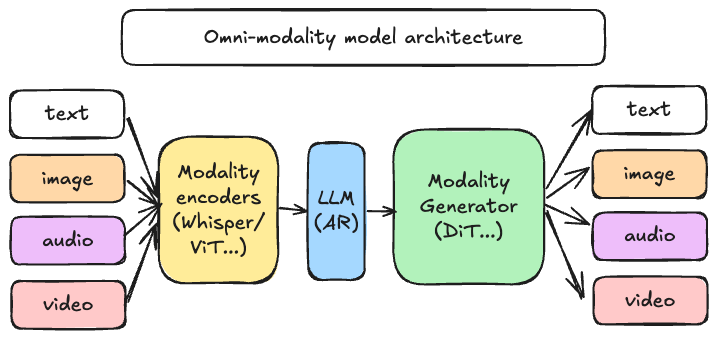
## About
[vLLM](https://github.com/vllm-project/vllm) was originally designed to support large language models for text-based autoregressive generation tasks. vLLM-Omni is a framework that extends its support for omni-modality model inference and serving:
- **Omni-modality**: Text, image, video, and audio data processing
- **Non-autoregressive Architectures**: extend the AR support of vLLM to Diffusion Transformers (DiT) and other parallel generation models
- **Heterogeneous outputs**: from traditional text generation to multimodal outputs
vLLM-Omni is fast with:
- State-of-the-art AR support by leveraging efficient KV cache management from vLLM
- Pipelined stage execution overlapping for high throughput performance
- Fully disaggregation based on OmniConnector and dynamic resource allocation across stages
vLLM-Omni is flexible and easy to use with:
- Heterogeneous pipeline abstraction to manage complex model workflows
- Seamless integration with popular Hugging Face models
- Tensor, pipeline, data and expert parallelism support for distributed inference
- Streaming outputs
- OpenAI-compatible API server
vLLM-Omni seamlessly supports most popular open-source models on HuggingFace, including:
- Omni-modality models (e.g. Qwen2.5-Omni, Qwen3-Omni)
- Multi-modality generation models (e.g. Qwen-Image)
For more information, checkout the following:
- [vllm-omni architecture design and recent roadmaps](https://docs.google.com/presentation/d/1qv4qMW1rKAqDREMXiUDLIgqqHQe7TDPj/edit?usp=sharing&ouid=110473603432222024453&rtpof=true&sd=true)
- [vllm-omni announcement blogpost](https://blog.vllm.ai/2025/11/30/vllm-omni.html)