# Lightx2v 参数卸载机制文档
## 📖 概述
Lightx2v 实现了先进的参数卸载机制,专为在有限硬件资源下处理大型模型推理而设计。该系统通过智能管理不同内存层次中的模型权重,提供了优秀的速度-内存平衡。
**核心特性:**
- **分block/phase卸载**:高效地以block/phase为单位管理模型权重,实现最优内存使用
- **Block**:Transformer模型的基本计算单元,包含完整的Transformer层(自注意力、交叉注意力、前馈网络等),是较大的内存管理单位
- **Phase**:Block内部的更细粒度计算阶段,包含单个计算组件(如自注意力、交叉注意力、前馈网络等),提供更精细的内存控制
- **多级存储支持**:GPU → CPU → 磁盘层次结构,配合智能缓存
- **异步操作**:使用 CUDA 流实现计算和数据传输的重叠
- **磁盘/NVMe 序列化**:当内存不足时支持二级存储
## 🎯 卸载策略
### 策略一:GPU-CPU 分block/phase卸载
**适用场景**:GPU 显存不足但系统内存充足
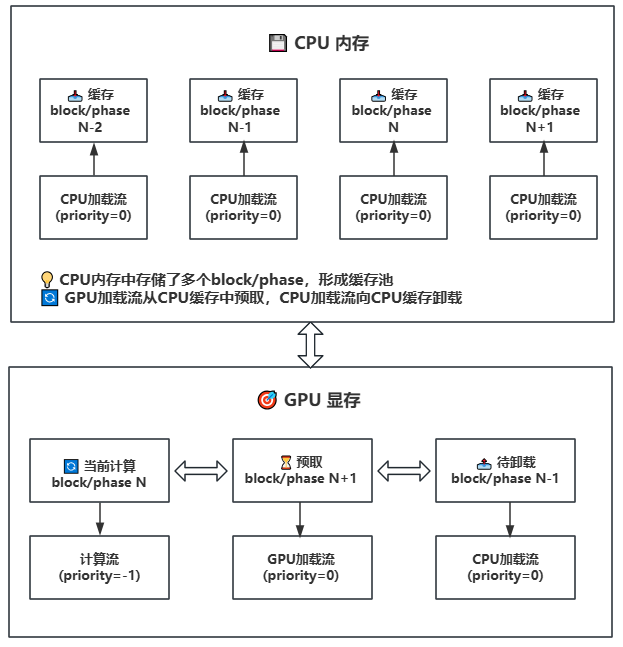
**工作原理**:在 GPU 和 CPU 内存之间以block或phase为单位管理模型权重,利用 CUDA 流实现计算和数据传输的重叠。Block包含完整的Transformer层,而Phase则是Block内部的单个计算组件。
**Block vs Phase 说明**:
- **Block粒度**:较大的内存管理单位,包含完整的Transformer层(自注意力、交叉注意力、前馈网络等),适合内存充足的情况,减少管理开销
- **Phase粒度**:更细粒度的内存管理,包含单个计算组件(如自注意力、交叉注意力、前馈网络等),适合内存受限的情况,提供更灵活的内存控制
**关键特性:**
- **异步传输**:使用三个不同优先级的CUDA流实现计算和传输的并行
- 计算流(priority=-1):高优先级,负责当前计算
- GPU加载流(priority=0):中优先级,负责从CPU到GPU的预取
- CPU加载流(priority=0):中优先级,负责从GPU到CPU的卸载
- **预取机制**:提前将下一个block/phase加载到 GPU
- **智能缓存**:在 CPU 内存中维护权重缓存
