--flop_counter_start` to choose which step to count the FLOPS. It is recommended to allow a warm-up stage before using the FLOPS counter.
Similarly, you can set `--use_profiler` flag and pass a profiling output path using `--profiler_dir` to capture the profile traces of your model using [PyTorch profiler](https://pytorch.org/tutorials/intermediate/tensorboard_profiler_tutorial.html). To get accurate profiling result, the pytorch profiler requires a warm-up stage and the current config is wait=1, warmup=2, active=3, thus the profiler will start the profiling after step 3 and will record the next 3 steps. Therefore, in order to use pytorch profiler, the --max-train-step has been greater than 6. The pytorch profiler would be helpful for debugging purposes. However, the `--flop_counter` and `--use_profiler` can not be used in the same time to ensure the measurement accuracy.
description="Llama-recipes is a companion project to the Llama 2 model. It's goal is to provide examples to quickly get started with fine-tuning for domain adaptation and how to run inference for the fine-tuned models. "
"skip_missing_tokenizer: skip tests when we can not access meta-llama/Llama-2-7b-hf on huggingface hub (Log in with `huggingface-cli login` to unskip).",
[quickstart](./quickstart)|The "Hello World" of using Llama 3, start here if you are new to using Llama 3
[multilingual](./multilingual)|Scripts to add a new language to Llama
[finetuning](./finetuning)|Scripts to finetune Llama 3 on single-GPU and multi-GPU setups
[inference](./inference)|Scripts to deploy Llama 3 for inference [locally](./inference/local_inference/), on mobile [Android](./inference/mobile_inference/android_inference/) and using [model servers](./inference/mobile_inference/)
[use_cases](./use_cases)|Scripts showing common applications of Llama 3
[responsible_ai](./responsible_ai)|Scripts to use PurpleLlama for safeguarding model outputs
[llama_api_providers](./llama_api_providers)|Scripts to run inference on Llama via hosted endpoints
[benchmarks](./benchmarks)|Scripts to benchmark Llama 3 models inference on various backends
[code_llama](./code_llama)|Scripts to run inference with the Code Llama models
[evaluation](./evaluation)|Scripts to evaluate fine-tuned Llama 3 models using `lm-evaluation-harness` from `EleutherAI`
The [`FMBench`](https://github.com/aws-samples/foundation-model-benchmarking-tool/tree/main) tool provides a quick and easy way to benchmark the Llama family of models for price and performance on any AWS service including [`Amazon SagMaker`](https://aws.amazon.com/solutions/guidance/generative-ai-deployments-using-amazon-sagemaker-jumpstart/), [`Amazon Bedrock`](https://aws.amazon.com/bedrock/) or `Amazon EKS` or `Amazon EC2` as `Bring your own endpoint`.
## The need for benchmarking
<!-- markdown-link-check-disable -->
Customers often wonder what is the best AWS service to run Llama models for _my specific use-case_ and _my specific price performance requirements_. While model evaluation metrics are available on several leaderboards ([`HELM`](https://crfm.stanford.edu/helm/lite/latest/#/leaderboard), [`LMSys`](https://chat.lmsys.org/?leaderboard)), but the price performance comparison can be notoriously hard to find and even more harder to trust. In such a scenario, we think it is best to be able to run performance benchmarking yourself on either on your own dataset or on a similar (task wise, prompt size wise) open-source datasets such as ([`LongBench`](https://huggingface.co/datasets/THUDM/LongBench), [`QMSum`](https://paperswithcode.com/dataset/qmsum)). This is the problem that [`FMBench`](https://github.com/aws-samples/foundation-model-benchmarking-tool/tree/main) solves.
