
Merge branch 'main' into audio_r2v
Showing
README_zh.md
0 → 100644
app/README.md
0 → 100755
{kind=link}
27.7 KB
{kind=link}
31.4 KB
{kind=link}
21.2 KB
{kind=link}
22.5 KB
{kind=link}
24.4 KB
{kind=link}
25.1 KB
{kind=link}
45.1 KB
{kind=link}
43.7 KB
{kind=link}
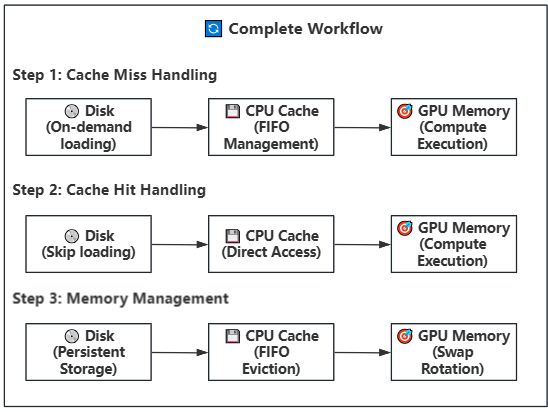
27.8 KB
{kind=link}
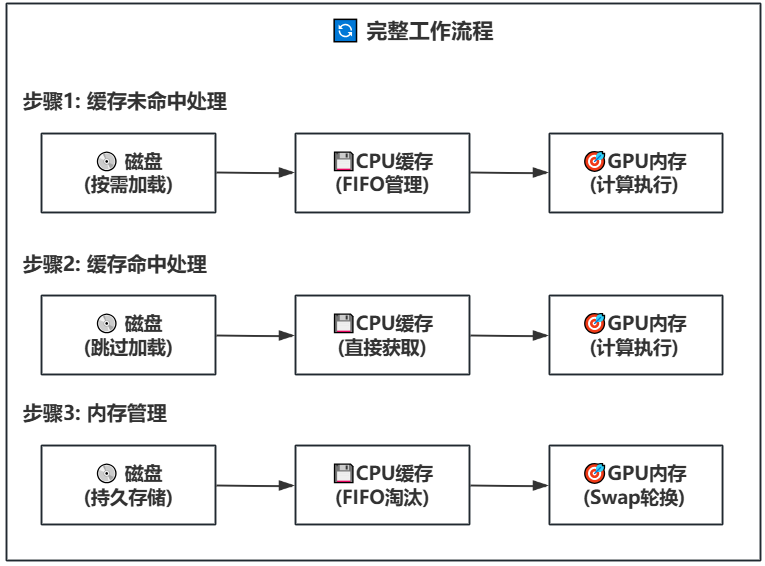
52.3 KB
File moved
27.7 KB
31.4 KB
21.2 KB
22.5 KB
24.4 KB
25.1 KB
45.1 KB
43.7 KB
27.8 KB
52.3 KB