- **流同步**:确保数据传输和计算的正确性
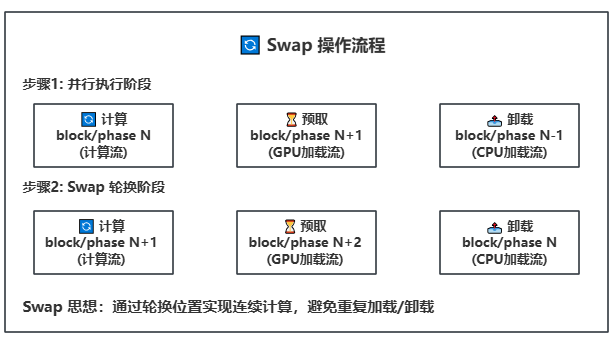
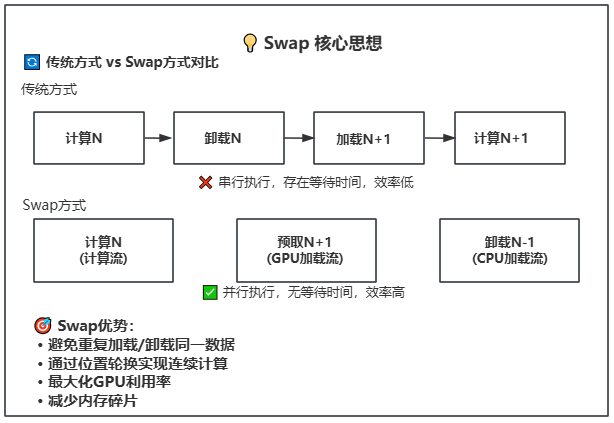
- **Swap操作**:计算完成后轮换block/phase位置,实现连续计算
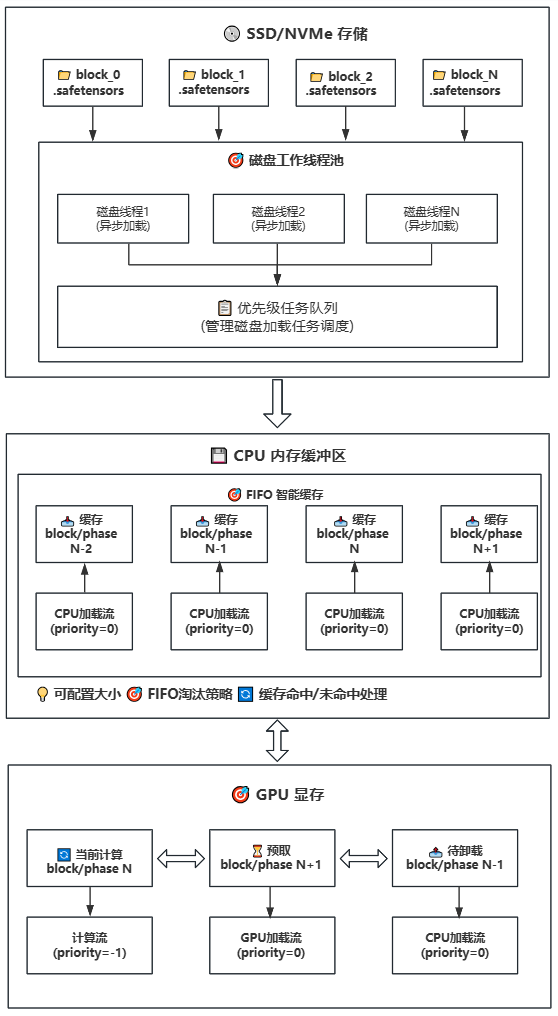
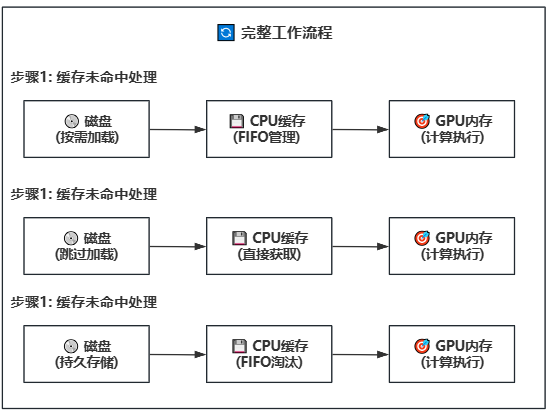
### 策略二:磁盘-CPU-GPU 分block/phase卸载(延迟加载)
**适用场景**:GPU 显存和系统内存都不足
**工作原理**:在策略一的基础上引入磁盘存储,实现三级存储层次(磁盘 → CPU → GPU)。CPU继续作为缓存池,但大小可配置,适用于CPU内存受限的设备。
**关键特性:**
- **延迟加载**:模型权重按需从磁盘加载,避免一次性加载全部模型
- **智能缓存**:CPU内存缓冲区使用FIFO策略管理,可配置大小
- **多线程预取**:使用多个磁盘工作线程并行加载
- **异步传输**:使用CUDA流实现计算和数据传输的重叠
- **Swap轮换**:通过位置轮换实现连续计算,避免重复加载/卸载
**工作步骤**:
- **磁盘存储**:模型权重按block存储在SSD/NVMe上,每个block一个.safetensors文件
- **任务调度**:当需要某个block/phase时,优先级任务队列分配磁盘工作线程
- **异步加载**:多个磁盘线程并行从磁盘读取权重文件到CPU内存缓冲区
- **智能缓存**:CPU内存缓冲区使用FIFO策略管理缓存,可配置大小
- **缓存命中**:如果权重已在缓存中,直接传输到GPU,无需磁盘读取
- **预取传输**:缓存中的权重异步传输到GPU内存(使用GPU加载流)
- **计算执行**:GPU上的权重进行计算(使用计算流),同时后台继续预取下一个block/phase
- **Swap轮换**:计算完成后轮换block/phase位置,实现连续计算
- **内存管理**:当CPU缓存满时,自动淘汰最早使用的权重block/phase
## ⚙️ 配置参数
### GPU-CPU 卸载配置
```python
config = {
"cpu_offload": True,
"offload_ratio": 1.0, # 卸载比例(0.0-1.0)