<!-- markdown-link-check-enable -->
## [`FMBench`](https://github.com/aws-samples/foundation-model-benchmarking-tool/tree/main): an open-source Python package for FM benchmarking on AWS
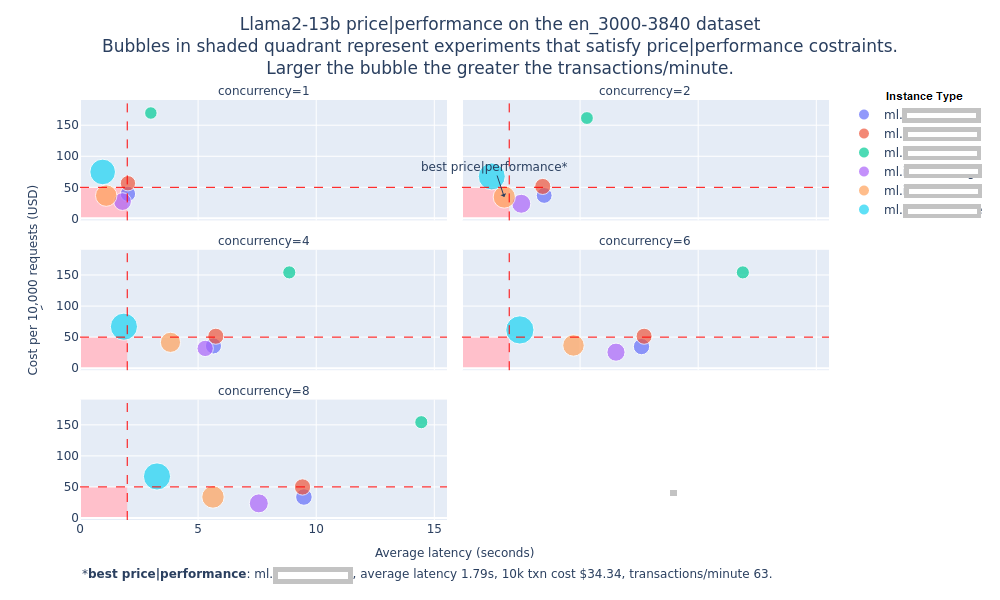
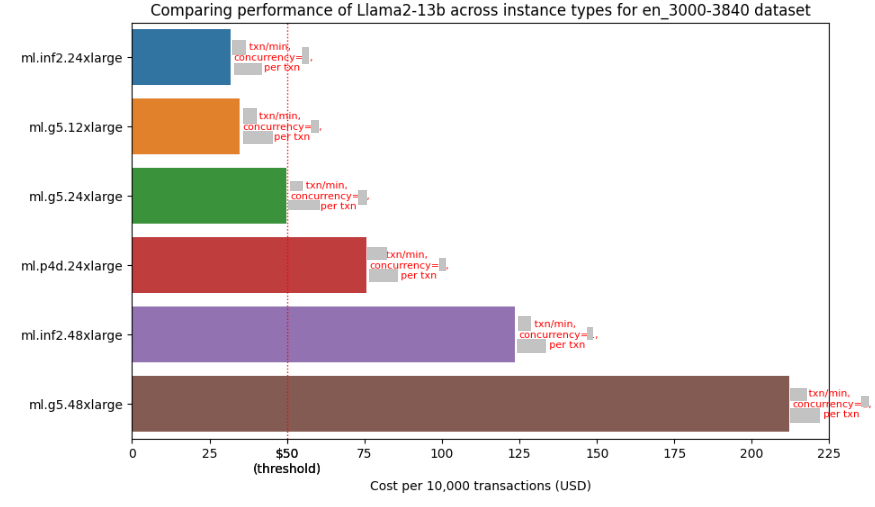
`FMBench` runs inference requests against endpoints that are either deployed through `FMBench` itself (as in the case of SageMaker) or are available either as a fully-managed endpoint (as in the case of Bedrock) or as bring your own endpoint. The metrics such as inference latency, transactions per-minute, error rates and cost per transactions are captured and presented in the form of a Markdown report containing explanatory text, tables and figures. The figures and tables in the report provide insights into what might be the best serving stack (instance type, inference container and configuration parameters) for a given Llama model for a given use-case.
The following figure gives an example of the price performance numbers that include inference latency, transactions per-minute and concurrency level for running the `Llama2-13b` model on different instance types available on SageMaker using prompts for Q&A task created from the [`LongBench`](https://huggingface.co/datasets/THUDM/LongBench) dataset, these prompts are between 3000 to 3840 tokens in length. **_Note that the numbers are hidden in this figure but you would be able to see them when you run `FMBench` yourself_**.

