
Initial commit
Showing
.gitignore
0 → 100644
LICENSE.txt
0 → 100644
Notice
0 → 100644
README.md
0 → 100644
README_zh.md
0 → 100644
assets/WECHAT.md
0 → 100644
assets/backbone.png
0 → 100644
{kind=link}
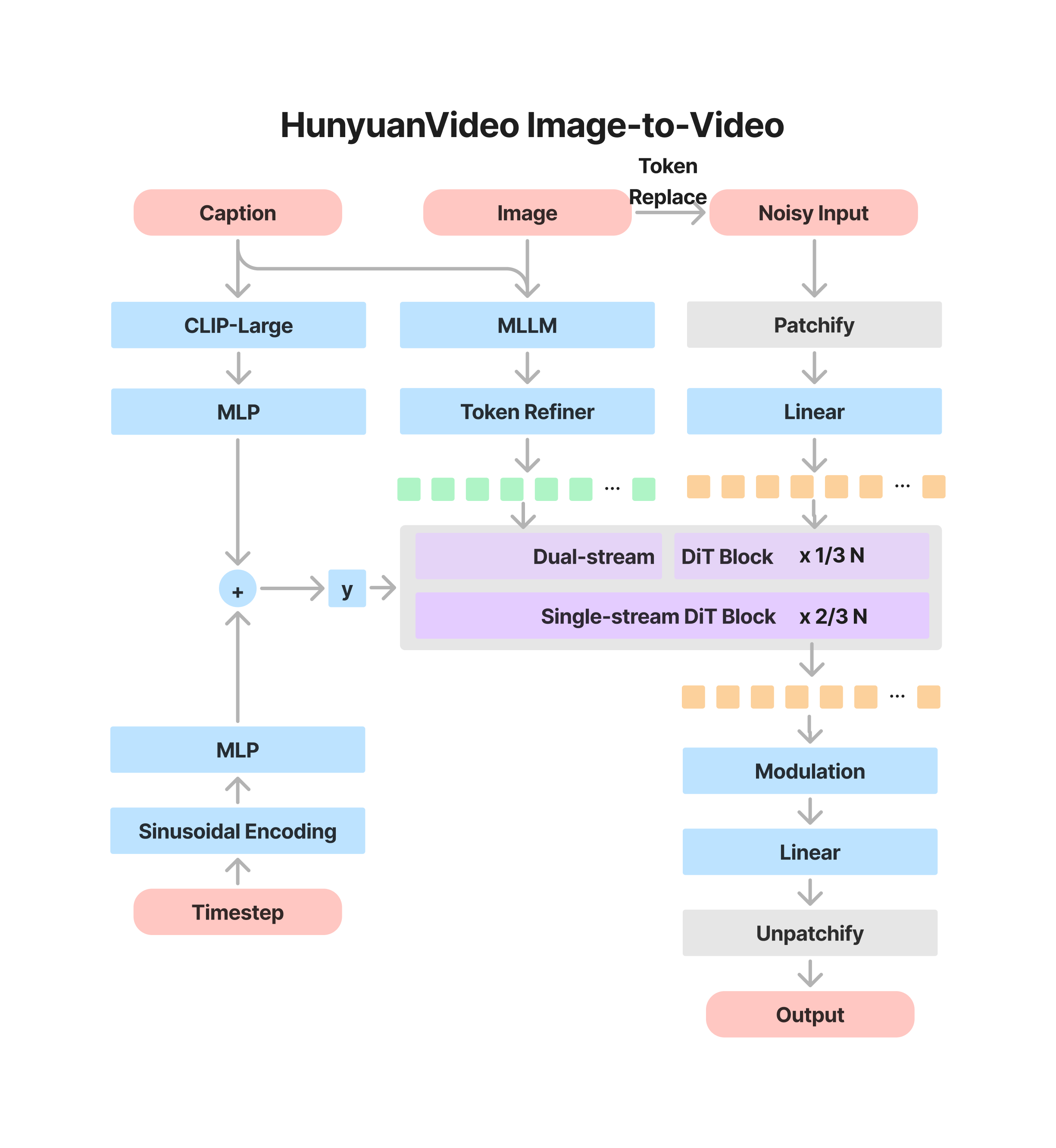
135 KB
assets/demo/i2v/imgs/0.jpg
0 → 100644
{kind=link}

401 KB
assets/demo/i2v/imgs/1.png
0 → 100644
{kind=link}

8.5 MB
assets/demo/i2v/videos/0.mp4
0 → 100644
File added
assets/demo/i2v/videos/1.mp4
0 → 100644
File added
{kind=link}

4.68 MB
{kind=link}

2.22 MB
File added
File added
File added
assets/hunyuanvideo.pdf
0 → 100644
File added