
init0905
Showing
File added
requirement copy.txt
0 → 100644
requirement.txt
0 → 100644
resources/legend.png
0 → 100644
{kind=link}

44.6 KB
resources/motion_planner.png
0 → 100644
{kind=link}
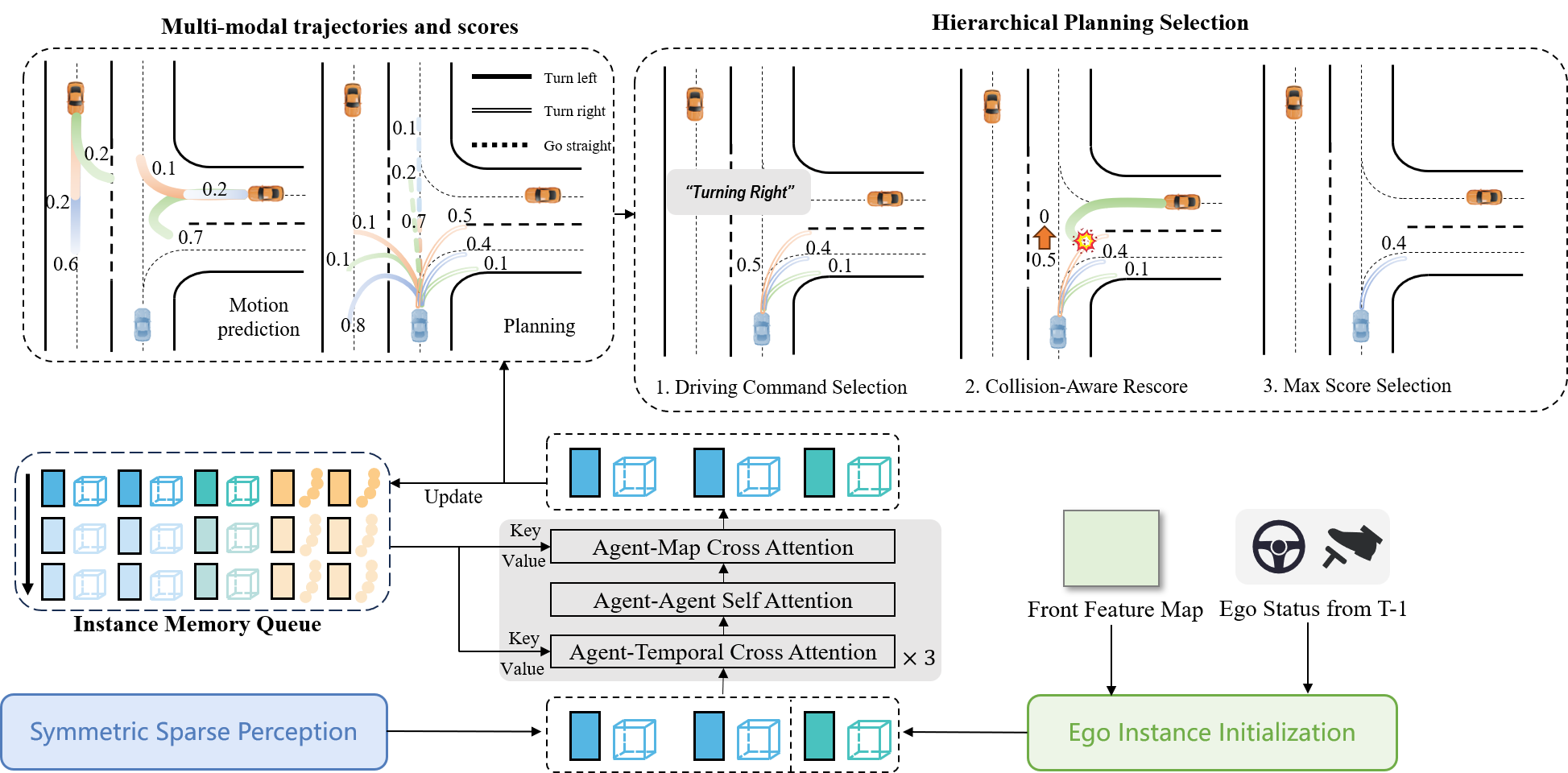
191 KB
resources/overview.png
0 → 100644
{kind=link}