The following table (also included in the report) provides information about the best available instance type for that experiment<sup>1</sup>.
|Information |Value |
|--- |--- |
|experiment_name |llama2-13b-inf2.24xlarge |
|payload_file |payload_en_3000-3840.jsonl |
|instance_type |ml.inf2.24xlarge |
|concurrency |** |
|error_rate |** |
|prompt_token_count_mean |3394 |
|prompt_token_throughput |2400 |
|completion_token_count_mean |31 |
|completion_token_throughput |15 |
|latency_mean |** |
|latency_p50 |** |
|latency_p95 |** |
|latency_p99 |** |
|transactions_per_minute |** |
|price_per_txn |** |
<sup>1</sup>** represent values hidden on purpose, these are available when you run the tool yourself.
The report also includes latency Vs prompt size charts for different concurrency levels. As expected, inference latency increases as prompt size increases but what is interesting to note is that the increase is much more at higher concurrency levels (and this behavior varies with instance types).

### How to get started with `FMBench`
The following steps provide a [Quick start guide for `FMBench`](https://github.com/aws-samples/foundation-model-benchmarking-tool#quickstart). For a more detailed DIY version, please see the [`FMBench Readme`](https://github.com/aws-samples/foundation-model-benchmarking-tool?tab=readme-ov-file#the-diy-version-with-gory-details).
1. Each `FMBench` run works with a configuration file that contains the information about the model, the deployment steps, and the tests to run. A typical `FMBench` workflow involves either directly using an already provided config file from the [`configs`](https://github.com/aws-samples/foundation-model-benchmarking-tool/tree/main/src/fmbench/configs) folder in the `FMBench` GitHub repo or editing an already provided config file as per your own requirements (say you want to try benchmarking on a different instance type, or a different inference container etc.).
>A simple config file with key parameters annotated is included in this repo, see [`config.yml`](./config.yml). This file benchmarks performance of Llama2-7b on an `ml.g5.xlarge` instance and an `ml.g5.2xlarge` instance. You can use this provided config file as it is for this Quickstart.
1. Launch the AWS CloudFormation template included in this repository using one of the buttons from the table below. The CloudFormation template creates the following resources within your AWS account: Amazon S3 buckets, Amazon IAM role and an Amazon SageMaker Notebook with this repository cloned. A read S3 bucket is created which contains all the files (configuration files, datasets) required to run `FMBench` and a write S3 bucket is created which will hold the metrics and reports generated by `FMBench`. The CloudFormation stack takes about 5-minutes to create.
|AWS Region | Link |
|:------------------------:|:-----------:|
|us-east-1 (N. Virginia) | [<img src="./img/CFT.png">](https://console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks/new?stackName=fmbench&templateURL=https://aws-blogs-artifacts-public.s3.amazonaws.com/artifacts/ML-FMBT/template.yml) |
1. Now you are ready to `fmbench` with the following command line. We will use a sample config file placed in the S3 bucket by the CloudFormation stack for a quick first run.
1. We benchmark performance for the `Llama2-7b` model on a `ml.g5.xlarge` and a `ml.g5.2xlarge` instance type, using the `huggingface-pytorch-tgi-inference` inference container. This test would take about 30 minutes to complete and cost about $0.20.
1. It uses a simple relationship that 750 words equals 1000 tokens, to get a more accurate representation of token counts use the `Llama2 tokenizer`. **_It is strongly recommended that for more accurate results on token throughput you use a tokenizer specific to the model you are testing rather than the default tokenizer. See instructions provided [here](https://github.com/aws-samples/foundation-model-benchmarking-tool/tree/main?tab=readme-ov-file#the-diy-version-with-gory-details) on how to use a custom tokenizer_**.
1. Open another terminal window and do a `tail -f` on the `fmbench.log` file to see all the traces being generated at runtime.
```{.bash}
tail -f fmbench.log
```
1. The generated reports and metrics are available in the `sagemaker-fmbench-write-<replace_w_your_aws_region>-<replace_w_your_aws_account_id>` bucket. The metrics and report files are also downloaded locally and in the `results` directory (created by `FMBench`) and the benchmarking report is available as a markdown file called `report.md` in the `results` directory. You can view the rendered Markdown report in the SageMaker notebook itself or download the metrics and report files to your machine for offline analysis.