"offload_granularity": "block", # 卸载粒度:"block"或"phase"
"lazy_load": False, # 禁用延迟加载
}
```
### 磁盘-CPU-GPU 卸载配置
```python
config = {
"cpu_offload": True,
"lazy_load": True, # 启用延迟加载
"offload_ratio": 1.0, # 卸载比例
"offload_granularity": "phase", # 推荐使用phase粒度
"num_disk_workers": 2, # 磁盘工作线程数
"offload_to_disk": True, # 启用磁盘卸载
"offload_path": ".", # 磁盘卸载路径
}
```
**智能缓存关键参数:**
- `max_memory`:控制CPU缓存大小,影响缓存命中率和内存使用
- `num_disk_workers`:控制磁盘加载线程数,影响预取速度
- `offload_granularity`:控制缓存粒度(block或phase),影响缓存效率
- `"block"`:以完整的Transformer层为单位进行缓存管理
- `"phase"`:以单个计算组件为单位进行缓存管理
详细配置文件可参考[config](https://github.com/ModelTC/lightx2v/tree/main/configs/offload)
## 🎯 使用建议
- 🔄 GPU-CPU分block/phase卸载:适合GPU显存不足(RTX 3090/4090 24G)但系统内存(>64/128G)充足
- 💾 磁盘-CPU-GPU分block/phase卸载:适合GPU显存(RTX 3060/4090 8G)和系统内存(16/32G)都不足
- 🚫 无Offload:适合高端硬件配置,追求最佳性能
## 🔍 故障排除
### 常见问题及解决方案
1. **磁盘I/O瓶颈**
- 解决方案:使用NVMe SSD,增加num_disk_workers
2. **内存缓冲区溢出**
- 解决方案:增加max_memory或减少num_disk_workers
3. **加载超时**
- 解决方案:检查磁盘性能,优化文件系统
**注意**:本卸载机制专为Lightx2v设计,充分利用了现代硬件的异步计算能力,能够显著降低大模型推理的硬件门槛。