`arabic-bert-base` model was pretrained on ~8.2 Billion words:
- Arabic version of [OSCAR](https://traces1.inria.fr/oscar/) - filtered from [Common Crawl](http://commoncrawl.org/)
- Recent dump of Arabic [Wikipedia](https://dumps.wikimedia.org/backup-index.html)
and other Arabic resources which sum up to ~95GB of text.
__Notes on training data:__
- Our final version of corpus contains some non-Arabic words inlines, which we did not remove from sentences since that would affect some tasks like NER.
- Although non-Arabic characters were lowered as a preprocessing step, since Arabic characters does not have upper or lower case, there is no cased and uncased version of the model.
- The corpus and vocabulary set are not restricted to Modern Standard Arabic, they contain some dialectical Arabic too.
## Pretraining details
- This model was trained using Google BERT's github [repository](https://github.com/google-research/bert) on a single TPU v3-8 provided for free from [TFRC](https://www.tensorflow.org/tfrc).
- Our pretraining procedure follows training settings of bert with some changes: trained for 3M training steps with batchsize of 128, instead of 1M with batchsize of 256.
## Load Pretrained Model
You can use this model by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
# AraBERT : Pre-training BERT for Arabic Language Understanding
**AraBERT** is an Arabic pretrained lanaguage model based on [Google's BERT architechture](https://github.com/google-research/bert). AraBERT uses the same BERT-Base config.
There are two version off the model AraBERTv0.1 and AraBERTv1, with the difference being that AraBERTv1 uses pre-segmented text where prefixes and suffixes were splitted using the [Farasa Segmenter](http://alt.qcri.org/farasa/segmenter.html).
The model was trained on ~70M sentences or ~23GB of Arabic text with ~3B words. The training corpora are a collection of publically available large scale raw arabic text ([Arabic Wikidumps](https://archive.org/details/arwiki-20190201), [The 1.5B words Arabic Corpus](https://www.semanticscholar.org/paper/1.5-billion-words-Arabic-Corpus-El-Khair/f3eeef4afb81223df96575adadf808fe7fe440b4), [The OSIAN Corpus](https://www.aclweb.org/anthology/W19-4619), Assafir news articles, and 4 other manually crawled news websites (Al-Akhbar, Annahar, AL-Ahram, AL-Wafd) from [the Wayback Machine](http://web.archive.org/))
We evalaute both AraBERT models on different downstream tasks and compare it to [mBERT]((https://github.com/google-research/bert/blob/master/multilingual.md)), and other state of the art models (*To the extent of our knowledge*). The Tasks were Sentiment Analysis on 6 different datasets ([HARD](https://github.com/elnagara/HARD-Arabic-Dataset), [ASTD-Balanced](https://www.aclweb.org/anthology/D15-1299), [ArsenTD-Lev](https://staff.aub.edu.lb/~we07/Publications/ArSentD-LEV_Sentiment_Corpus.pdf), [LABR](https://github.com/mohamedadaly/LABR), [ArSaS](http://lrec-conf.org/workshops/lrec2018/W30/pdf/22_W30.pdf)), Named Entity Recognition with the [ANERcorp](http://curtis.ml.cmu.edu/w/courses/index.php/ANERcorp), and Arabic Question Answering on [Arabic-SQuAD and ARCD](https://github.com/husseinmozannar/SOQAL)
## Results (Acc.)
Task | prev. SOTA | mBERT | AraBERTv0.1 | AraBERTv1
---|:---:|:---:|:---:|:---:
HARD |95.7 [ElJundi et.al.](https://www.aclweb.org/anthology/W19-4608/)|95.7|96.2|96.1
*We would be extremly thankful if everyone can contibute to the Results table by adding more scores on different datasets*
## How to use
You can easily use AraBERT since it is almost fully compatible with existing codebases (You can use this repo instead of the official BERT one, the only difference is in the ```tokenization.py``` file where we modify the _is_punctuation function to make it compatible with the "+" symbol and the "[" and "]" characters)
To use HuggingFace's Transformer repository you only need to provide a lost of token that forces the model to not split them, also make sure that the text is pre-segmented:
**You can find the PyTorch models in HuggingFace's Transformer Library under the ```aubmindlab``` username**
## If you used this model please cite us as:
```
@misc{antoun2020arabert,
title={AraBERT: Transformer-based Model for Arabic Language Understanding},
author={Wissam Antoun and Fady Baly and Hazem Hajj},
year={2020},
eprint={2003.00104},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access.
***We are looking for sponsors to train BERT-Large and other Transformer models, the sponsor only needs to cover to data storage and compute cost of the generating the pretraining data***
# AraBERT : Pre-training BERT for Arabic Language Understanding
**AraBERT** is an Arabic pretrained lanaguage model based on [Google's BERT architechture](https://github.com/google-research/bert). AraBERT uses the same BERT-Base config.
There are two version off the model AraBERTv0.1 and AraBERTv1, with the difference being that AraBERTv1 uses pre-segmented text where prefixes and suffixes were splitted using the [Farasa Segmenter](http://alt.qcri.org/farasa/segmenter.html).