## 🚨 Benchmarking Llama3 on Amazon Bedrock 🚨
Llama3 is now available on Bedrock (read [blog post](https://aws.amazon.com/blogs/aws/metas-llama-3-models-are-now-available-in-amazon-bedrock/)), and you can now benchmark it using `FMBench`. Here is the config file for benchmarking `Llama3-8b-instruct` and `Llama3-70b-instruct` on Bedrock.
<!-- markdown-link-check-disable -->
-[Config file](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/fmbench/configs/bedrock/config-bedrock-llama3.yml) for `Llama3-8b-instruct` and `Llama3-70b-instruct`.
<!-- markdown-link-check-enable -->
## 🚨 Benchmarking Llama3 on Amazon SageMaker 🚨
Llama3 is now available on SageMaker (read [blog post](https://aws.amazon.com/blogs/machine-learning/meta-llama-3-models-are-now-available-in-amazon-sagemaker-jumpstart/)), and you can now benchmark it using `FMBench`. Here are the config files for benchmarking `Llama3-8b-instruct` and `Llama3-70b-instruct` on `ml.p4d.24xlarge`, `ml.inf2.24xlarge` and `ml.g5.12xlarge` instances.
<!-- markdown-link-check-disable -->
-[Config file](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/fmbench/configs/llama3/8b/config-llama3-8b-instruct-g5-p4d.yml) for `Llama3-8b-instruct` on `ml.p4d.24xlarge` and `ml.g5.12xlarge`.
-[Config file](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/fmbench/configs/llama3/70b/config-llama3-70b-instruct-g5-p4d.yml) for `Llama3-70b-instruct` on `ml.p4d.24xlarge` and `ml.g5.48xlarge`.
-[Config file](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/fmbench/configs/llama3/8b/config-llama3-8b-inf2-g5.yml) for `Llama3-8b-instruct` on `ml.inf2.24xlarge` and `ml.g5.12xlarge`.
<!-- markdown-link-check-enable -->
## Benchmarking Llama2 on Amazon SageMaker
Llama2 models are available through SageMaker JumpStart as well as directly deployable from Hugging Face to a SageMaker endpoint. You can use `FMBench` to benchmark Llama2 on SageMaker for different combinations of instance types and inference containers.
<!-- markdown-link-check-disable -->
-[Config file](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/fmbench/configs/llama2/7b/config-llama2-7b-g5-quick.yml) for `Llama2-7b` on `ml.g5.xlarge` and `ml.g5.2xlarge` instances, using the [Hugging Face TGI container](763104351884.dkr.ecr.us-east-1.amazonaws.com/huggingface-pytorch-tgi-inference:2.0.1-tgi1.1.0-gpu-py39-cu118-ubuntu20.04).
-[Config file](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/fmbench/configs/llama2/7b/config-llama2-7b-g4dn-g5-trt.yml) for `Llama2-7b` on `ml.g4dn.12xlarge` instance using the [Deep Java Library DeepSpeed container](763104351884.dkr.ecr.us-east-1.amazonaws.com/djl-inference:0.26.0-deepspeed0.12.6-cu121).
-[Config file](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/fmbench/configs/llama2/13b/config-llama2-13b-inf2-g5-p4d.yml) for `Llama2-13b` on `ml.g5.12xlarge`, `ml.inf2.24xlarge` and `ml.p4d.24xlarge` instances using the [Hugging Face TGI container](763104351884.dkr.ecr.us-east-1.amazonaws.com/huggingface-pytorch-tgi-inference:2.0.1-tgi1.1.0-gpu-py39-cu118-ubuntu20.04) and the [Deep Java Library & NeuronX container](763104351884.dkr.ecr.us-east-1.amazonaws.com/djl-inference:0.26.0-neuronx-sdk2.16.0).