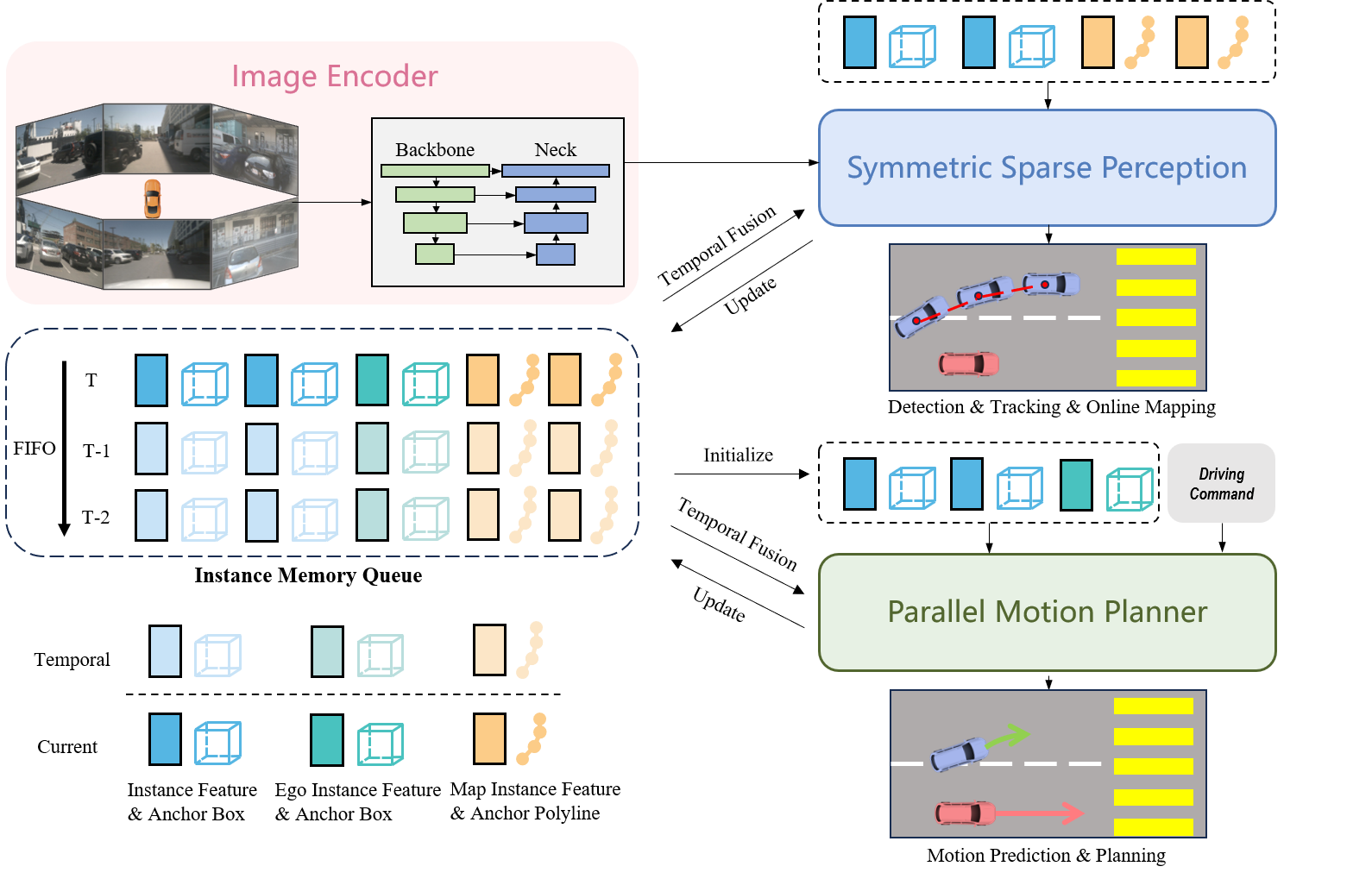
296 KB
resources/sdc_car.png
0 → 100644
{kind=link}

208 KB
{kind=link}
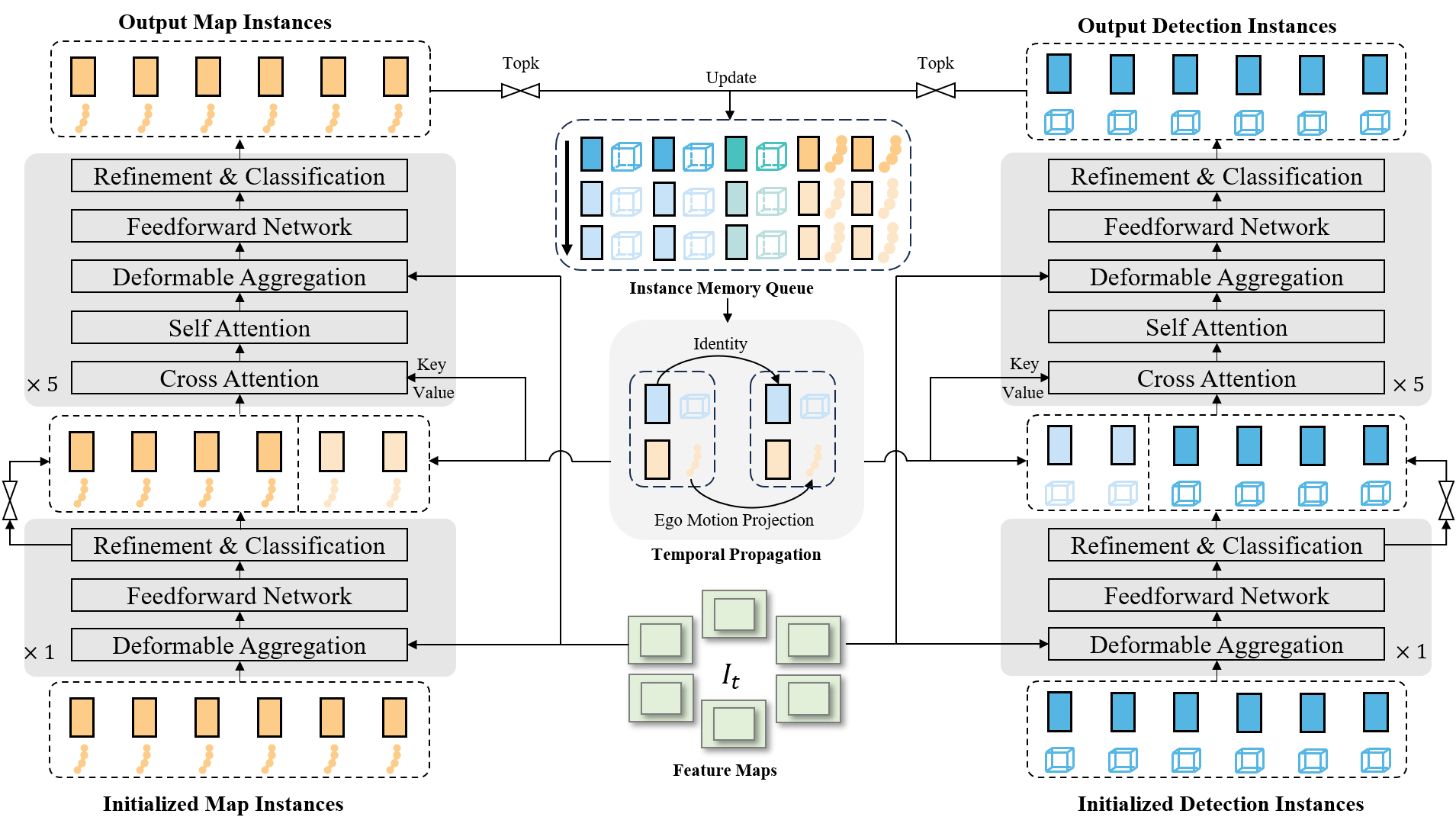
183 KB