The model was trained on ~70M sentences or ~23GB of Arabic text with ~3B words. The training corpora are a collection of publically available large scale raw arabic text ([Arabic Wikidumps](https://archive.org/details/arwiki-20190201), [The 1.5B words Arabic Corpus](https://www.semanticscholar.org/paper/1.5-billion-words-Arabic-Corpus-El-Khair/f3eeef4afb81223df96575adadf808fe7fe440b4), [The OSIAN Corpus](https://www.aclweb.org/anthology/W19-4619), Assafir news articles, and 4 other manually crawled news websites (Al-Akhbar, Annahar, AL-Ahram, AL-Wafd) from [the Wayback Machine](http://web.archive.org/))
We evalaute both AraBERT models on different downstream tasks and compare it to [mBERT]((https://github.com/google-research/bert/blob/master/multilingual.md)), and other state of the art models (*To the extent of our knowledge*). The Tasks were Sentiment Analysis on 6 different datasets ([HARD](https://github.com/elnagara/HARD-Arabic-Dataset), [ASTD-Balanced](https://www.aclweb.org/anthology/D15-1299), [ArsenTD-Lev](https://staff.aub.edu.lb/~we07/Publications/ArSentD-LEV_Sentiment_Corpus.pdf), [LABR](https://github.com/mohamedadaly/LABR), [ArSaS](http://lrec-conf.org/workshops/lrec2018/W30/pdf/22_W30.pdf)), Named Entity Recognition with the [ANERcorp](http://curtis.ml.cmu.edu/w/courses/index.php/ANERcorp), and Arabic Question Answering on [Arabic-SQuAD and ARCD](https://github.com/husseinmozannar/SOQAL)
## Results (Acc.)
Task | prev. SOTA | mBERT | AraBERTv0.1 | AraBERTv1
---|:---:|:---:|:---:|:---:
HARD |95.7 [ElJundi et.al.](https://www.aclweb.org/anthology/W19-4608/)|95.7|96.2|96.1
*We would be extremly thankful if everyone can contibute to the Results table by adding more scores on different datasets*
## How to use
You can easily use AraBERT since it is almost fully compatible with existing codebases (You can use this repo instead of the official BERT one, the only difference is in the ```tokenization.py``` file where we modify the _is_punctuation function to make it compatible with the "+" symbol and the "[" and "]" characters)
To use HuggingFace's Transformer repository you only need to provide a lost of token that forces the model to not split them, also make sure that the text is pre-segmented:
**You can find the PyTorch models in HuggingFace's Transformer Library under the ```aubmindlab``` username**
## If you used this model please cite us as:
```
@misc{antoun2020arabert,
title={AraBERT: Transformer-based Model for Arabic Language Understanding},
author={Wissam Antoun and Fady Baly and Hazem Hajj},
year={2020},
eprint={2003.00104},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access.
***We are looking for sponsors to train BERT-Large and other Transformer models, the sponsor only needs to cover to data storage and compute cost of the generating the pretraining data***
'context':"Claude Monet, né le 14 novembre 1840 à Paris et mort le 5 décembre 1926 à Giverny, est un peintre français et l’un des fondateurs de l'impressionnisme."
A baseline model for question-answering in french ([CamemBERT](https://camembert-model.fr/) model fine-tuned on [french-translated SQuAD 1.1 dataset](https://github.com/Alikabbadj/French-SQuAD))
'context':"Claude Monet, né le 14 novembre 1840 à Paris et mort le 5 décembre 1926 à Giverny, est un peintre français et l’un des fondateurs de l'impressionnisme."
# BERT (base-multilingual-cased) fine-tuned on XQuAD
This model was created by [Google](https://github.com/google-research/bert/blob/master/multilingual.md) and fine-tuned on [XQuAD](https://github.com/deepmind/xquad) for multilingual (`11 different languages`) **Q&A** downstream task.
## Details of the language model('bert-base-multilingual-cased')
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
```
</details>
I used `Data augmentation techniques` and splited the dataset in order to have a train and test set. The test set was created in a way that contains the same number of samples for each language. Finally, I got:
| Dataset | # samples |
| ----------- | --------- |
| XQUAD train | 50 K |
| XQUAD test | 8 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py)
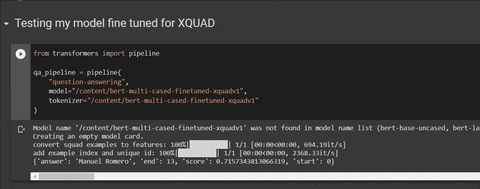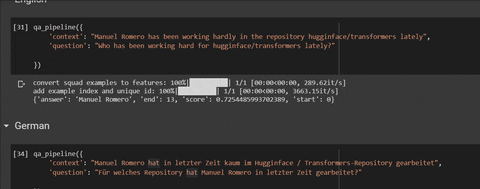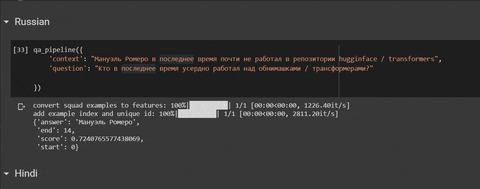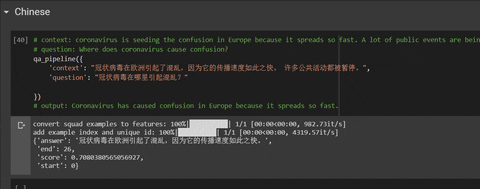
Try it on a Colab:
<ahref="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Try_mrm8488_xquad_finetuned_model.ipynb"target="_parent"><imgsrc="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667"alt="Open In Colab"data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