-[Config file](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/fmbench/configs/llama2/70b/config-llama2-70b-g5-p4d-trt.yml) for `Llama2-70b` on `ml.p4d.24xlarge` instance using the [Deep Java Library TensorRT container](763104351884.dkr.ecr.us-east-1.amazonaws.com/djl-inference:0.26.0-tensorrtllm0.7.1-cu122).
-[Config file](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/fmbench/configs/llama2/70b/config-llama2-70b-inf2-g5.yml) for `Llama2-70b` on `ml.inf2.48xlarge` instance using the [HuggingFace TGI with Optimum NeuronX container](763104351884.dkr.ecr.{region}.amazonaws.com/huggingface-pytorch-tgi-inference:1.13.1-optimum0.0.17-neuronx-py310-ubuntu22.04).
<!-- markdown-link-check-enable -->
## Benchmarking Llama2 on Amazon Bedrock
The Llama2-13b-chat and Llama2-70b-chat models are available on [Bedrock](https://aws.amazon.com/bedrock/llama/). You can use `FMBench` to benchmark Llama2 on Bedrock for both on-demand throughput and provisioned throughput inference options.
<!-- markdown-link-check-disable -->
-[Config file](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/fmbench/configs/bedrock/config-bedrock.yml) for `Llama2-13b-chat` and `Llama2-70b-chat` on Bedrock for on-demand throughput.
<!-- markdown-link-check-enable -->
- For testing provisioned throughput simply replace the `ep_name` parameter in `experiments` section of the config file with the ARN of your provisioned throughput.
## More..
For bug reports, enhancement requests and any questions please create a [GitHub issue](https://github.com/aws-samples/foundation-model-benchmarking-tool/issues) on the `FMBench` repo.
In this folder we provide a series of benchmark scripts that apply a throughput analysis for Llama 2 models inference on various backends:
* On-prem - Popular serving frameworks and containers (i.e. vLLM)
* [**WIP**]Cloud API - Popular API services (i.e. Azure Model-as-a-Service)
* [**WIP**]On-device - Popular on-device inference solutions on Android and iOS (i.e. mlc-llm, QNN)
* [**WIP**]Optimization - Popular optimization solutions for faster inference and quantization (i.e. AutoAWQ)
# Why
There are three major reasons we want to run these benchmarks and share them with our Llama community:
* Provide inference throughput analysis based on real world situation to help you select the best service or deployment for your scenario
* Provide a baseline measurement for validating various optimization solutions on different backends, so we can provide guidance on which solutions work best for your scenario
* Encourage the community to develop benchmarks on top of our works, so we can better quantify the latest proposed solutions combined with current popular frameworks, especially in this crazy fast-moving area
# Parameters
Here are the parameters (if applicable) that you can configure for running the benchmark:
***PROMPT** - Prompt sent in for inference (configure the length of prompt, choose from 5, 25, 50, 100, 500, 1k and 2k)
***MAX_NEW_TOKENS** - Max number of tokens generated
***CONCURRENT_LEVELS** - Max number of concurrent requests
***MODEL_PATH** - Model source
***MODEL_HEADERS** - Request headers
***SAFE_CHECK** - Content safety check (either Azure service or simulated latency)
***THRESHOLD_TPS** - Threshold TPS (threshold for tokens per second below which we deem the query to be slow)
***TOKENIZER_PATH** - Tokenizer source
***RANDOM_PROMPT_LENGTH** - Random prompt length (for pretrained models)
***NUM_GPU** - Number of GPUs for request dispatch among multiple containers
***TEMPERATURE** - Temperature for inference
***TOP_P** - Top_p for inference
***MODEL_ENDPOINTS** - Container endpoints
* Model parallelism or model replicas - Load one model into multiple GPUs or multiple model replicas on one instance. More detail in the README files for specific containers.
You can also configure other model hyperparameters as part of the request payload.
All these parameters are stored in ```parameter.json``` and real prompts are stored in ```input.jsonl```. Running the script will load these configurations.
# Metrics
The benchmark will report these metrics per instance:
* Number of concurrent requests
* P50 Latency(ms)
* P99 Latency(ms)
* Request per second (RPS)
* Output tokens per second
* Output tokens per second per GPU
* Input tokens per second
* Input tokens per second per GPU
* Average tokens per second per request
We intend to add these metrics in the future:
* Time to first token (TTFT)
The benchmark result will be displayed in the terminal output and saved as a CSV file (```performance_metrics.csv```) which you can export to spreadsheets.
