
vllm-omni_0.15.0.rc1+fix1 first commit
Showing
Too many changes to show.
To preserve performance only 306 of 306+ files are displayed.
{kind=link}
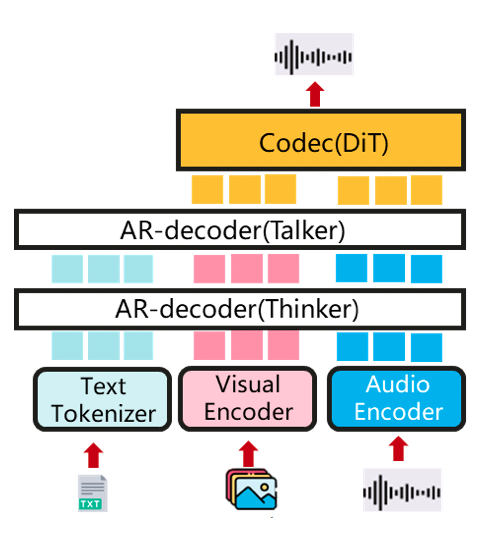
107 KB
{kind=link}
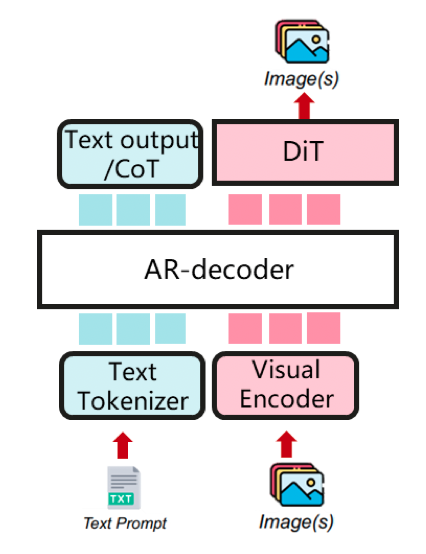
96.6 KB
{kind=link}
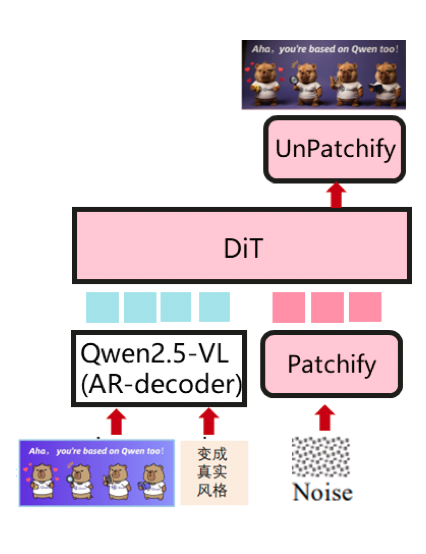
126 KB
{kind=link}
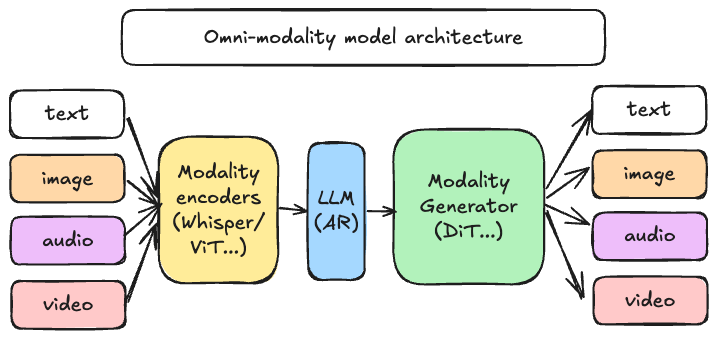
52.8 KB
{kind=link}

127 KB
{kind=link}

316 KB
{kind=link}
367 KB
{kind=link}
480 KB
16.6 KB
{kind=link}
41 KB
docs/usage/faq.md
0 → 100644