# BERT (base-multilingual-cased) fine-tuned on XQuAD
This model was created by [Google](https://github.com/google-research/bert/blob/master/multilingual.md) and fine-tuned on [XQuAD](https://github.com/deepmind/xquad) for multilingual (`11 different languages`) **Q&A** downstream task.
## Details of the language model('bert-base-multilingual-cased')
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
```
</details>
I used `Data augmentation techniques` and splited the dataset in order to have a train and test set. The test set was created in a way that contains the same number of samples for each language. Finally, I got:
| Dataset | # samples |
| ----------- | --------- |
| XQUAD train | 50 K |
| XQUAD test | 8 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py)
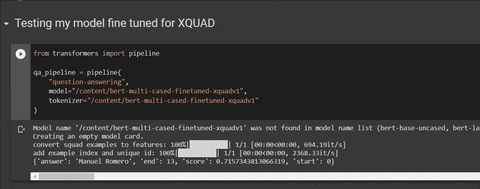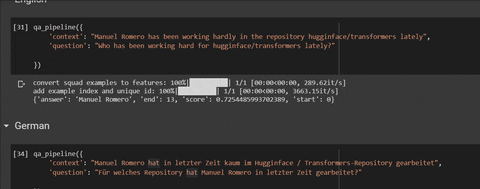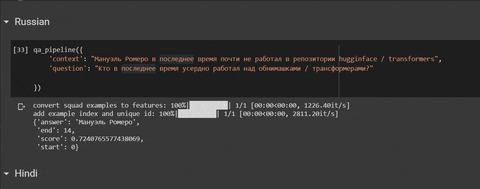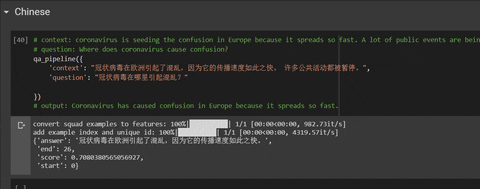
Try it on a Colab:
<ahref="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Try_mrm8488_xquad_finetuned_model.ipynb"target="_parent"><imgsrc="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667"alt="Open In Colab"data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