# Getting Started
Please follow the ```README.md``` in each subfolder for instructions on how to setup and run these benchmarks.
This folder contains code to run inference benchmark for Llama 2 models on cloud API with popular cloud service providers. The benchmark will focus on overall inference **throughput** for querying the API endpoint for output generation with different level of concurrent requests. Remember that to send queries to the API endpoint, you are required to acquire subscriptions with the cloud service providers and there will be a fee associated with it.
Disclaimer - The purpose of the code is to provide a configurable setup to measure inference throughput. It is not a representative of the performance of these API services and we do not plan to make comparisons between different API providers.
# Azure - Getting Started
To get started, there are certain steps we need to take to deploy the models:
<!-- markdown-link-check-disable -->
* Register for a valid Azure account with subscription [here](https://azure.microsoft.com/en-us/free/search/?ef_id=_k_CjwKCAiA-P-rBhBEEiwAQEXhH5OHAJLhzzcNsuxwpa5c9EJFcuAjeh6EvZw4afirjbWXXWkiZXmU2hoC5GoQAvD_BwE_k_&OCID=AIDcmm5edswduu_SEM__k_CjwKCAiA-P-rBhBEEiwAQEXhH5OHAJLhzzcNsuxwpa5c9EJFcuAjeh6EvZw4afirjbWXXWkiZXmU2hoC5GoQAvD_BwE_k_&gad_source=1&gclid=CjwKCAiA-P-rBhBEEiwAQEXhH5OHAJLhzzcNsuxwpa5c9EJFcuAjeh6EvZw4afirjbWXXWkiZXmU2hoC5GoQAvD_BwE)
<!-- markdown-link-check-enable -->
* Take a quick look on what is the [Azure AI Studio](https://learn.microsoft.com/en-us/azure/ai-studio/what-is-ai-studio?tabs=home) and navigate to the website from the link in the article
* Follow the demos in the article to create a project and [resource](https://learn.microsoft.com/en-us/azure/azure-resource-manager/management/manage-resource-groups-portal) group, or you can also follow the guide [here](https://learn.microsoft.com/en-us/azure/ai-studio/how-to/deploy-models-llama?tabs=azure-studio)
* Select Llama models from Model catalog
* Deploy with "Pay-as-you-go"
Once deployed successfully, you should be assigned for an API endpoint and a security key for inference.
For more information, you should consult Azure's official documentation [here](https://learn.microsoft.com/en-us/azure/ai-studio/how-to/deploy-models-llama?tabs=azure-studio) for model deployment and inference.
Now, replace the endpoint url and API key in ```azure/parameters.json```. For parameter `MODEL_ENDPOINTS`, with chat models the suffix should be `v1/chat/completions` and with pretrained models the suffix should be `v1/completions`.
Note that the API endpoint might implemented a rate limit for token generation in certain amount of time. If you encountered the error, you can try reduce `MAX_NEW_TOKEN` or start with smaller `CONCURRENT_LEVELs`.
Once everything configured, to run chat model benchmark:
```python chat_azure_api_benchmark.py```
To run pretrained model benchmark:
```python pretrained_azure_api_benchmark.py```
Once finished, the result will be written into a CSV file in the same directory, which can be later imported into dashboard of your choice.
print("| Number of Concurrent Requests | P50 Latency (ms) | P99 Latency (ms) | RPS | Output Tokens per Second | Input Tokens per Second | Average Output Tokens per Second per Request | Number of Requests Below Threshold |")
writer.writerow(["Number of Concurrent Requests","P50 Latency (ms)","P99 Latency (ms)","RPS","Output Tokens per Second","Input Tokens per Second","Average Output Tokens per Second per Request"])
"25" : "How does Llama 2 improve text generation, offering coherent, relevant, and contextually appropriate content?",
"50" : "In the context of the rapid evolution of AI, how does the Llama 2 address issues of ethical concerns, bias reduction, and increased performance to generate text that is not only coherent but also culturally sensitive?",
"100" : "As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience?",
"500" : "In AI context as a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience?",
"1k" : "In the context of the AI evolution, as a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience?",
"2k" : "In the context of the evolution of AI, especially in the crazy LLM field, as a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience?"
