
Initial commit
Showing
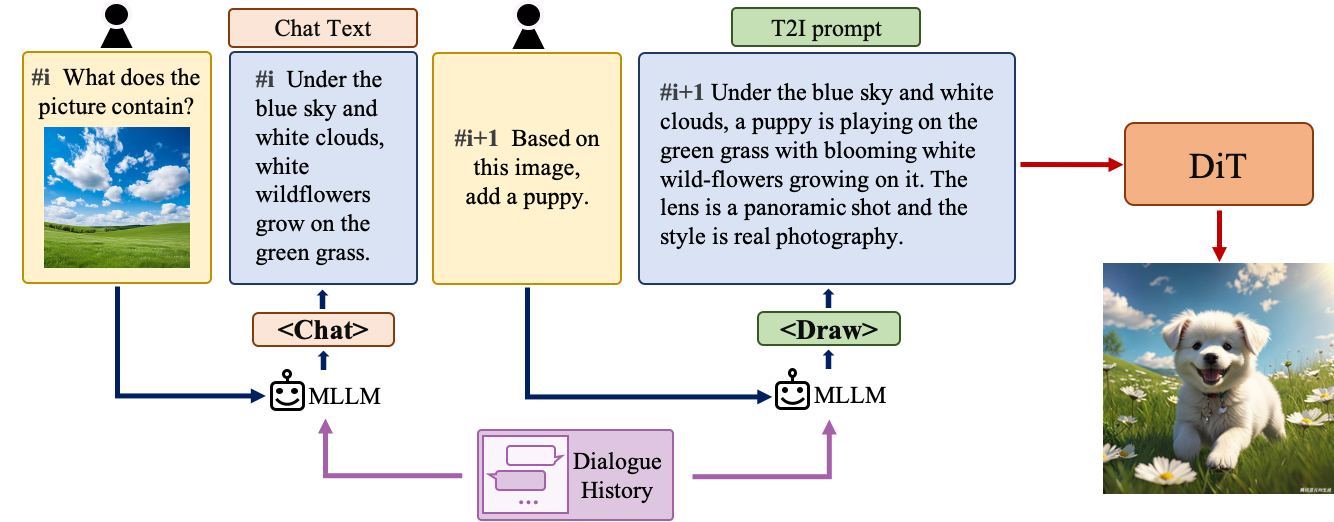
asset/mllm.png
0 → 100644
{kind=link}
290 KB
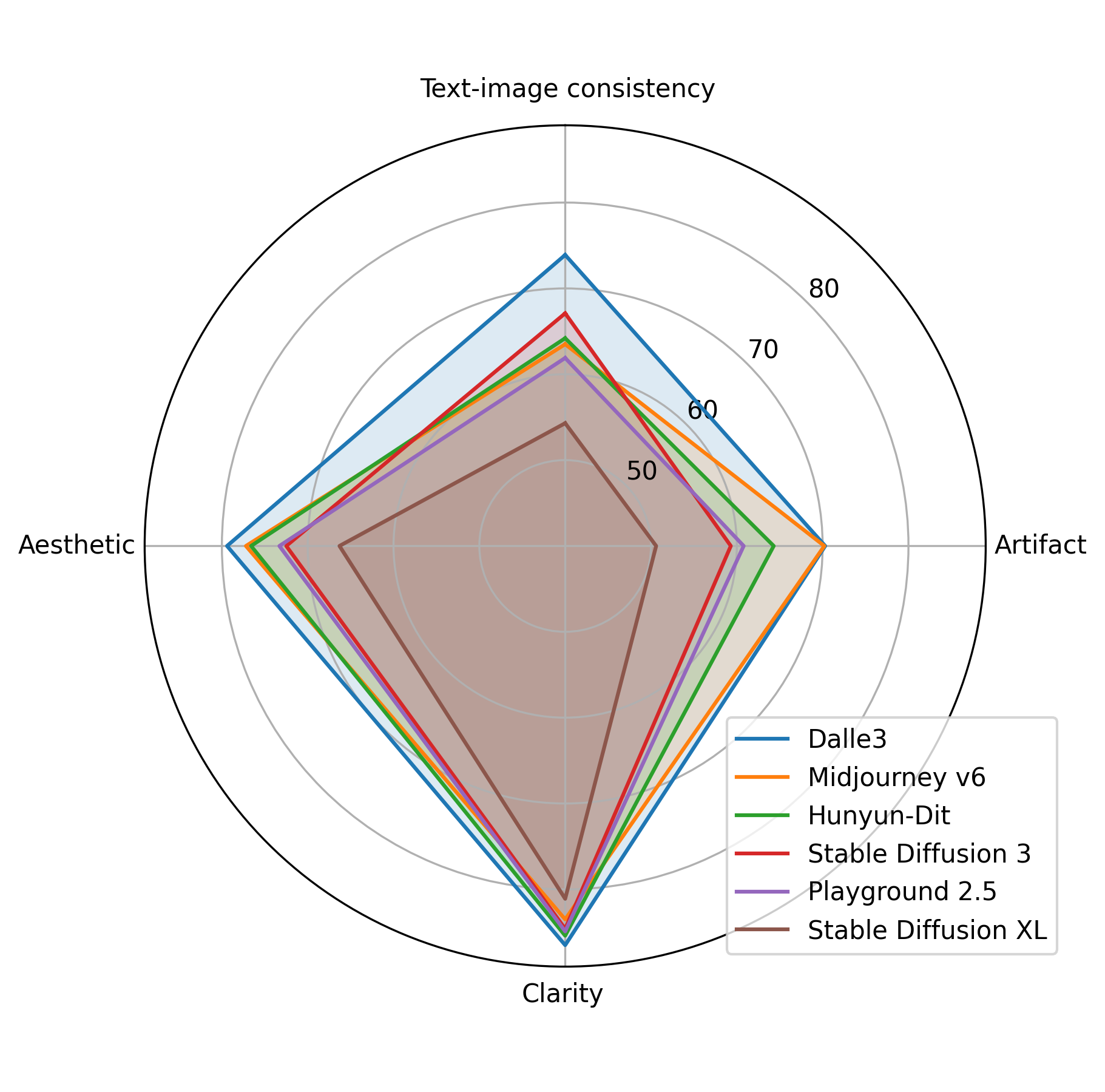
asset/radar.png
0 → 100644
{kind=link}
500 KB
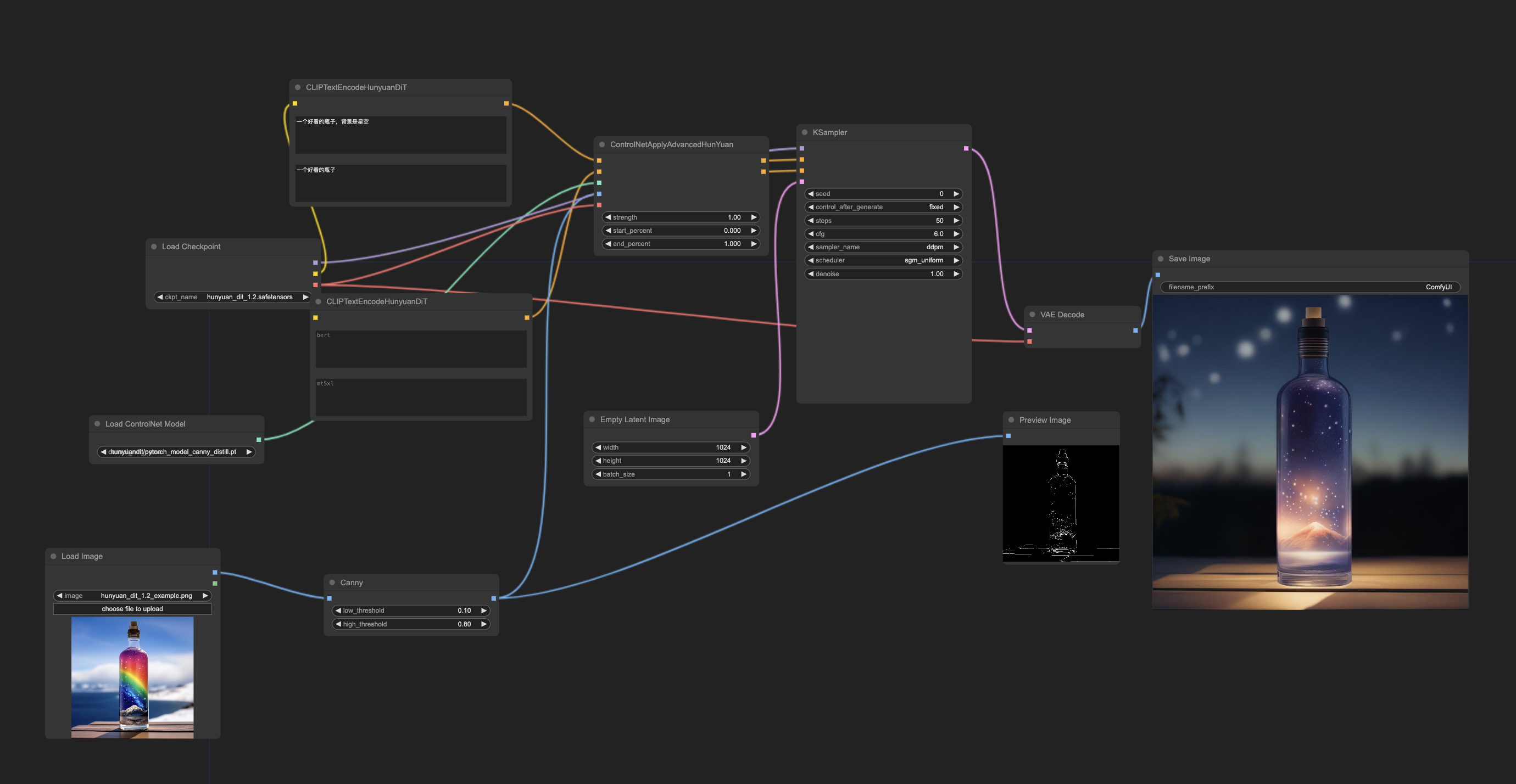
comfyui/README.md
0 → 100644
{kind=link}
971 KB
{kind=link}

1.5 MB
{kind=link}

1.17 MB
controlnet/README.md
0 → 100644
{kind=link}

210 KB
{kind=link}

31.7 KB
{kind=link}

24.7 KB
{kind=link}

1.39 MB
{kind=link}

1.36 MB
{kind=link}

1.56 MB
dataset/yamls/porcelain.yaml
0 → 100644
diffusers/README.md
0 → 100644
environment.yml
0 → 100644
example_prompts.txt
0 → 100644
hydit/__init__.py
0 → 100644