print("| Number of Concurrent Requests | P50 Latency (ms) | P99 Latency (ms) | RPS | Output Tokens per Second | Input Tokens per Second | Average Output Tokens per Second per Request | Number of Requests Below Threshold |")
writer.writerow(["Number of Concurrent Requests","P50 Latency (ms)","P99 Latency (ms)","RPS","Output Tokens per Second","Input Tokens per Second","Average Output Tokens per Second per Request"])
This folder contains code to run inference benchmark for Meta Llama 3 models on-prem with popular serving frameworks.
The benchmark will focus on overall inference **throughput** for running containers on one instance (single or multiple GPUs) that you can acquire from cloud service providers such as Azure and AWS. You can also run this benchmark on local laptop or desktop.
We support benchmark on these serving framework:
*[vLLM](https://github.com/vllm-project/vllm)
# vLLM - Getting Started
To get started, we first need to deploy containers on-prem as a API host. Follow the guidance [here](../../../inference/model_servers/llama-on-prem.md#setting-up-vllm-with-llama-3) to deploy vLLM on-prem.
Note that in common scenario which overall throughput is important, we suggest you prioritize deploying as many model replicas as possible to reach higher overall throughput and request-per-second (RPS), comparing to deploy one model container among multiple GPUs for model parallelism. Additionally, as deploying multiple model replicas, there is a need for a higher level wrapper to handle the load balancing which here has been simulated in the benchmark scripts.
For example, we have an instance from Azure that has 8xA100 80G GPUs, and we want to deploy the Meta Llama 3 70B instruct model, which is around 140GB with FP16. So for deployment we can do:
* 1x70B model parallel on 8 GPUs, each GPU RAM takes around 17.5GB for loading model weights.
* 2x70B models each use 4 GPUs, each GPU RAM takes around 35GB for loading model weights.
* 4x70B models each use 2 GPUs, each GPU RAM takes around 70GB for loading model weights. (Preferred configuration for max overall throughput. Note that you will have 4 endpoints hosted on different ports and the benchmark script will route requests into each model equally)
Here are examples for deploying 2x70B chat models over 8 GPUs with vLLM.
Once you have finished deployment, you can use the command below to run benchmark scripts in a separate terminal.
```
python chat_vllm_benchmark.py
```
<!-- markdown-link-check-disable -->
If you are going to use [Azure AI content check](https://azure.microsoft.com/en-us/products/ai-services/ai-content-safety), then you should install dependencies as shown below in your terminal:
<!-- markdown-link-check-enable -->
```
pip install azure-ai-contentsafety azure-core
```
Besides chat models, we also provide benchmark scripts for running pretrained models for text completion tasks. To better simulate the real traffic, we generate configurable random token prompt as input. In this process, we select vocabulary that is longer than 2 tokens so the generated words are closer to the English, rather than symbols.
However, random token prompts can't be applied for chat model benchmarks, since the chat model expects a valid question. By feeding random prompts, chat models rarely provide answers that is meeting our ```MAX_NEW_TOKEN``` requirement, defeating the purpose of running throughput benchmarks. Hence for chat models, the questions are copied over to form long inputs such as for 2k and 4k inputs.
To run pretrained model benchmark, follow the command below.
# Simple round-robin to dispatch requests into different containers
executor_id=0
lock=threading.Lock()
defgenerate_text()->Tuple[int,int]:
headers=MODEL_HEADERS
payload={
"model":MODEL_PATH,
"messages":[
{
"role":"user",
"content":PROMPT
}
],
"stream":False,
"temperature":TEMPERATURE,
"top_p":TOP_P,
"max_tokens":MAX_NEW_TOKENS
}
start_time=time.time()
if(SAFE_CHECK):
# Function to send prompts for safety check. Add delays for request round-trip that count towards overall throughput measurement.
# Expect NO returns from calling this function. If you want to check the safety check results, print it out within the function itself.
analyze_prompt(PROMPT)
# Or add delay simulation if you don't want to use Azure Content Safety check. The API round-trip for this check is around 0.3-0.4 seconds depends on where you located. You can use something like this: time.sleep(random.uniform(0.3, 0.4))
# Function to send prompts for safety check. Add delays for request round-trip that count towards overall throughput measurement.
# Expect NO returns from calling this function. If you want to check the safety check results, print it out within the function itself.
analyze_prompt(PROMPT)
# Or add delay simulation if you don't want to use Azure Content Safety check. The API round-trip for this check is around 0.3-0.4 seconds depends on where you located. You can use something like this: time.sleep(random.uniform(0.3, 0.4))
print("| Number of Concurrent Requests | P50 Latency (ms) | P99 Latency (ms) | RPS | Output Tokens per Second | Output Tokens per Second per GPU | Input Tokens per Second | Input Tokens per Second per GPU |Average Output Tokens per Second per Request | Number of Requests Below Threshold |")
writer.writerow(["Number of Concurrent Requests","P50 Latency (ms)","P99 Latency (ms)","RPS","Output Tokens per Second","Output Tokens per Second per GPU","Input Tokens per Second","Input Tokens per Second per GPU","Average Output Tokens per Second per Request"])
"25" : "How does Llama 2 improve text generation, offering coherent, relevant, and contextually appropriate content?",
"50" : "In the context of the rapid evolution of AI, how does the Llama 2 address issues of ethical concerns, bias reduction, and increased performance to generate text that is not only coherent but also culturally sensitive?",
"100" : "As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience?",
"500" : "In AI context as a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience?",
"1k" : "In the context of the AI evolution, as a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience?",
"2k" : "In the context of the evolution of AI, especially in the crazy LLM field, as a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience? As a sophisticated large language model, how does Llama 2 balance the intricate dance of producing highly coherent, contextually rich text while navigating ethical considerations, biases, and the imperative need for inclusivity and diversity? Furthermore, how does it ensure that the generated content adheres to global communication standards and respects cultural sensitivities, offering tailored experiences that are both engaging and respectful to a diverse audience?"
# Simple round-robin to dispatch requests into different containers
executor_id=0
lock=threading.Lock()
defgenerate_text()->Tuple[int,int]:
headers=MODEL_HEADERS
payload={
"model":MODEL_PATH,
"messages":[
{
"role":"user",
"content":PROMPT
}
],
"stream":False,
"temperature":TEMPERATURE,
"top_p":TOP_P,
"max_tokens":MAX_NEW_TOKENS
}
start_time=time.time()
if(SAFE_CHECK):
# Function to send prompts for safety check. Add delays for request round-trip that count towards overall throughput measurement.
# Expect NO returns from calling this function. If you want to check the safety check results, print it out within the function itself.
analyze_prompt(PROMPT)
# Or add delay simulation if you don't want to use Azure Content Safety check. The API round-trip for this check is around 0.3-0.4 seconds depends on where you located. You can use something like this: time.sleep(random.uniform(0.3, 0.4))
# Function to send prompts for safety check. Add delays for request round-trip that count towards overall throughput measurement.
# Expect NO returns from calling this function. If you want to check the safety check results, print it out within the function itself.
analyze_prompt(PROMPT)
# Or add delay simulation if you don't want to use Azure Content Safety check. The API round-trip for this check is around 0.3-0.4 seconds depends on where you located. You can use something like this: time.sleep(random.uniform(0.3, 0.4))
print("| Number of Concurrent Requests | P50 Latency (ms) | P99 Latency (ms) | RPS | Output Tokens per Second | Output Tokens per Second per GPU | Input Tokens per Second | Input Tokens per Second per GPU |Average Output Tokens per Second per Request | Number of Requests Below Threshold |")
writer.writerow(["Number of Concurrent Requests","P50 Latency (ms)","P99 Latency (ms)","RPS","Output Tokens per Second","Output Tokens per Second per GPU","Input Tokens per Second","Input Tokens per Second per GPU","Average Output Tokens per Second per Request"])

{kind=link}

{kind=link}
{kind=link}
{kind=link}
